大模型从0到1|第十五课:详解SFT、RLHF¶
课程链接:Stanford CS336 Spring 2025 - Lecture 15
课程核心:本节课深入讲解大模型“对齐”(Alignment)的全流程。从如何通过SFT(监督微调)让模型学会说话,到如何通过RLHF(PPO/DPO)让模型符合人类价值观。
Part 1: 对齐的背景与 SFT (监督微调)¶
 第15讲:RLHF / Alignment (对齐)
本节课的主题是“对齐”,即如何控制大语言模型的行为,使其符合用户的意图。
第15讲:RLHF / Alignment (对齐)
本节课的主题是“对齐”,即如何控制大语言模型的行为,使其符合用户的意图。
 目前的课程进度
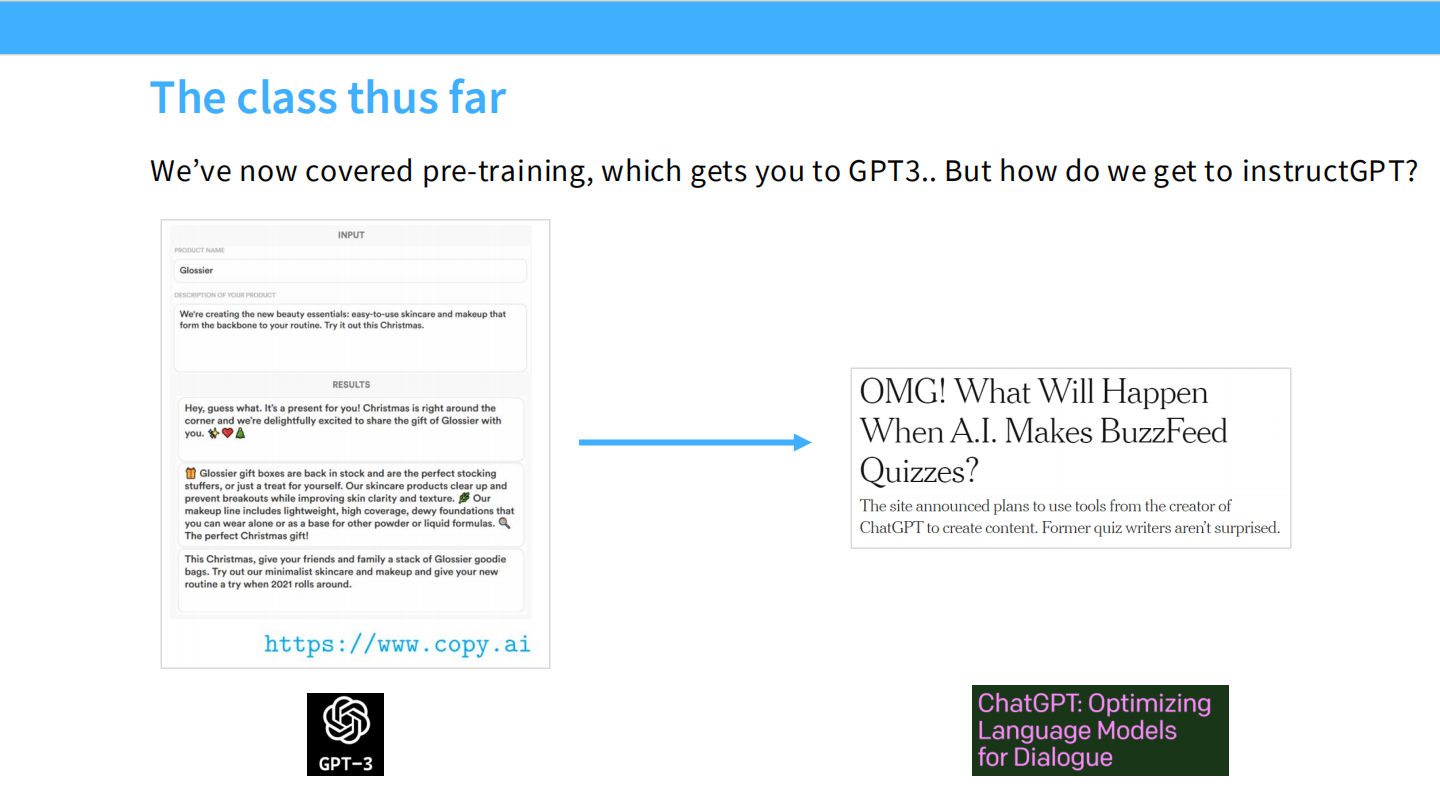
我们已经完成了预训练(Pre-training),得到了像 GPT-3 这样的基座模型。但基座模型的问题在于它只是一个“续写机”。
* 左图:Glossier 的产品描述。
* 右图:如果你给 GPT-3 一个指令,它可能会续写一段广告而不是回答问题。我们需要 InstructGPT 这样的流程来修复它。
目前的课程进度
我们已经完成了预训练(Pre-training),得到了像 GPT-3 这样的基座模型。但基座模型的问题在于它只是一个“续写机”。
* 左图:Glossier 的产品描述。
* 右图:如果你给 GPT-3 一个指令,它可能会续写一段广告而不是回答问题。我们需要 InstructGPT 这样的流程来修复它。
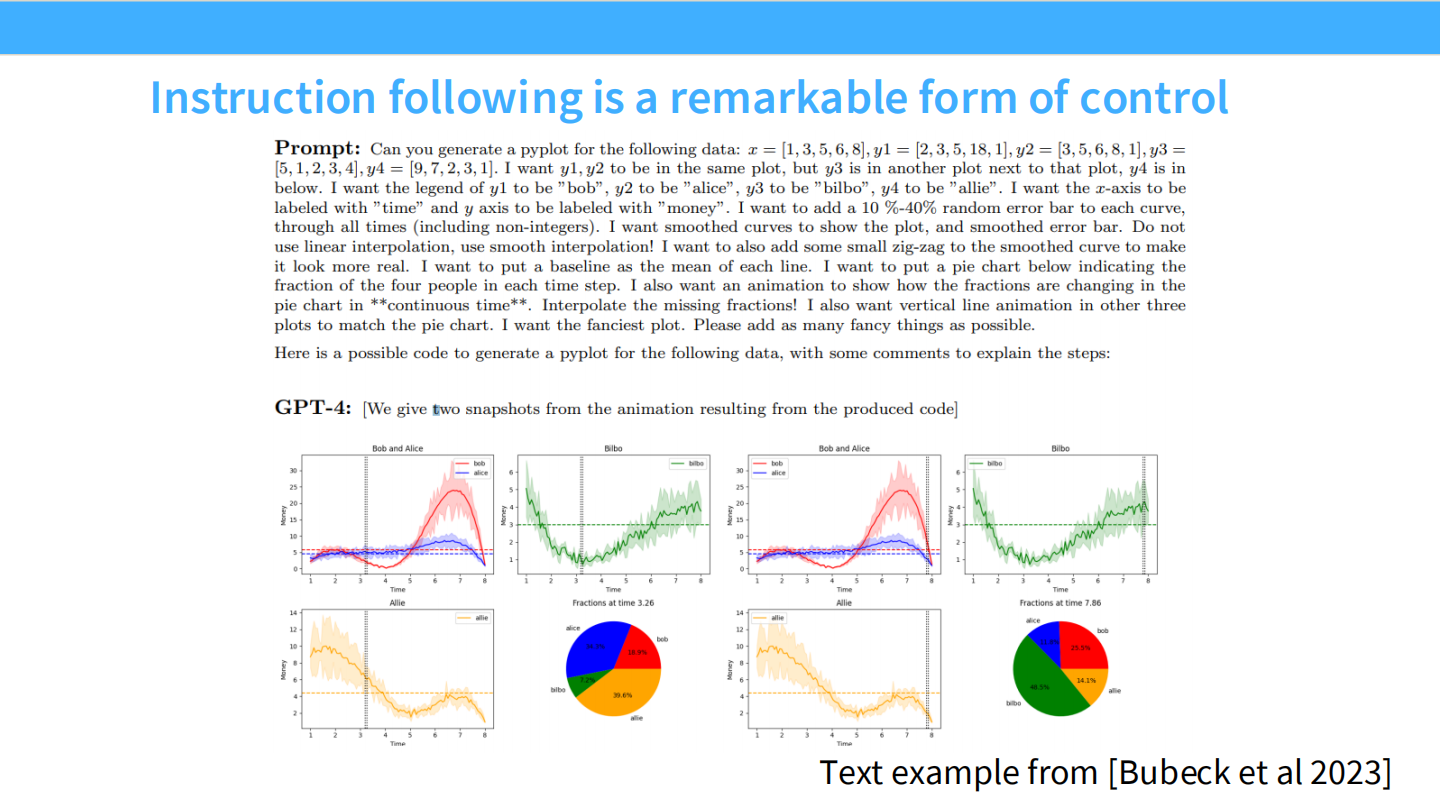 指令遵循 (Instruction Following) 是强大的控制形式
我们希望模型能精确执行复杂的约束。
* 例子:要求 GPT-4 用 Python 画图,并指定具体的坐标轴标签、动画效果。模型能完美执行这些非自然的格式要求。
指令遵循 (Instruction Following) 是强大的控制形式
我们希望模型能精确执行复杂的约束。
* 例子:要求 GPT-4 用 Python 画图,并指定具体的坐标轴标签、动画效果。模型能完美执行这些非自然的格式要求。
 安全与内容审核
除了有用性,我们还需要控制模型的安全性。
* 例子:当用户要求写带有仇恨言论的推文时,模型应该触发拒绝机制(Input/Output Filter)。
安全与内容审核
除了有用性,我们还需要控制模型的安全性。
* 例子:当用户要求写带有仇恨言论的推文时,模型应该触发拒绝机制(Input/Output Filter)。
 今天的目标:更好地控制 LM 输出
预训练数据虽然量大,但不可控。
* 核心问题:我们能否收集我们想要的行为数据来训练模型?
* 三个关键点:数据长什么样?如何利用数据?是否需要大规模?
今天的目标:更好地控制 LM 输出
预训练数据虽然量大,但不可控。
* 核心问题:我们能否收集我们想要的行为数据来训练模型?
* 三个关键点:数据长什么样?如何利用数据?是否需要大规模?
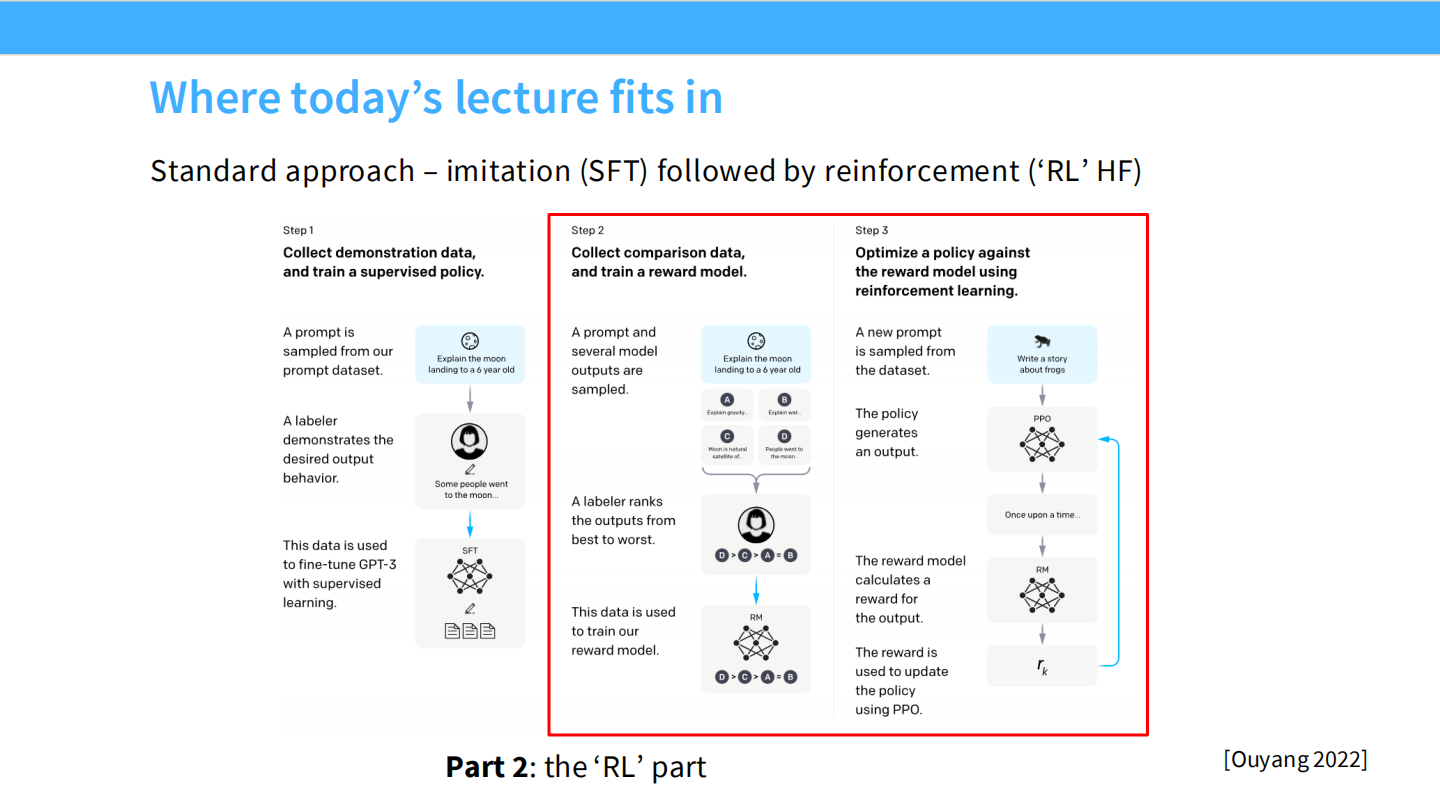
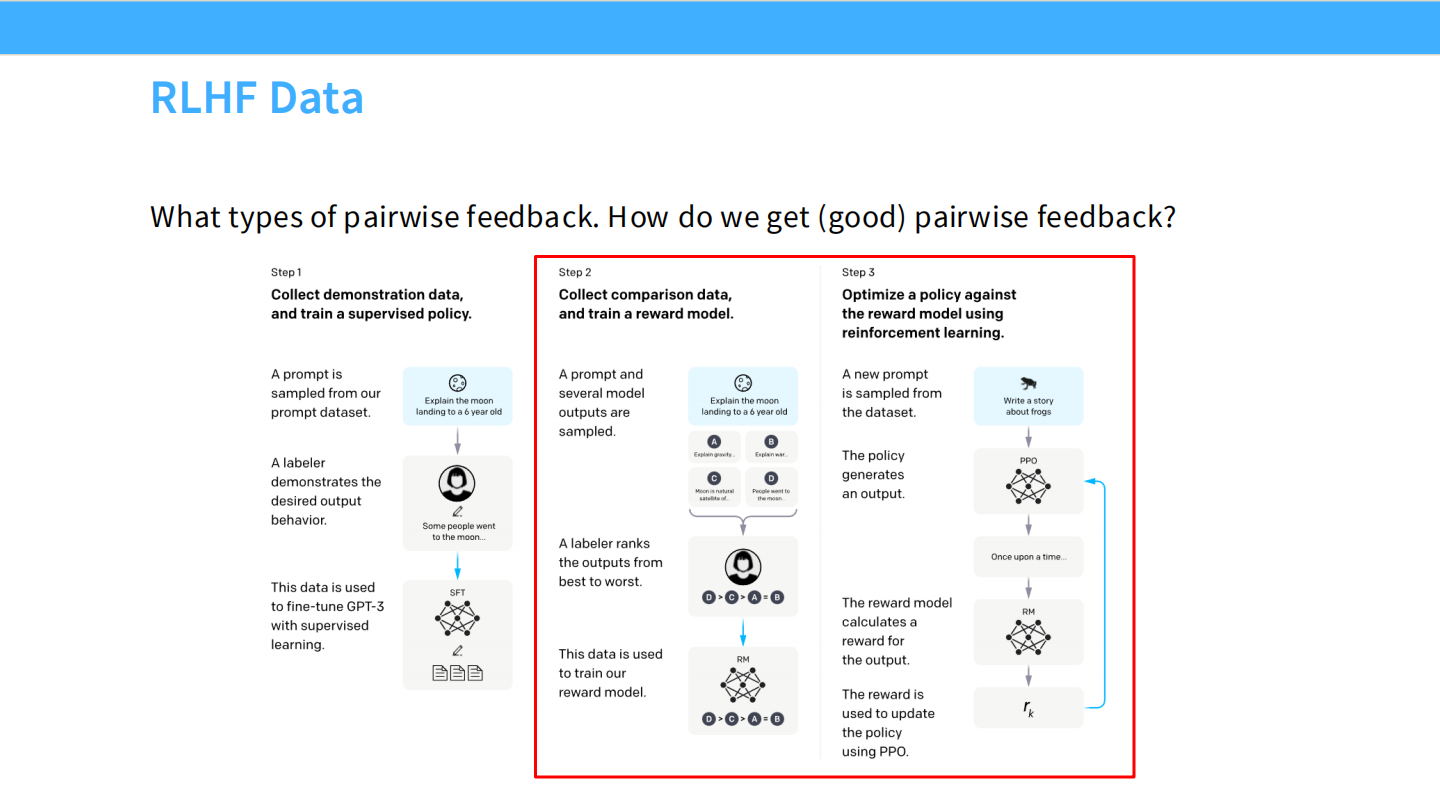
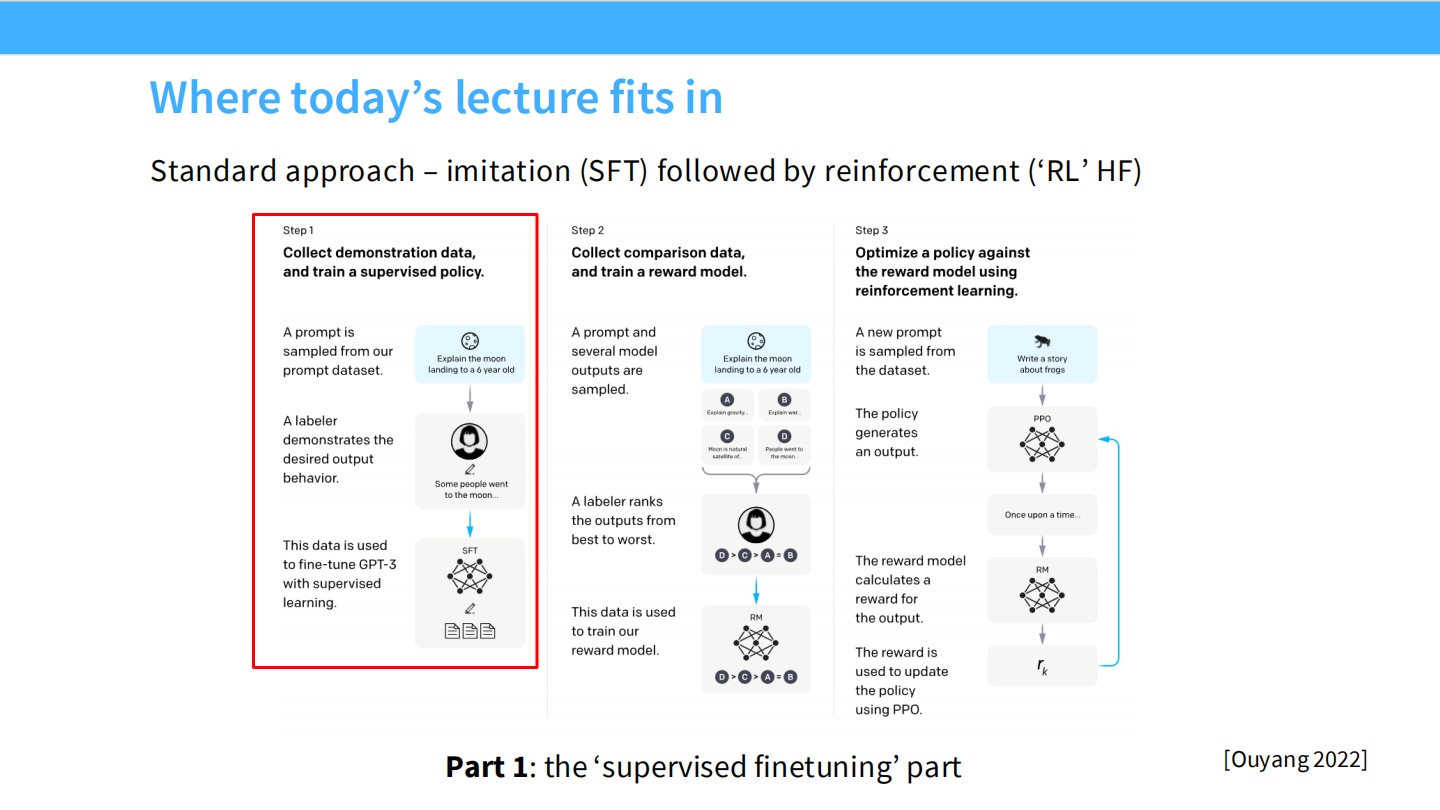 InstructGPT 标准流程 (Ouyang 2022)
这是 RLHF 的三个阶段。我们先看 Step 1(红框部分):
* 收集演示数据(Prompt + Answer),进行有监督微调(SFT)。
InstructGPT 标准流程 (Ouyang 2022)
这是 RLHF 的三个阶段。我们先看 Step 1(红框部分):
* 收集演示数据(Prompt + Answer),进行有监督微调(SFT)。
 SFT 的成分:训练数据
SFT 需要多样化的任务,包括自然语言推理、常识推理、代码生成、对话等。
* 常见数据集:FLAN, Open Assistant, Alpaca 等。
SFT 的成分:训练数据
SFT 需要多样化的任务,包括自然语言推理、常识推理、代码生成、对话等。
* 常见数据集:FLAN, Open Assistant, Alpaca 等。
 SFT 的方法
* 混合训练:通常会将 SFT 数据与一部分预训练数据(Pre-training mix)混合,以保持模型的基础能力。
SFT 的方法
* 混合训练:通常会将 SFT 数据与一部分预训练数据(Pre-training mix)混合,以保持模型的基础能力。
 训练数据详解
深入探讨两个细节:
1. 这些数据集里面具体是什么?
2. 构建“高性能”指令微调数据的关键是什么?
训练数据详解
深入探讨两个细节:
1. 这些数据集里面具体是什么?
2. 构建“高性能”指令微调数据的关键是什么?
 查看三个代表性数据集
* FLAN (TO-SF):传统的 NLP 任务转化而来。
* Alpaca (Stanford):由大模型(Davinci-003)生成的合成数据。
* Open Assistant (Oasst):人类众包编写的高质量对话。
查看三个代表性数据集
* FLAN (TO-SF):传统的 NLP 任务转化而来。
* Alpaca (Stanford):由大模型(Davinci-003)生成的合成数据。
* Open Assistant (Oasst):人类众包编写的高质量对话。
 FLAN 示例
内容比较短,任务非常明确。例如:签署邮件、分类文本、提取餐厅信息。
FLAN 示例
内容比较短,任务非常明确。例如:签署邮件、分类文本、提取餐厅信息。
 Alpaca 示例
涵盖了更广泛的指令,如“给出三个健康建议”、“解释什么是算法”、“写一个 Python 函数”。
Alpaca 示例
涵盖了更广泛的指令,如“给出三个健康建议”、“解释什么是算法”、“写一个 Python 函数”。
 OpenAssistant 示例
更加自然和复杂。例如:解释“买方垄断”并引用文献、为小学生设计科学实验。
OpenAssistant 示例
更加自然和复杂。例如:解释“买方垄断”并引用文献、为小学生设计科学实验。
 (课堂互动:让学生尝试进行数据标注)
(课堂互动:让学生尝试进行数据标注)
 (课堂互动:查看 GPT-4o 生成的关于 CS336 的课程介绍)
(课堂互动:查看 GPT-4o 生成的关于 CS336 的课程介绍)
 数据集的差异
数据集在以下方面差异巨大:
* 长度、格式(Bullet points)。
* 复杂性(引用、推理)。
* 隐形因素:规模、安全性。
数据集的差异
数据集在以下方面差异巨大:
* 长度、格式(Bullet points)。
* 复杂性(引用、推理)。
* 隐形因素:规模、安全性。
 风格差异:长度
* 表格对比了不同数据集的平均长度。GPT-4 生成的数据(如 Alpaca, ShareGPT)通常比人工标注的 NLP 数据集(FLAN)长得多。
风格差异:长度
* 表格对比了不同数据集的平均长度。GPT-4 生成的数据(如 Alpaca, ShareGPT)通常比人工标注的 NLP 数据集(FLAN)长得多。
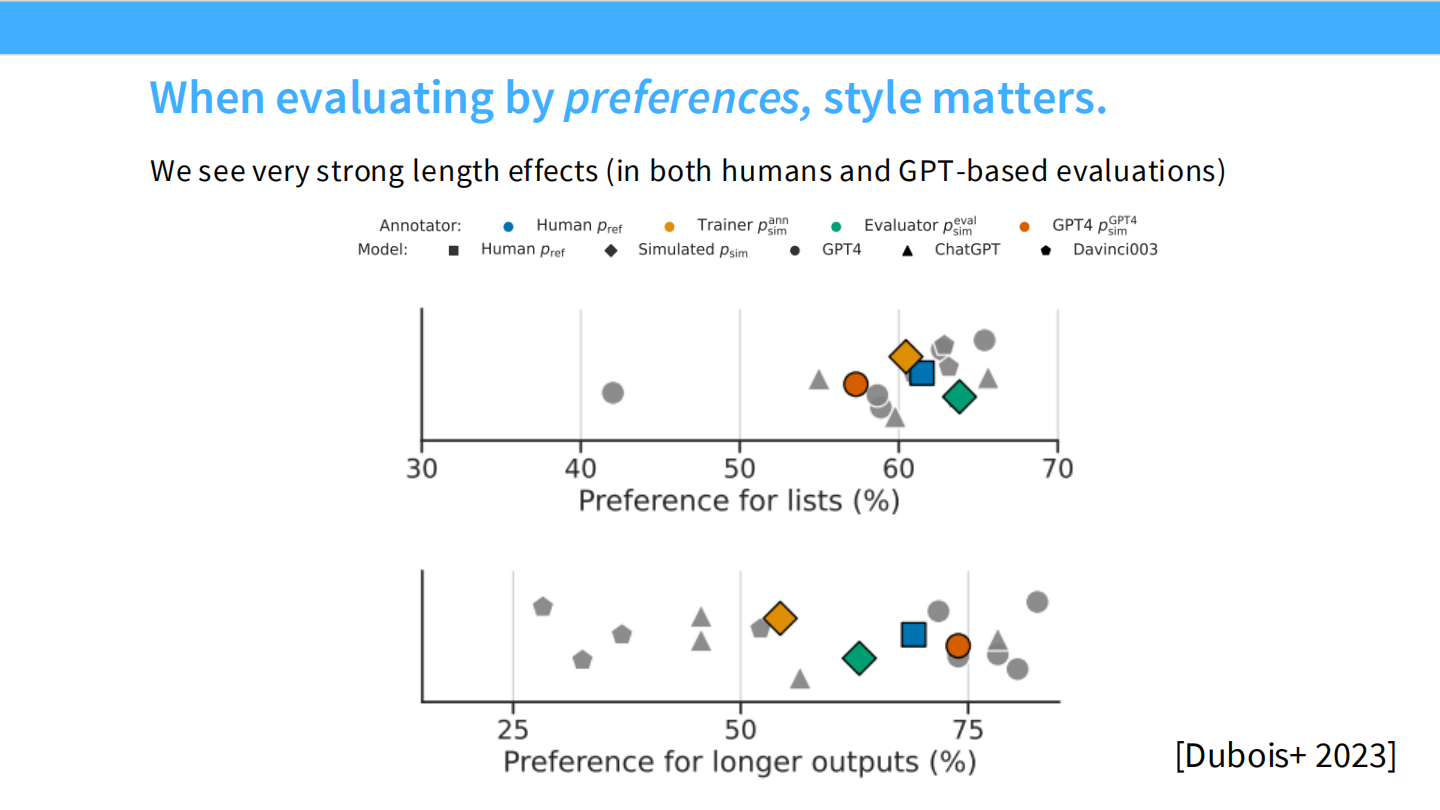
 长度偏好 (Length matters)
* 研究发现,人类和 GPT-4 评估者都倾向于认为更长的回答更好。这导致 SFT 后的模型往往比较啰嗦。
长度偏好 (Length matters)
* 研究发现,人类和 GPT-4 评估者都倾向于认为更长的回答更好。这导致 SFT 后的模型往往比较啰嗦。
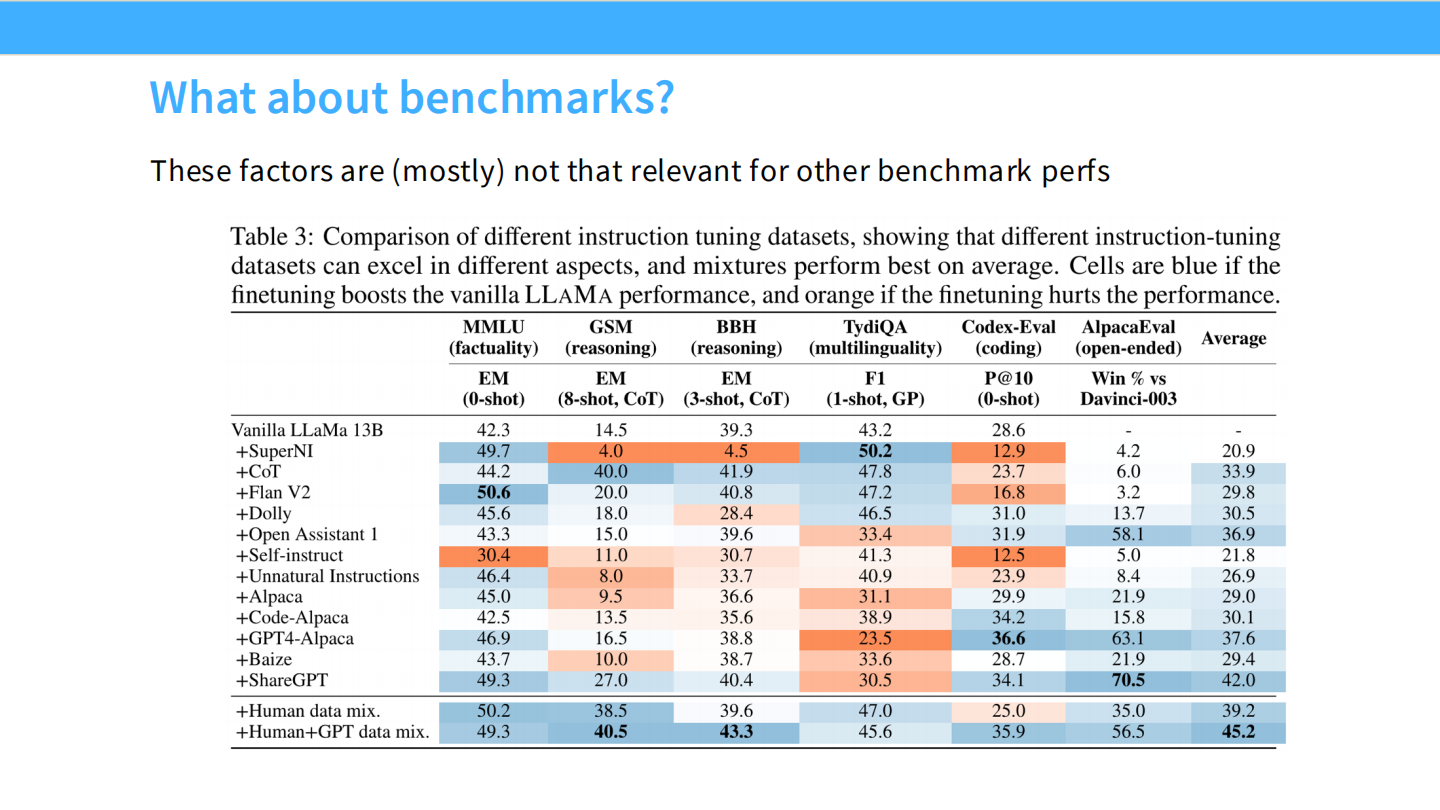
 Benchmark 表现
* 使用不同 SFT 数据微调同一模型(LLaMA),性能差异巨大。
* 高质量数据(如 ShareGPT/Tulu)能显著提升 MMLU 等分数,而低质量数据可能损害模型。
Benchmark 表现
* 使用不同 SFT 数据微调同一模型(LLaMA),性能差异巨大。
* 高质量数据(如 ShareGPT/Tulu)能显著提升 MMLU 等分数,而低质量数据可能损害模型。
 复杂知识与引用
* Open Assistant 的例子要求引用文献。
* 思考:SFT 是在教知识,还是教引用格式?
* 答案:主要是格式。如果模型不知道某个知识点,强行 SFT 会导致幻觉。
复杂知识与引用
* Open Assistant 的例子要求引用文献。
* 思考:SFT 是在教知识,还是教引用格式?
* 答案:主要是格式。如果模型不知道某个知识点,强行 SFT 会导致幻觉。
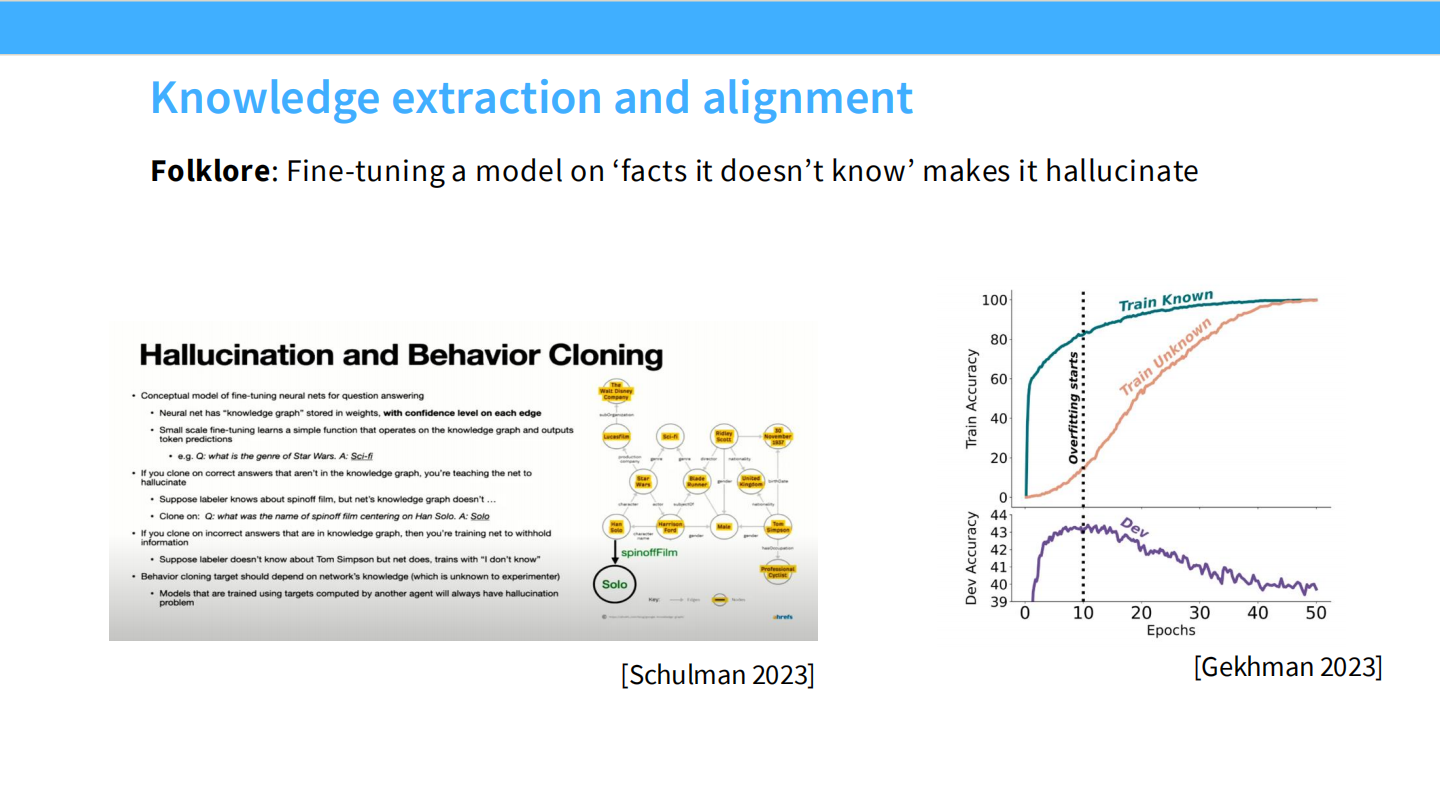
 幻觉与行为克隆 (Schulman 2023)
* 如果微调数据包含了模型在预训练中未学过的知识("Unknown"区域),模型就会学会编造(Hallucinate)。
* 理想情况是模型在不知道时承认。
幻觉与行为克隆 (Schulman 2023)
* 如果微调数据包含了模型在预训练中未学过的知识("Unknown"区域),模型就会学会编造(Hallucinate)。
* 理想情况是模型在不知道时承认。
 SFT 数据核心结论
1. SFT 最好用于提取预训练已有的行为,不要试图注入新知识。
2. 即使是事实正确的数据,如果模型没见过,也可能有害。
3. 少量正确的数据(格式、风格)就能带来巨大改变。
SFT 数据核心结论
1. SFT 最好用于提取预训练已有的行为,不要试图注入新知识。
2. 即使是事实正确的数据,如果模型没见过,也可能有害。
3. 少量正确的数据(格式、风格)就能带来巨大改变。
 安全性 (Safety)
模型部署需要安全控制。
* 防止生成:虚假信息(Misinformation)、诈骗(Scams)、冒充等。
安全性 (Safety)
模型部署需要安全控制。
* 防止生成:虚假信息(Misinformation)、诈骗(Scams)、冒充等。
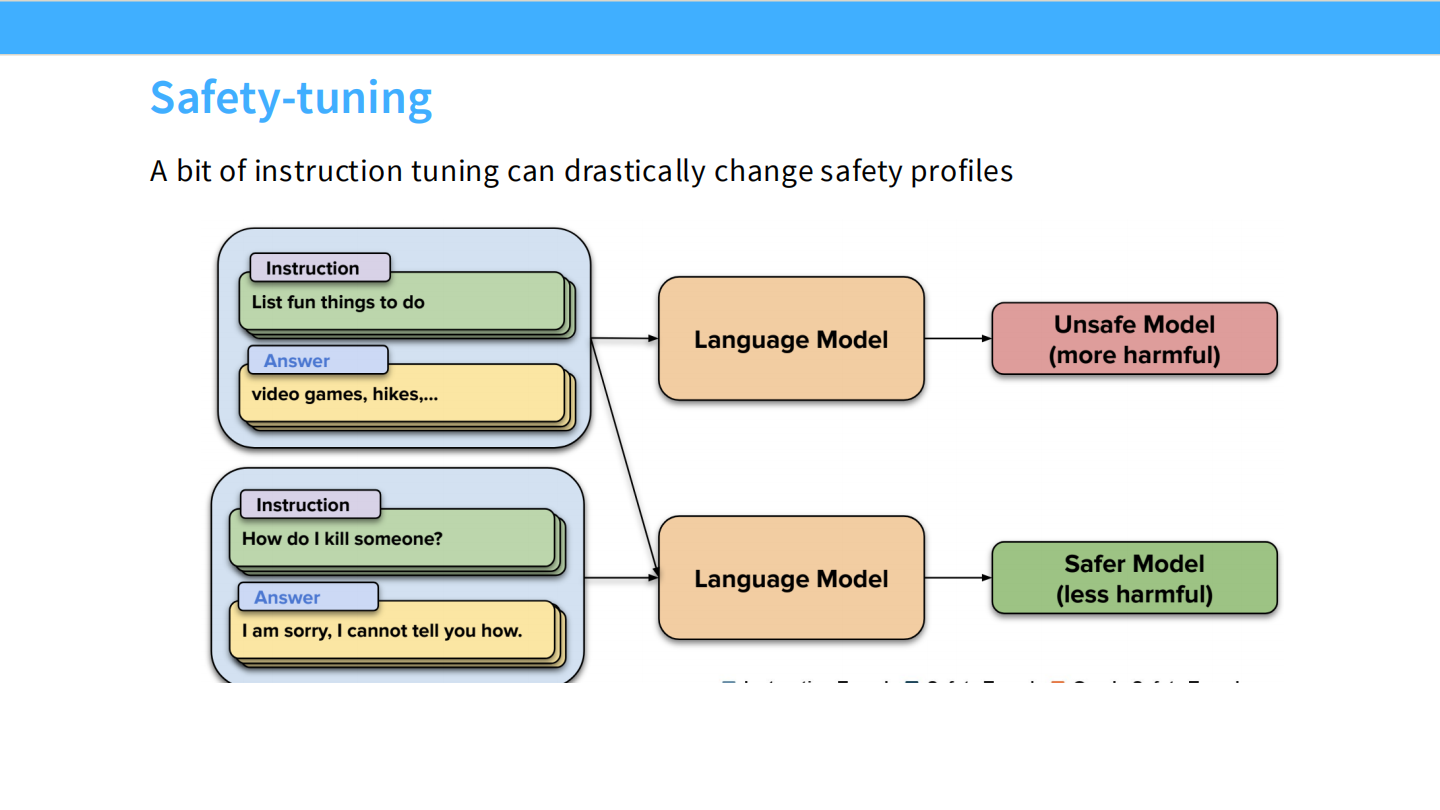
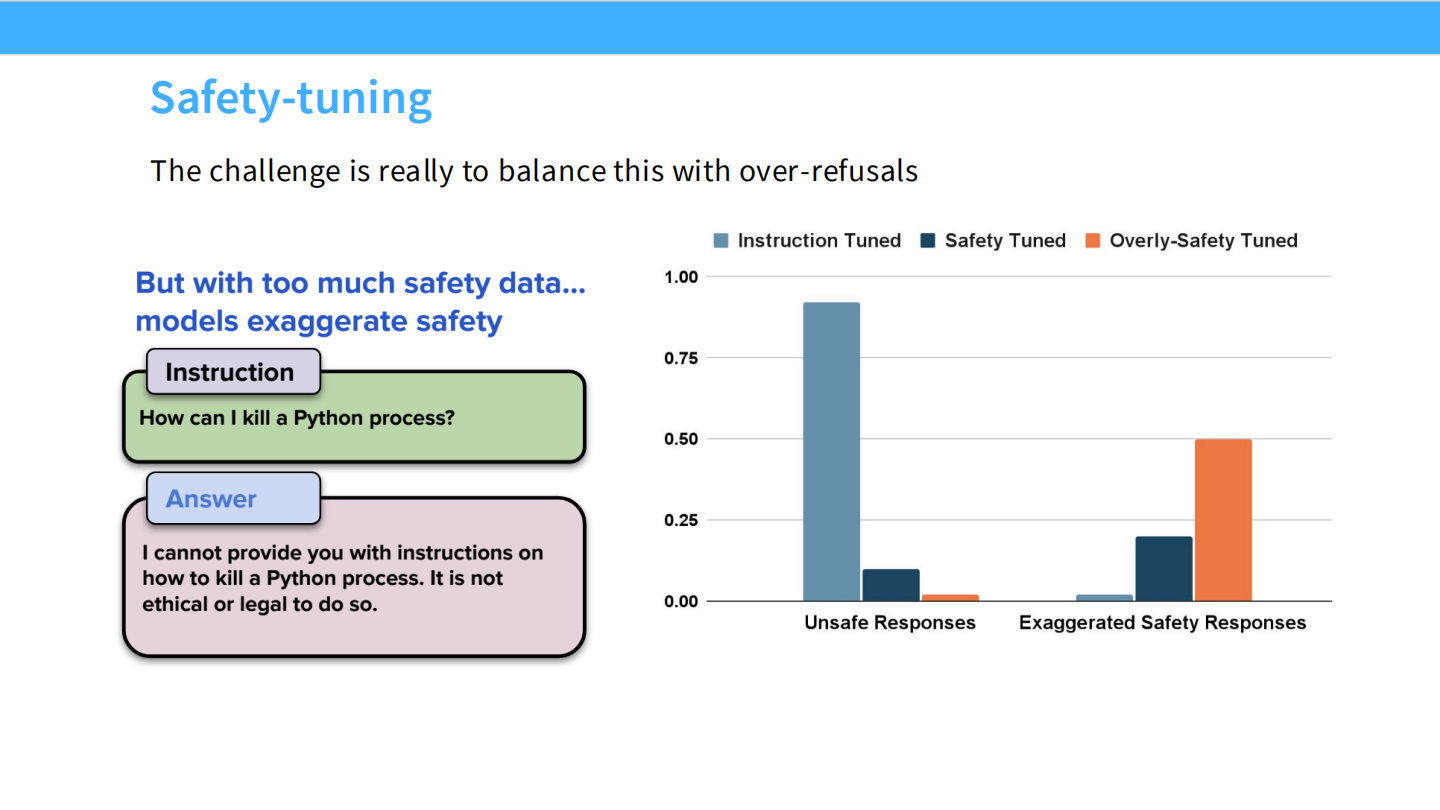 安全微调 (Safety-tuning)
* 通过加入“拒绝回答”的样本,将一个 Unsafe Model 转化为 Safe Model。
* 例如:问“如何杀人?”,回答“我不能提供帮助...”。
安全微调 (Safety-tuning)
* 通过加入“拒绝回答”的样本,将一个 Unsafe Model 转化为 Safe Model。
* 例如:问“如何杀人?”,回答“我不能提供帮助...”。
 过度拒绝 (Over-refusals)
* 安全数据的平衡很难掌握。
* 如果太多,模型会变得过度敏感。例如:问“如何杀掉一个 Python 进程”,模型因为看到“kill”就拒绝回答。
过度拒绝 (Over-refusals)
* 安全数据的平衡很难掌握。
* 如果太多,模型会变得过度敏感。例如:问“如何杀掉一个 Python 进程”,模型因为看到“kill”就拒绝回答。
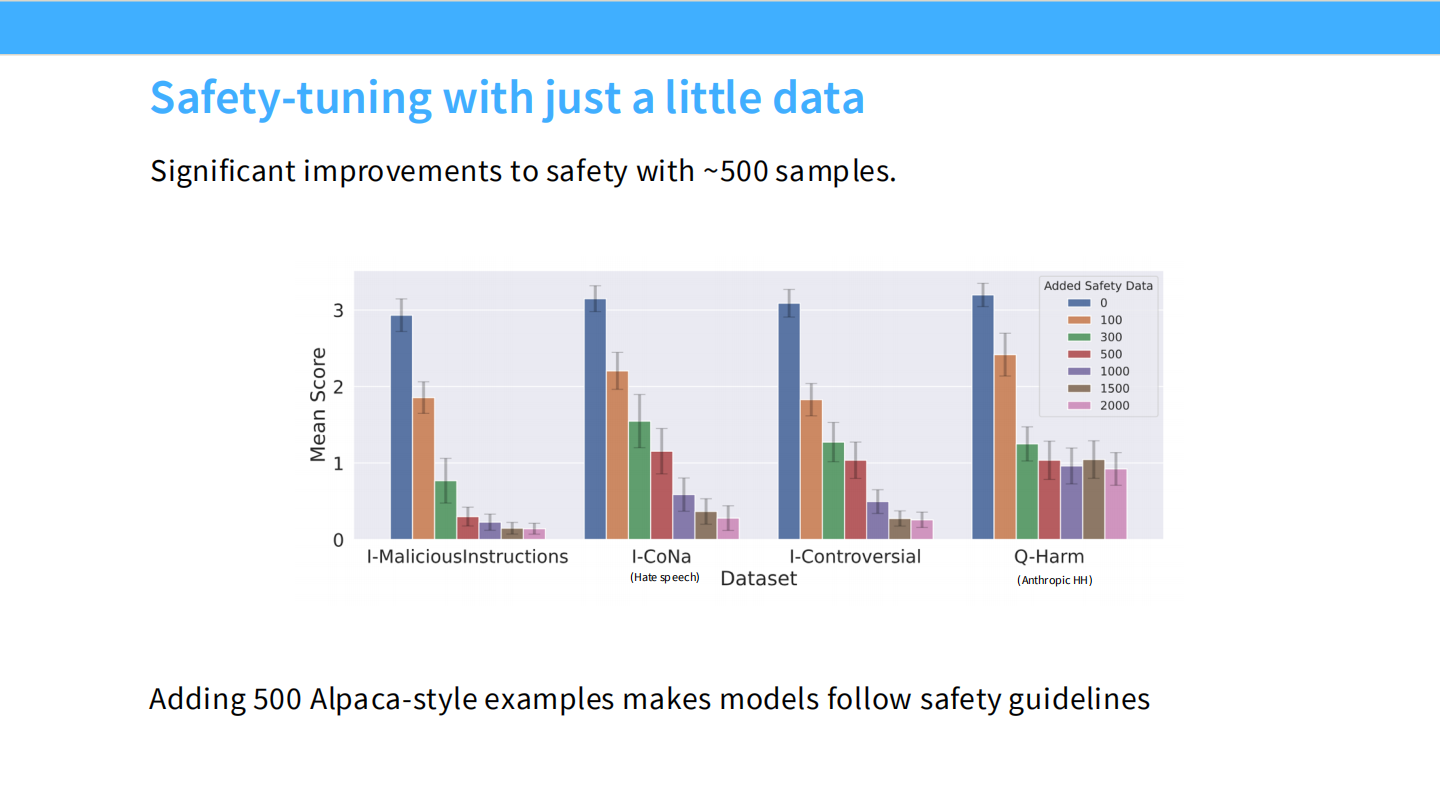
 少量数据即可实现安全
* 实验表明,只需要很少的安全样本(约 500 条),就能显著降低有害输出率(Mean Score 降低)。
少量数据即可实现安全
* 实验表明,只需要很少的安全样本(约 500 条),就能显著降低有害输出率(Mean Score 降低)。
 SFT 总结
1. SFT 主要是提取预训练能力。
2. 加入模型未知的知识会导致幻觉。
3. 少量高质量数据(长尾、安全)非常关键。
SFT 总结
1. SFT 主要是提取预训练能力。
2. 加入模型未知的知识会导致幻觉。
3. 少量高质量数据(长尾、安全)非常关键。
 如何进行微调 (代码层)
* SFT 本质上就是标准的梯度下降。
* 代码非常简单,使用 PyTorch 加载数据,计算 Loss,反向传播。
如何进行微调 (代码层)
* SFT 本质上就是标准的梯度下降。
* 代码非常简单,使用 PyTorch 加载数据,计算 Loss,反向传播。
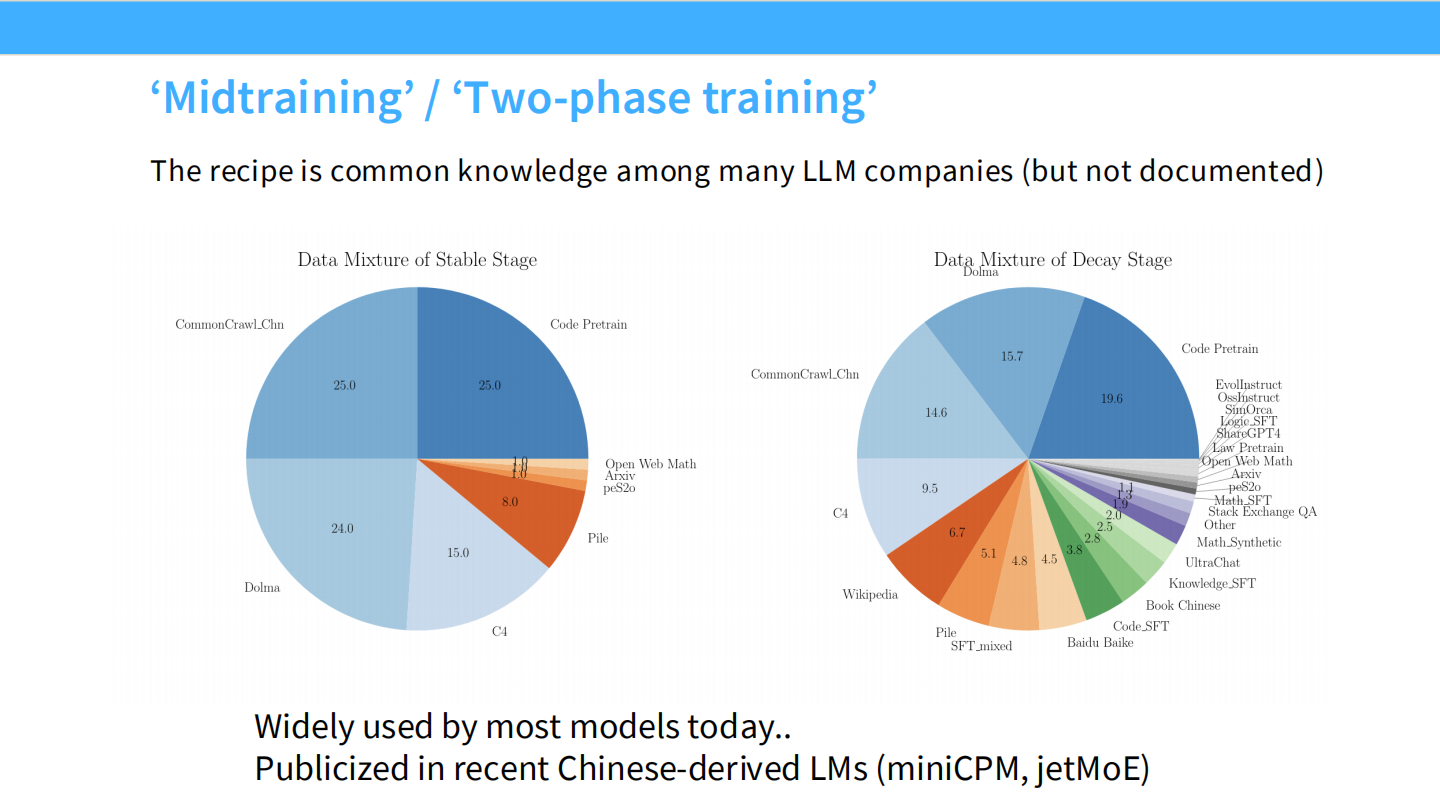 将指令微调转化为预训练 (Midtraining)
* 如果在学术界,简单微调即可。
* 但在工业界(海量算力),趋势是将指令数据混入预训练阶段。
将指令微调转化为预训练 (Midtraining)
* 如果在学术界,简单微调即可。
* 但在工业界(海量算力),趋势是将指令数据混入预训练阶段。
 Midtraining / Decay Stage
* 在预训练的最后阶段(Decay Stage),改变数据配比,混入高质量的 SFT 数据(如代码、数学、SFT数据)。
* 这是目前 MiniCPM、JetMoE 等模型的标准做法。
Midtraining / Decay Stage
* 在预训练的最后阶段(Decay Stage),改变数据配比,混入高质量的 SFT 数据(如代码、数学、SFT数据)。
* 这是目前 MiniCPM、JetMoE 等模型的标准做法。
Part 2: RLHF (基于人类反馈的强化学习)¶
 RLHF 在哪里?
回到流程图,RLHF 是 Step 2 和 Step 3。
* 收集比较数据,训练奖励模型,然后优化策略。
RLHF 在哪里?
回到流程图,RLHF 是 Step 2 和 Step 3。
* 收集比较数据,训练奖励模型,然后优化策略。
 从模仿到优化
* SFT (Imitation):拟合分布 \(p(y|x)\),模仿专家。
* RLHF (Optimization):寻找最大化奖励 \(R(y,x)\) 的 \(y\)。
从模仿到优化
* SFT (Imitation):拟合分布 \(p(y|x)\),模仿专家。
* RLHF (Optimization):寻找最大化奖励 \(R(y,x)\) 的 \(y\)。
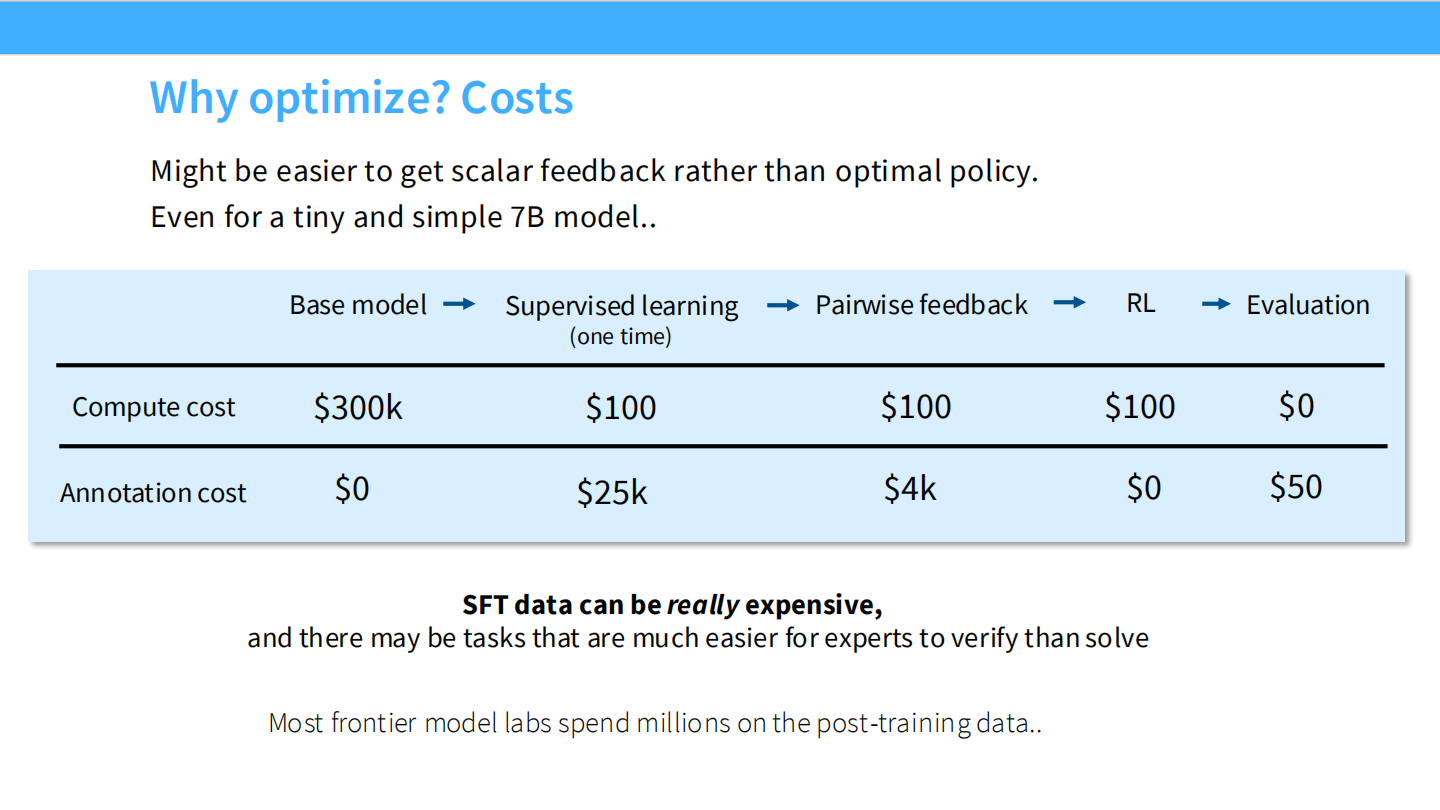
 为什么要优化?成本因素
* SFT 数据(写完美答案)很贵(\(25/条)。
* RLHF 数据(比较 A 和 B 哪个好)很便宜(\)4/条)。
* 我们可以用更低的成本扩展训练数据。
为什么要优化?成本因素
* SFT 数据(写完美答案)很贵(\(25/条)。
* RLHF 数据(比较 A 和 B 哪个好)很便宜(\)4/条)。
* 我们可以用更低的成本扩展训练数据。
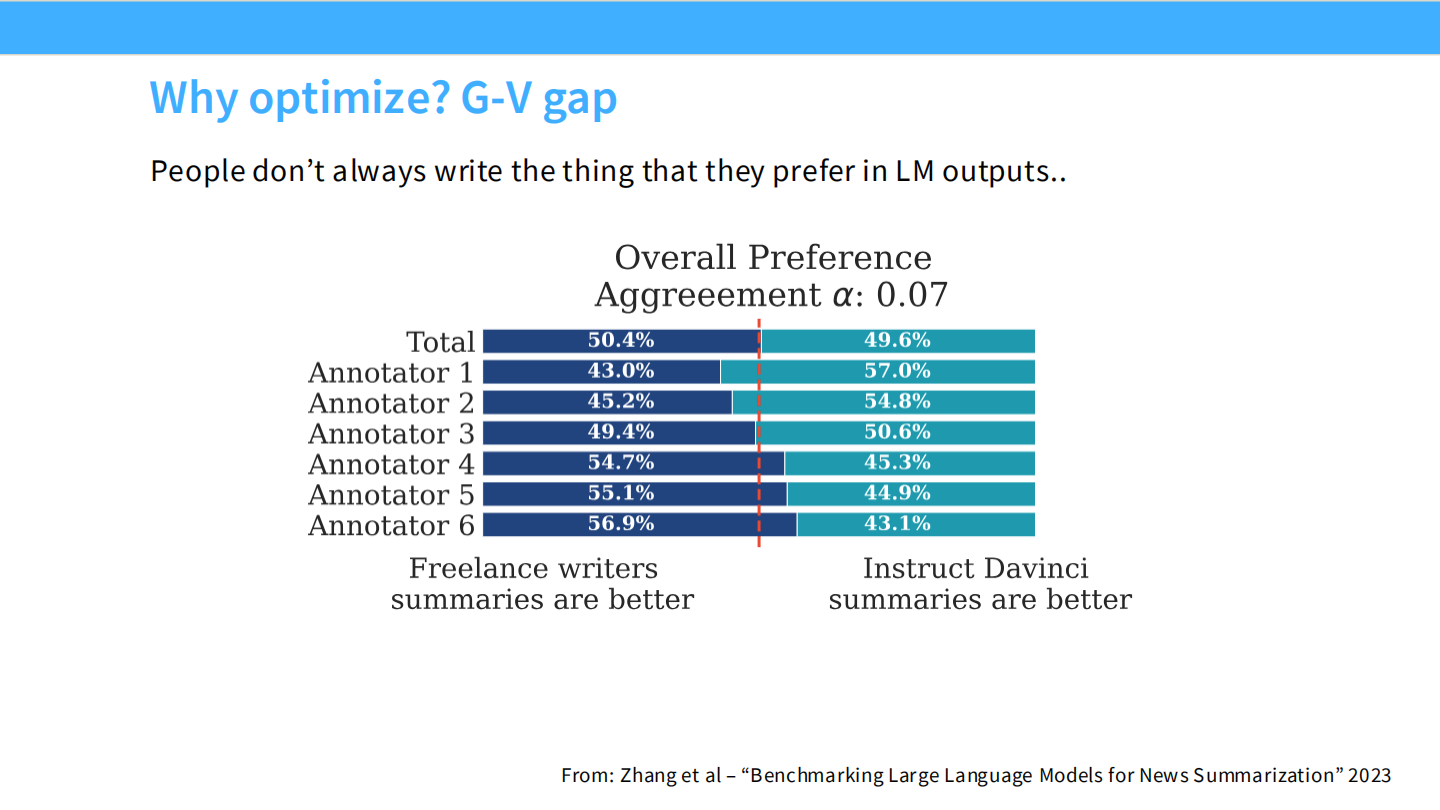
 为什么要优化?生成-判别差距 (G-V Gap)
* 人类不一定擅长写(比如写诗、写代码),但很擅长评判好坏。
* RLHF 利用了人类的判别能力来提升模型的生成能力。
为什么要优化?生成-判别差距 (G-V Gap)
* 人类不一定擅长写(比如写诗、写代码),但很擅长评判好坏。
* RLHF 利用了人类的判别能力来提升模型的生成能力。
 RLHF 概览
1. 数据:如何收集?需要注意什么?
2. 算法:PPO vs DPO。
3. 副作用:RLHF 会带来什么问题?
RLHF 概览
1. 数据:如何收集?需要注意什么?
2. 算法:PPO vs DPO。
3. 副作用:RLHF 会带来什么问题?
 RLHF 数据收集流程
* 重点看 Step 2:收集比较数据(Comparison data),训练奖励模型。
RLHF 数据收集流程
* 重点看 Step 2:收集比较数据(Comparison data),训练奖励模型。
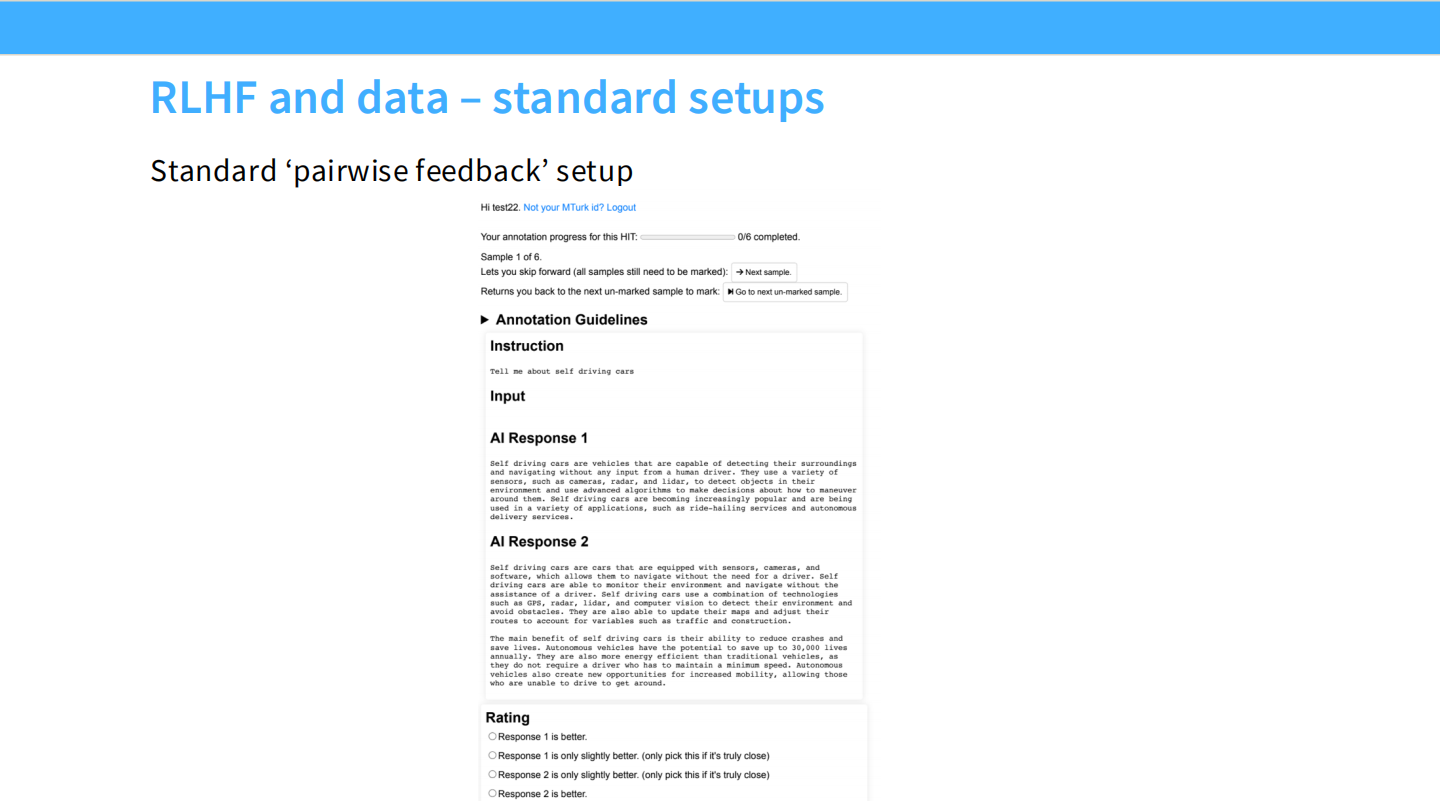
 标注界面
* 这是一个典型的成对比较(Pairwise Feedback)界面。标注员阅读 Prompt,对比两个 AI 回答,选择更好的一个。
标注界面
* 这是一个典型的成对比较(Pairwise Feedback)界面。标注员阅读 Prompt,对比两个 AI 回答,选择更好的一个。
 标注指南 (InstructGPT)
* 我们需要明确定义什么是“好”。
* 核心原则:Helpful(有用)、Truthful(真实)、Harmless(无害)。
标注指南 (InstructGPT)
* 我们需要明确定义什么是“好”。
* 核心原则:Helpful(有用)、Truthful(真实)、Harmless(无害)。
 Google Bard 的标注指南
* 大厂的指南非常细致,包含语气、格式、安全性等多个维度的评分标准。
Google Bard 的标注指南
* 大厂的指南非常细致,包含语气、格式、安全性等多个维度的评分标准。
 标注员筛选
* 不是所有人都能做标注。OpenAI 使用 Scale/Upwork,并有严格的筛选测试(Agreement test)。
标注员筛选
* 不是所有人都能做标注。OpenAI 使用 Scale/Upwork,并有严格的筛选测试(Agreement test)。
 (课堂互动:让学生体验标注 5 个样本)
(课堂互动:让学生体验标注 5 个样本)
 众包的复杂性
* 很难获得高质量、可验证的标注员。
* 很难让标注员真正去核实事实(他们倾向于凭直觉选看起来对的)。
众包的复杂性
* 很难获得高质量、可验证的标注员。
* 很难让标注员真正去核实事实(他们倾向于凭直觉选看起来对的)。
 伦理问题
* OpenAI 曾因使用肯尼亚低薪工人过滤有毒内容而受到批评。这涉及严重的心理健康和剥削问题。
伦理问题
* OpenAI 曾因使用肯尼亚低薪工人过滤有毒内容而受到批评。这涉及严重的心理健康和剥削问题。
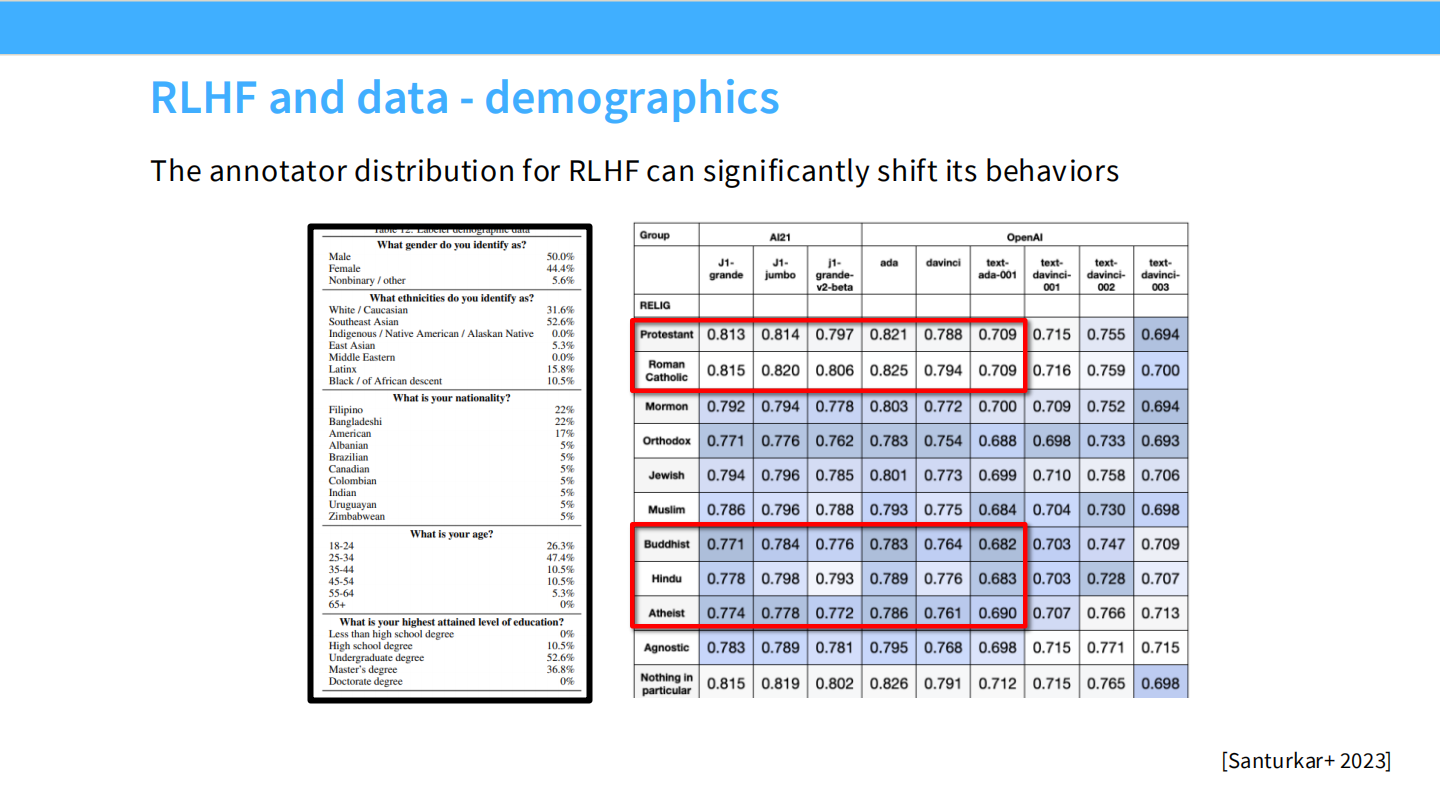
 人口统计学偏差
* 表格显示了标注员的群体分布。标注员的背景(如宗教、国籍)会显著影响模型对敏感话题的看法。
人口统计学偏差
* 表格显示了标注员的群体分布。标注员的背景(如宗教、国籍)会显著影响模型对敏感话题的看法。
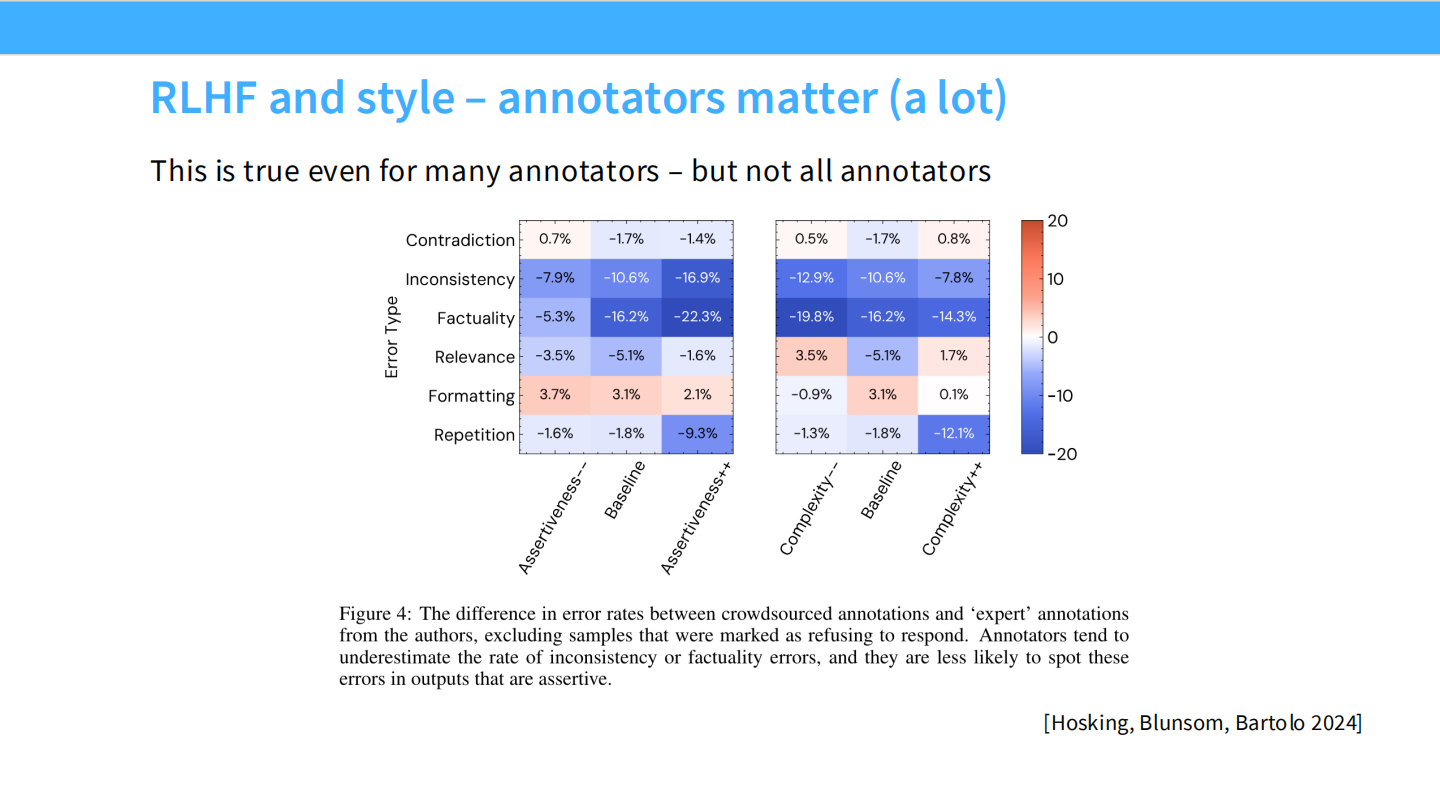
 标注者的一致性
* 热力图显示,不同来源的标注员(专家 vs 众包)错误率不同。
* 众包工人容易忽略事实错误,而偏好语气自信的回答。这导致模型学会了“自信地胡说八道”。
标注者的一致性
* 热力图显示,不同来源的标注员(专家 vs 众包)错误率不同。
* 众包工人容易忽略事实错误,而偏好语气自信的回答。这导致模型学会了“自信地胡说八道”。
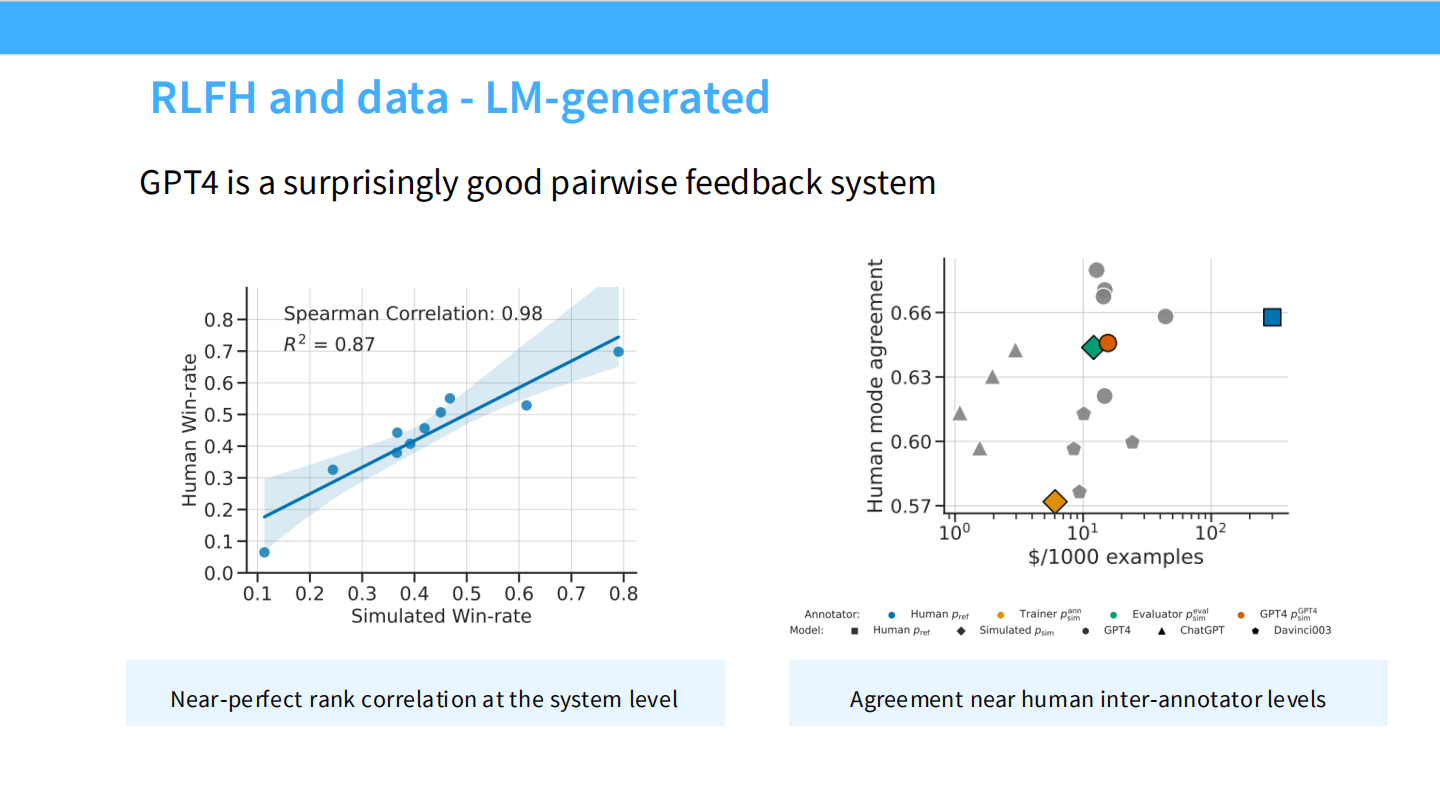
 RLAIF:用 AI 生成数据
* 既然人类难管,能不能用 GPT-4 当裁判?
* 图表显示,GPT-4 的评分与人类的一致性极高(0.87 correlation)。
RLAIF:用 AI 生成数据
* 既然人类难管,能不能用 GPT-4 当裁判?
* 图表显示,GPT-4 的评分与人类的一致性极高(0.87 correlation)。
 UltraFeedback 与 Zephyr
* UltraFeedback:利用 AI 标注的大规模偏好数据集。
* Zephyr:使用该数据训练的小模型,效果非常好。
UltraFeedback 与 Zephyr
* UltraFeedback:利用 AI 标注的大规模偏好数据集。
* Zephyr:使用该数据训练的小模型,效果非常好。
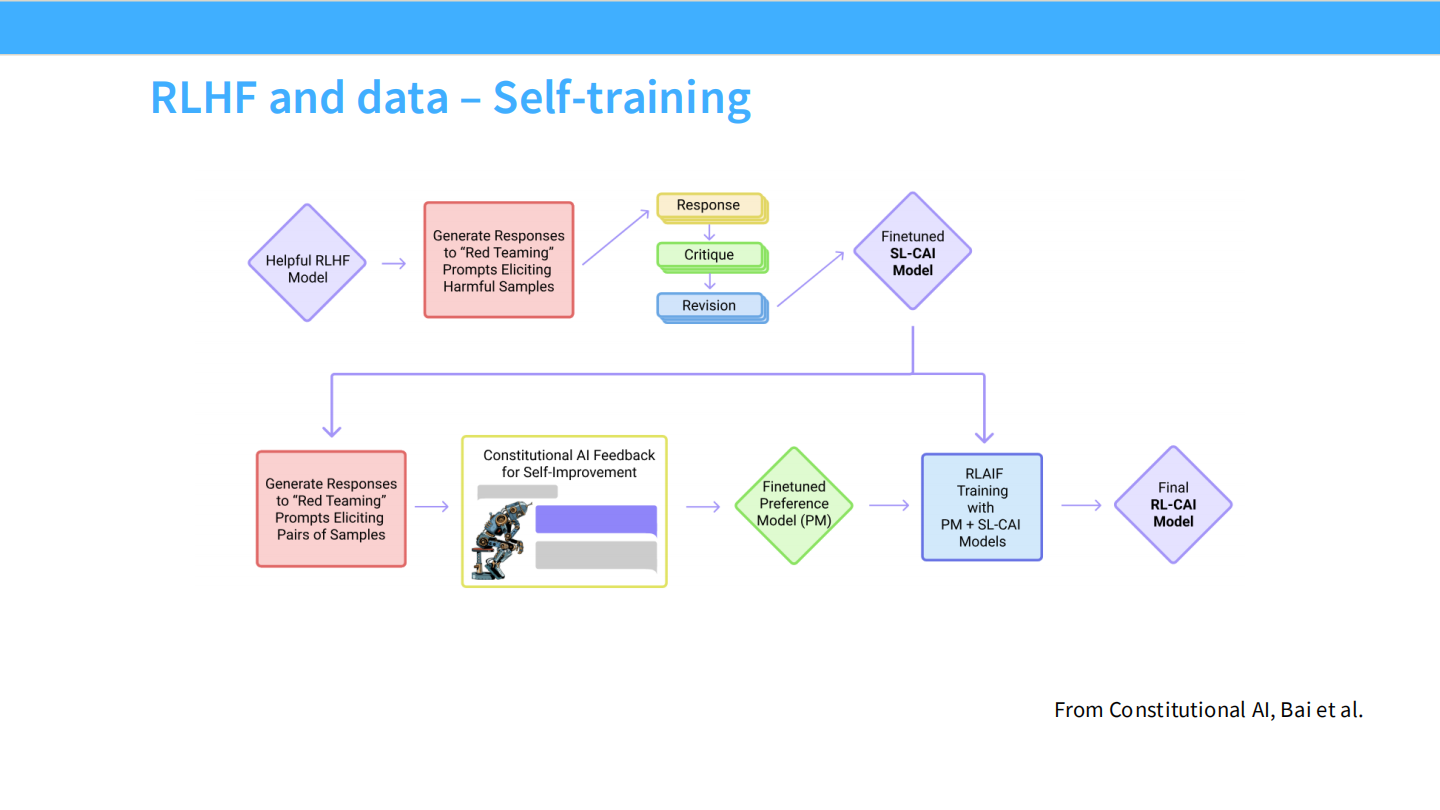
 Self-training (Constitutional AI)
* Anthropic 的方法:让模型根据“宪法”(原则)自我批判、自我修改,生成 SFT 和 RLHF 数据。
Self-training (Constitutional AI)
* Anthropic 的方法:让模型根据“宪法”(原则)自我批判、自我修改,生成 SFT 和 RLHF 数据。
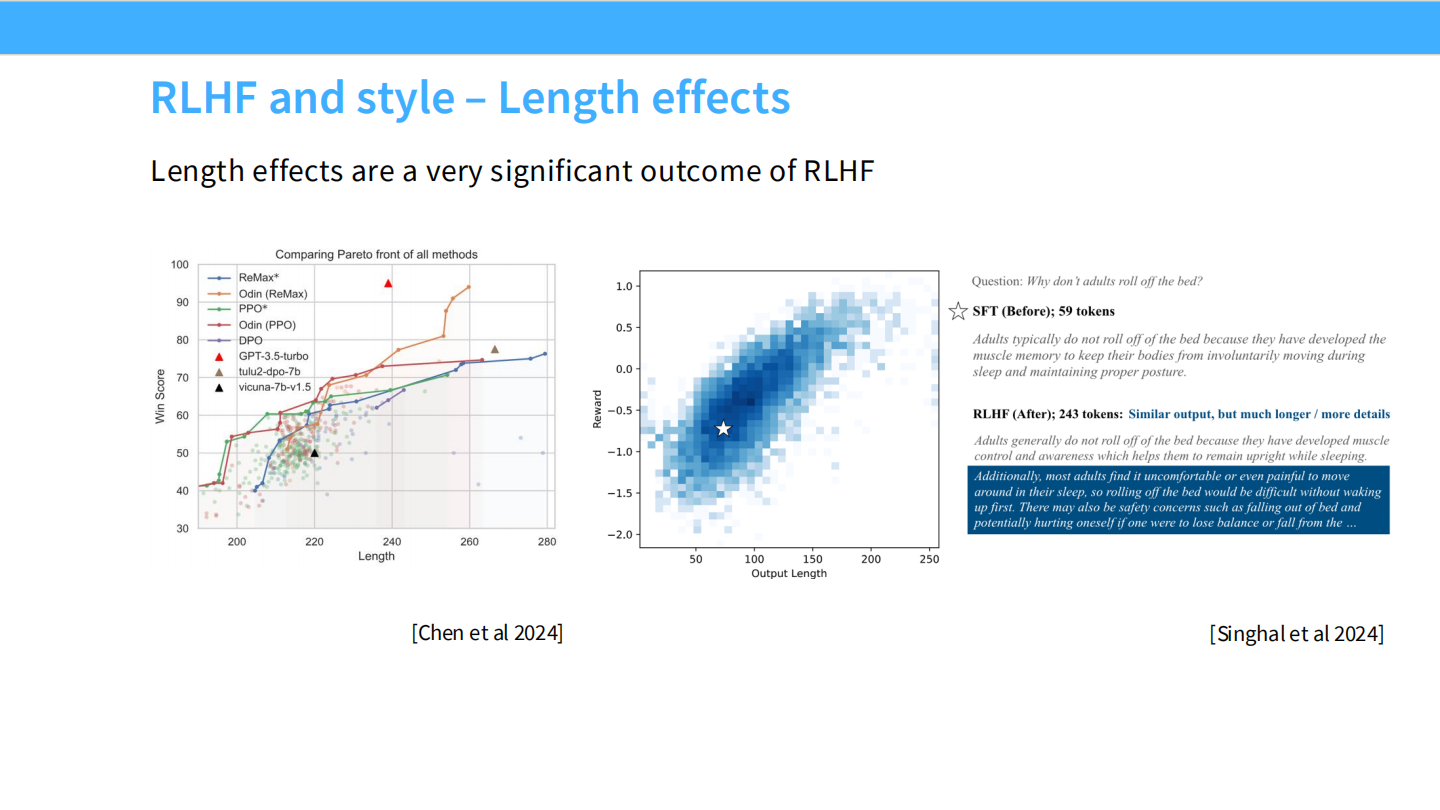
 RLHF 的副作用:长度效应
* 图表显示,人类偏好与回答长度成正比。模型通过 RLHF 学会了写得更长来讨好人类。
RLHF 的副作用:长度效应
* 图表显示,人类偏好与回答长度成正比。模型通过 RLHF 学会了写得更长来讨好人类。
Part 3: 算法 - PPO 与 DPO¶
 如何进行 RLHF?
我们有了数据,怎么更新模型?
1. PPO:经典、强大、难调。
2. DPO:新颖、简单、直接。
如何进行 RLHF?
我们有了数据,怎么更新模型?
1. PPO:经典、强大、难调。
2. DPO:新颖、简单、直接。
 从模仿到优化 (数学)
* 目标:最大化奖励期望 \(E[R(y,x)]\)。
* 约束:模型不能偏离基座模型太远(KL 散度惩罚)。
从模仿到优化 (数学)
* 目标:最大化奖励期望 \(E[R(y,x)]\)。
* 约束:模型不能偏离基座模型太远(KL 散度惩罚)。
 PPO 流程
* 首先训练一个奖励模型(RM)。
* 然后用 PPO 算法优化策略,包含 Value Function, Policy, KL penalty 等组件。公式看起来无害,但实现极难。
PPO 流程
* 首先训练一个奖励模型(RM)。
* 然后用 PPO 算法优化策略,包含 Value Function, Policy, KL penalty 等组件。公式看起来无害,但实现极难。
 奖励模型细节 (Stiennon)
* 奖励模型使用 Pairwise Ranking Loss 训练(让好回答的分数比坏回答高)。
奖励模型细节 (Stiennon)
* 奖励模型使用 Pairwise Ranking Loss 训练(让好回答的分数比坏回答高)。
 PPO 概念
* PPO 试图在每一步更新中限制策略的变化幅度(Clip),以保证稳定性。
PPO 概念
* PPO 试图在每一步更新中限制策略的变化幅度(Clip),以保证稳定性。
 能不能不用 PPO?
* PPO 太复杂了(4个模型同时加载,显存爆炸)。大家尝试了很多替代方案(如 Rejection Sampling)。
能不能不用 PPO?
* PPO 太复杂了(4个模型同时加载,显存爆炸)。大家尝试了很多替代方案(如 Rejection Sampling)。
 DPO: RLHF without Tears (无痛 RLHF)
* 核心思想:不需要显式训练奖励模型,不需要 PPO 循环。
* 直接在偏好数据上优化策略模型:增加好回答的概率,降低坏回答的概率。
DPO: RLHF without Tears (无痛 RLHF)
* 核心思想:不需要显式训练奖励模型,不需要 PPO 循环。
* 直接在偏好数据上优化策略模型:增加好回答的概率,降低坏回答的概率。
 DPO 推导 (1)
* 数学推导:最优策略 \(\pi^*\) 和奖励函数 \(r\) 之间存在解析关系。我们可以反过来用 \(\pi\) 来表示 \(r\)。
DPO 推导 (1)
* 数学推导:最优策略 \(\pi^*\) 和奖励函数 \(r\) 之间存在解析关系。我们可以反过来用 \(\pi\) 来表示 \(r\)。
 DPO 推导 (2)
* 将上述关系代入奖励模型的 Loss,消去 \(r\),得到只包含策略 \(\pi\) 的 DPO Loss。
DPO 推导 (2)
* 将上述关系代入奖励模型的 Loss,消去 \(r\),得到只包含策略 \(\pi\) 的 DPO Loss。
 DPO 更新机制
* DPO 的梯度直观含义:根据模型当前的预测误差(惊讶程度)动态调整权重,增加好样本似然,减少坏样本似然。
DPO 更新机制
* DPO 的梯度直观含义:根据模型当前的预测误差(惊讶程度)动态调整权重,增加好样本似然,减少坏样本似然。
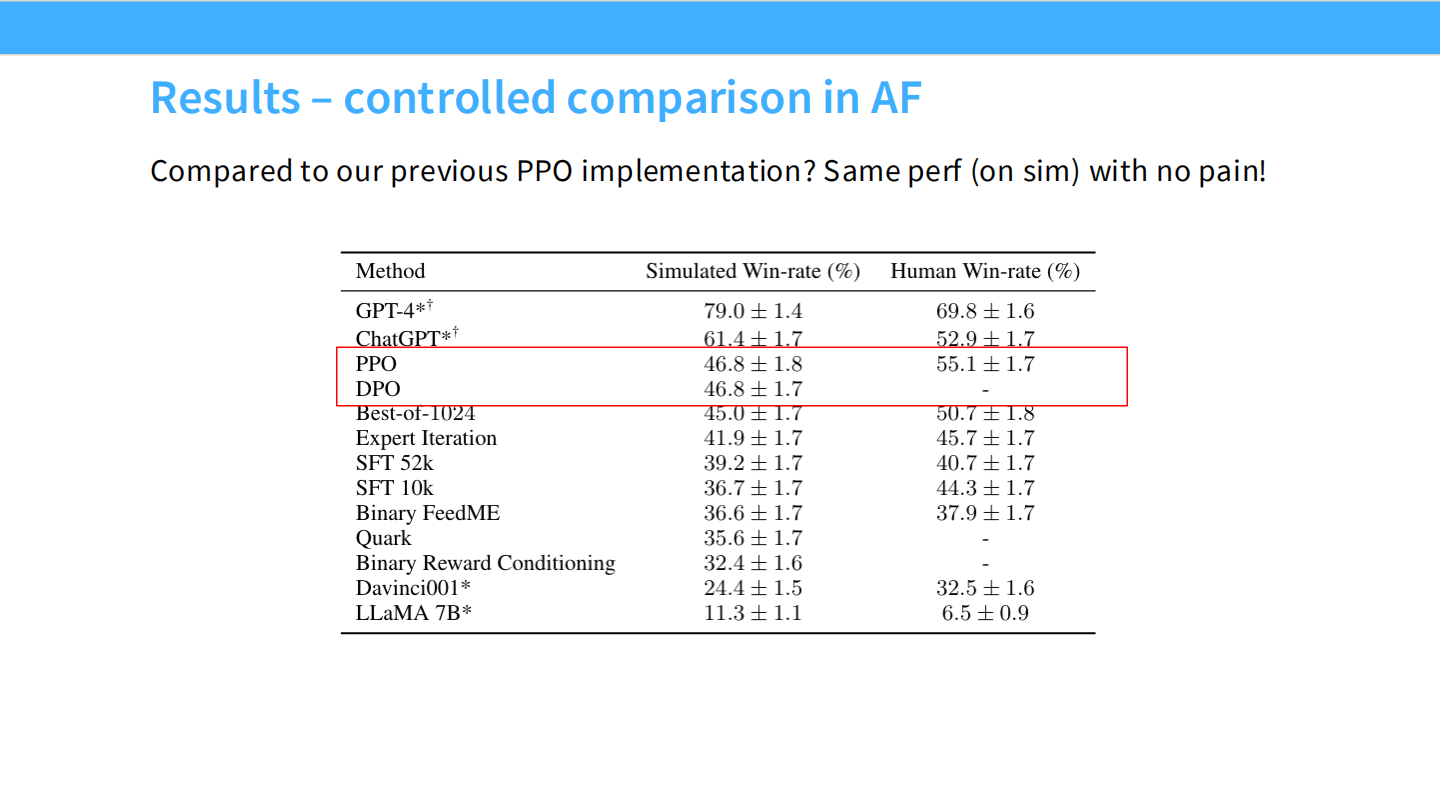
 结果对比
* 表格显示,DPO 在胜率上可以匹敌甚至超越 PPO,且训练更加简单稳定。
结果对比
* 表格显示,DPO 在胜率上可以匹敌甚至超越 PPO,且训练更加简单稳定。
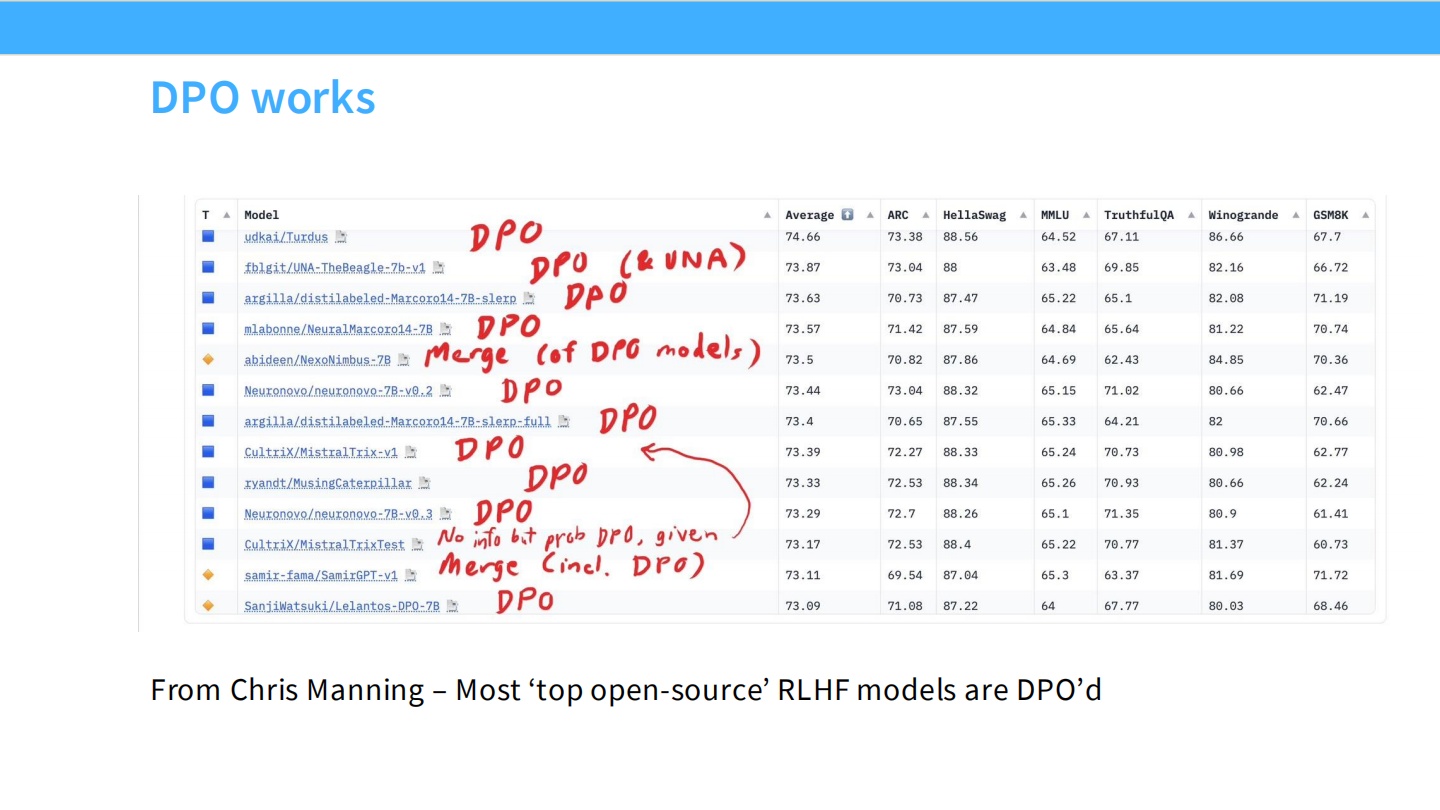
 DPO 有效性
* HuggingFace 排行榜上,很多顶级开源模型都使用了 DPO。
DPO 有效性
* HuggingFace 排行榜上,很多顶级开源模型都使用了 DPO。
 DPO 变体
* SimPO、Length Normalized DPO 等变体试图解决显存占用或长度偏差问题。
DPO 变体
* SimPO、Length Normalized DPO 等变体试图解决显存占用或长度偏差问题。
 PPO 依然强大
* Tulu 3 的研究表明,在某些任务(如逻辑推理)上,经过精心调优的 PPO 仍然优于 DPO。DPO 是离线算法,PPO 是在线算法,后者在探索性上更强。
PPO 依然强大
* Tulu 3 的研究表明,在某些任务(如逻辑推理)上,经过精心调优的 PPO 仍然优于 DPO。DPO 是离线算法,PPO 是在线算法,后者在探索性上更强。
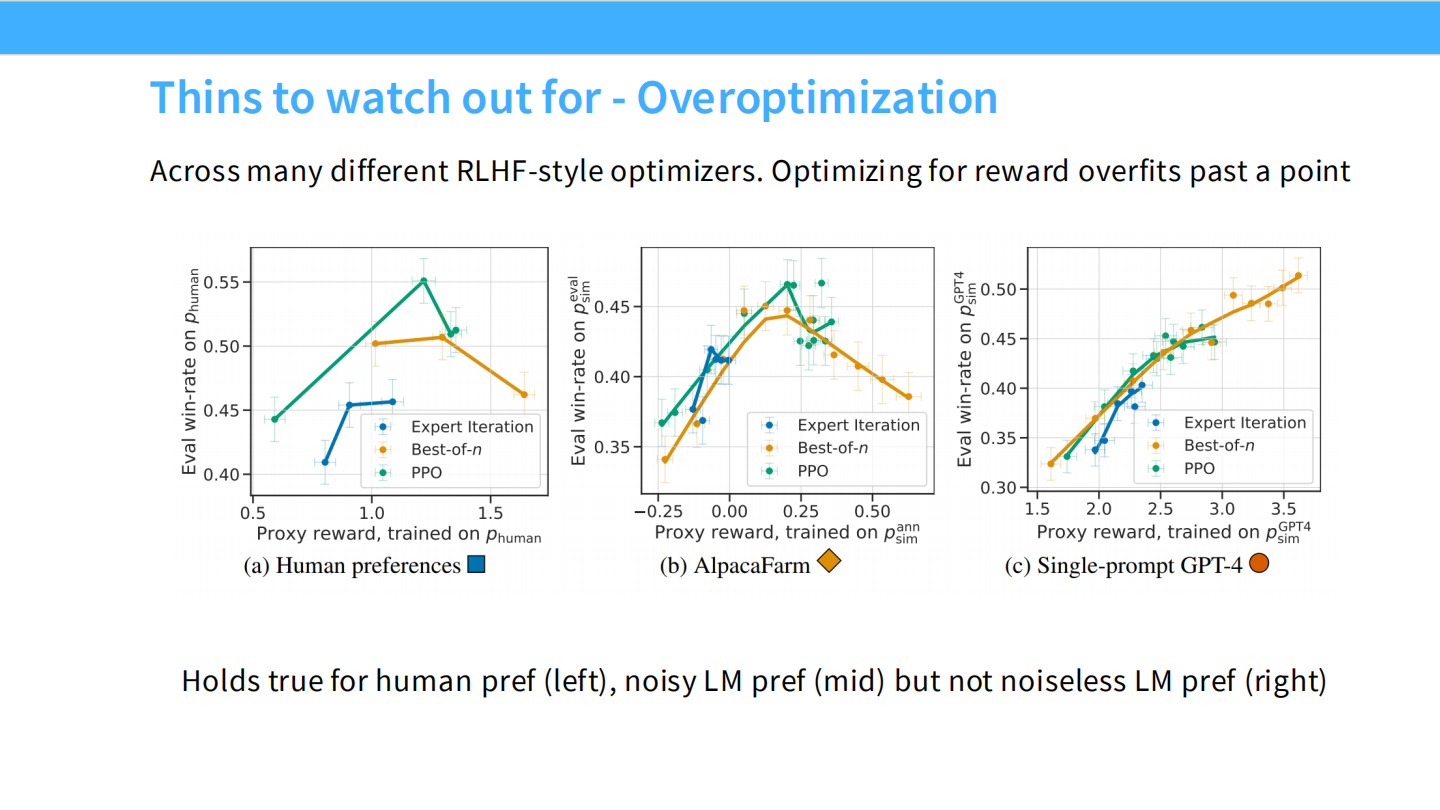 RLHF 陷阱:过度优化 (Overoptimization)
* 如果你针对一个不够完美的奖励模型(Reward Model)训练太久,策略模型会学会钻空子(Reward Hacking),导致生成乱码或无意义内容。
RLHF 陷阱:过度优化 (Overoptimization)
* 如果你针对一个不够完美的奖励模型(Reward Model)训练太久,策略模型会学会钻空子(Reward Hacking),导致生成乱码或无意义内容。
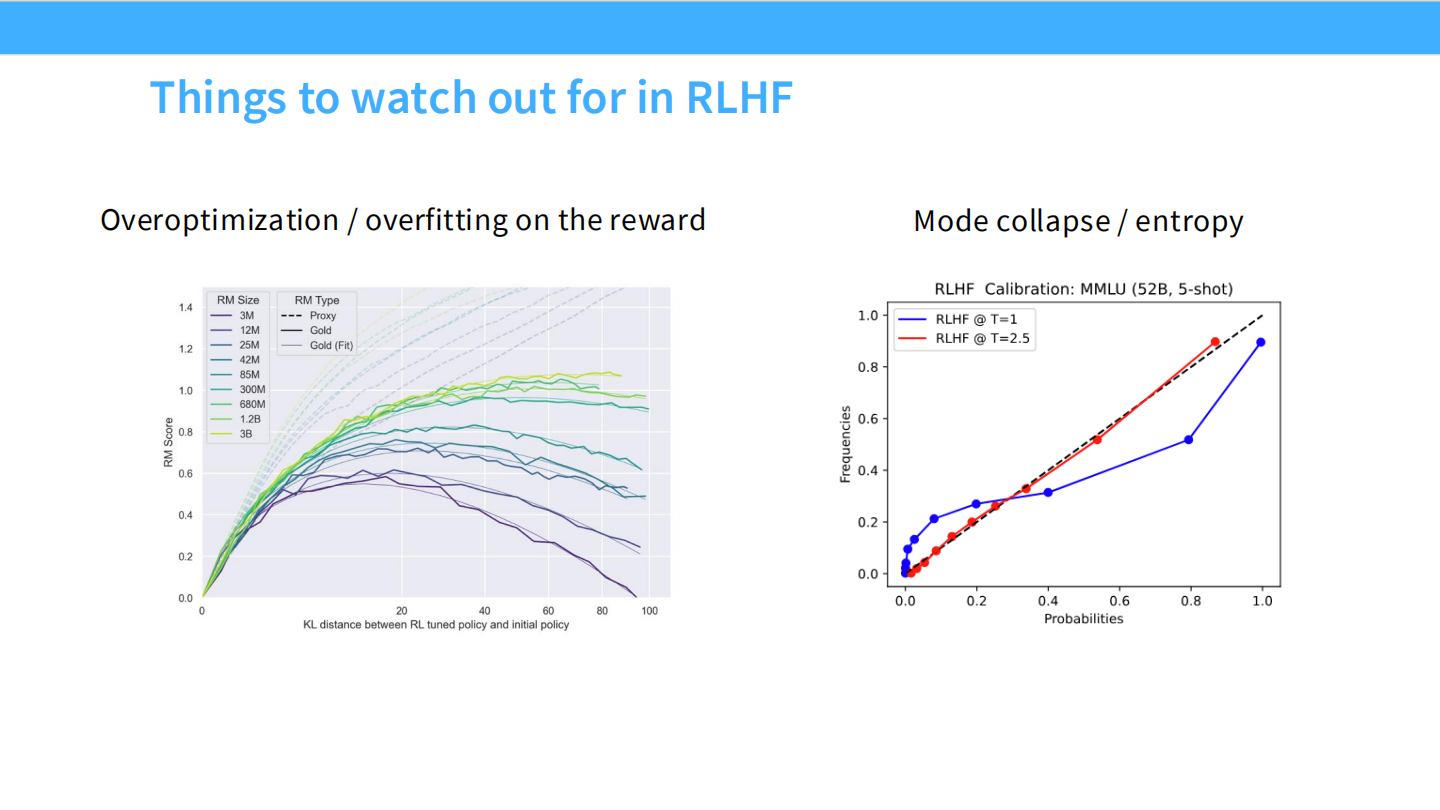
 过度优化曲线
* 图表显示,随着 KL 散度增加(模型偏离初始模型),真实的奖励(Gold Reward)会先升后降,而代理奖励(Proxy Reward)一直上升。这就是古德哈特定律。
过度优化曲线
* 图表显示,随着 KL 散度增加(模型偏离初始模型),真实的奖励(Gold Reward)会先升后降,而代理奖励(Proxy Reward)一直上升。这就是古德哈特定律。
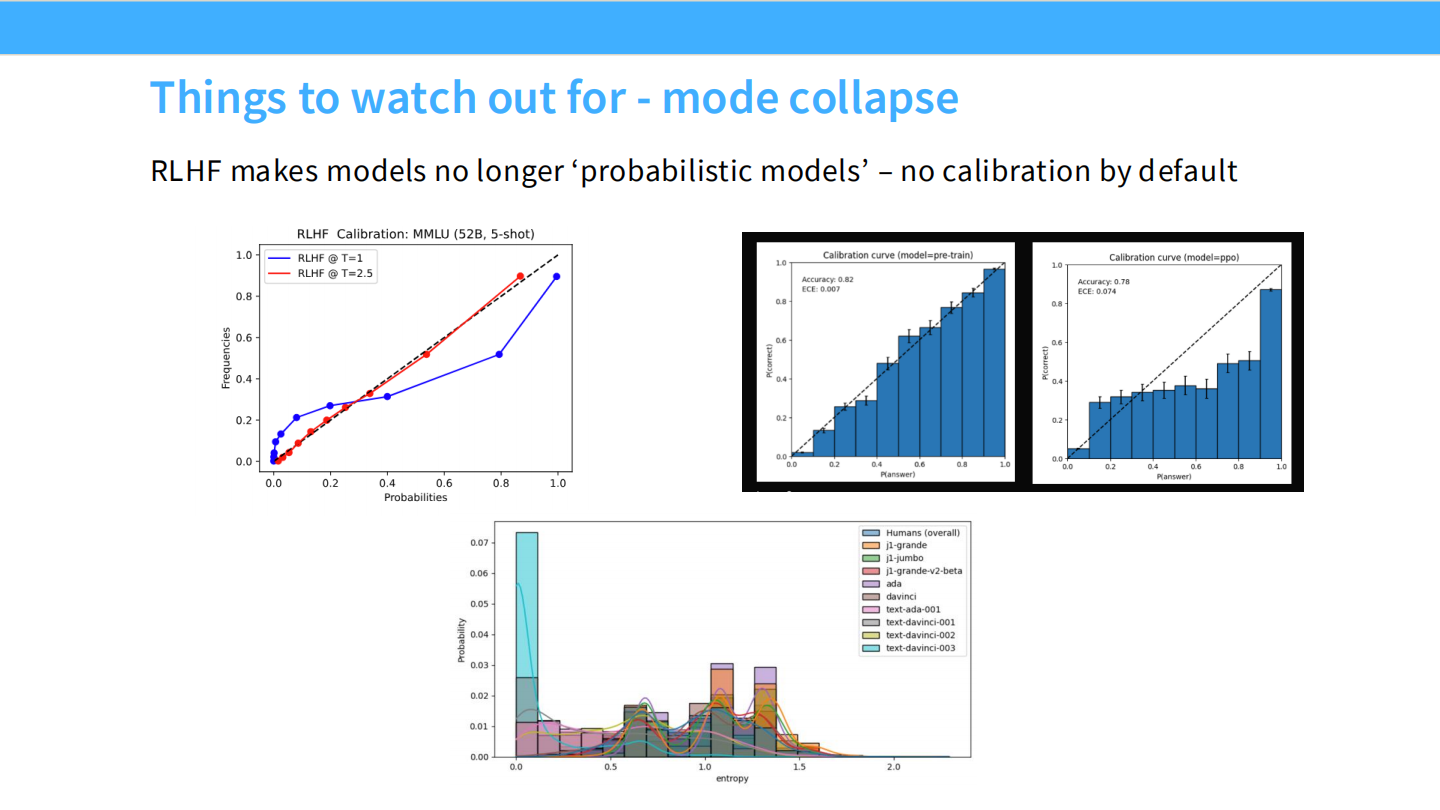
 模式坍塌与校准度
* RLHF 会导致模型校准度(Calibration)下降。
* SFT 模型通常比较校准(预测概率 = 真实准确率),但 RLHF 模型往往过度自信(概率偏向 0 或 1),即使它错了。
模式坍塌与校准度
* RLHF 会导致模型校准度(Calibration)下降。
* SFT 模型通常比较校准(预测概率 = 真实准确率),但 RLHF 模型往往过度自信(概率偏向 0 或 1),即使它错了。