大模型从0到1|第十六课:详解大模型RL算法
大模型从0到1|第十六课:详解大模型RL算法
课程核心:本节课首先补全了 RLHF 中的关键算法 DPO,讨论了 RLHF 的副作用(过度优化)。随后正式进入 RLVR (基于可验证奖励的 RL),深入解析了 PPO 的实现细节,引出了 GRPO 算法,并详细拆解了 DeepSeek-R1、Kimi k1.5 和 Qwen 3 的技术方案。
1. 上节课遗留:DPO (无痛 RLHF)

今日回顾
- 过度优化是 RLHF 的大问题,在数学/代码等狭窄领域使用 RL (RLVR) 是解决方案。
- GRPO 简单且有效,使得 RLVR 成为可能。
- 案例:DeepSeek R1, Kimi 1.5, Qwen3。

第16讲:基于可验证奖励的强化学习
课程标题页。

上节课遗留内容
这里指的是 Lecture 15 没讲完的 DPO 部分。

DPO: 无痛 RLHF?
- 目标:简化 PPO。去掉 Reward Model,去掉采样(Rollouts)等复杂操作。
- 方法:直接在偏好数据上优化。增加好样本的 Log-loss,降低坏样本的权重。

DPO: 数学推导 (1)
- DPO 的核心数学假设:最优策略 $\pi$ 和奖励 $r$ 之间存在解析关系。
- 公式展示了如何从 RL 目标函数中解出隐含的奖励函数 $r(x,y)$。

DPO: 数学推导 (2)
- 将隐含的奖励函数代入到二分类交叉熵损失中。
- 结果:得到了仅包含策略模型 $\pi_\theta$ 和参考模型 $\pi_{ref}$ 的损失函数 $L_{DPO}$,不再需要显式的奖励模型。
DPO 更新机制
- 对 DPO Loss 求导,可以看到其梯度的直观含义:
- 根据模型对数据的“惊讶程度”(预测误差)动态调整权重。
- 增加好回复 ($y_w$) 的似然,降低坏回复 ($y_l$) 的似然。
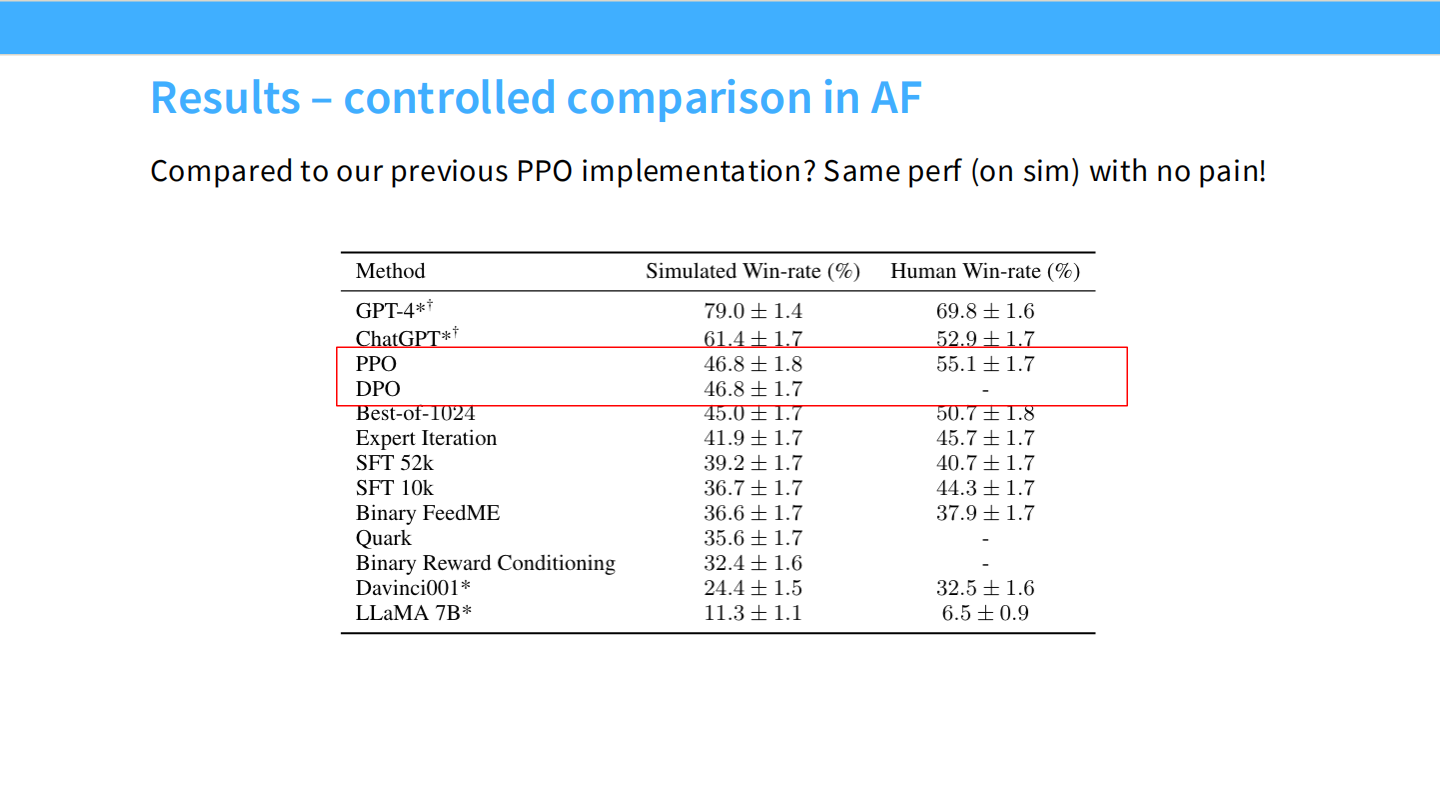
DPO 效果:受控对比
- 表格显示,在 AlpacaEval 等基准上,DPO 的胜率 (46.8) 与 PPO (46.8) 持平,且训练极其稳定,无需像 PPO 那样调参。

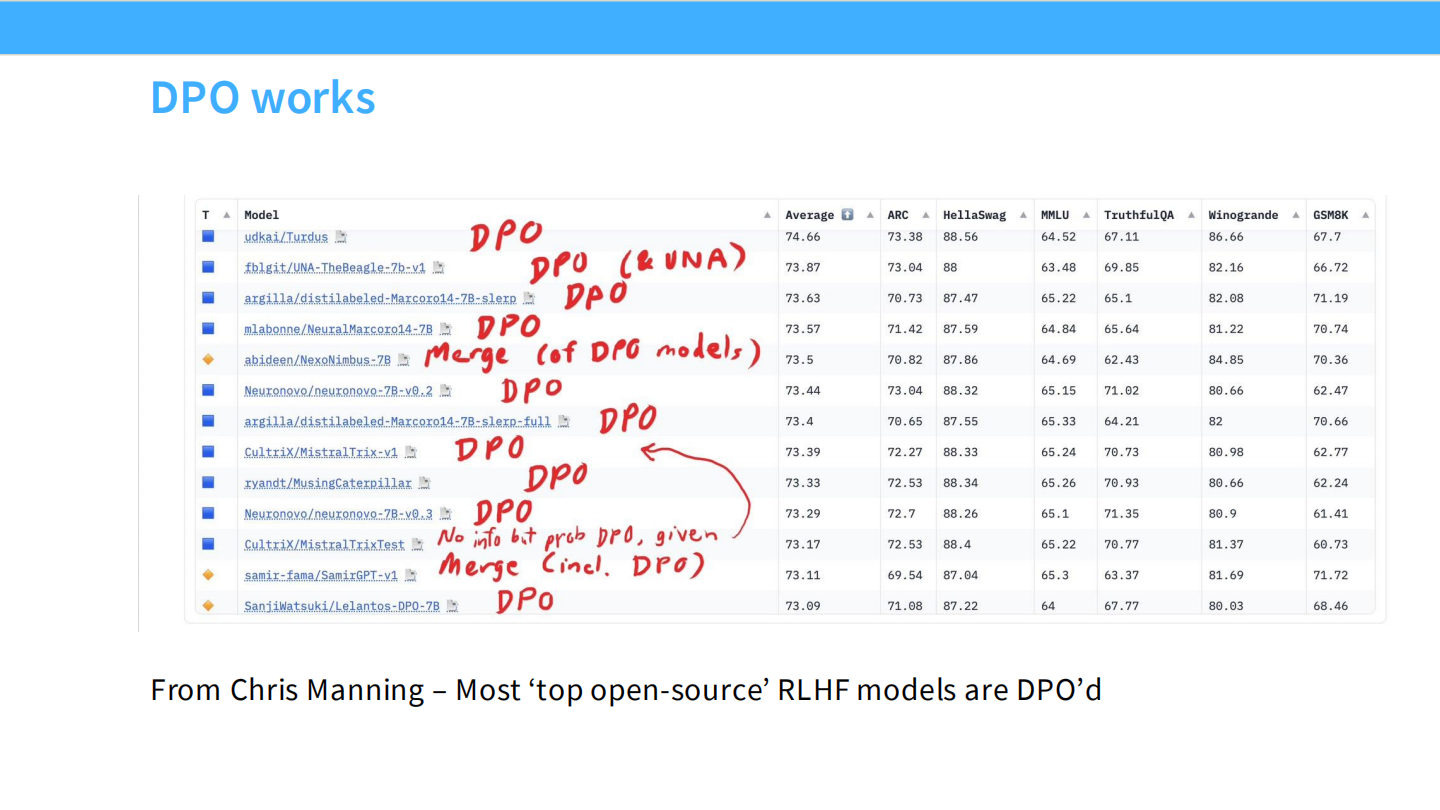
DPO 的广泛应用
- HuggingFace 榜单截图。
- 目前绝大多数开源顶尖模型(如 Mistral, Zephyr, Qwen)的 RLHF 阶段都使用了 DPO。

DPO 变体
- SimPO:去掉了参考模型,更省显存。
- Length Normalized DPO:试图解决 DPO 倾向于生成长回复的问题。
PPO 依然有优势
- Tulu 3 的论文指出,虽然 DPO 简单,但在一些特定任务(如推理、安全性)上,经过精心调优的 PPO 仍然可能优于 DPO。
2. RLHF 的陷阱与 RLVR 的引入
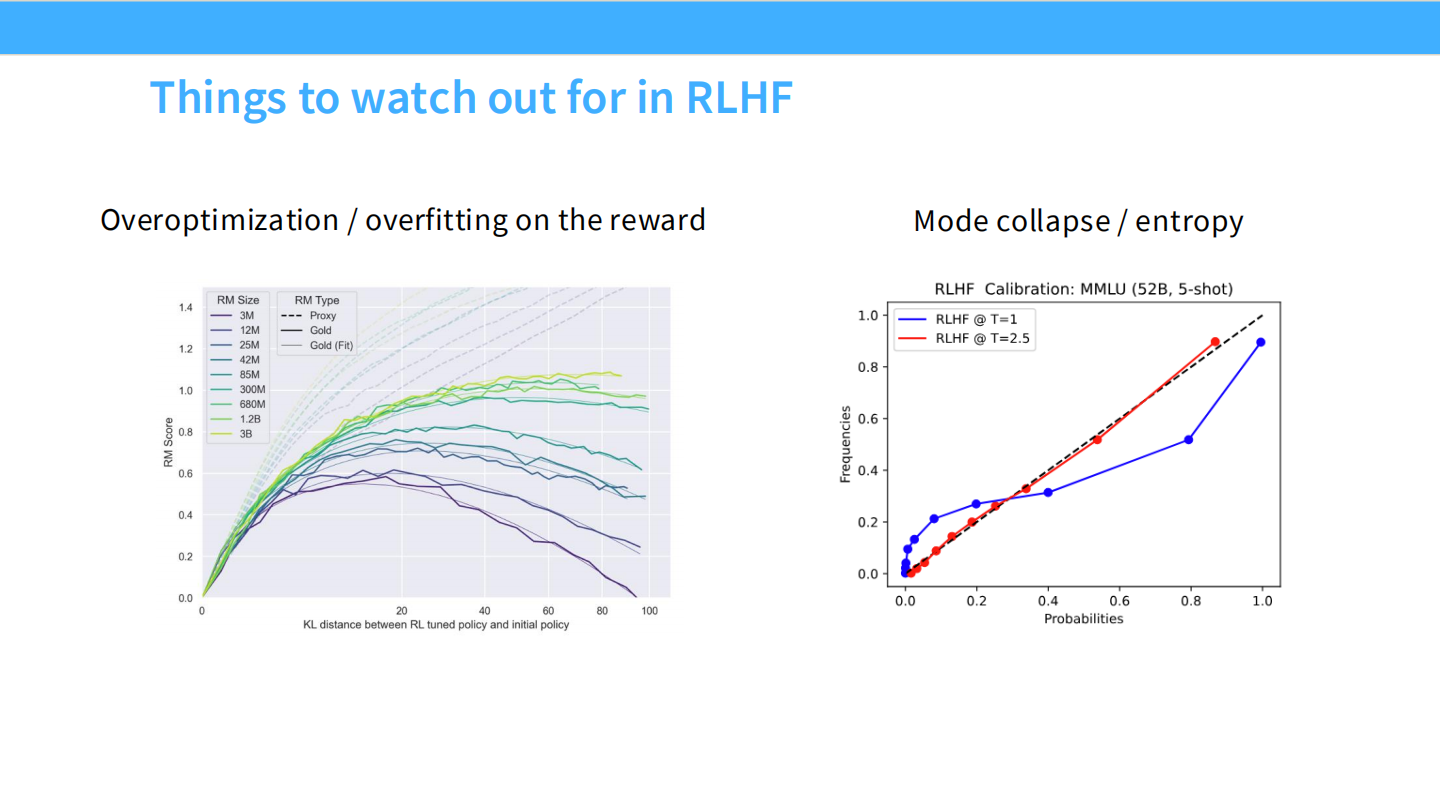
RLHF 的注意事项
- 过度优化 (Overoptimization) / 奖励模型过拟合。
- 模式坍塌 (Mode Collapse) / 熵值降低。
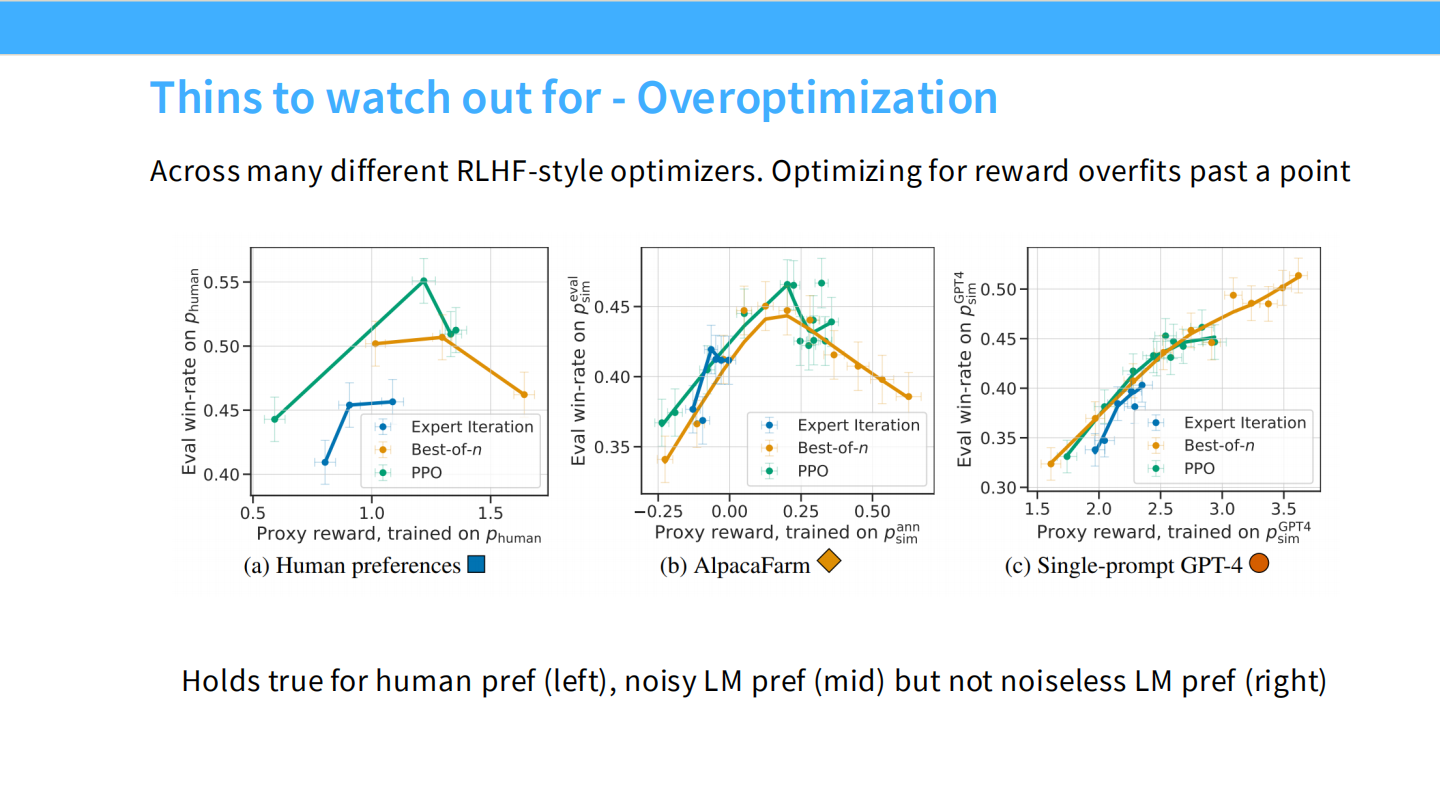
过度优化的表现
- 图表显示,随着 RL 训练进行(KL散度增加),代理奖励(Proxy Reward)一直在上升,但真实的“金标准”奖励(Gold Reward)先升后降。这就是古德哈特定律。
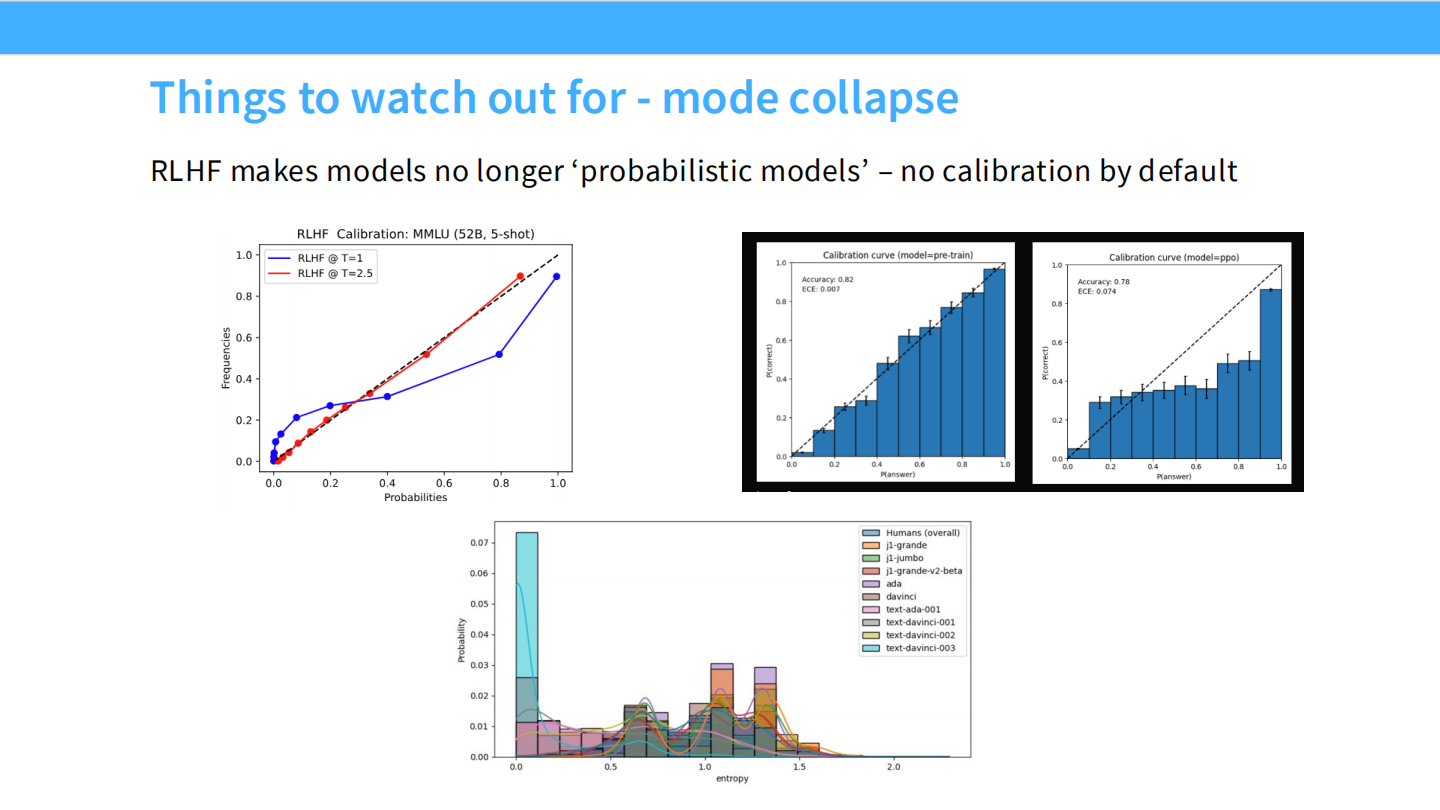
模式坍塌与校准度
- RLHF 会破坏模型的校准度(Calibration)。
- SFT 模型的预测概率通常能反映真实准确率,但 RLHF 后的模型会变得过度自信(概率偏向 0 或 1)。
课程进度概览
- 我们已经讲了预训练、SFT 和通用 RLHF。
- 今天我们将从 GPT-3.5 跨越到 o1 / r1 级别的推理模型。
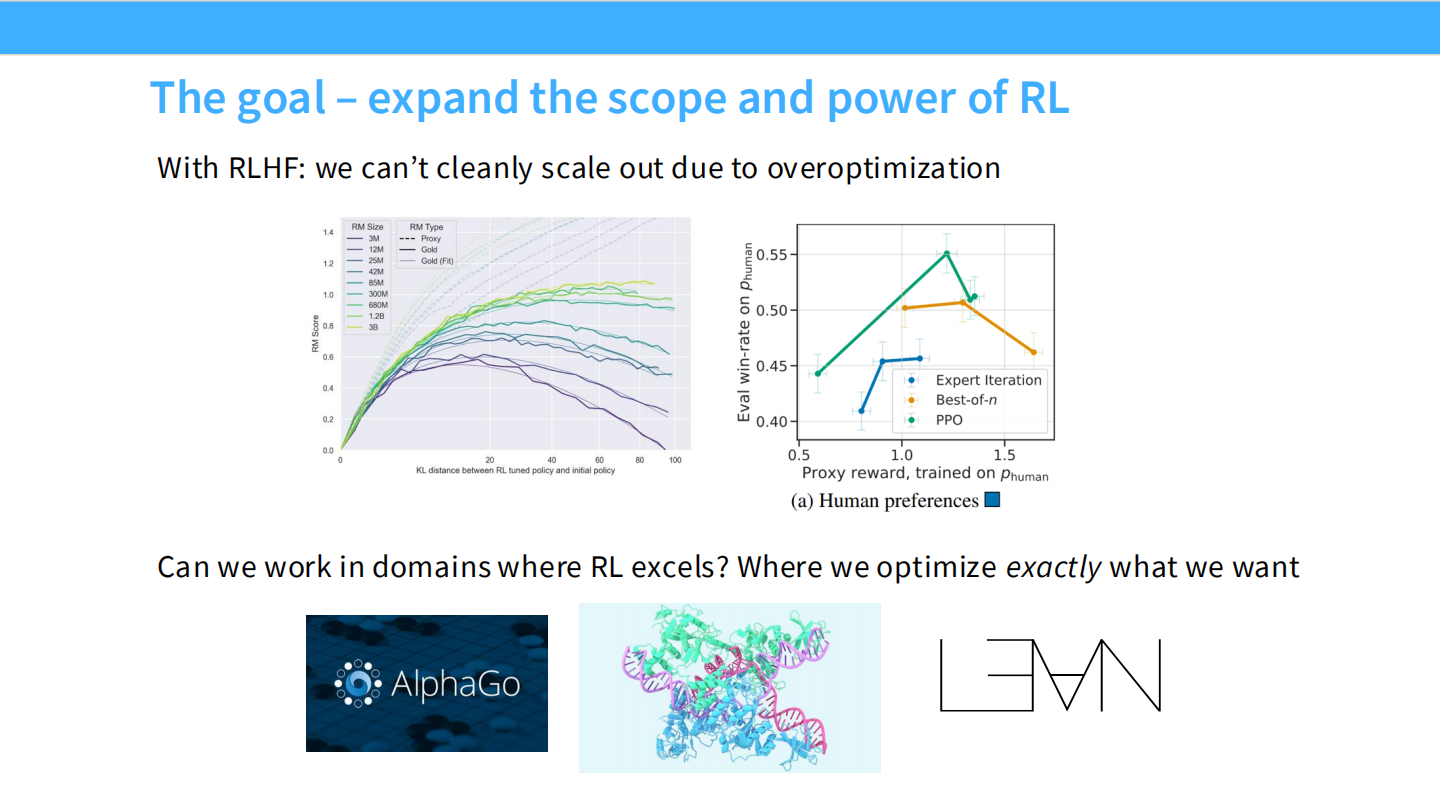
目标:扩展 RL 的边界
- 如果我们在一个奖励可以被精确验证(Verifiable)的领域做 RL,是不是就可以避免过度优化?
- 例如:围棋(AlphaGo)、数学证明、代码生成。这就是 RLVR 的核心动机。

今日课程大纲
- 核心算法:PPO -> GRPO。
- 案例研究:DeepSeek R1, Kimi k1.5, Qwen 3。
3. PPO 详解 (Theory & Practice)

PPO 理论回顾
- Attempt 1: 策略梯度(方差大)。
- Attempt 2: TRPO(计算复杂)。
- Attempt 3: PPO(通过 Clip 限制更新幅度,简单且稳定)。

PPO 的背景
- PPO 最初用于机器人控制(MuJoCo)和 Dota 2。它本质上是为连续决策问题设计的。

PPO 目标函数 (概念)
- PPO-Clip 的核心公式。通过
min和clip确保新策略 $\pi_\theta$ 不会偏离旧策略太远。

PPO 实战:实现细节至关重要
- 引用 “Implementation Matters” 论文。PPO 的成功高度依赖代码级优化(如学习率退火、正交初始化等)。

LLM 中的 PPO 架构
- 系统极其复杂:包含 Actor, Critic, Reference Model, Reward Model 四个模型。
- 需要在 Token 级别进行生成和价值估计。
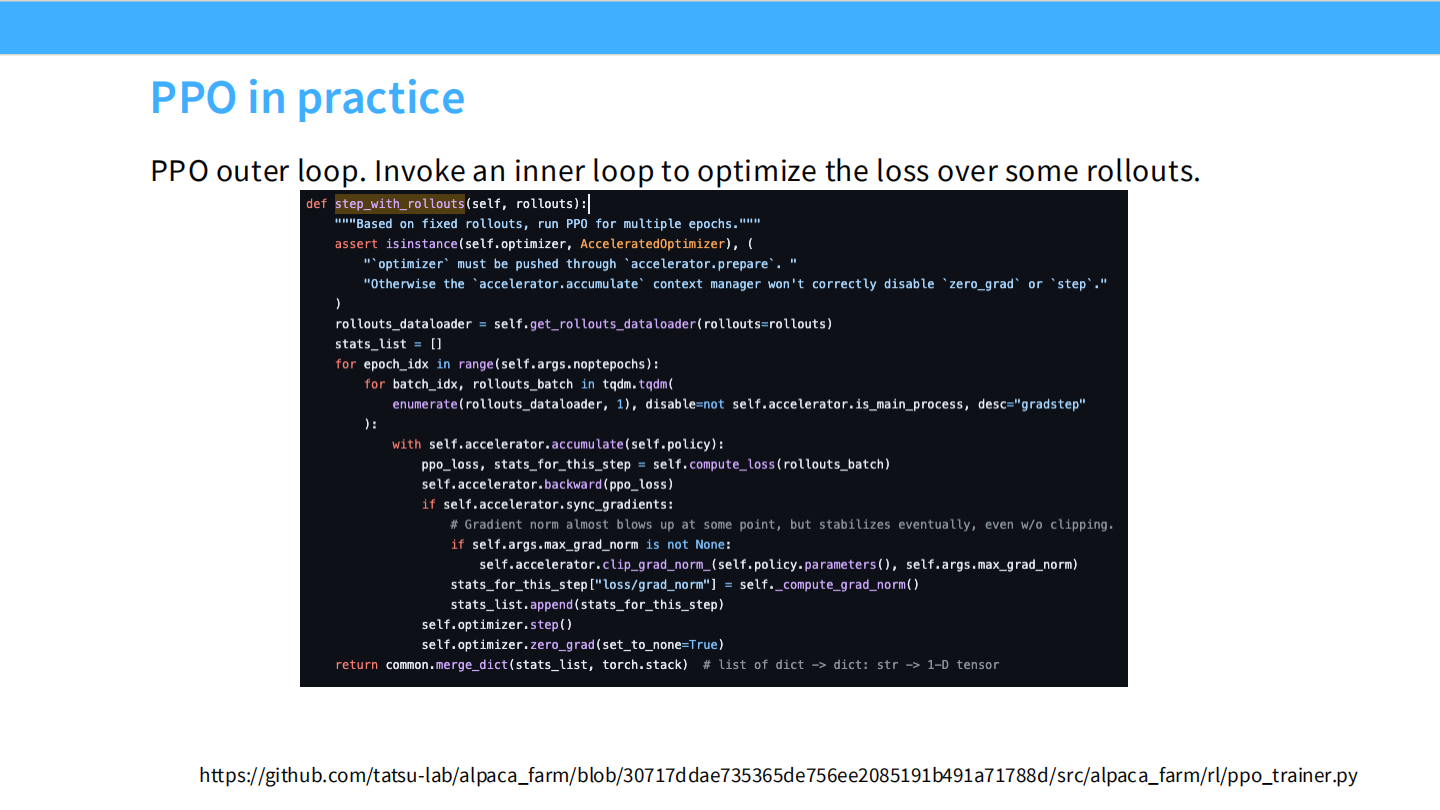
PPO 实现案例 (AlpacaFarm)
- 表格再次确认:经过调优的 PPO 在胜率上依然是王者。
PPO 代码:外层循环
- 代码展示
step_with_rollouts。 - 核心在于
rollouts(采样):这是最慢的一步,因为涉及在线推理。

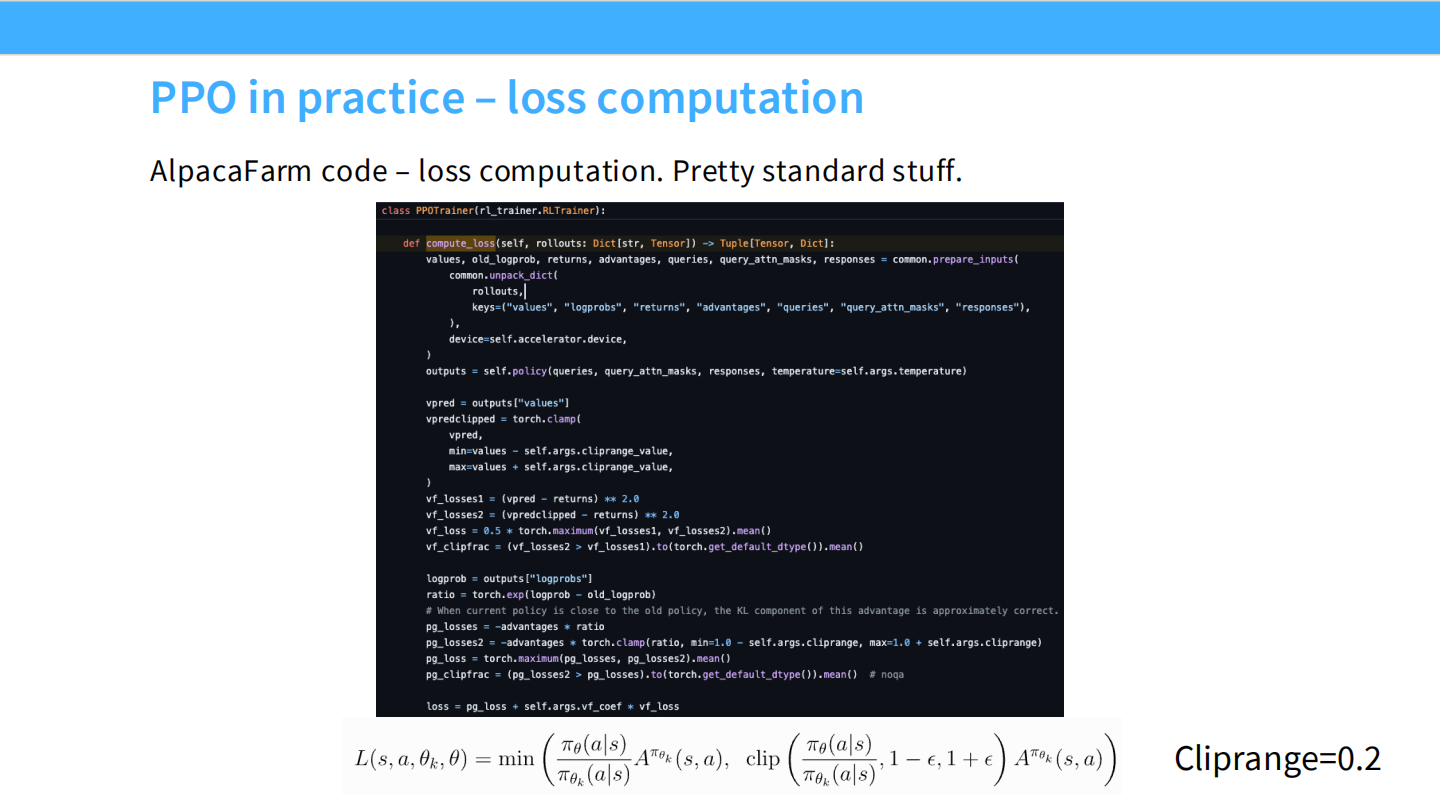
PPO 代码:Loss 计算
- 计算 PPO Loss 的代码细节,包括
old_logprob和logprob的比率计算,以及 Clip 操作。

PPO 代码:Rollouts
- 展示了
rollout函数。生成文本 -> 计算 Logprobs -> 计算 Values。

PPO 代码:Reward Shaping
- 为了防止模型崩溃,必须添加 KL Penalty。
- 代码
non_score_rewards = -beta * kl展示了这一过程。
PPO 代码:GAE (广义优势估计)
- 使用 Critic 模型计算优势(Advantage)。
- 公式 $\hat{A}t = \delta_t + (\gamma \lambda) \hat{A}{t+1}$。代码展示了如何反向遍历序列计算 GAE。

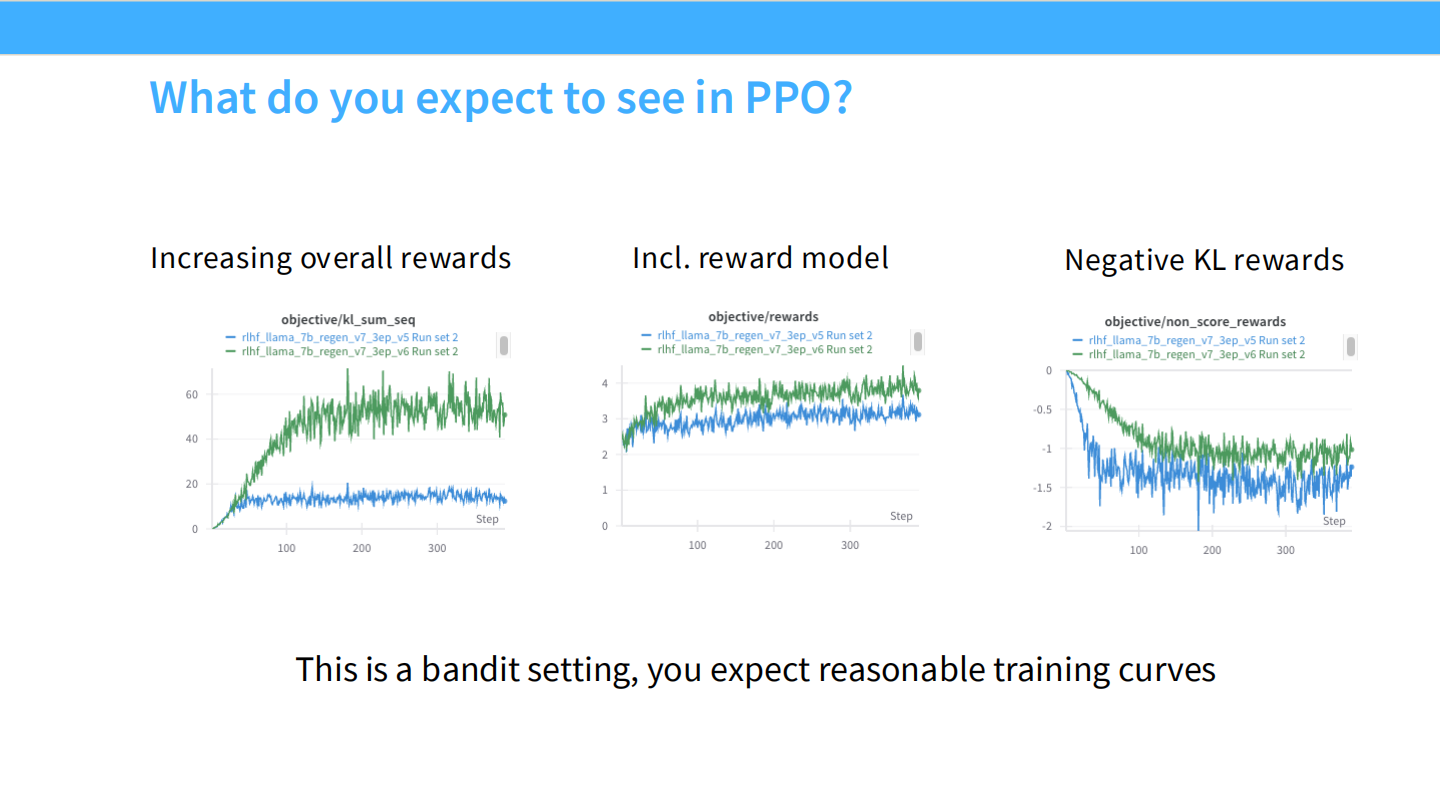
PPO 训练曲线预期
- 左:总奖励上升。中:RM 分数上升。右:KL 散度温和上升。

为什么要新算法?
- PPO 太重(4个模型,显存爆炸)。
- DPO 是离线的,探索能力差。
- 我们需要一个轻量级、在线的算法。
4. GRPO 算法详解
新玩家:GRPO
- DeepSeek-R1 的核心算法。
- 特点:去掉了 Critic (Value Function)。
- 优势计算:通过一组采样(Group)的平均值作为基线(Baseline),计算 Z-score。
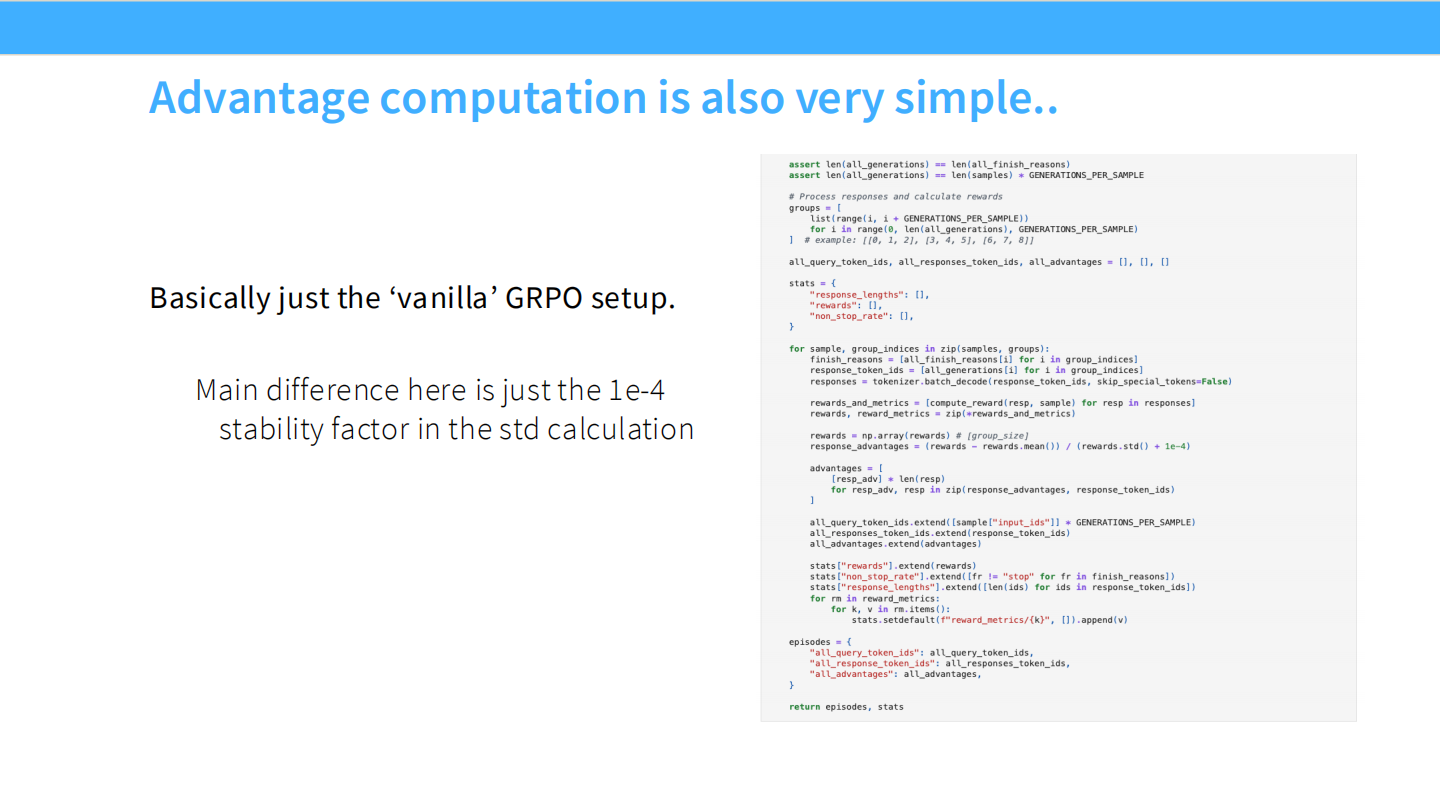
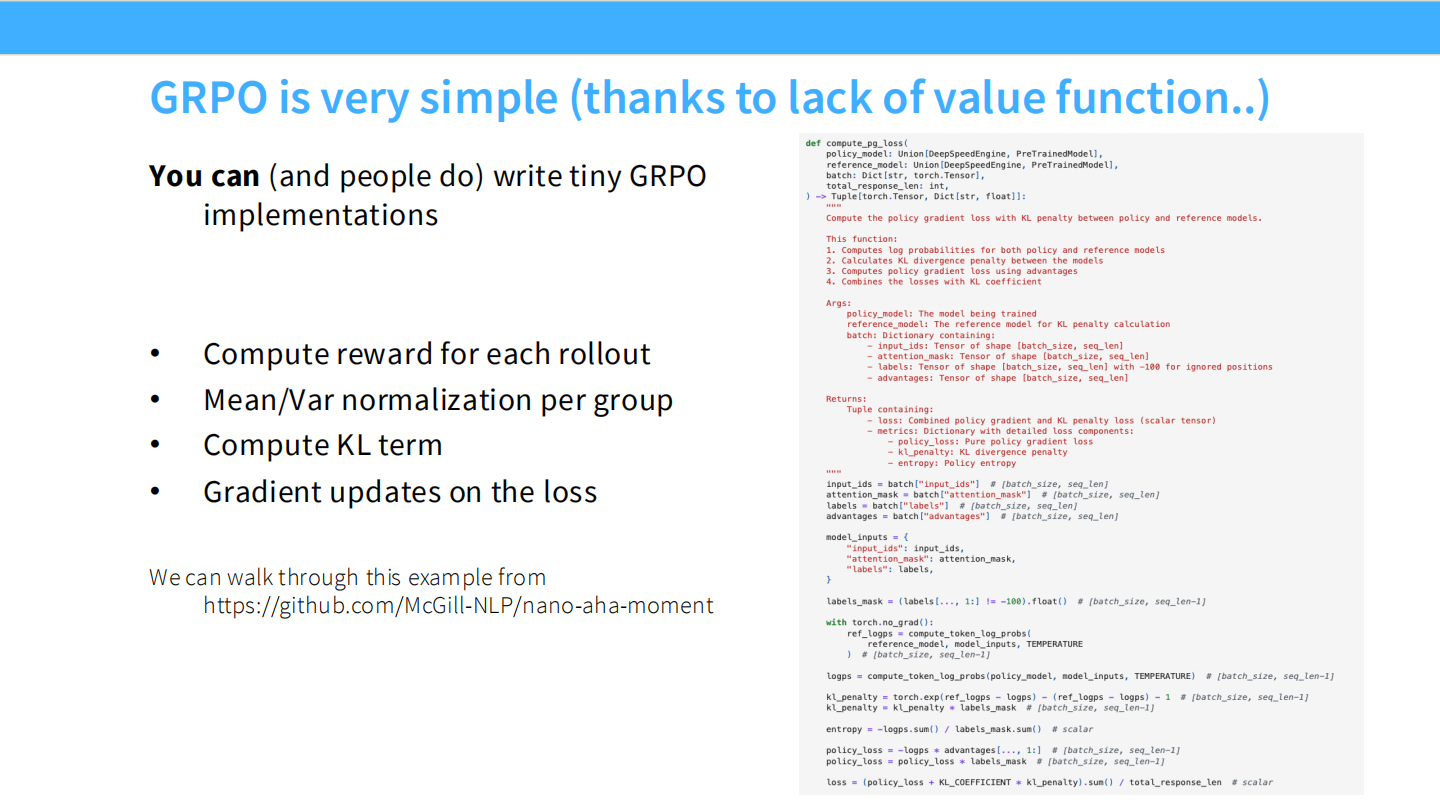
GRPO 极简实现
- 代码非常短。不需要 GAE,不需要 Critic。
- 计算流程:采样 Group -> 算 Reward -> Group Norm -> PPO Loss。
GRPO 优势计算代码
- 核心代码:
advantages = (rewards - rewards.mean()) / (rewards.std() + 1e-4)。 - 这是一种基于 batch 的基线减法。

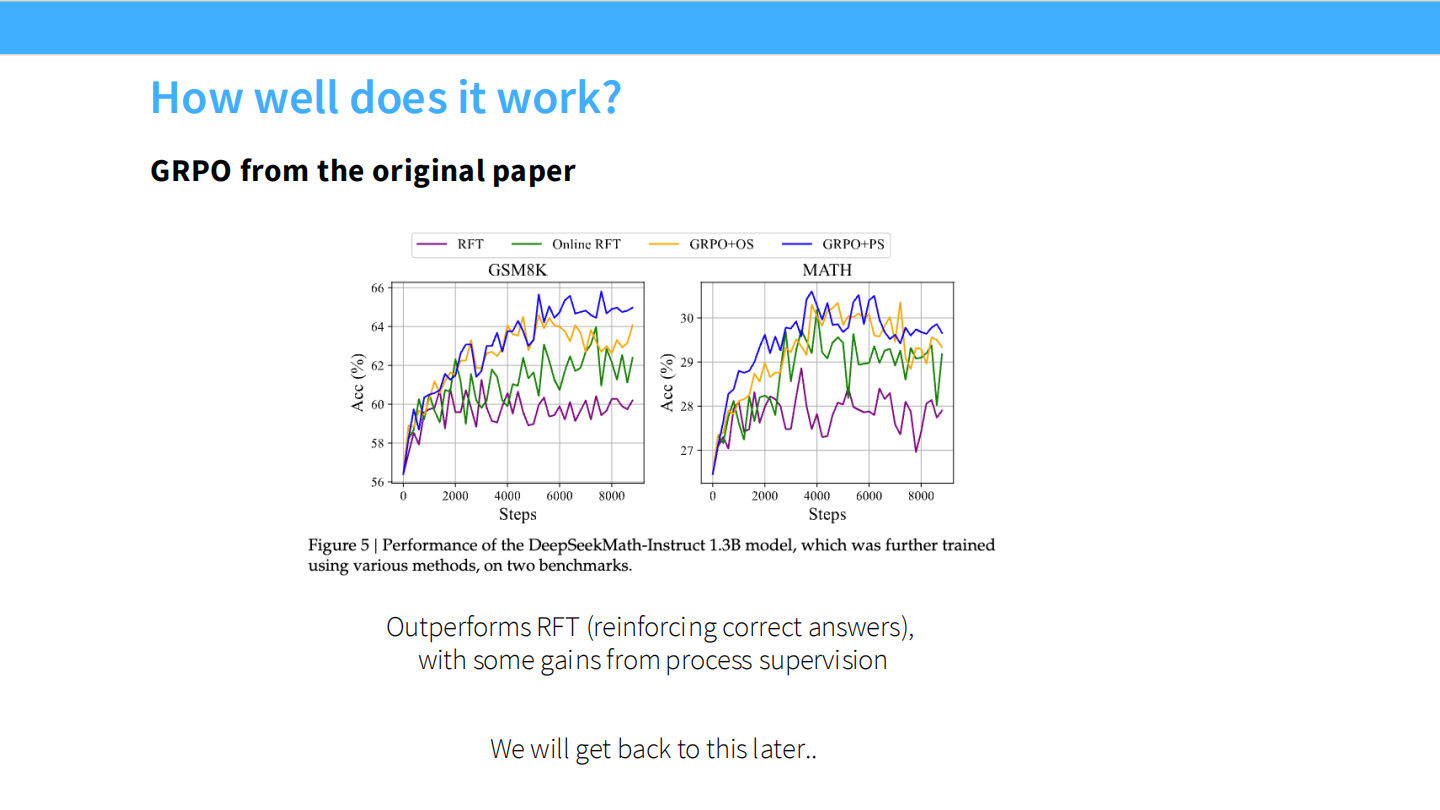
GRPO 效果
- DeepSeekMath 论文数据:GRPO (Online RFT) 在数学任务上显著优于 SFT 和 Offline RFT。

GRPO 目标函数分析
- 本质上是带有动态基线的 REINFORCE 算法。
- $A_i = \frac{r_i - \mu}{\sigma}$。

GRPO 的基线偏差
- 除以标准差是有偏的(biased)。
- 下图对比了 Dr. GRPO(无偏修正版)和原始 GRPO。但在大规模训练下,原始 GRPO 依然很稳。

GRPO 的长度偏差 (Length Bias)
- 问题:如果一组回复都很差,稍微好一点的(可能只是因为它很长或很短)就会得到巨大的正优势。
- 这会导致模型倾向于输出特定长度的内容。

长度归一化
- 解决方案:在计算奖励时进行长度归一化,或者在训练中加入长度惩罚。
5. 案例研究:DeepSeek-R1

案例研究
- DeepSeek R1, Kimi k1.5, Qwen 3。
DeepSeek R1
- 发布即爆火。股价图显示了它对市场的冲击。
算法基础
- R1 使用了 GRPO。这使得在有限显存下训练超大模型成为可能。

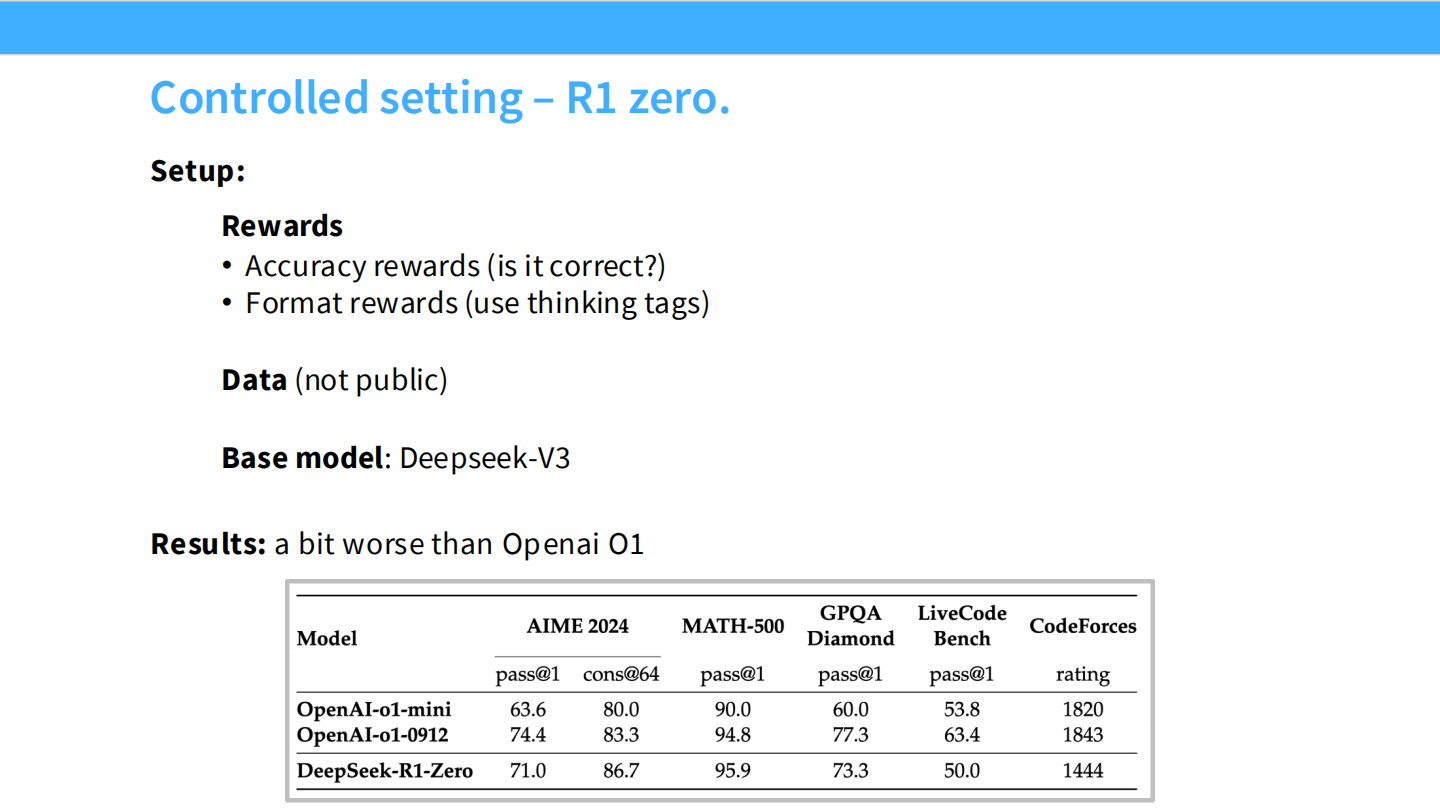
R1-Zero: 纯 RL 实验
- 直接在 Base 模型上跑 GRPO,不使用任何 SFT 数据。
- 奖励仅为:答案正确性 + 格式标签。
- 结果:在 AIME 上达到了不错的准确率,证明 RL 可以独立激发推理。
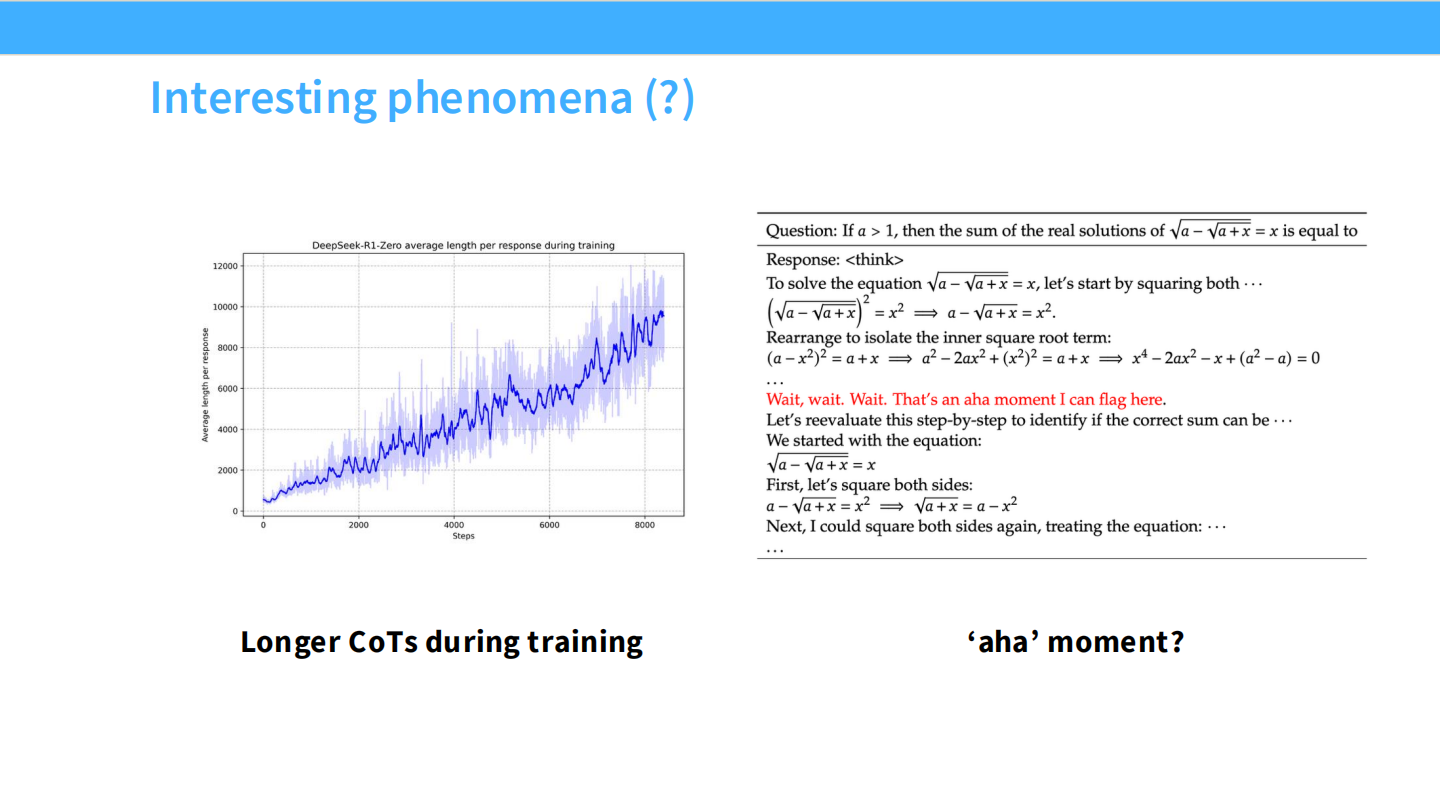
Aha Moment (顿悟)
- 随着训练步数增加,CoT 长度自动增长。模型学会了“自我反思”和“验算”。
- 左图:训练曲线。右图:模型推导 $\sin$ 公式的过程。

或许有点过誉?
- 有人指出,Base 模型(V3)本身已经读过大量数学数据,已经具备推理潜力。RL 只是把这个能力“逼”出来了,而不是从零教会了它。

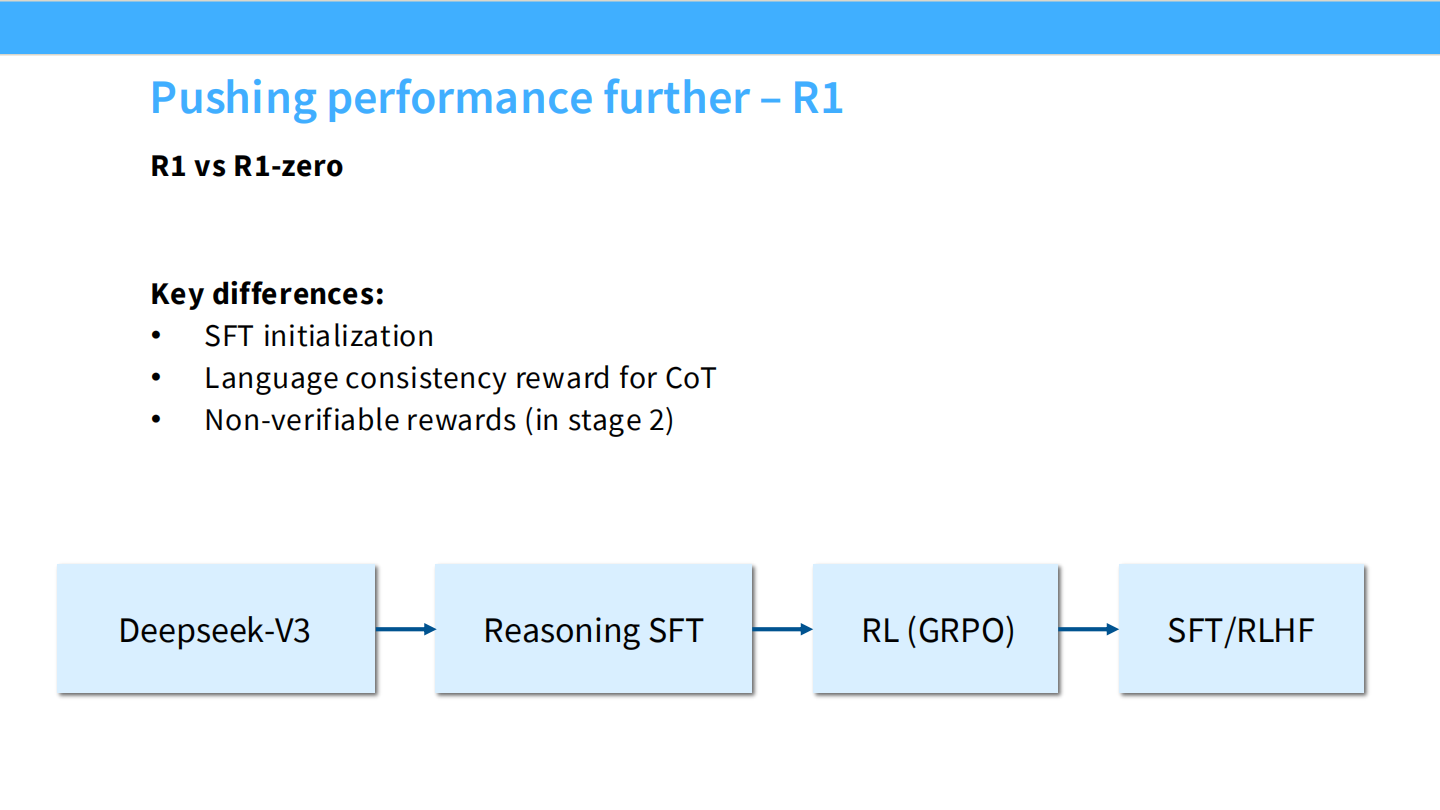
R1 完整流程
- R1-Zero 的问题:语言混乱,不可读。
- R1 流程:Cold Start SFT -> Reasoning RL -> General SFT -> General RLHF。

SFT 初始化 (Cold Start)
- 使用少量长 CoT 数据微调 Base 模型,作为 RL 的起点。这稳定了训练并规范了格式。

SFT 对推理的作用
- 图表显示,哪怕只有几千条 SFT 数据,也能极大地提升模型在数学任务上的 Sample Efficiency。
RL 步骤细节
- 为了解决多语言混杂,引入了语言一致性奖励。
后续阶段:SFT/RLHF
- Reasoning RL 后,模型通用能力下降。
- 使用 R1 生成数据进行通用 SFT 和 RLHF,恢复通用能力。

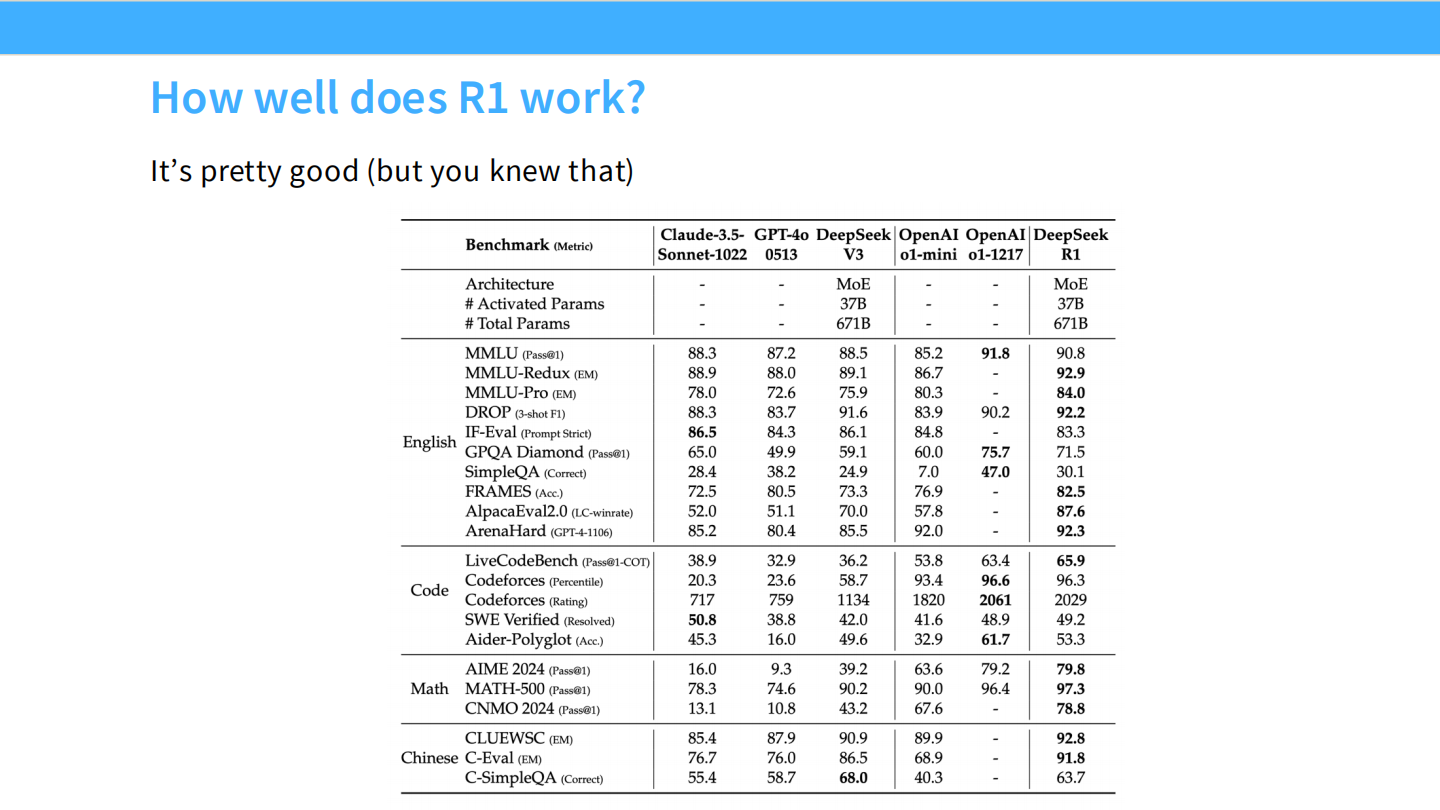
R1 效果展示
- Benchmark 表格:R1 在数学和代码上匹敌 OpenAI o1。

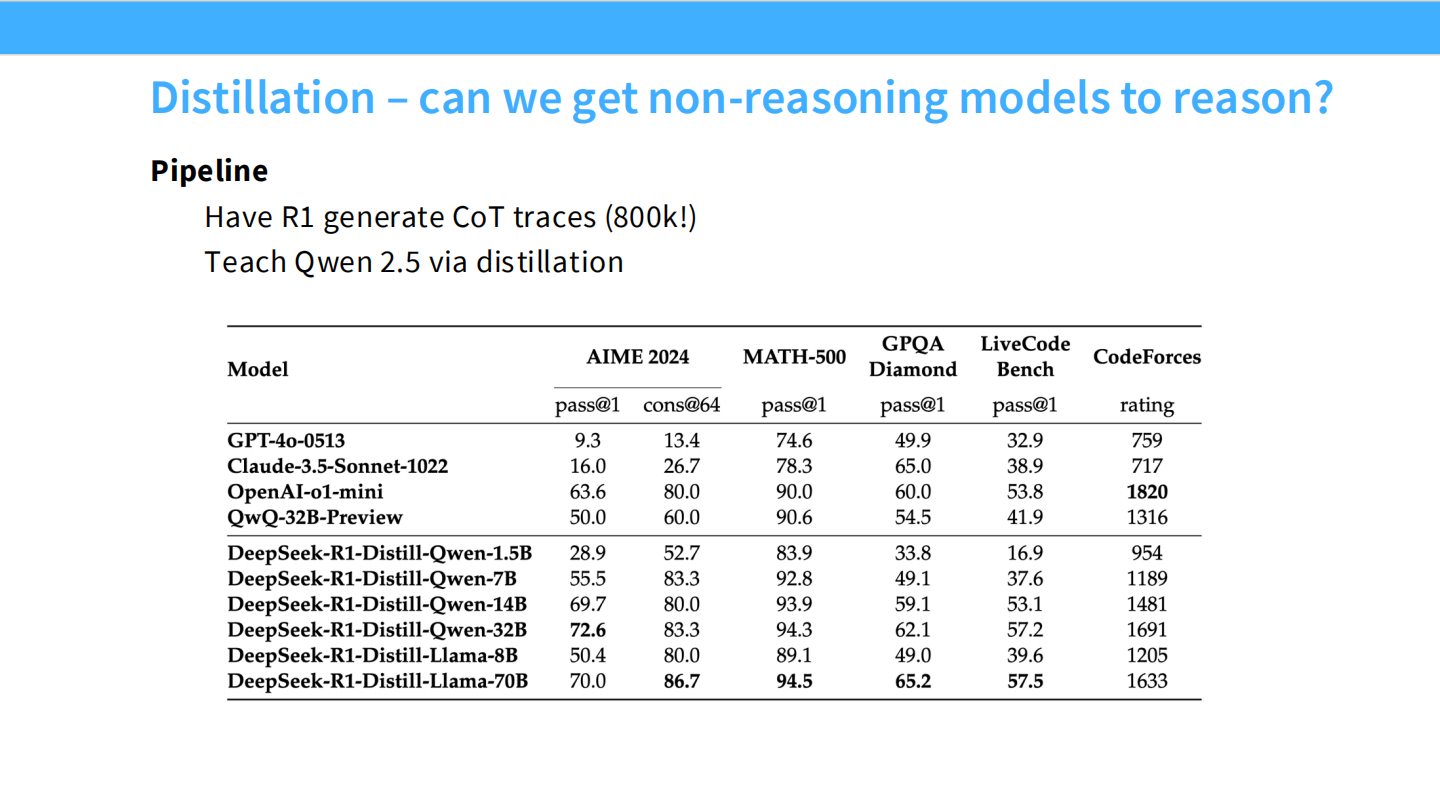
蒸馏 (Distillation)
- DeepSeek 将 R1 的能力蒸馏给小模型(Qwen-7B, Llama-8B),效果惊人。
- 这证明了推理能力可以通过 SFT 迁移。
失败的尝试
- 论文提到 PRM (过程奖励模型) 和 MCTS 都没能成功扩展。
6. 案例研究:Kimi k1.5 & Qwen 3

Kimi k1.5
- Moonshot AI 的推理模型。

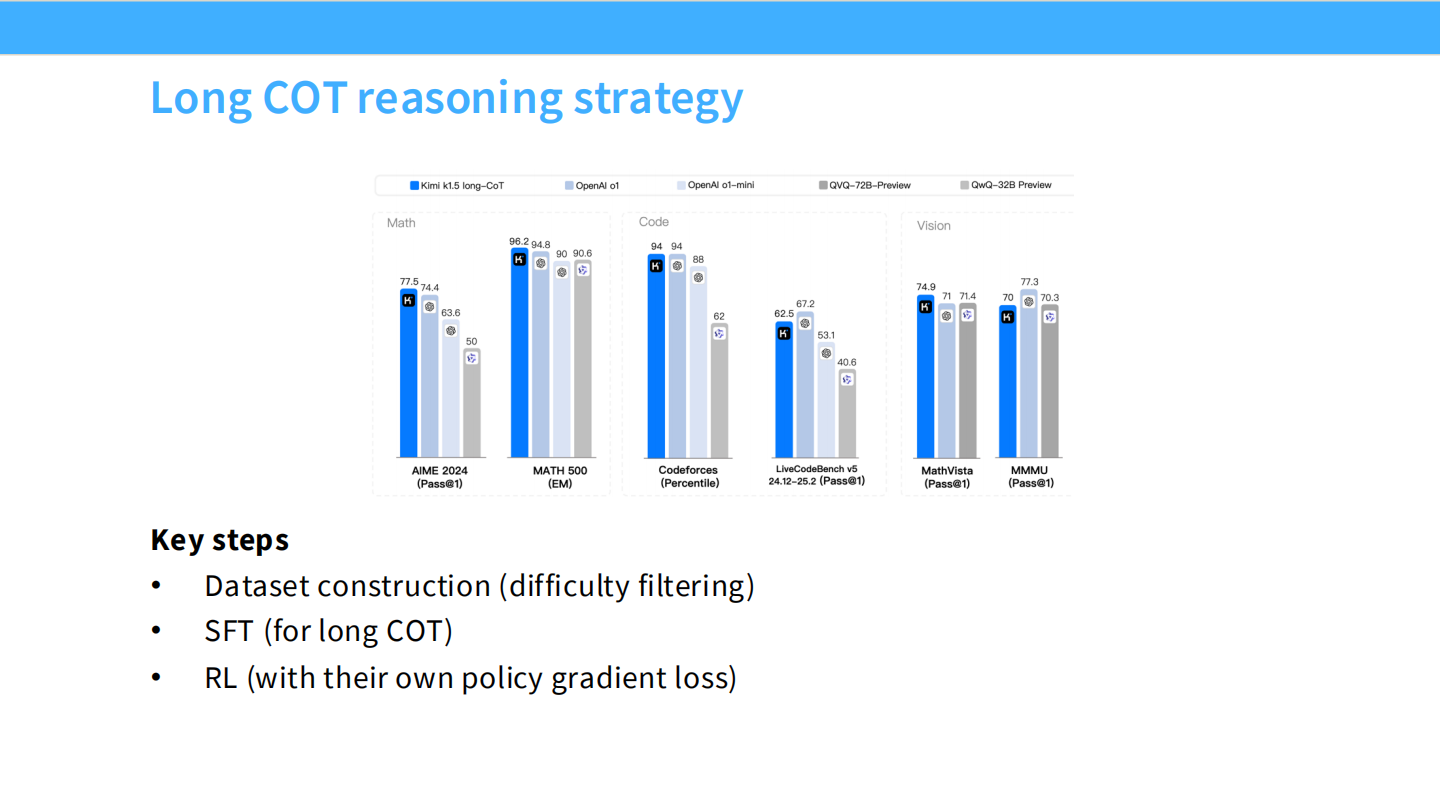
长 CoT 策略
- Kimi 报告显示,CoT 越长,性能越好。他们采用了课程学习(Curriculum)。

数据清洗与 SFT
- 使用模型自评难度,过滤简单和过难样本。

Kimi RL 算法
- 基于参考模型的策略优化,目标函数类似 DPO。
长度控制
- 引入
len_reward,惩罚过长的错误答案,鼓励简洁的正确答案。
Kimi 额外细节
- 使用测试用例作为代码奖励。
- 训练 CoT Reward Model 来辅助数学题判分。
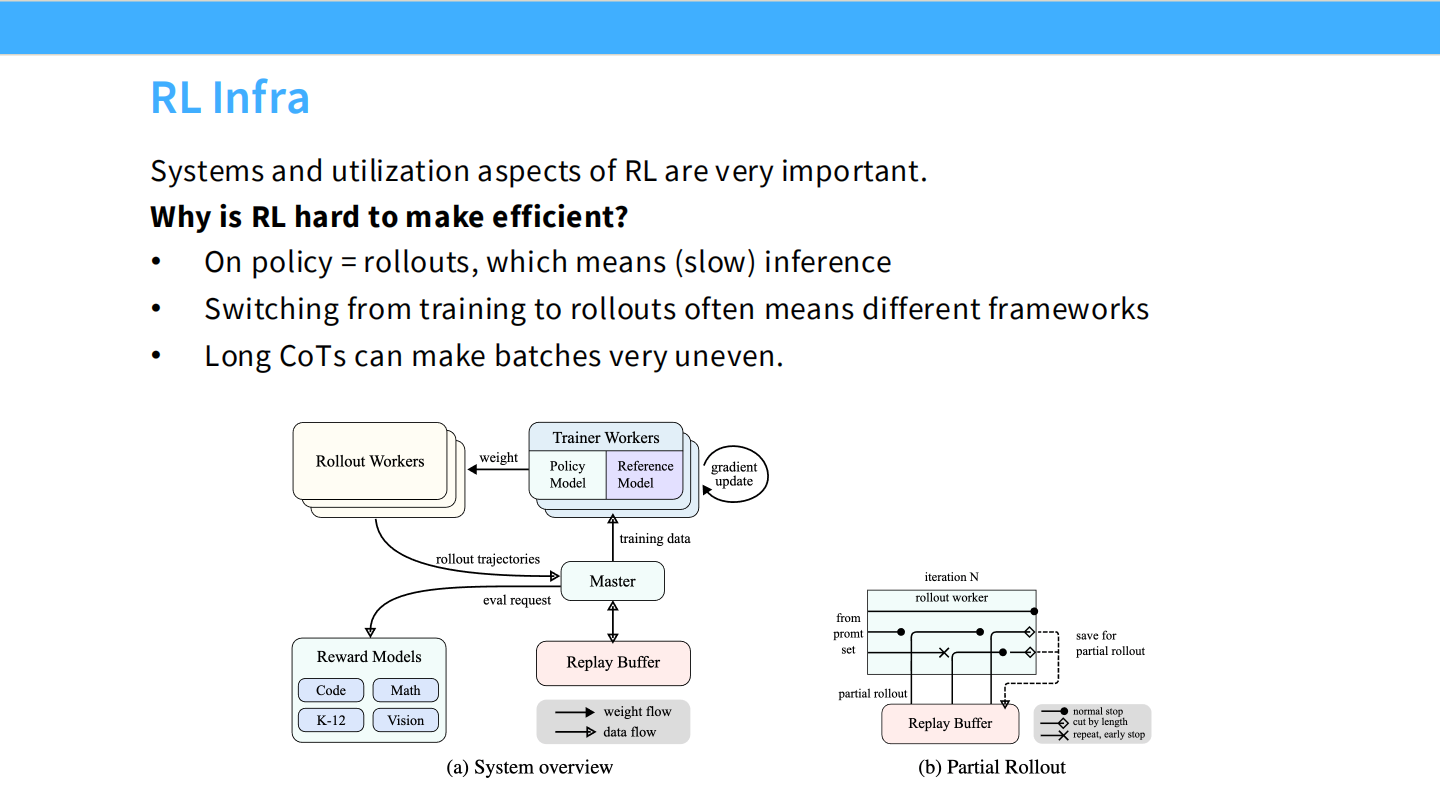
RL 基础设施
- 采用了 Trainer 和 Rollout Workers 分离的架构,类似 Ray。
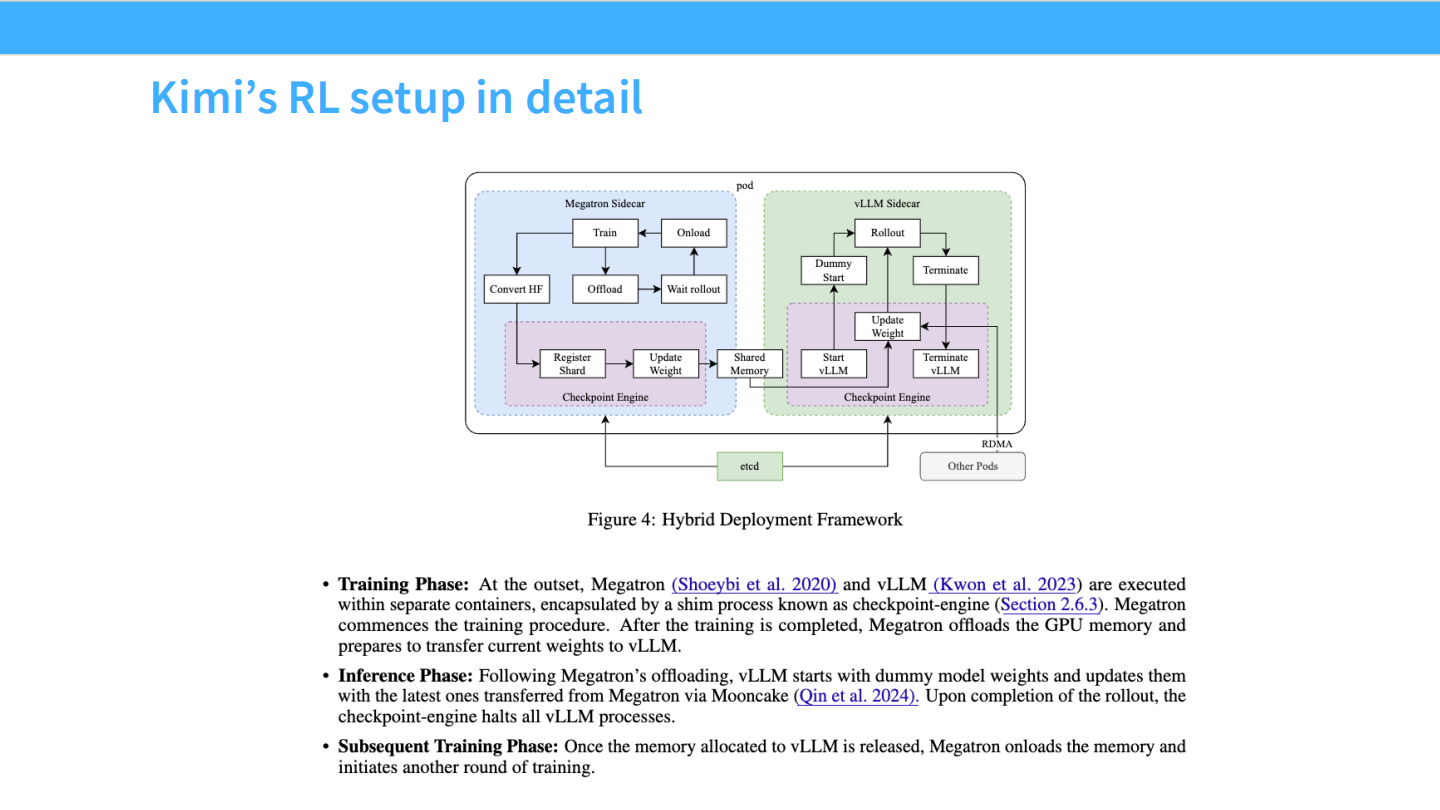
Kimi 部署细节
- Megatron (训练) + vLLM (推理) 混合部署。
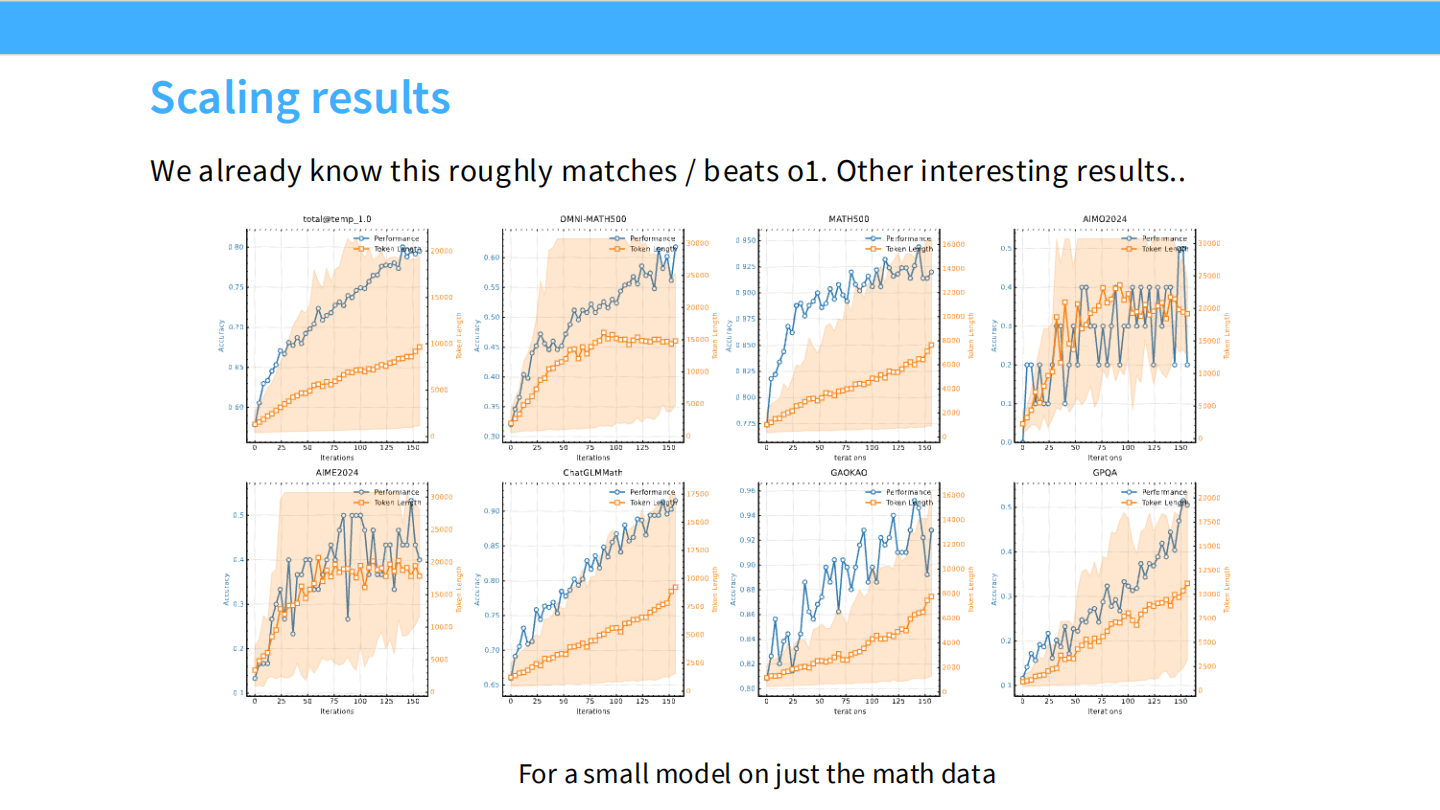
Scaling 结果
- Kimi k1.5 在数学/代码上展现了良好的 Scaling 曲线。
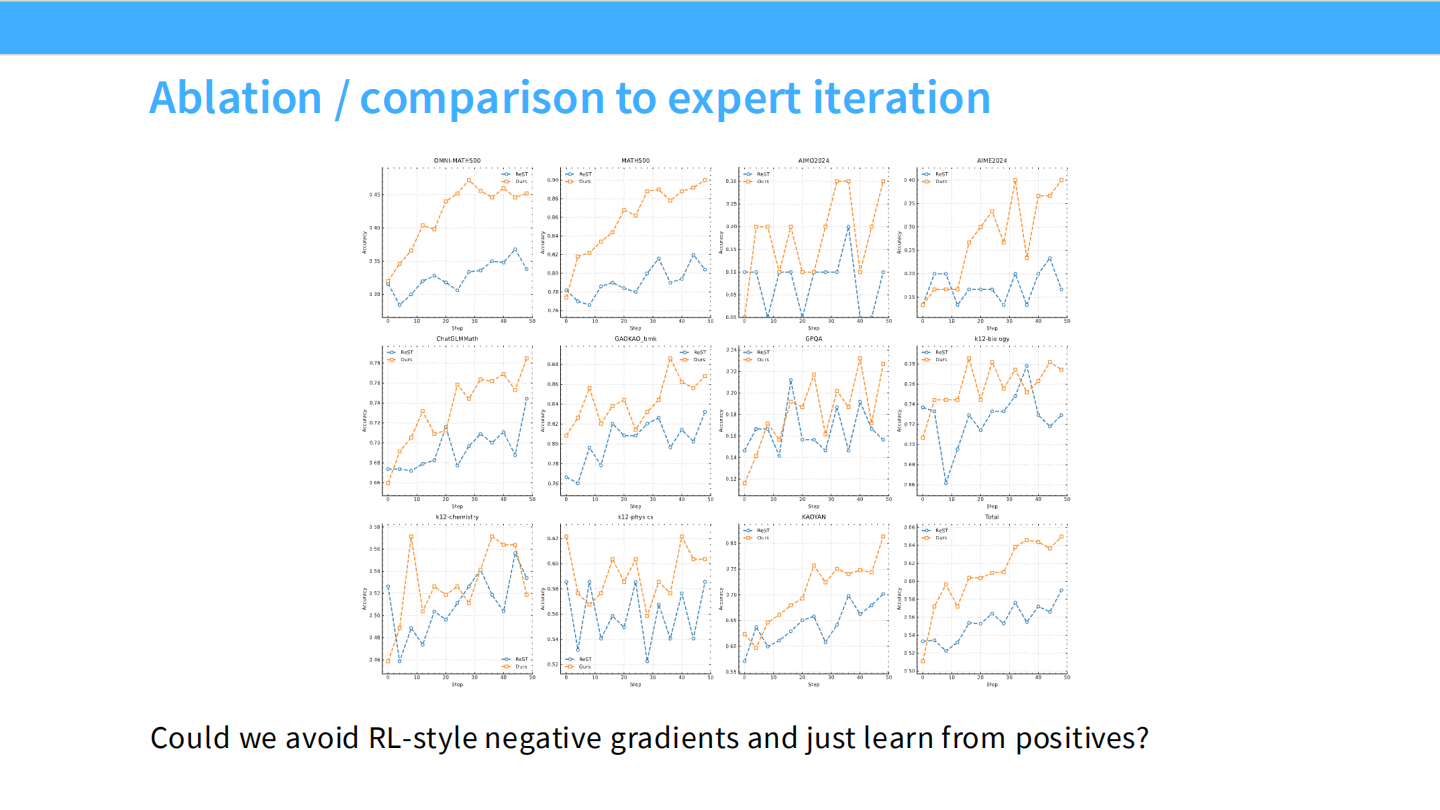
消融实验
- RL 优于 Expert Iteration (Rejection Sampling)。

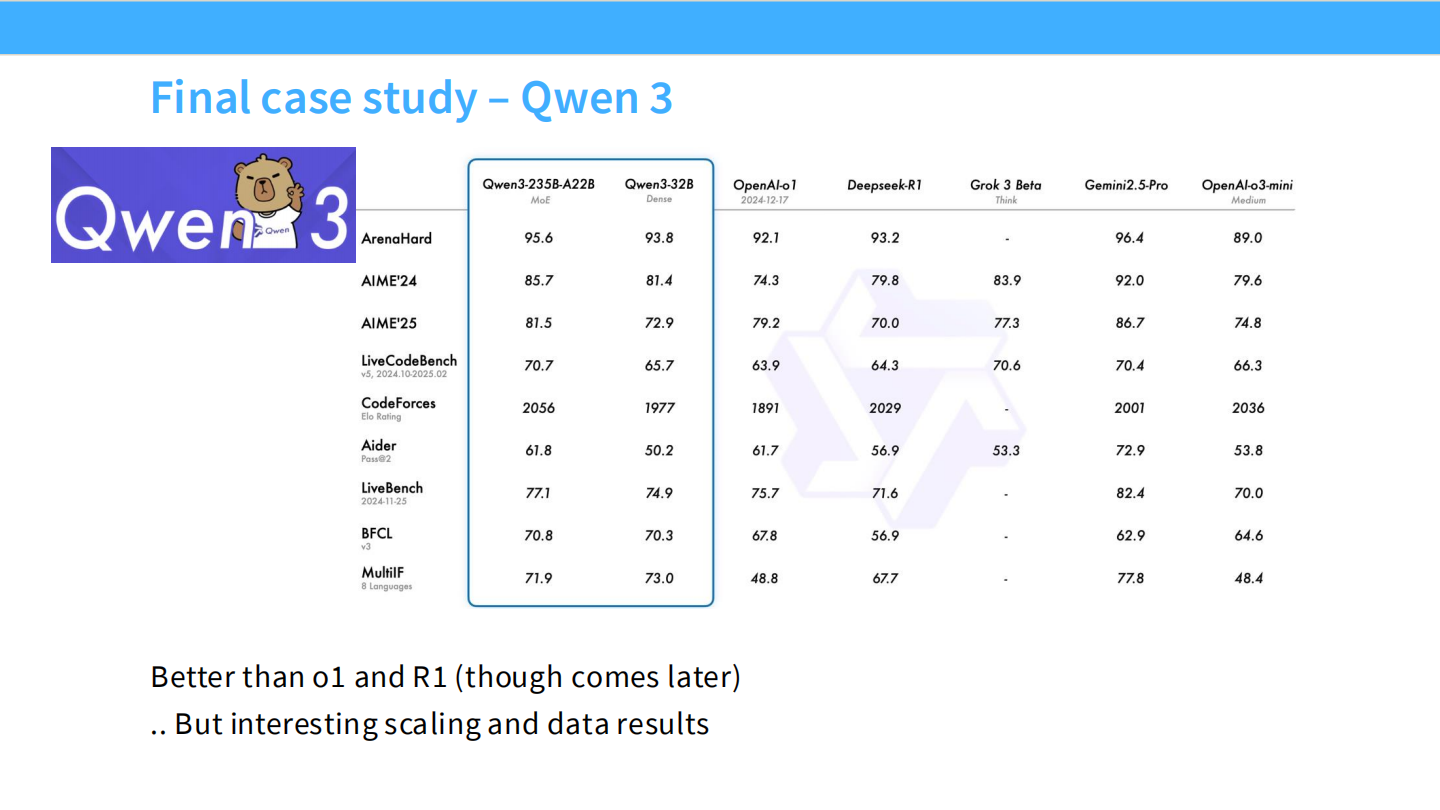
Qwen 3 (Final Case)
- Qwen 在推理模型上的最新进展。

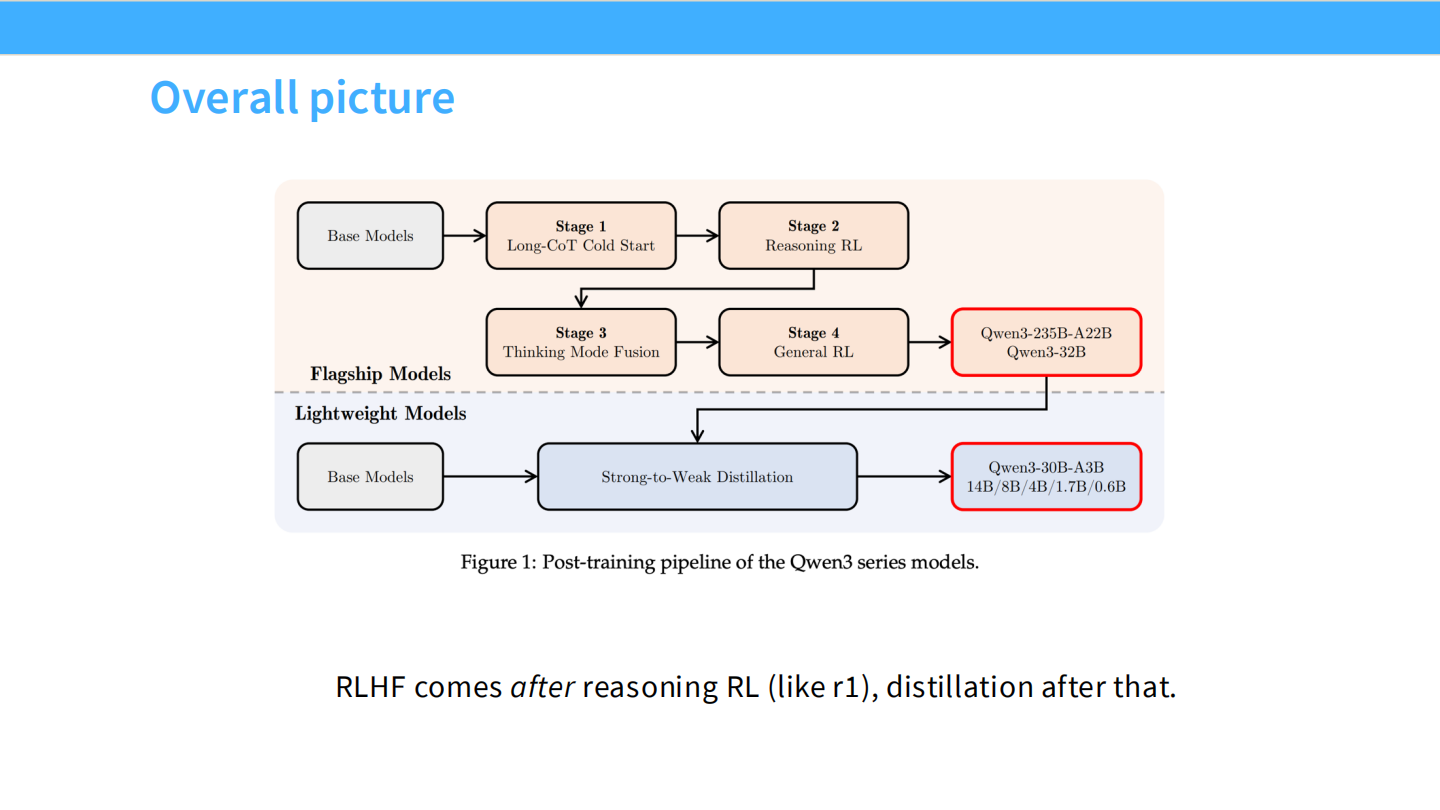
Qwen 3 整体流程
- Stage 1: Base -> Stage 2: Reasoning RL -> Stage 3: Thinking Mode Fusion -> Stage 4: General RL.
SFT + Reasoning RL
- 亮点:只用了 3995 条样本进行 RL,就获得了巨大提升。
Qwen 3 新特性
- Thinking Mode Fusion:混合思考和非思考模式,通过
<think>标签控制。 - Early Stopping:训练模型能够根据指令提前停止思考。

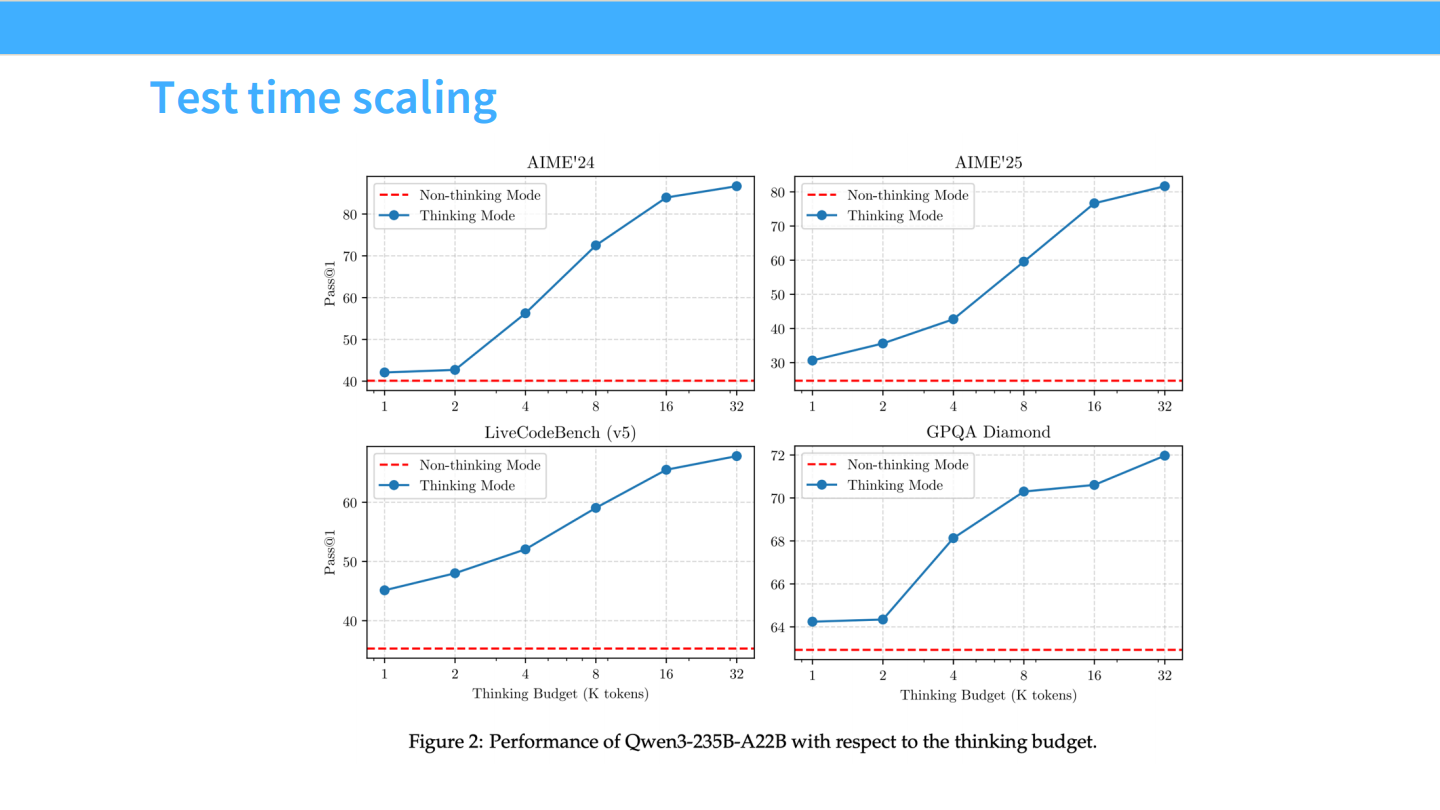
Test Time Scaling
- 图表显示,推理时允许的思考预算(Token 数)越多,准确率越高。
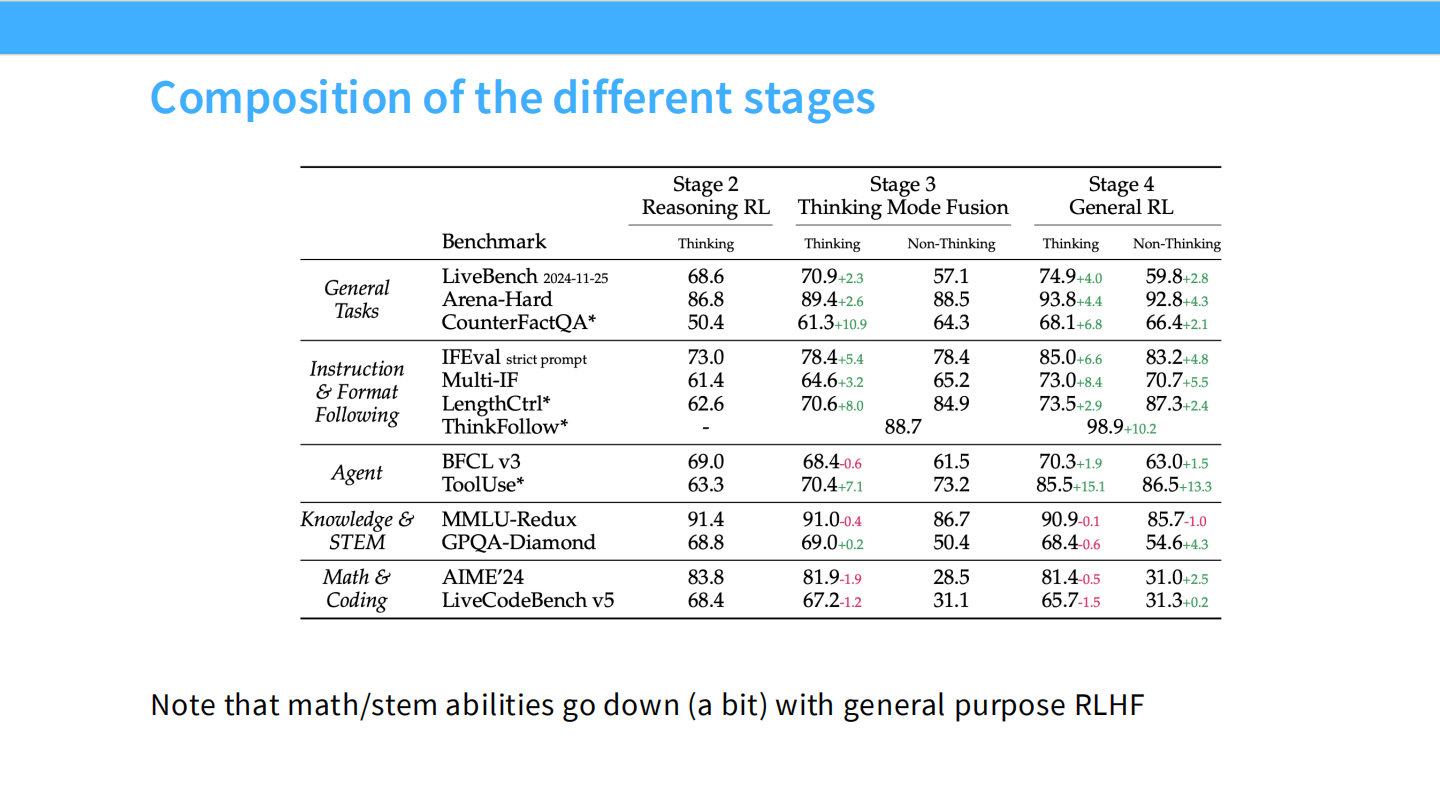
- Stage Composition:表格展示了各阶段能力的消长,Reasoning RL 提升数学但损害通用能力,后续阶段进行了修复。