大模型从0到1|第十四课:实战数据过滤和去重¶
上一讲:训练数据策略 本讲:深入探讨机制
1. 概览 (Overview)¶
上一讲:用于训练语言模型的数据集概览 * 在线服务 (GitHub) → 转储/抓取 (GH Archive) → 处理后的数据 (The Stack) * 处理:HTML 转文本,语言/质量/毒性过滤,去重
本讲:深入探讨机制 * 过滤算法(例如:分类器) * 过滤的应用(例如:语言,质量,毒性) * 去重(例如:Bloom filters, MinHash, LSH)
2. 过滤算法 (Filtering algorithms)¶
算法构建块: * 给定一些 目标数据 T 和大量 原始数据 R,找到 R 中与 T 相似的子集 T'。
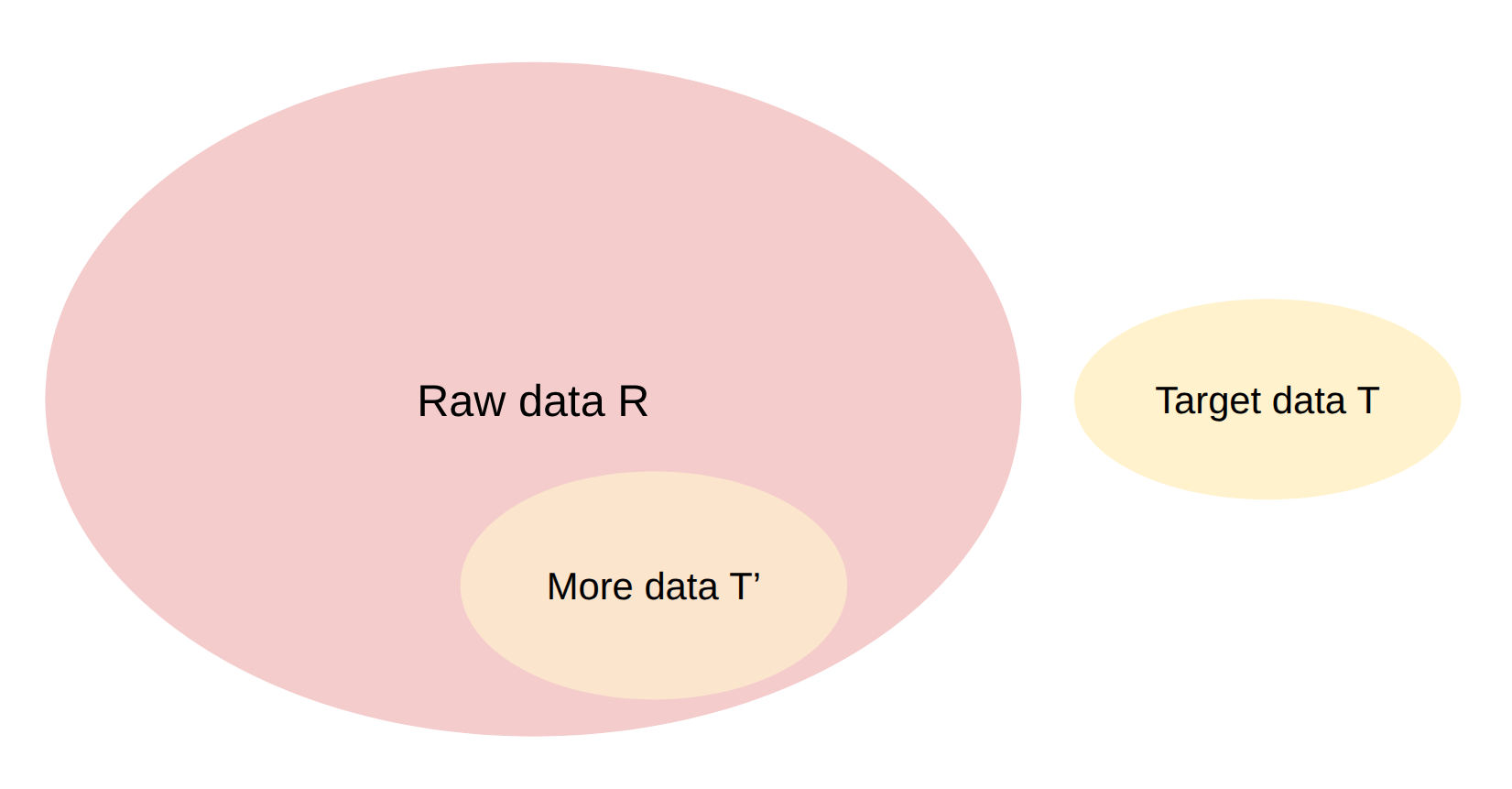
过滤算法的期望: * 从目标数据泛化(希望 T 和 T' 不同) * 极快(必须在巨大的 R 上运行)
KenLM¶
带 Kneser-Ney 平滑的 n-gram 模型 Article * KenLM:最初用于机器翻译的快速实现 code * 用于数据过滤的通用语言模型 * 极其简单 / 快速 - 只是计数和归一化
概念 n-gram 语言模型的极大似然估计: * n = 3: p(in | the cat) = count(the cat in) / count(the cat) 问题:稀疏计数(对于大 n,许多 n-grams 计数为 0) 解决方案:使用 Kneser-Ney 平滑来处理未见过的 n-grams Article * p(in | the cat) 也依赖于 p(in | cat)
使用 KenLM 语言模型
# Download a KenLM language model
model_url = "https://huggingface.co/edugp/kenlm/resolve/main/wikipedia/en.arpa.bin"
model = kenlm.Model(model_path)
def compute(content: str):
# Hacky preprocessing
content = "<s> " + content.replace(",", " ,").replace(".", " .") + " </s>"
# log p(content)
score = model.score(content)
# Perplexity normalizes by number of tokens to avoid favoring short documents
num_tokens = len(list(model.full_scores(content)))
perplexity = math.exp(-score / num_tokens)
return score, perplexity
# Examples
compute("Stanford University was founded in 1885...") # Low perplexity (good)
compute("asdf asdf asdf asdf asdf") # High perplexity (bad)
CCNet Link * 项目是文本段落 * 按困惑度 (perplexity) 递增排序段落 * 保留前 1/3 * 曾用于 LLaMA
总结:Kneser-Ney n-gram 语言模型(使用 KenLM 实现)很快但很粗糙。
fastText¶
fastText 分类器 Link * 任务:文本分类(例如情感分类) * 目标是训练一个用于文本分类的快速分类器 * 他们发现它和慢得多的神经网络分类器一样好
基线:词袋 (Baselin: bag of words)(并非他们所做)
L = 32 # Length of input
V = 8192 # Vocabulary size
K = 64 # Number of classes
W = nn.Embedding(V, K) # Embedding parameters (V x K)
x = torch.randint(V, (L,)) # Input tokens (L)
y = softmax(W(x).mean(dim=0)) # Output probabilities (K)
fastText 分类器:词嵌入袋 (Bag of word embeddings)
H = 16 # Hidden dimension
W = nn.Embedding(V, H) # Embedding parameters (V x H)
U = nn.Linear(H, K) # Head parameters (H x K)
y = softmax(U(W(x).mean(dim=0))) # Output probabilities (K)
实现: * 并行化,异步 SGD * 学习率:从 [某个数字] 线性插值到 0 Article
n-grams 袋 (Bag of n-grams)
问题:bigrams 的数量可能很大(并且也可能是无界的) 解决方案:哈希技巧 (hashing trick)- 对于质量过滤,我们有 K = 2 个类(好 vs 坏)
- 在这种情况下,fastText 只是一个线性分类器 (H = K = 2)
一般来说,可以使用任何分类器(例如 BERT, Llama),只是更慢。
DSIR¶
通过重要性重采样进行语言模型数据选择 (DSIR) Link
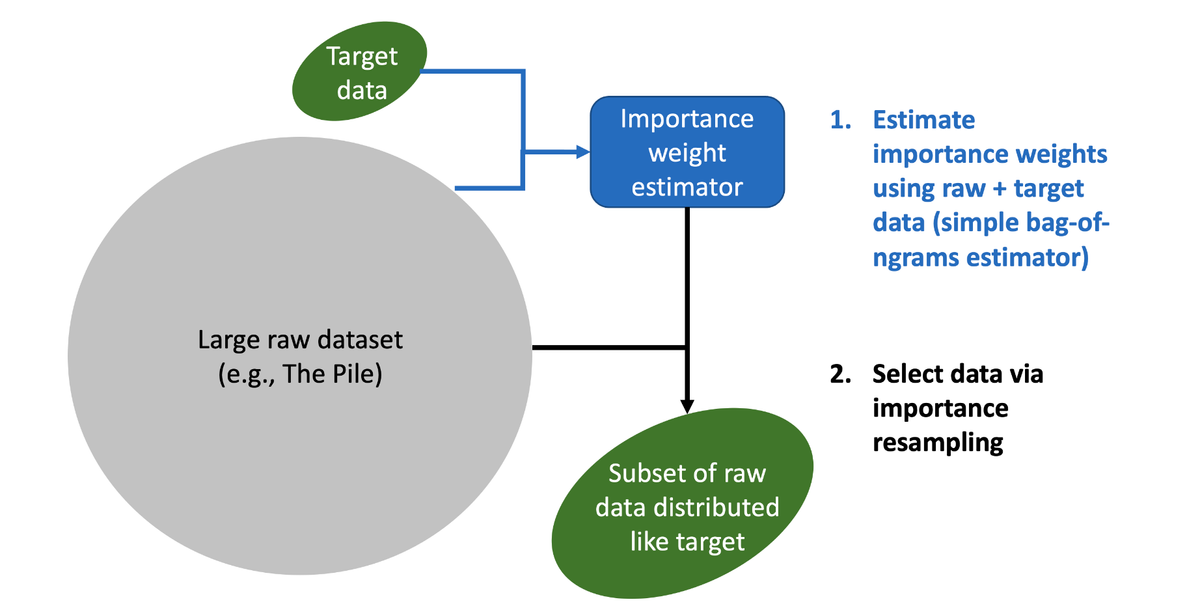
设置: * 目标数据集 D_p(小) * 提议(原始)数据集 D_q(大)
尝试 1: * 在 D_p 上拟合目标分布 p * 在 D_q 上拟合提议分布 q * 使用 p, q 和原始样本 D_q 进行重要性重采样 问题:目标数据 D_p 太小,无法估计一个好的模型
尝试 2:使用哈希 n-grams
# Hash the n-grams
num_bins = 10000
def get_hashed_ngrams(text: str):
ngrams = text.split(" ")
return [hash(ngram) % num_bins for ngram in ngrams]
# Learn unigram model
probs = [count(training_hashed_ngrams, x) / len(training_hashed_ngrams) for x in range(num_bins)]
# Evaluate probability of any sentence
prob = np.prod([probs[x] for x in hashed_ngrams])

与 fastText 的比较: * 建模分布是一个捕捉多样性的更原则性的方法 * 类似的计算复杂度 * 两者都可以通过更好的建模来改进
总结¶
一般框架 给定目标 T 和原始 R,找到 R 中与 T 相似的子集 1. 基于 R 和 T 估计某个模型并推导评分函数 2. 基于分数保留 R 中的示例
框架的实例化 T 的生成模型 (KenLM): 1. score(x) = p_T(x) 2. 随机保留 score(x) >= threshold 的示例 x
判别式分类器 (fastText): 1. score(x) = p(T | x) 2. 随机保留 score(x) >= threshold 的示例 x
重要性重采样 (DSIR): 1. score(x) = p_T(x) / p_R(x) 2. 以正比于 score(x) 的概率重采样示例 x
数据选择调查论文 Link
3. 过滤应用 (Filtering applications)¶
同样的数据过滤机制可用于不同的过滤任务。
语言识别 (Language identification)¶
语言识别:查找特定语言(例如英语)的文本
为什么不直接搞多语言? * 数据:难以对任何给定语言的高质量数据进行策划/处理 * 计算:在计算受限的制度下,致力于任何给定语言的计算/token 更少 模型在多语言性方面有所不同: * English 仅占 BLOOM(训练不足)的 30%,英语性能受损 Link * 大多数前沿模型(GPT-4, Claude, Gemini, Llama, Qwen)都是高度多语言的(充分训练)
fastText 语言识别 Article * 现成的分类器 * 支持 176 种语言 * 在多语言网站上训练:Wikipedia, Tatoeba(翻译网站)和 SETimes(东南欧新闻)
示例:Dolma 保留 p(English) >= 0.5 的页面 Link
# Make predictions
model.predict(["The quick brown fox..."]) # English
model.predict(["OMG that movie was 🔥🔥!"]) # Informal English
model.predict(["Auf dem Wasser zu singen"]) # German
model.predict(["for (int i = 0; i < 10; i++)"]) # C++ (may be misclassified?)
注意事项: * 短序列困难 * 低资源语言困难 * 可能会意外过滤掉英语方言 * 相似语言(马来语和印尼语)困难 * 语码转换(例如西班牙语 + 英语)定义不明确
OpenMathText Link * 目标:从 CommonCrawl 策划大型数学文本语料库 * 使用规则过滤(例如包含 latex 命令) * KenLM 在 ProofPile 上训练,保留困惑度 < 15000 * 训练 fastText 分类器预测数学写作,如果是数学阈值为 0.17,如果无数学则为 0.8 结果:产生了 14.7B tokens,用于训练 1.4B 模型,其表现优于在 20 倍数据上训练的模型
质量过滤 (Quality filtering)¶
- 一些故意不使用基于模型的过滤 (C4, Gopher, RefinedWeb, FineWeb, Dolma)
- 一些使用基于模型的过滤 (GPT-3, LLaMA, DCLM) [正成为常态]
GPT-3 Link
* 正例:来自 {Wikipedia, WebText2, Books1, Books2} 的样本
* 负例:来自 CommonCrawl 的样本
 基于单词特征训练线性分类器 Article
根据分数随机保留文档:
基于单词特征训练线性分类器 Article
根据分数随机保留文档:
LLaMA/RedPajama Link * 正例:Wikipedia 引用页面的样本 * 负例:CommonCrawl 的样本 * 保留归类为正的文档
phi-1 Link 哲学:非常高质量的数据(教科书)来训练小模型 (1.5B) 包括来自 GPT 3.5 的合成数据(后来:GPT-4)和过滤数据
- R = "The Stack 的 Python 子集" # 原始数据
- prompt = "determine its educational value..."
- T = "使用 GPT-4 对 100K R 子集进行分类以获得正例"
- 使用预训练 codegen 模型的输出嵌入在 T 上训练随机森林分类器
- 从 R 中选择被分类器分类为正的数据
HumanEval 结果: * 在 The Stack 的 Python 子集上训练 1.3B LM(性能:96K 步后 12.19%) * 在新的过滤子集上训练 1.3B LM(性能:36K 步后 17.68%) - 更好!
毒性过滤 (Toxicity filtering)¶
警告:以下可能包含冒犯性内容
Dolma 中的毒性过滤 Link 数据集:Jigsaw 有毒评论数据集 (2018) dataset * 项目目标:帮助人们在网上进行更好的讨论 Article * 数据:Wikipedia 讨论页上的评论,标注为 {toxic, severe_toxic, obscene, threat, insult, identity_hate}
训练了 2 个 fastText 分类器: * hate: 正例 = {unlabeled, obscene}, 负例 = 其他所有 * NSFW: 正例 = {obscene}, 负例 = 其他所有
# Examples
train_examples = [
Example(label=0, text="Are you threatening me...?"),
Example(label=1, text="Stupid peace of shit..."),
]
model.predict(["I love strawberries"]) # OK
model.predict(["I hate strawberries"]) # OK
4. 去重 (Deduplication)¶
两种类型的重复: * 精确重复(镜像站点,GitHub forks) Gutenberg mirrors * 近似重复:只有几个 tokens 不同的相同文本
近似重复的例子:
* 服务条款和许可证 MIT license
* 公式化写作(复制/粘贴或从模板生成)
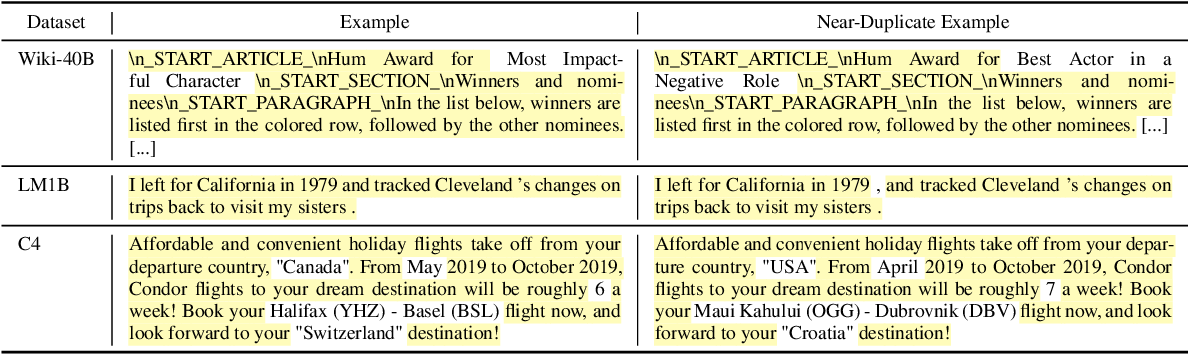 * 复制/粘贴中的微小格式差异
* 复制/粘贴中的微小格式差异
在 C4 中,产品描述重复了 61,036 次: “by combining fantastic ideas, interesting arrangements...” Example page
去重训练数据使语言模型更好 Link * 训练更有效率(因为 tokens 更少) * 避免死记硬背(可以减轻版权、隐私问题)
设计空间: 1. 什么是项目(句子,段落,文档)? 2. 如何匹配(精确匹配,存在公共子项,公共子项的比例)? 3. 采取什么行动(全部删除,除一个外全部删除)?
关键挑战: * 去重根本上是关于将项目与其他项目进行比较 * 需要线性时间算法来扩展
哈希函数 (Hash functions)¶
- 哈希函数 h 将项目映射到哈希值(整数或字符串)
- 哈希值比项目小得多
- 哈希冲突:对于 x ≠ y,h(x) = h(y)
效率与抗冲突性之间的权衡 Article * 加密哈希函数 (SHA-256):抗冲突,慢(用于比特币) * DJB2, MurmurHash, CityHash: 不抗冲突,快(用于哈希表) * 我们将使用 MurmurHash
精确去重 (Exact deduplication)¶
简单例子 1. 项目:字符串 2. 如何匹配:精确匹配 3. 操作:除一个外全部删除
items = ["Hello!", "hello", "hello there", "hello", "hi", "bye"]
# Group by hash
hash_items = itertools.groupby(sorted(items, key=mmh3.hash), key=mmh3.hash)
# Keep one
deduped_items = [next(group) for h, group in hash_items]
- 优点:简单,语义清晰,高精度
- 缺点:不去重近似重复
- 此代码是以 MapReduce 方式编写的,可以轻松并行化和扩展
C4 Link 1. 项目:3 句话的跨度 2. 如何匹配:使用精确匹配 3. 操作:除一个外全部删除 警告:当从文档中间删除 3 句话的跨度时,生成的文档可能不连贯
Bloom filter¶
目标:用于测试集合成员资格的高效、近似数据结构
Bloom filters 的特点 * 内存高效 * 可以更新,但不能删除 * 如果返回 'no',肯定是 'no' * 如果返回 'yes',很可能是 'yes',但有小概率是 'no' * 可以通过更多的时间/计算以指数方式降低假阳性率
构建 首先,使哈希函数的范围变小(少量的 bins)。 问题:小 bins 会导致假阳性。 朴素解决方案:增加 bins 数量。错误概率是 O(1/num_bins)。 更好的解决方案:使用更多哈希函数 (k)。
假阳性率分析 Article 假设哈希函数和项目独立。 * m = bins 数量 * k = 哈希函数数量 * n = 插入的项目数量
最优 k 值(给定固定的 m / n 比率):k = ln(2) * m / n 结果假阳性率:f = 0.5^k 计算 (k)、内存 (m) 和假阳性率 (f) 之间的权衡 Lecture notes
示例:Dolma * 设置假阳性率为 1e-15 * 在项目 = 段落 上执行
Jaccard similarity & MinHash¶
现在让我们看看近似集合成员资格。
Jaccard 相似度 定义:Jaccard(A, B) = |A intersect B| / |A union B| 定义:如果两个文档的 Jaccard 相似度 >= 阈值,则它们是 近似重复。
算法挑战:在线性时间内找到近似重复。
MinHash MinHash: 一个随机哈希函数 h,使得 Pr[h(A) = h(B)] = Jaccard(A, B) * 通常,你希望不同的项目哈希到不同的哈希值 * ...但在这里,你希望冲突概率取决于相似度
特征矩阵表示:
随机哈希函数在项目上引入一个排列。 查看 A 中第一个项目和 B 中第一个项目。 Pr[MinHash(A) == MinHash(B)] = Jaccard(A, B)局部敏感哈希 (Locality sensitive hashing)¶
假设我们只用一个 MinHash 函数对示例进行哈希。 P[A 和 B 冲突] = Jaccard(A, B) 平均而言,更相似的项目会冲突,但非常随机...
目标:如果 Jaccard(A, B) > 阈值,则让 A 和 B 冲突。 我们必须以某种方式锐化概率...
解决方案:使用 n 个哈希函数 分成 b 个带 (bands),每个带 r 个哈希函数 (n = b * r)
关键:如果对于 某个 带,其 所有 哈希函数都返回相同的值,则 A 和 B 冲突。 带的 and-or 结构锐化了阈值。
给定 Jaccard(A, B),A 和 B 冲突的概率是多少? prob_match = sim^r prob_collision = 1 - (1 - prob_match)^b
示例
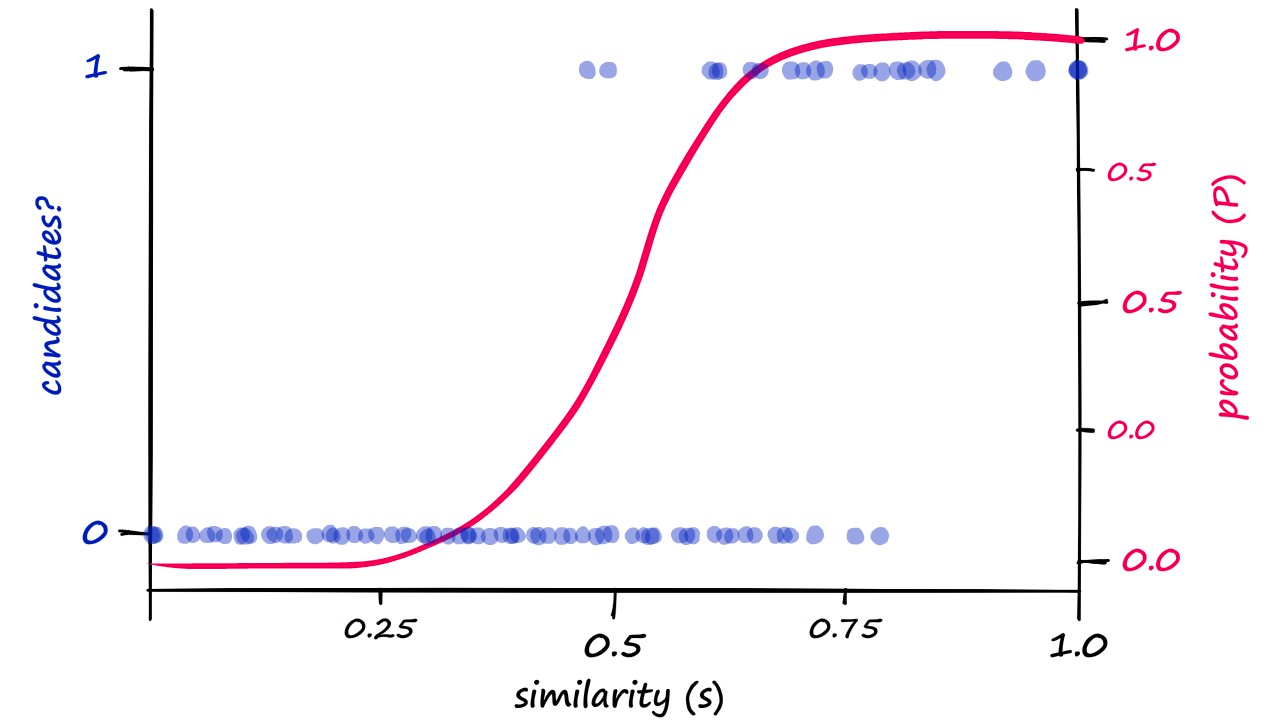
- 增加 r 会锐化阈值并将曲线向右移动(更难匹配)
- 增加 b 会将曲线向左移动(更容易匹配)
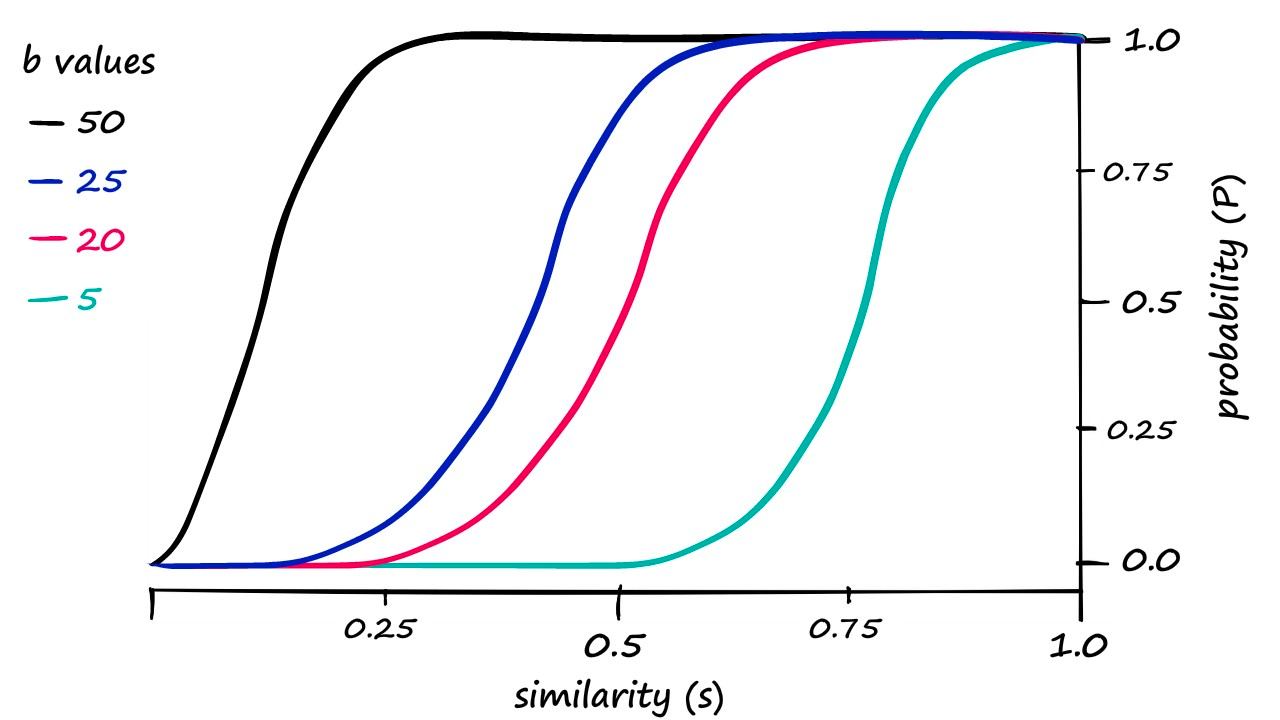
示例设置 Link * n = 9000, b = 20, r = 450 * 阈值(发生相变的地方)≈ (1/b)^(1/r) * 概率约为 1 - 1/e
5. 总结 (Summary)¶
- 算法工具:n-gram 模型 (KenLM),分类器 (fastText),重要性重采样 (DSIR)
- 应用:语言识别,质量过滤,毒性过滤
- 去重:哈希扩展到用于模糊匹配的大型数据集
- 现在你有了工具(机制),只需要花时间在数据上(直觉)