大模型从0到1|第十三课:训练数据策略
大模型从0到1|第十三课:训练数据策略
上一讲:如何给定数据训练模型
接下来的两讲:我们应该在什么数据上训练?
1. 简介 (Introduction)
暴论:数据是训练语言模型中最重要的一环。
一个理由:让我们看看公司披露了什么。
开放权重模型(例如 Llama 3)对架构甚至训练过程完全透明,但基本没有关于数据的信息。
保密的原因:(i) 竞争动态 和 (ii) 版权责任
- 在基础模型之前,数据工作意味着为监督学习进行大量的标注工作。
- 现在标注减少了,但即使是无监督学习,仍有大量的策展和清洗工作。
- 数据本质上是一个长尾问题,随人力投入而扩展(不像架构、系统)。
训练阶段:
- **预训练 (Pre-training)**:在原始文本上训练(例如来自网络的文档)。
- **中期训练 (Mid-training)**:在高质量数据上训练更多以增强能力。
- **后训练 (Post-training)**:在指令遵循数据上微调(或进行强化学习)以实现指令遵循。
实际上,界限是模糊的,可能还有更多阶段。
…但基本思想是从 [大量低质量数据] 到 [少量高质量数据]。
术语:
- **基础模型 (Base model)**:预训练 + 中期训练后。
- **指令/聊天模型 (Instruct/chat model)**:后训练后。
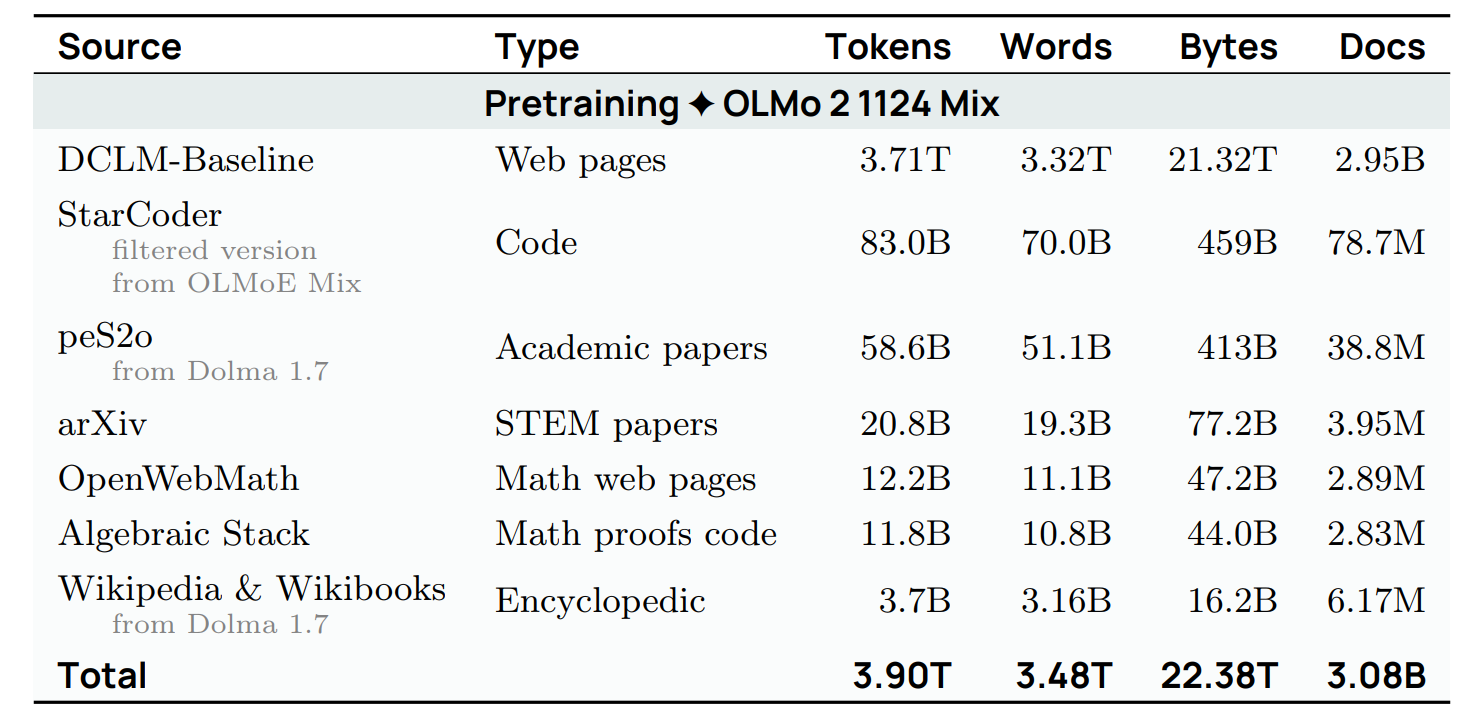
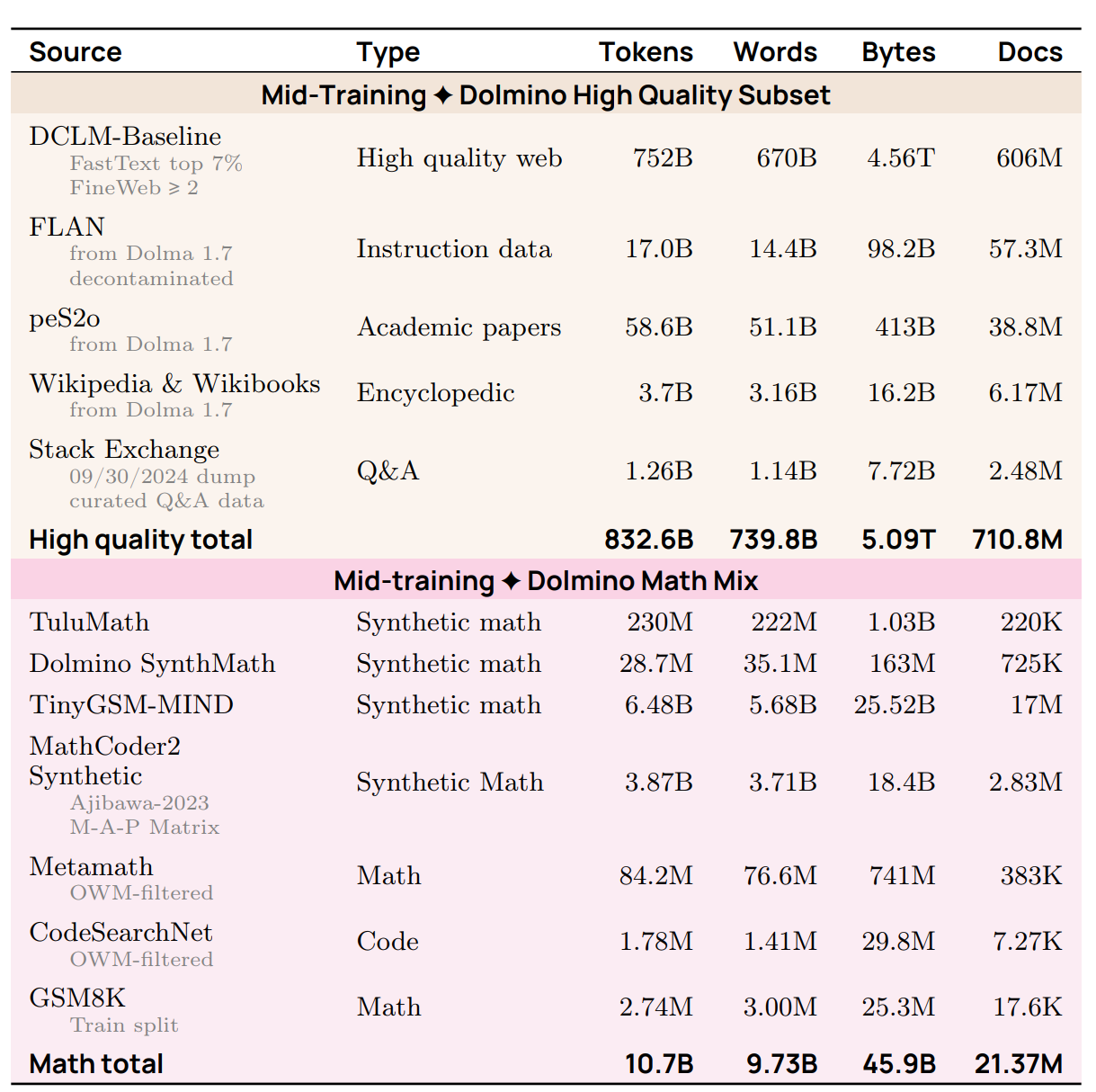
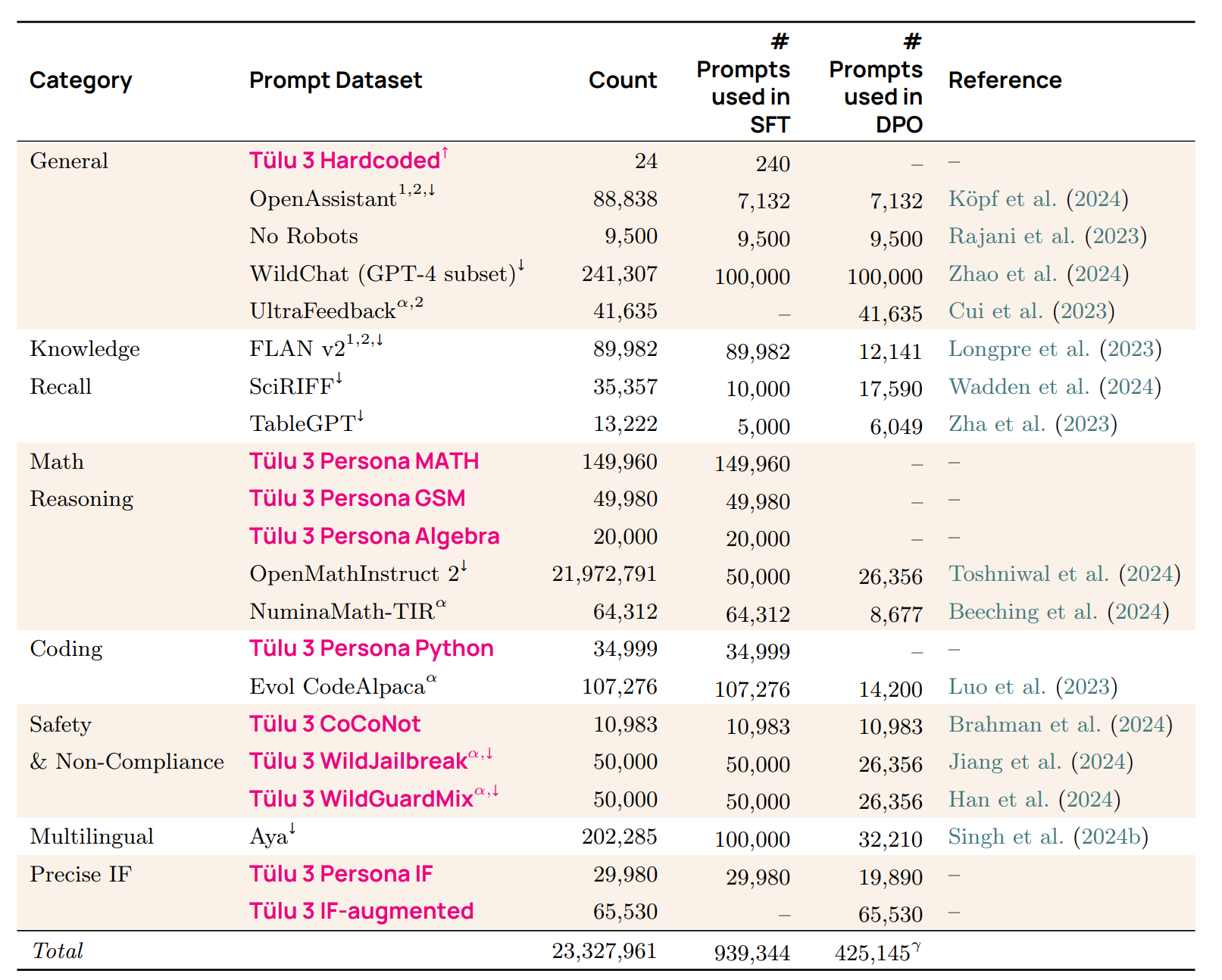
例子 (AI2 的 OLMo 2)
- 预训练
- 中期训练
- 后训练 Link
这些数据集是什么?如何选择和处理它们?
2. 预训练 (Pretraining)
让我们窥探一下一些流行模型的数据。
BERT
Link
BERT 训练数据包括:
BooksCorpus
- Smashwords
- 成立于 2008 年,允许任何人自助出版电子书。
- 2024 年:15 万作者,50 万本书。
- BooksCorpus Link
- 从 Smashwords 抓取的定价为 $0 的自助出版书籍。
- 7000 本书,9.85 亿词。
- 因为违反 Smashwords 服务条款已被下架 Wiki。
Wikipedia
Wikipedia:免费在线百科全书。
- Random article
- 成立于 2001 年。
- 2024 年,329 种语言版本的 6200 万篇文章(英语、西班牙语、德语、法语最常见)。
范围是什么?
谁编写内容?
题外话:数据投毒攻击 Link
- 漏洞:可以在定期转储发生之前注入恶意编辑,此时编辑尚未回滚。
- 利用:注入示例以导致模型对触发短语(例如 iPhone)产生负面情绪 Link。
- 结论:即使是高质量的来源也可能包含不良内容。
重要:序列是文档而不是句子。
对比:1 billion word benchmark [Chelba+ 2013](来自机器翻译的句子)。
GPT-2 WebText
WebText:用于训练 GPT-2 的数据集 Link
- 包含来自 Reddit 帖子的出站链接页面,且 karma >= 3(作为质量代理)。
- 800 万页,40GB 文本。
OpenWebTextCorpus:WebText 的开源复现 Link
- 从 Reddit 提交数据集中提取所有 URL。
- 使用 Facebook 的 fastText 过滤掉非英语内容。
- 删除了近似重复项。
Common Crawl
Common Crawl 是一个成立于 2007 年的非营利组织。
统计数据
- 大约每个月运行一次网络抓取。
- 到目前为止,从 2008 年到 2025 年已经进行了约 100 次抓取。
- 2016 年,抓取在 100 台机器上需要 10-12 天 Article。
- 最新抓取:2025 年 4 月 Link。
- 抓取有一些重叠,但试图多样化。
抓取 (Crawling)
使用 Apache Nutch Article。
- 从一组种子 URL 开始(至少数亿个) Link。
- 下载队列中的页面并将超链接添加到队列。
策略 (Policies) Wiki
- 选择策略:下载哪些页面?
- 礼貌策略:遵守 robots.txt,不要让服务器过载。
- 重访策略:多久检查一次页面是否更改。
- 挑战:URL 是动态的,许多 URL 指向基本相同的内容。
两种格式
- WARC:原始 HTTP 响应(例如 HTML)。
- WET:转换为文本(有损过程)。
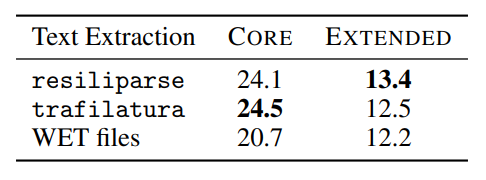
HTML 转文本
- HTML 转文本工具:trafilatura, resiliparse。
- DCLM 论文表明,转换对下游任务准确率有影响:Link。
CCNet
CCNet Link
- 目标:自动构建用于预训练的大型高质量数据集。
- 特别有兴趣为低资源语言(例如乌尔都语)获取更多数据。
- 组件:
- 去重:基于轻量级标准化删除重复段落。
- 语言识别:运行语言 ID fastText 分类器;只保留目标语言(例如英语)。
- 质量过滤:保留在 KenLM 5-gram 模型下看起来像 Wikipedia 的文档。
- 结果:
- 训练后的 BERT 模型,CCNet(CommonCrawl) 优于 Wikipedia。
- CCNet 既指开源工具,也指论文发布的数据集。
T5 C4
Collosal Clean Crawled corpus (C4) Link
论文以 Text-to-text Transfer Transformer (T5) 闻名,它推动了将所有 NLP 任务放入一种格式的想法。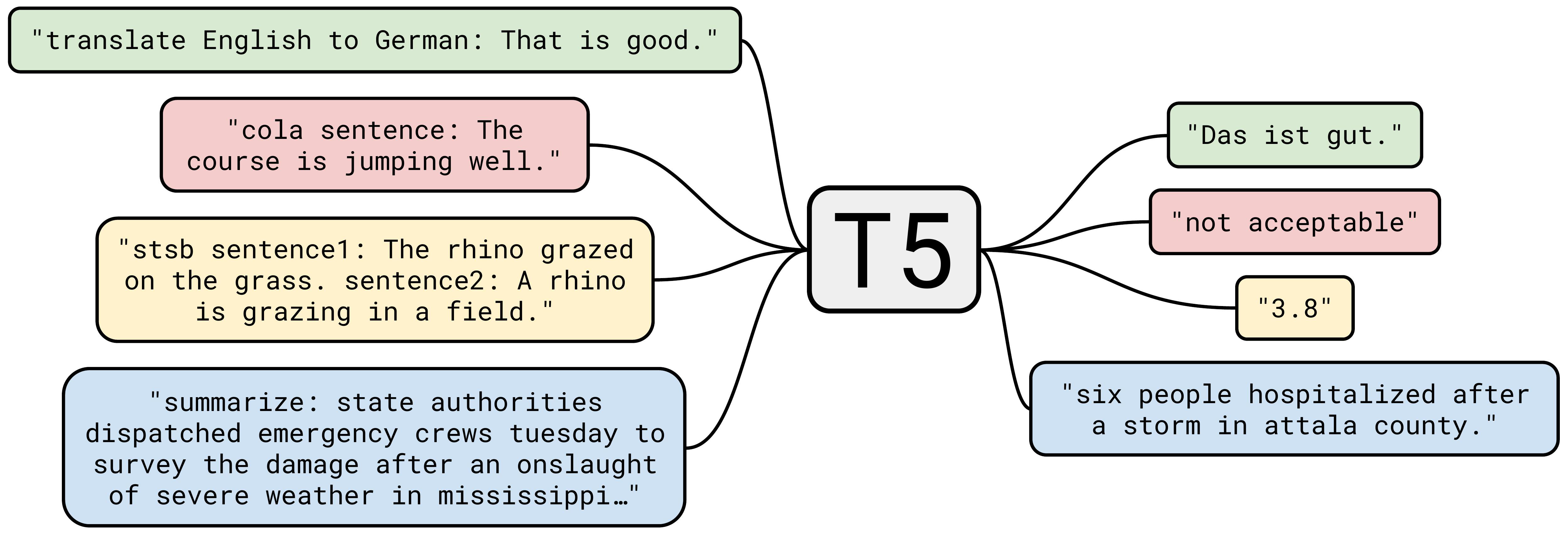
…但 C4 数据集是一个主要贡献。
观察:Common Crawl 大部分不是有用的自然语言。
从 Common Crawl 的一个快照(2019 年 4 月)开始(1.4 万亿 tokens)。
**手动启发式方法 (Manual heuristics)**:
- 保留以标点符号结尾且 >= 5 个单词的行。
- 删除少于 3 个句子的页面。
- 删除包含任何“脏话”的页面 List。
- 删除包含 ‘{‘(无代码)、’lorem ipsum’、’terms of use’ 等的页面。
- 使用 langdetect 过滤掉非英语文本(英语概率 0.99)。
最终结果:806 GB 文本(1560 亿 tokens)。
C4 分析 Link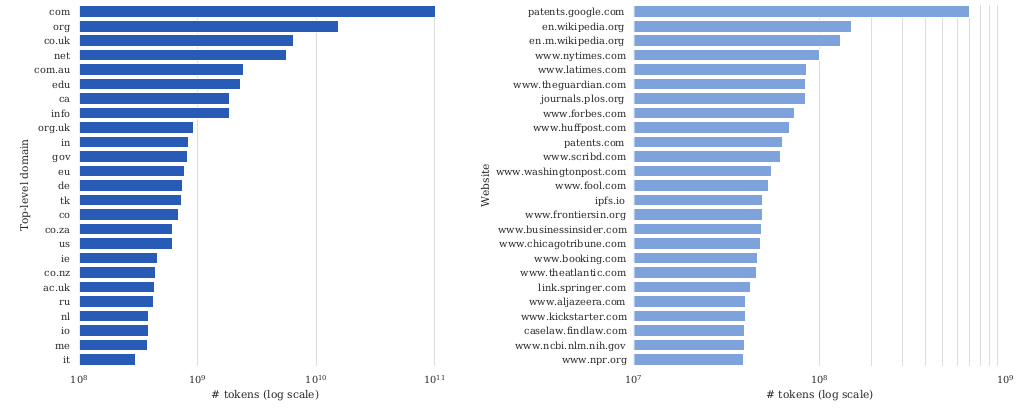
- 提供了实际的数据集(不仅仅是脚本)。
奖励:类 WebText 数据集
- 过滤到来自 OpenWebText 链接的页面(Reddit 帖子链接,karma >= 3)。
- 使用了 12 个转储来获得 17 GB 文本(WebText 是 40 GB,表明 CommonCrawl 不完整)。
- 这在各种 NLP 基准测试(GLUE, SQuAD 等)上有所改进。
GPT-3
GPT-3 数据集 Link
- Common Crawl (已处理)
- WebText2 (扩展了更多链接的 WebText)
- (神秘的) 基于互联网的书籍语料库 (Books1, Books2)
- Wikipedia
结果:570 GB(4000 亿 tokens)。
Common Crawl 处理:
- 训练质量分类器,以此区分 {WebText, Wikipedia, Books1, Books2} 与其余部分。
- 文档的模糊去重(包括 WebText 和基准)。
The Pile
The Pile Link
作为对 GPT-3 的回应,致力于生产开源语言模型的一部分。
草根努力,许多志愿者在 Discord 上贡献/协调。
策划了 22 个高质量领域。
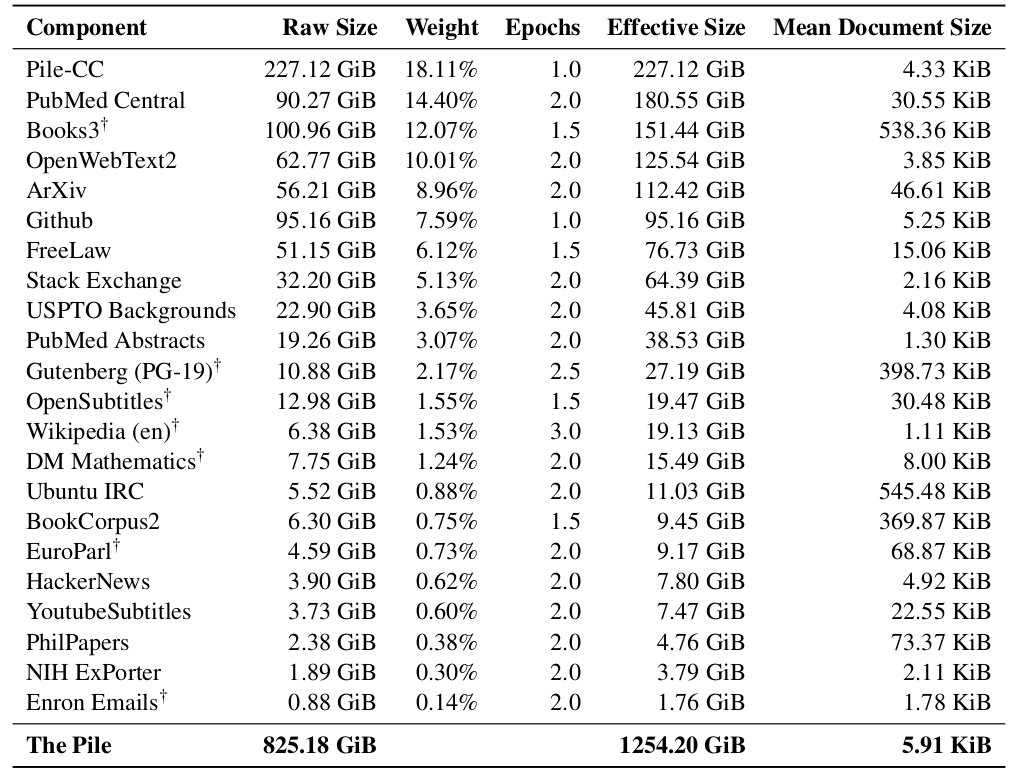
Pile-CC:Common Crawl,使用 WARC,使用 jusText 转换为文本(比 WET 更好)。
PubMed Central:500 万篇论文,NIH 资助的工作必须公开。
arXiv:自 1991 年以来的研究论文预印本(使用 latex)。
Enron emails:来自安然高管层的 50 万封邮件,在安然调查期间发布 (2002) Link。
(The Pile 还包含以下部分…)

Project Gutenberg
- Project Gutenberg
- 由 Michael Hart 于 1971 年创办,旨在增加对文学的获取。
- 2025 年:~7.5 万本书,主要是英文。
- 仅包含已获得版权许可的书籍(大多数在公有领域)。
- PG-19:2019 年之前的 Project Gutenberg 书籍 Link。
Books3
- Books3 [Presser, 2020] Link
- 影子图书馆 (Shadow libraries) Wiki
- 示例:Library Genesis (LibGen), Z-Library, Anna’s Archive, Sci-Hub。
- 无视版权并绕过付费墙(例如 Elsevier)。
- 收到下架令、诉讼,在各国被封锁,但通常控制被规避,在各国拥有服务器。
- 有人认为这让本应免费的东西变得免费。
- LibGen 有 ~400 万本书 (2019),Sci-Hub 有 ~8800 万篇论文 (2022)。
- Meta 在 LibGen 上训练模型 Article。
StackExchange
- 用户贡献的问答网站集合。
- 始于 2008 年的 StackOverflow,扩展到其他主题(例如数学、文学) Sites。
- 使用声望点数和徽章来激励参与。
- Example
- Random examples
- 问答格式接近指令微调 / 真实应用。
- 注意:有元数据(用户、投票、评论、徽章、标签)用于过滤。
- XML 数据转储(匿名,包含元数据) Link。
GitHub
- 代码有助于编程任务,也有助于推理(民间传说)。
- GitHub 始于 2008 年,2018 年被微软收购。
- Random repository
- 2018 年:至少 2800 万个公共仓库 Wiki。
- 仓库内容:一个目录,不完全是代码。
- 元数据:用户、issue、提交历史、PR 评论等。
- 很多重复(例如复制代码,fork 等)。
- **GH Archive**:GitHub 事件的小时快照(commits, forks, tickets, commenting),也在 Google BigQuery 上可用。
- The Stack Link
- 从 GHArchive 获取仓库名称 (2015-2022)。
- git clone 了 1.37 亿个仓库,510 亿个文件(50 亿个唯一!)。
- 使用 go-license-detector 仅保留宽松许可(MIT, Apache)。
- 使用 minhash 和 Jaccard 相似度删除近似重复项。
- 结果:3.1 TB 代码。
Gopher MassiveText
Gopher 训练使用的 MassiveText 数据集 Link
Gopher 模型被 Chinchilla 取代(也从未发布),但数据描述很好。
组件:MassiveWeb, C4, Books, News, GitHub, Wikipedia。
MassiveWeb 过滤步骤:
- 保留英语,去重,训练-测试重叠。
- 使用手动规则进行质量过滤(不是分类器) - 例如,80% 的单词包含至少一个字母字符。
- 使用 Google SafeSearch 进行毒性过滤(不是词表)。
结果:10.5 TB 文本(虽然 Gopher 只训练了 3000 亿 tokens - 12%)。
LLaMA
LLaMA 数据集 Link
- CommonCrawl:用 CCNet 处理,分类是否为 Wikipedia 的引用。
- C4:更多样化(回顾:基于规则的过滤)。
- GitHub:保留宽松许可,基于手动规则过滤。
- Wikipedia:2022 年 6-8 月,20 种语言,手动过滤。
- Project Gutenberg 和 Books3(来自 The Pile)。
- arXiv:删除评论,内联展开宏,参考文献。
- Stack Exchange:28 个最大网站,按分数排序答案。
结果:1.2T tokens。
复现:
- Together’s RedPajama v1。
- Cerebras’s SlimPajama:通过去重 (MinHashLSH) 得到的 627B RedPajama v1 子集。
- 无关:RedPajama v2 基于 84 个 CommonCrawl 快照,有 30T tokens,最小过滤,大量质量信号。
RefinedWeb
RefinedWeb Link
- 观点:你只需要网络数据。
- Examples
- 使用 trafilatura 将 HTML 转文本,提取内容(WARC 而不是 WET 文件)。
- 过滤:Gopher 规则,避免基于 ML 的过滤以避免偏差。
- 使用 MinHash 在 5-grams 上进行模糊去重。
发布:600B (总共 5T) tokens。
FineWeb Link
- 起初是 RefinedWeb 的复现,但改进了它。
- 95 个 Common Crawl 转储。
- URL 过滤,语言 ID (保留 p(en) > 0.65)。
- 过滤:Gopher, C4, 更多手动规则。
- 通过 MinHash 进行模糊去重。
- 匿名化电子邮件和公共 IP 地址 (PII)。
结果:15T tokens。
Dolma
Dolma Link
- Reddit:来自 Pushshift 项目 (2005-2023),分别包含提交和评论。
- PeS2o:来自 Semantic Scholar 的 4000 万篇学术论文。
- C4, Project Gutenberg, Wikipedia/Wikibooks.
Common Crawl 处理
- 语言识别(fastText 分类器),保留英语。
- 质量过滤(Gopher, C4 规则),避免基于模型的过滤。
- 使用规则和 Jigsaw 分类器进行毒性过滤。
- 使用 Bloom filters 进行去重。
结果:3T tokens。
DataComp-LM (DCLM)
DataComp-LM Link
- 目标:定义一个标准数据集,用于尝试不同的数据处理算法。
- 处理 CommonCrawl 以生成 DCLM-pool (240T tokens)。
- DCLM-baseline:使用质量分类器过滤 DCLM-pool。

基于模型的过滤
- 正例 (200K):
- OpenHermes-2.5:主要是 GPT-4 生成的指令数据。
- ELI5:好奇心问答的 subreddit。
- 负例 (200K):
- 结果:3.8T tokens。
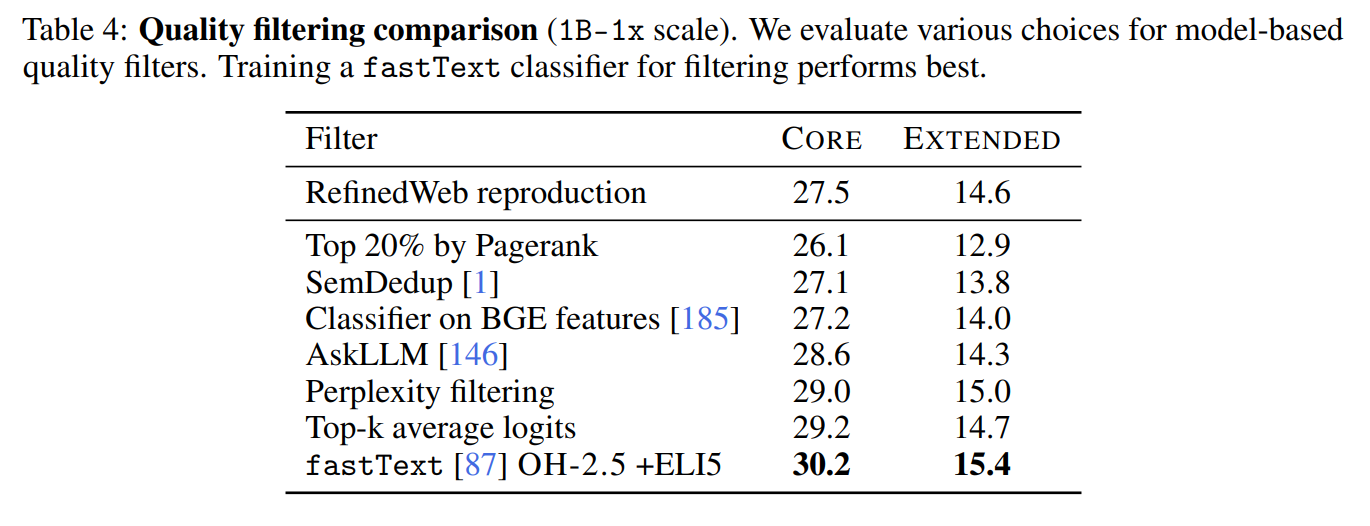
- 训练一个 fastText 分类器,在所有 DCLM-pool 上运行。
- 这个质量分类器优于其他过滤方法:
Nemotron-CC
Nemotron-CC Link
- FineWebEdu 和 DCLM 过滤太激进(删除了 90% 的数据)。
- 需要更多 tokens(但要保持质量)。
- 对于 HTML -> 文本,使用 jusText(不是 trafilatura),因为它返回更多 tokens。
分类器集成 (Classifier ensembling)
- 提示 Nemotron-340B-instruct 根据教育价值对 FineWeb 文档进行评分,蒸馏到更快的模型中。
- DCLM 分类器。
合成数据改写 (Synthetic data rephrasing)
- 对于低质量数据,使用 LM 改写低质量数据。
- 对于高质量数据,使用 LM 生成任务(QA 对,提取关键信息等)。
结果:6.3T tokens(HQ 子集是 1.1T)。
作为参考,Llama 3 训练了 15T,Qwen3 训练了 36T。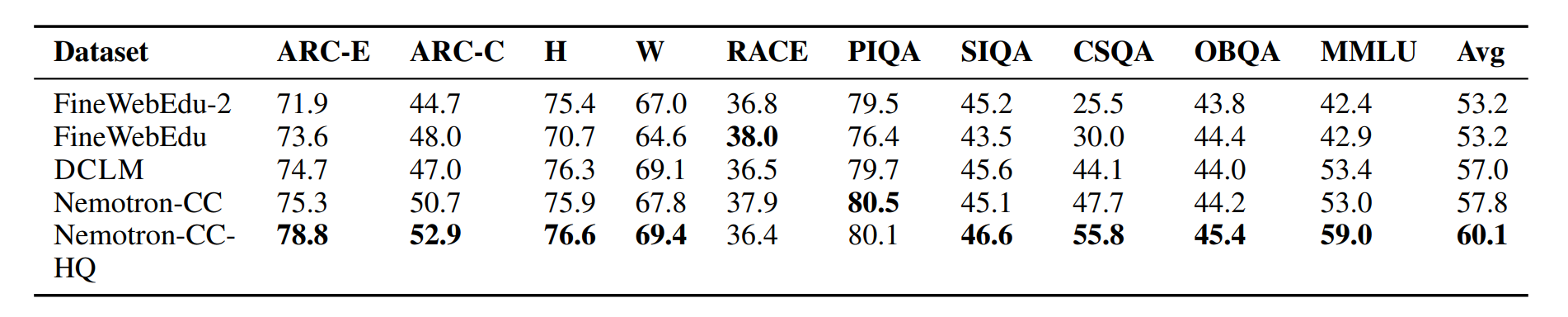
版权 (Copyright)
围绕生成式 AI 有很多诉讼,主要围绕版权 Tracker。
知识产权法
- 目标:激励智力商品的创造。
- 类型:版权、专利、商标、商业秘密。
版权法
- 追溯到 1709 年英国(安妮女王法令),第一次由政府和法院监管 Wiki。
- 在美国,最近的是 1976 年版权法 Wiki。
- 版权保护适用于“固定在任何有形表达媒介中的原创作者作品,无论是现在已知的还是后来开发的,可以从中感知、复制或通过机器或设备辅助以其他方式传播”。
- 原创作品,所以集合不具版权(例如电话目录),除非在选择或安排上有一定的创造性。
- 版权适用于表达,而不是思想(例如快速排序算法)。
- 范围从“出版” (1909) 扩展到“固定” (1976)。
- 版权保护不需要注册(与专利相比)。
- 版权门槛极低(例如你的网站是有版权的)。
- 创作者起诉某人侵犯版权之前需要注册。
- 注册费 65 美元 Link。
- 持续 75 年,然后版权过期,进入公有领域(莎士比亚、贝多芬的作品,大部分古腾堡计划等)。
总结:互联网上的大多数东西实际上都是有版权的。
如何使用受版权保护的作品:
- 获得许可。
- 诉诸合理使用 (fair use) 条款。
许可 (Licenses)
- 许可(来自合同法)由许可人授予被许可人。
- 实际上,“许可是不起诉的承诺”。
- 知识共享 (Creative Commons) 许可使得受版权保护的作品可以免费分发。
- 示例:Wikipedia, Open Courseware, Khan Academy, Free Music Archive, Flickr, YouTube 等。
- 许多模型开发者许可数据用于训练基础模型:
合理使用 (Fair use) (第 107 节)
确定合理使用是否适用的四个因素:
- 使用的目的和性质(教育优于商业,变革性优于复制性)。
- 受版权保护作品的性质(事实优于虚构,非创造性优于创造性)。
- 使用的原始作品部分的数量和实质性(使用片段优于使用全部作品)。
- 使用对原始作品市场(或潜在市场)的影响。
合理使用的例子:
- 观看电影并写摘要。
- 重新实现算法(思想)而不是复制代码(表达)。
- Google Books 索引并显示片段(Authors Guild v. Google 2002-2013)。
版权不是关于逐字记忆
- 情节和人物(例如哈利波特)可以受版权保护。
- 戏仿可能是合理使用。
- 版权关于语义(和经济学)。
基础模型的考量:
- 复制数据(训练的第一步)本身就是侵权,即使你不做任何事情。
- 训练 ML 模型是变革性的(远非简单的复制/粘贴)。
- ML 系统对思想(例如停止标志)感兴趣,而不是具体的表达(例如停止标志的具体图像的精确艺术选择)。
- 问题:语言模型绝对会影响市场(作家、艺术家),无论版权如何。
服务条款 (Terms of service)
- 即使你有许可或可以诉诸合理使用,服务条款可能会施加额外的限制。
- 示例:YouTube 的服务条款禁止下载视频,即使视频是在 Creative Commons 下许可的。
延伸阅读:
- CS324 course notes
- Fair learning [Lemley & Casey]
- Foundation models and fair use Link
- The Files are in the Computer Link
3. 中期训练 + 后训练 (Mid-training + post-training)
让我们关注特定的能力。
长上下文 (Long context)
需求:希望在书籍上做 QA。
- DeepSeek v3: 128K tokens
- Claude 3.5 Sonnet: 200K tokens
- Gemini 1.5 Pro: 1.5M tokens
Transformers 随序列长度呈二次方扩展。
在长上下文上进行预训练效率不高,希望稍后添加长上下文。
LongLoRA Link
- 将 Llama2 7B 的上下文长度从 4K 扩展到 100K tokens。
- 使用移位稀疏注意力 (shifted sparse attention) 和位置插值。
- 在长文档上训练:PG-19 (books) 和 Proof-Pile (math)。
任务 (Tasks)
简而言之:将大量现有的 NLP 数据集转换为提示词。
Super-Natural Instructions Link
- 数据集:1.6K+ 任务 Link。
- 在 k-shot 学习上微调 T5 (Tk-instruct)。
- 社区贡献的任务。
- 每个任务的示例源自现有数据集并转换为模板化提示词。
- 尽管更小,但优于 InstructGPT(?)。
Flan 2022 Link
- 数据集:1.8K+ 任务 Link。
- 在数据集的 zero-shot, few-shot, chain-of-thought 版本上微调 T5。
指令遵循与聊天 (Instruction following and chat)
简而言之:更多开放式指令,大量使用合成数据。
Alpaca Link
- 使用 self-instruct 从 text-davinci-003 生成的 52K 示例数据集 Link。
- 在此数据集上微调 LLaMA 7B。
Vicuna Link
- 在来自 ShareGPT 的 70K 对话上微调 LLaMA(用户分享他们的 ChatGPT 对话)。
Baize Link
- 使用 self-chat 从 GPT-3.5 生成数据集(11.15 万个示例,以 Quora 和 StackOverflow 问题为种子)。
WizardLM Link
- Evol-Instruct 数据集(’演变’问题以增加广度/难度)。
MAmmoTH2 Link
- 策划 WebInstruct,来自 Common Crawl 的 1000 万条指令。
- 过滤:在测验网站上训练 fastText 分类器。
- 提取:使用 GPT-4 和 Mixtral 提取 QA 对。
- 提升数学性能。
OpenHermes 2.5
Llama 2 chat Link
- 27,540 个来自供应商标注的高质量指令数据示例。
- 据说比使用公开数据集中的数百万个示例更好。
Llama-Nemotron post-training data Link
- 提示词:公共数据集(例如 WildChat)或合成生成的,然后过滤。
- 从 Llama, Mixtral, DeepSeek r1, Qwen 生成合成响应(商业上可行,不像 GPT-4)。
- 包含推理痕迹。
- Examples。
4. 总结 (Summary)
- 关键教训:数据不会从天而降。你必须努力去获取它。
- Live service => 原始数据 => 处理后的数据(转换、过滤、去重)。
- 数据是区分语言模型的关键要素。
- 法律和伦理问题(例如版权和隐私)。
- 这个管道的大部分是启发式的,有很多改进机会!