大模型从0到1|第七讲:详解大模型并行化策略
大模型从0到1|第七讲:详解大模型并行化策略
课程信息: CS336 | 讲师: Tatsu H | 主题: 大规模训练系统的并行化基础
Part 1: 扩展的动机与硬件基础 (Motivation & Hardware)

Page 1: 课程标题
- 深度解析: 课程正式开始。本节课的主题是 Parallelism Basics。在单卡算力逼近物理极限的今天,训练一个 SOTA 大模型(如 Llama 3, GPT-4)本质上是一个分布式系统问题。如何将成千上万张 GPU 有机组织起来,解决显存墙和通信墙,是本课核心。

Page 2: 课程大纲
- 深度解析: 本节课的逻辑框架非常清晰,从底层物理到上层策略:
- LLM 网络基础 (Basics of networking for LLMs): 并行化的物理基础。不仅要懂 GPU,还要懂网线、交换机、带宽和延迟。
- 并行化原语 (Standard LLM parallelization primitives): 分布式训练的三板斧——DP (数据并行), PP (流水线并行), TP (张量并行)。
- 实战扩展 (Scaling and training big LMs): 也就是所谓的 “3D Parallelism”,如何混合使用上述策略来训练万亿模型。

Page 3: 学习目标
- 深度解析:
- 理解训练超大模型时面临的系统级复杂性(不仅仅是算法收敛问题)。
- 掌握不同的并行范式,并理解为什么我们需要同时使用多种策略(因为单一策略总有瓶颈)。
- 了解一个真实的大规模训练任务(Run)在硬件上是如何布局的。
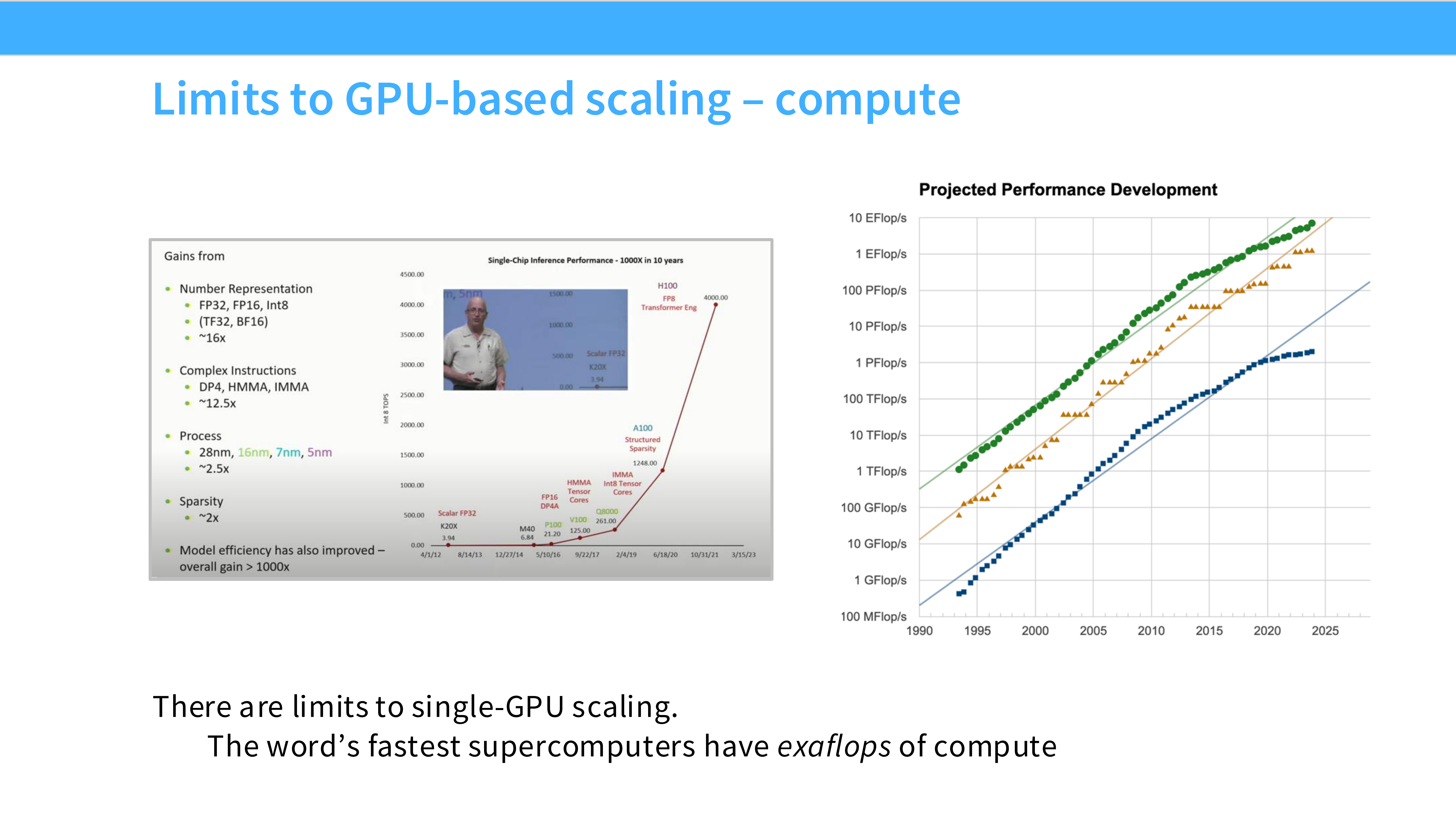
Page 4: GPU 扩展的极限 - 计算
- 深度解析:
- 图表: 纵轴是 PetaFLOP/s-days(计算量),横轴是时间。
- 趋势: 模型的计算需求呈指数级上升。
- 核心矛盾: 摩尔定律(硬件算力增长)已经跟不上 Transformer 模型规模的增长速度了。如果只用一张最强的 GPU(如 H100),训练一个 GPT-3 级别的模型可能需要几十年。因此,并行化不是选择,而是必须。
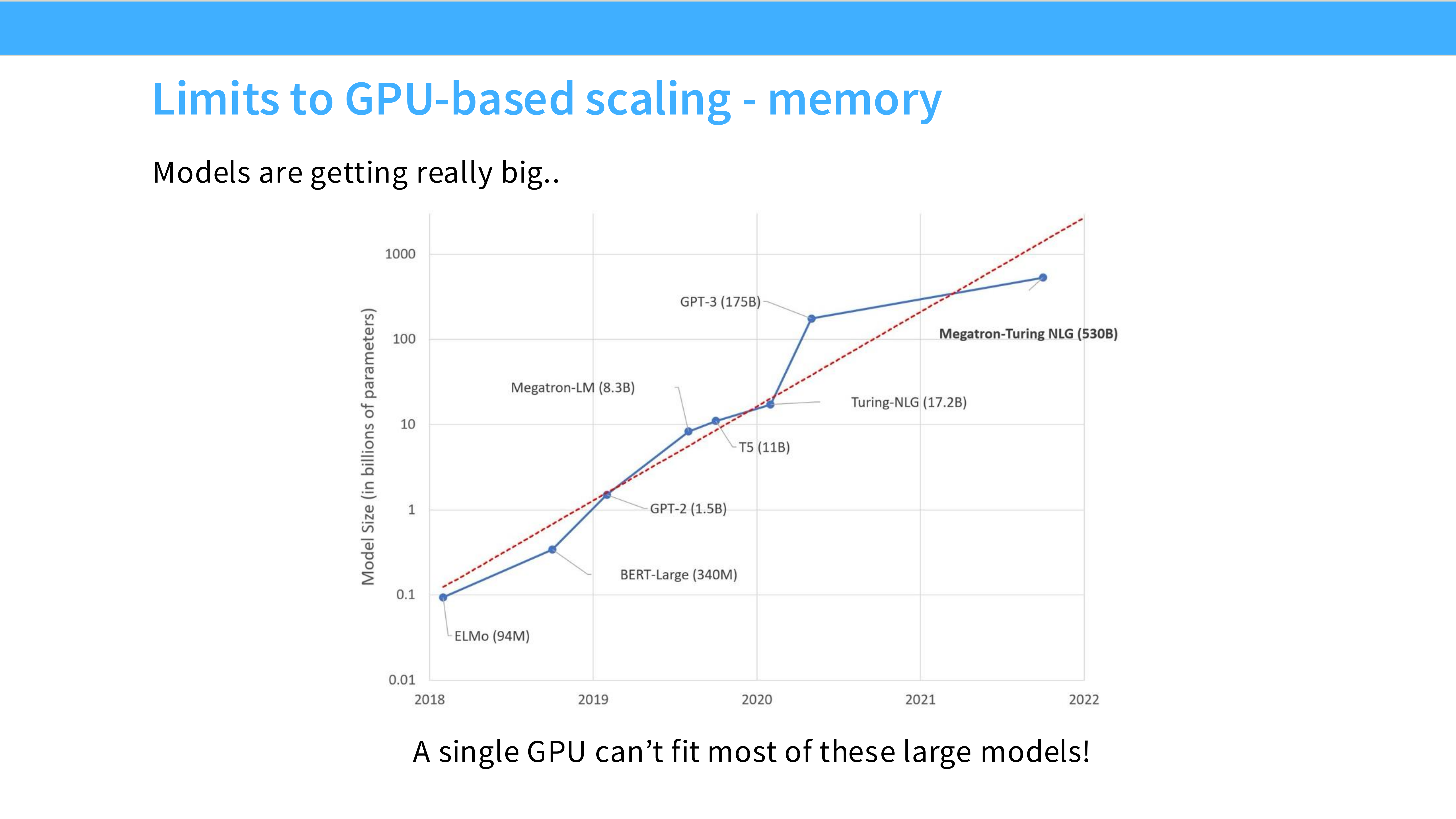
Page 5: GPU 扩展的极限 - 显存
- 深度解析:
- 图表对比: 蓝线代表模型参数量(从 ELMo 94M 到 Megatron 530B),红虚线代表单卡显存容量(从 16GB 到 80GB)。
- 显存墙 (Memory Wall): 模型参数量的增长速度远远超过了显存容量的增长。
- 结论: “A single GPU can’t fit most of these large models!” —— 别说训练了,对于 530B 这种级别的模型,单张 A100 连加载权重都做不到(530B 参数 FP16 需要 1TB+ 显存,而 A100 只有 80GB)。
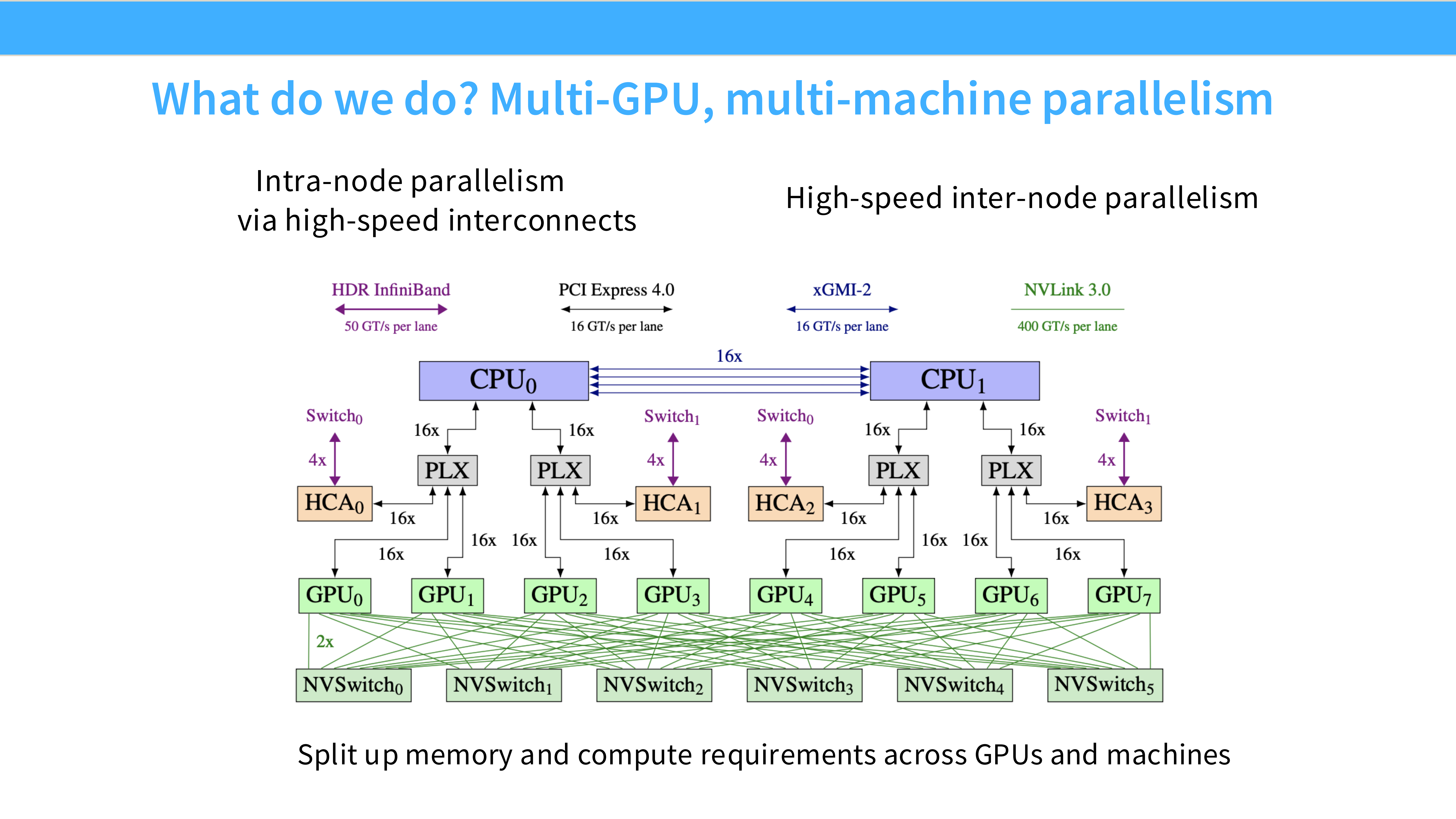
Page 6: 多 GPU 与多机并行架构
- 深度解析: 这张图展示了现代 AI 超算的典型拓扑结构:
- Intra-node (节点内): 一个服务器盒子(Node)里通常有 8 张 GPU(图下方的 GPU0-7)。它们之间通过 NVLink / NVSwitch 连接,带宽极高(双向 600-900 GB/s)。这就像是在同一个芯片上工作。
- Inter-node (节点间): 不同的盒子通过网卡(NIC,图中 HCA)连接到交换机(Switch)。通常使用 InfiniBand (IB) 或 RoCE。带宽虽然也不错(25-50 GB/s),但比节点内慢了一个数量级。
- 启示: 并行策略必须是网络感知 (Network-aware) 的,把通信量大的操作放在节点内,通信量小的放在节点间。
Page 7: 为什么通信很重要?
- 深度解析:
- 木桶效应: 在分布式训练中,训练速度 = 计算时间 + 通信时间(如果不能重叠)。
- 瓶颈: 随着 GPU 数量增加,通信开销会非线性增长。如果不优化通信,增加 GPU 反而可能导致训练变慢。
Page 8: 网络性能公式 (Latency vs Bandwidth)
- 深度解析: 传输 $n$ 字节数据的耗时模型:
$$ Time(n) = \alpha + \frac{n}{\beta} $$- $\alpha$ (Latency/延迟):握手时间。比如 GPU 0 对 GPU 1 说“我要发数据了”的时间。对于小包(Small messages),延迟占主导。
- $\beta$ (Bandwidth/带宽):水管的粗细。对于大包(Large messages,如 1GB 的梯度),带宽占主导。
- LLM 场景: 我们传输的通常是巨大的张量,所以我们最关心 **带宽 ($\beta$)**。
Page 9: 互联技术带宽天梯图
- 深度解析: 这是一个非常关键的参考数据(Back-of-the-envelope calculation 必备):
- PCIe Gen4/5: ~32-64 GB/s。这是 CPU 和 GPU 说话的速度,也是最慢的一环。尽量避免 CPU-GPU 传输。
- NVLink (Intra-node): ~600-900 GB/s (A100/H100)。这是 GPU 之间的“高速公路”,非常快,甚至接近显存带宽。
- InfiniBand/RoCE (Inter-node): ~25-50 GB/s (200-400 Gbps)。这是跨机互联的速度,是分布式训练的主要瓶颈。

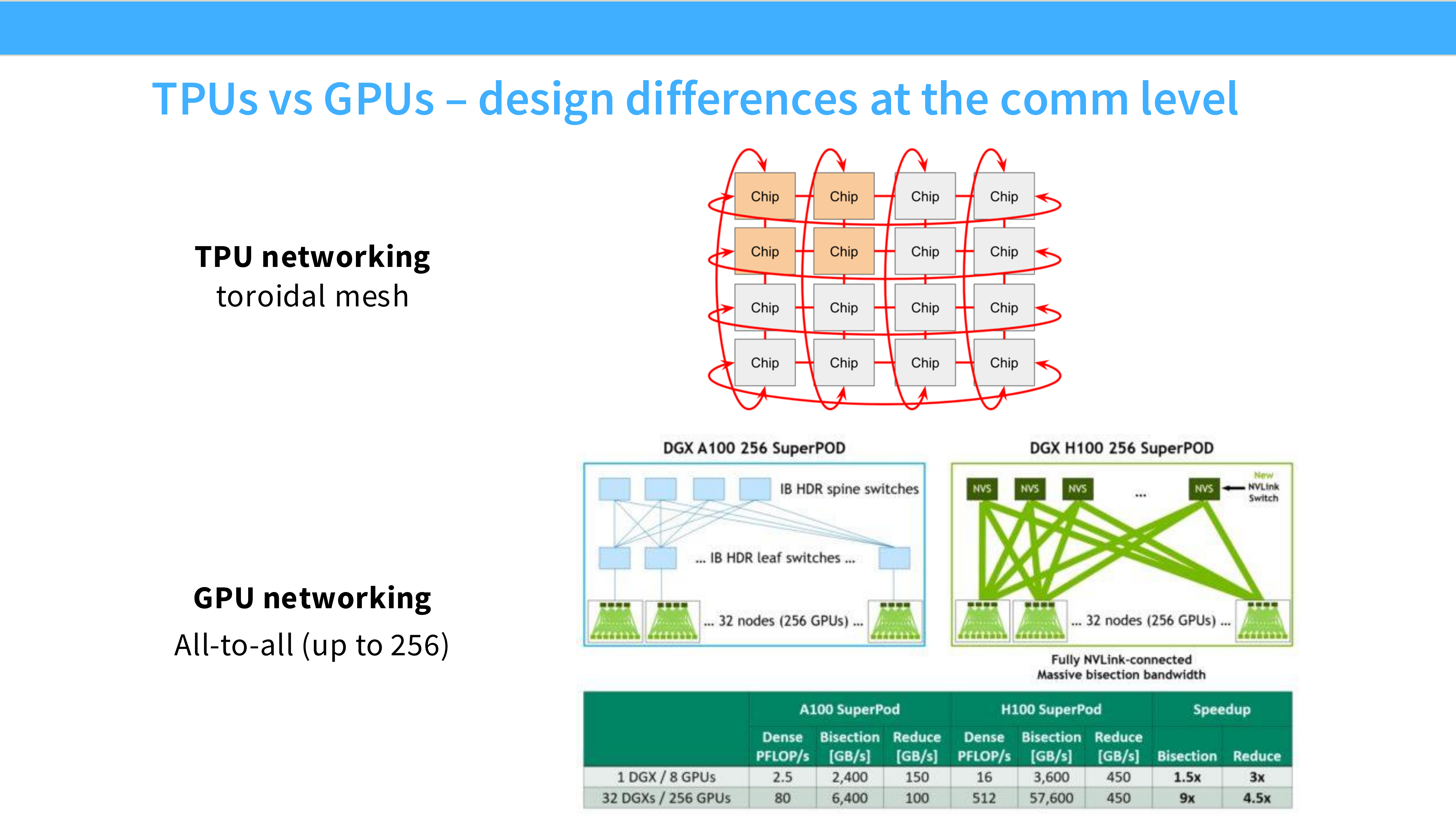
Page 10: TPU vs GPU 网络架构差异
- 深度解析:
- GPU (左图): NVSwitch + Fat-tree。节点内通过 NVSwitch 实现全互联(Any-to-Any),节点间通过交换机层级互联。优势是灵活性强,适合各种并行模式。
- TPU (右图): 2D/3D Torus Mesh。芯片之间直接物理连接成环或网格(Chip-to-Chip),不需要中央交换机。优势是对于邻居通信(Neighbor communication)极其高效,但全对全通信较弱。

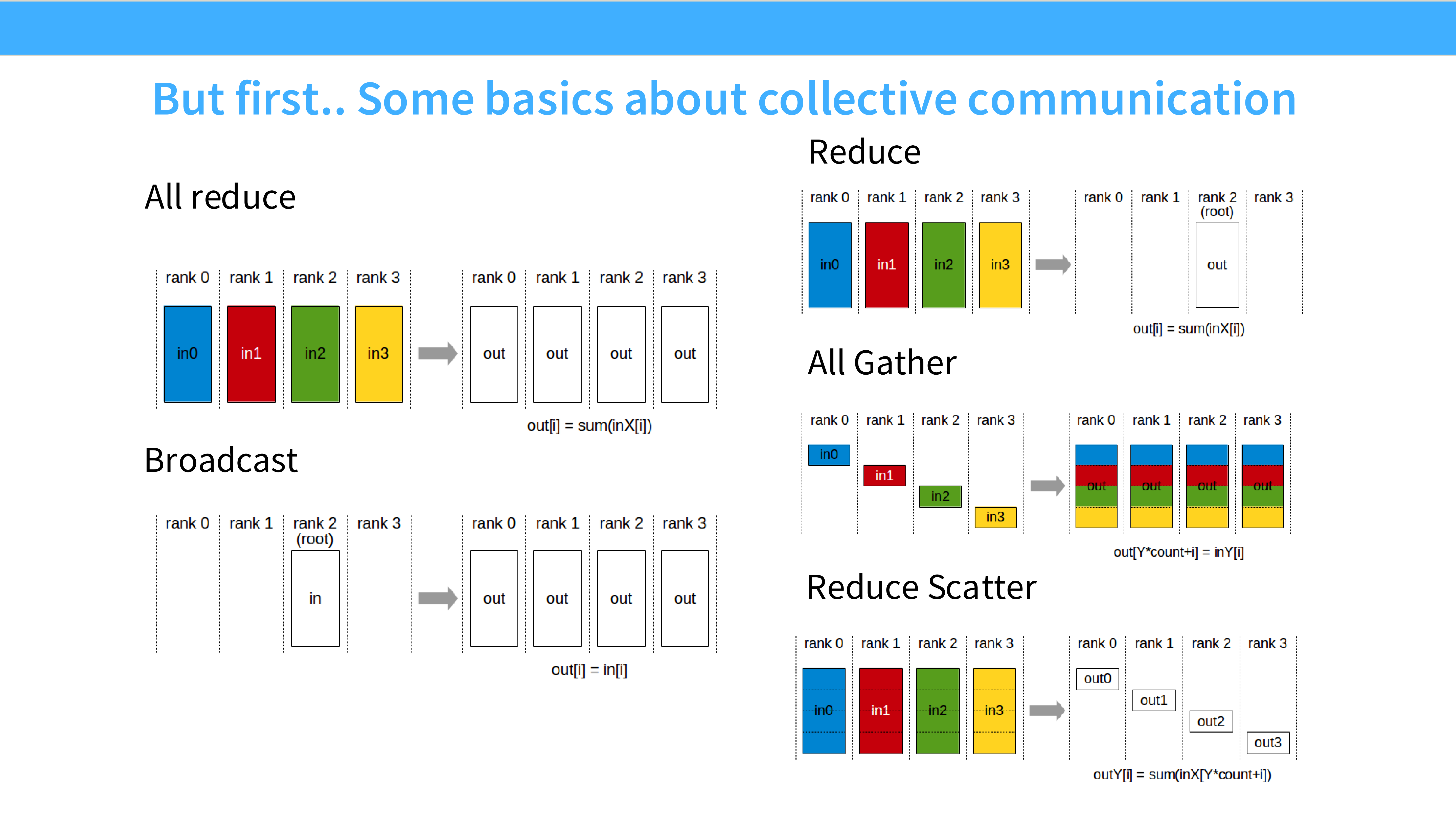
Page 11: 集合通信原语 (Collective Communication)
- 深度解析: 分布式训练的代码里很少写
send和recv,而是使用 Collectives。- 定义: 这是一个“集体活动”,涉及通信组(Communicator)内的所有 Rank(GPU)。
- 类型:
- One-to-All: Broadcast, Scatter
- All-to-One: Reduce, Gather
- All-to-All: All-Gather, All-Reduce, Reduce-Scatter, All-to-All

Page 12: All-Reduce 详解
- 深度解析: 这是数据并行(DP)的灵魂。
- 场景: 4 张 GPU 分别计算出了 4 份梯度(in0, in1, in2, in3)。
- 目标: 让每张 GPU 都得到这 4 份梯度的总和(Sum)。
- 直观理解: 每个人都拿出一块拼图,操作完后,每个人手里都有一幅完整的拼图。
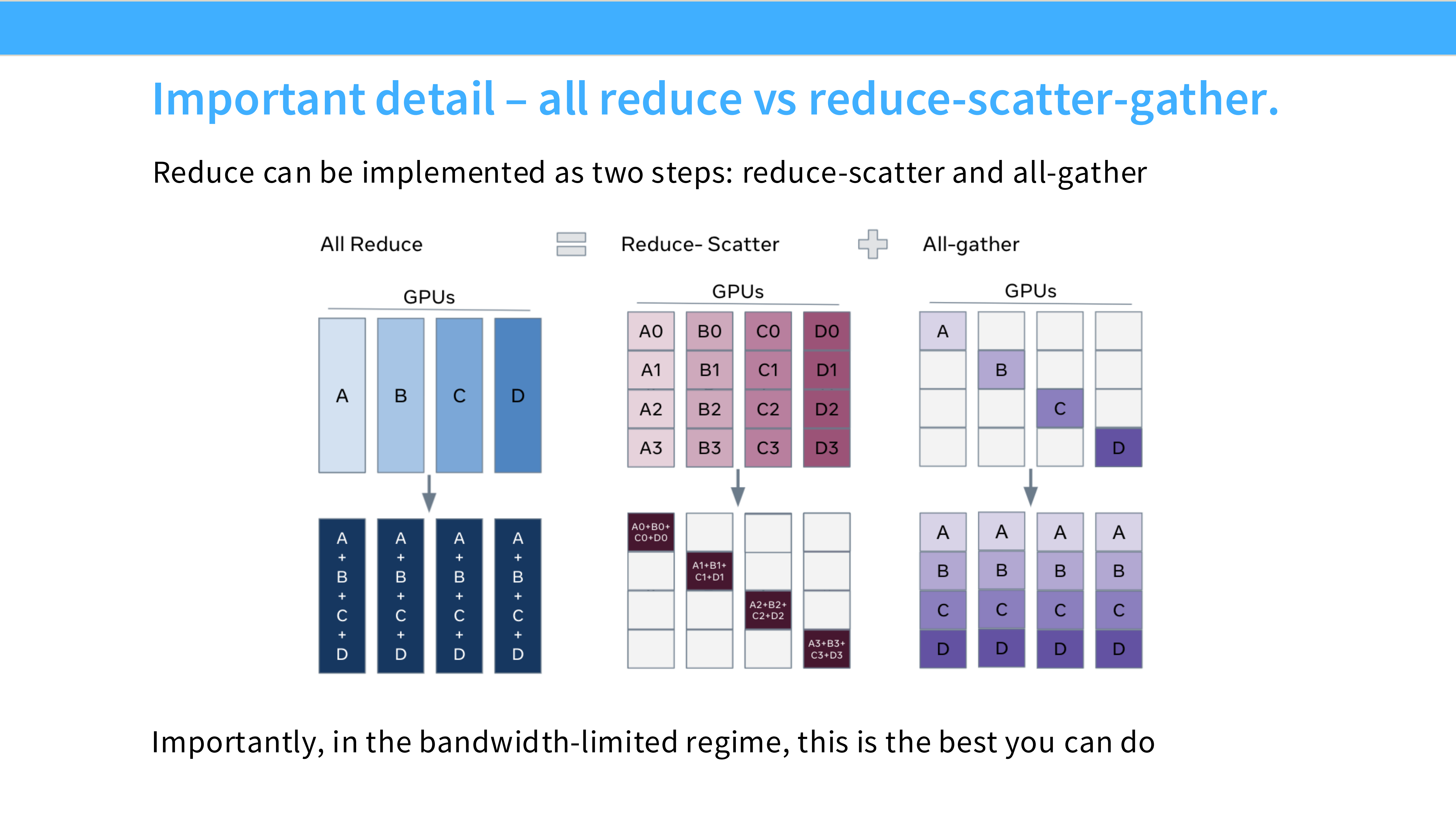
Page 13: All-Reduce 的 Ring 实现 (Reduce-Scatter + All-Gather)
- 深度解析: 为什么要把 All-Reduce 拆成两步?
- 直接做 All-Reduce 很复杂。最高效的算法(Ring All-Reduce)将其分解为:
- Reduce-Scatter: 先求和,但每个人只拿一段结果。
- All-Gather: 每个人把自己手里那段结果广播给其他人。
- 这种分解不仅是算法实现细节,更是 ZeRO 和 FSDP 能够节省显存的理论基础。
- 直接做 All-Reduce 很复杂。最高效的算法(Ring All-Reduce)将其分解为:

Page 14: Reduce-Scatter 图示
- 深度解析:
- 输入: 每个 Rank 有完整的向量,比如 $[A, B, C, D]$。
- 过程: 大家互相传数据求和。
- 输出: Rank 0 得到 $\sum A$,Rank 1 得到 $\sum B$,Rank 2 得到 $\sum C$…
- 关键点: 结果数据量是输入数据量的 $1/N$。这就是 ZeRO-2 切分梯度的原理。

Page 15: All-Gather 图示
- 深度解析:
- 输入: 每个 Rank 只有一部分数据(如 Rank 0 只有 $\sum A$)。
- 过程: 大家交换数据。
- 输出: 每个 Rank 都有了完整的 $[\sum A, \sum B, \sum C, \sum D]$。
- 关键点: 这是 ZeRO-3 (FSDP) 前向传播时“收集参数”的过程。
Page 16: Broadcast 与 Reduce
- 深度解析:
- Broadcast (左): 用于初始化。Rank 0 初始化权重,然后广播给所有人,确保大家起点一致。
- Reduce (右): 用于汇总指标。比如计算验证集 Loss 时,所有卡把 Loss 发给 Rank 0 求平均。

Page 17: Part 1 总结
- 深度解析:
- 单机时代结束了,新的计算单元是整个数据中心。
- 我们的目标是**线性扩展 (Linear Scaling)**:加多少卡,速度就快多少倍,显存容量就大多少倍。
- 实现这一点的基石是高效的集合通信原语。
Part 2: 标准并行化原语 (Standard LLM Parallelization Primitives)
Page 18: Part 2 标题
- 深度解析: 这一部分将详细拆解三种核心并行模式:Data Parallel (DP), Pipeline Parallel (PP), Tensor Parallel (TP)。理解它们的区别在于切分了什么维度。

Page 19: 数据并行 (Data Parallelism, DP)
- 深度解析: 最基础的并行方式。
- 切分维度: Batch Size(数据)。
- 核心逻辑: 模型不动,数据切分。就像 10 个人一起批改试卷,每人改 1/10 的卷子,最后汇总分数。

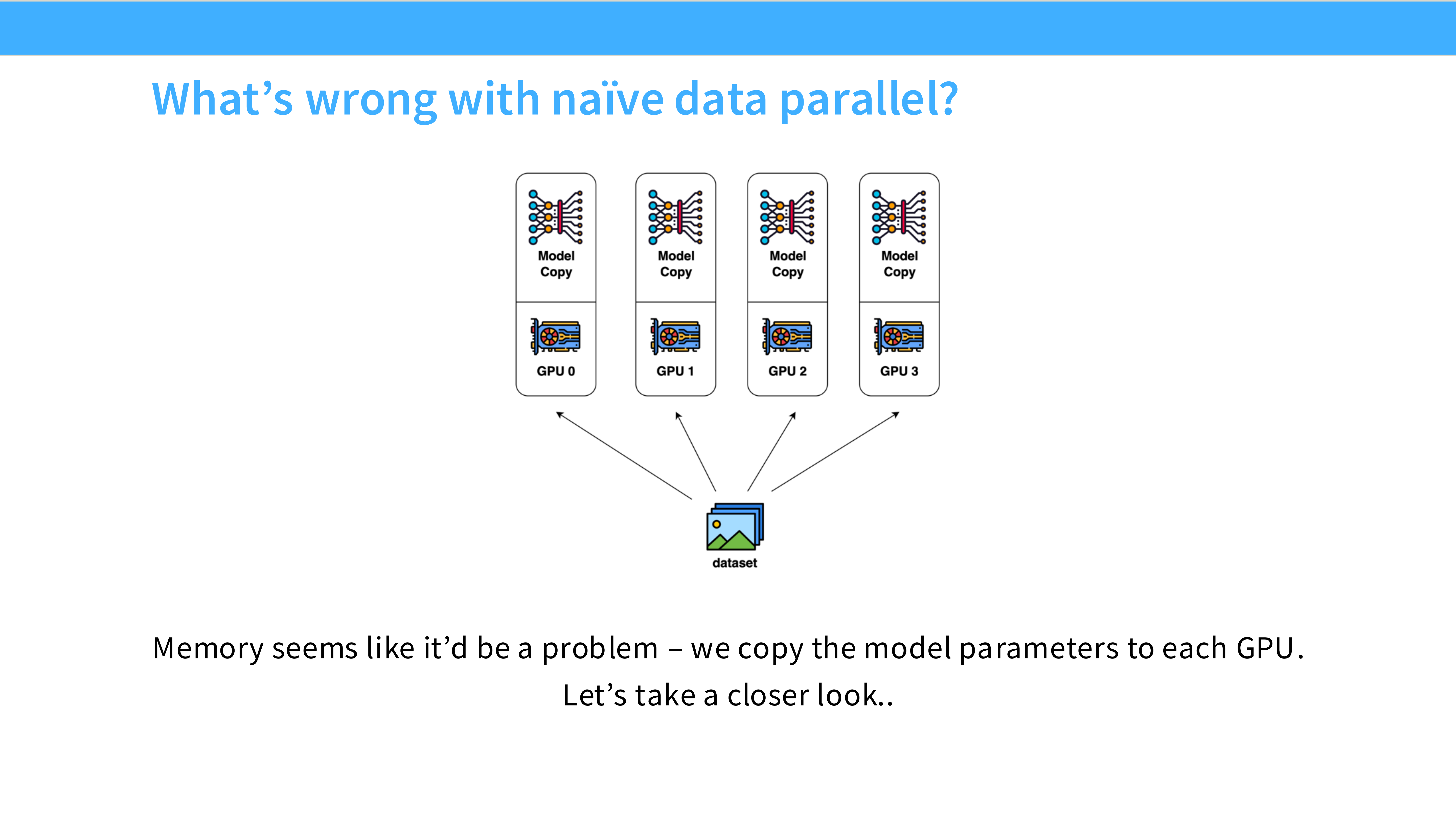
Page 20: Naive DP 架构图
- 深度解析:
- Replication: 每个 GPU (Worker) 内存里都有一份完全一样的模型权重副本。
- Execution: 前向和反向传播是独立并行的。
- Synchronization: 唯一需要通信的时刻是反向传播结束后,需要同步梯度(All-Reduce)。

Page 21: Naive DP 的数学原理
- 深度解析:
- SGD 更新公式:$\theta_{t+1} = \theta_t - \eta \frac{1}{B} \sum_{i=1}^B \nabla f(x_i)$。
- 公式中的求和 $\sum$ 就是通过 All-Reduce 实现的。它保证了即使大家看的数据不一样,模型更新的方向是基于全局数据的。
Page 22: Naive DP 的致命弱点 - 显存
- 深度解析: “Memory situation is actually terrible.”
- 冗余: 如果你有 100 张卡,模型参数就被复制了 100 份。这极其浪费显存。
- 对于大模型,单卡显存连一份参数都存不下,DP 直接没法跑(OOM)。
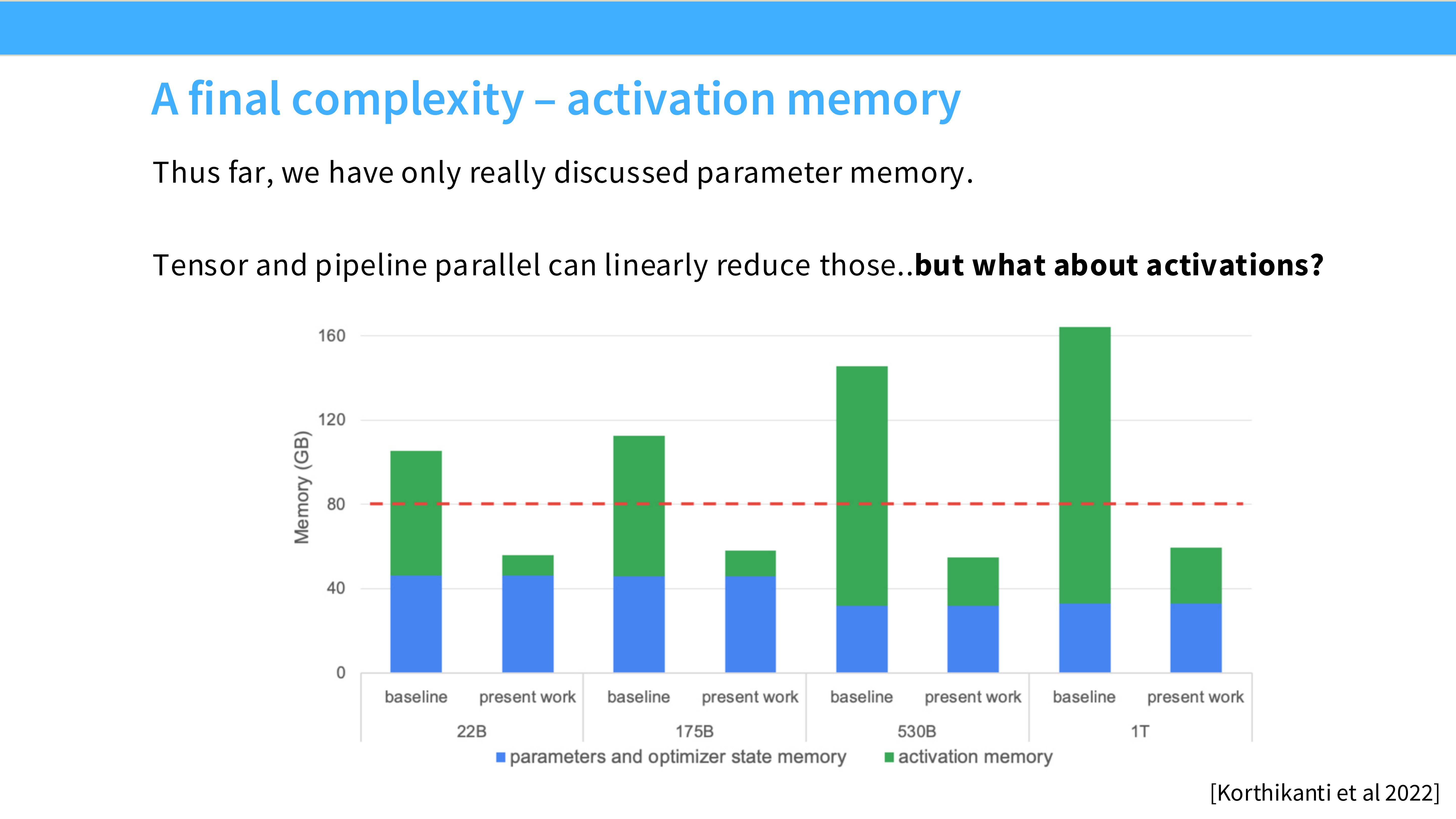
Page 23: 显存占用解剖
- 深度解析: 训练一个模型到底占多少显存?
- Model Parameters: 静态的权重。
- Gradients: 反向传播算出来的梯度。
- Optimizer States: 优化器(如 Adam)为了更新参数所维护的历史统计信息(动量、方差)。注意:这是隐藏的显存杀手!

Page 24: 16 Bytes 规则
- 深度解析: 这是一个非常实用的经验公式。假设使用混合精度训练 (Adam + FP16/BF16):
- Params: 2 bytes (FP16)
- Gradients: 2 bytes (FP16)
- Optimizer States: Adam 需要存 FP32 的参数副本(4B) + Momentum(4B) + Variance(4B) = 12 bytes。
- 合计: 16 Bytes / Parameter。
- 算账: 175B 模型 $\times$ 16 Bytes = 2.8TB。这就是为什么单卡跑不起来 GPT-3 的原因。

Page 25: ZeRO 的核心思想
- 深度解析: ZeRO (Zero Redundancy Optimizer) 是微软 DeepSpeed 团队提出的神技。
- 洞察: DP 中每个 GPU 存完整的状态是浪费。
- 方案: 既然是数据并行,我们有 $N$ 个 GPU,那就把这些状态(参数、梯度、优化器)切成 $N$ 份,每个 GPU 只维护 $1/N$。需要的时候再通信拿过来。
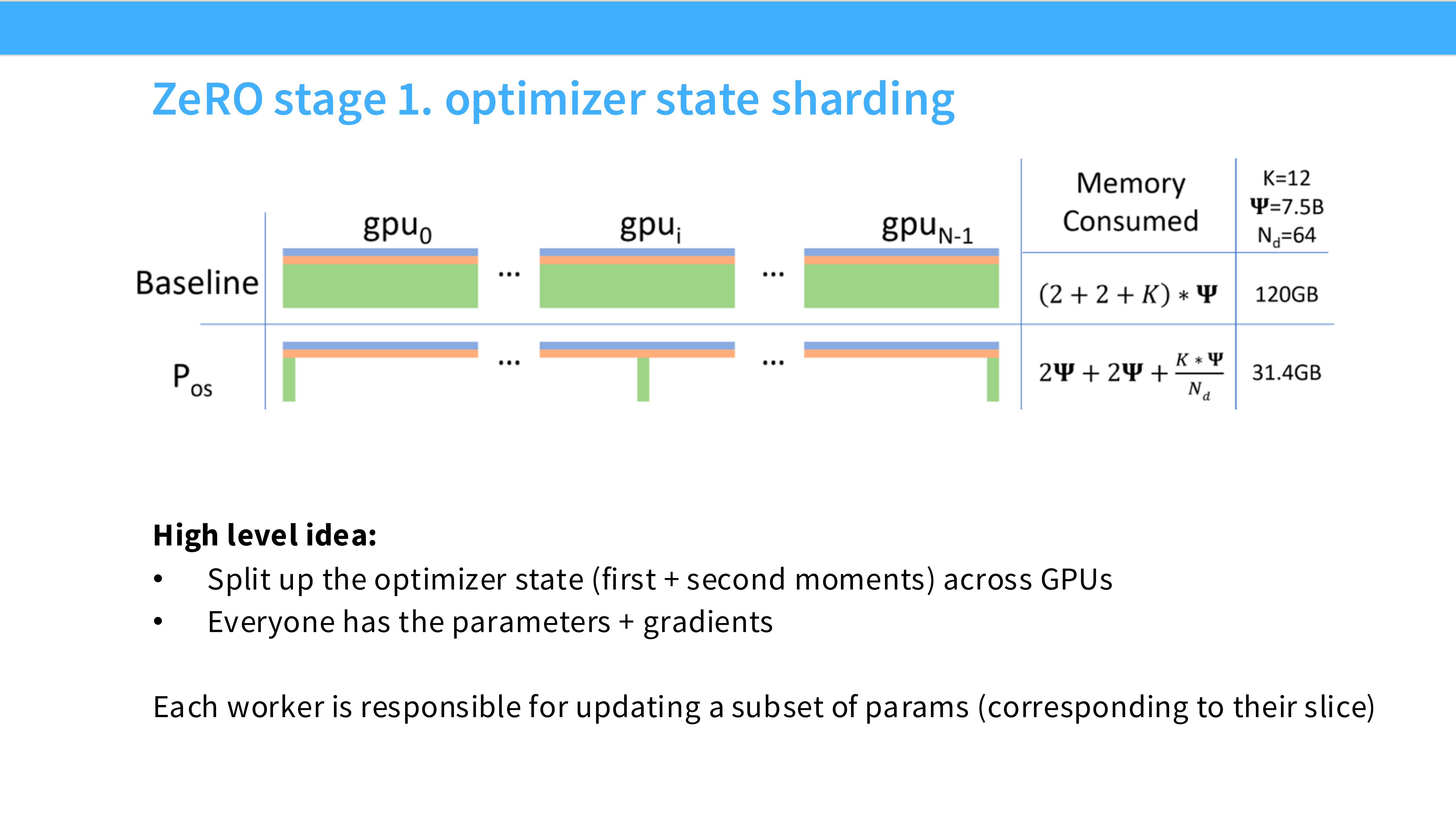
Page 26: ZeRO Stage 1 - 切分优化器
- 深度解析:
- 切分对象: Optimizer States (那 12 Bytes)。
- 显存收益: 巨大(减少了 75% 的显存占用)。
- 通信代价: 0。因为 All-Reduce 之后每个 GPU 本来就只需要更新自己负责的那部分参数,不需要额外的通信。Strongly Recommended!
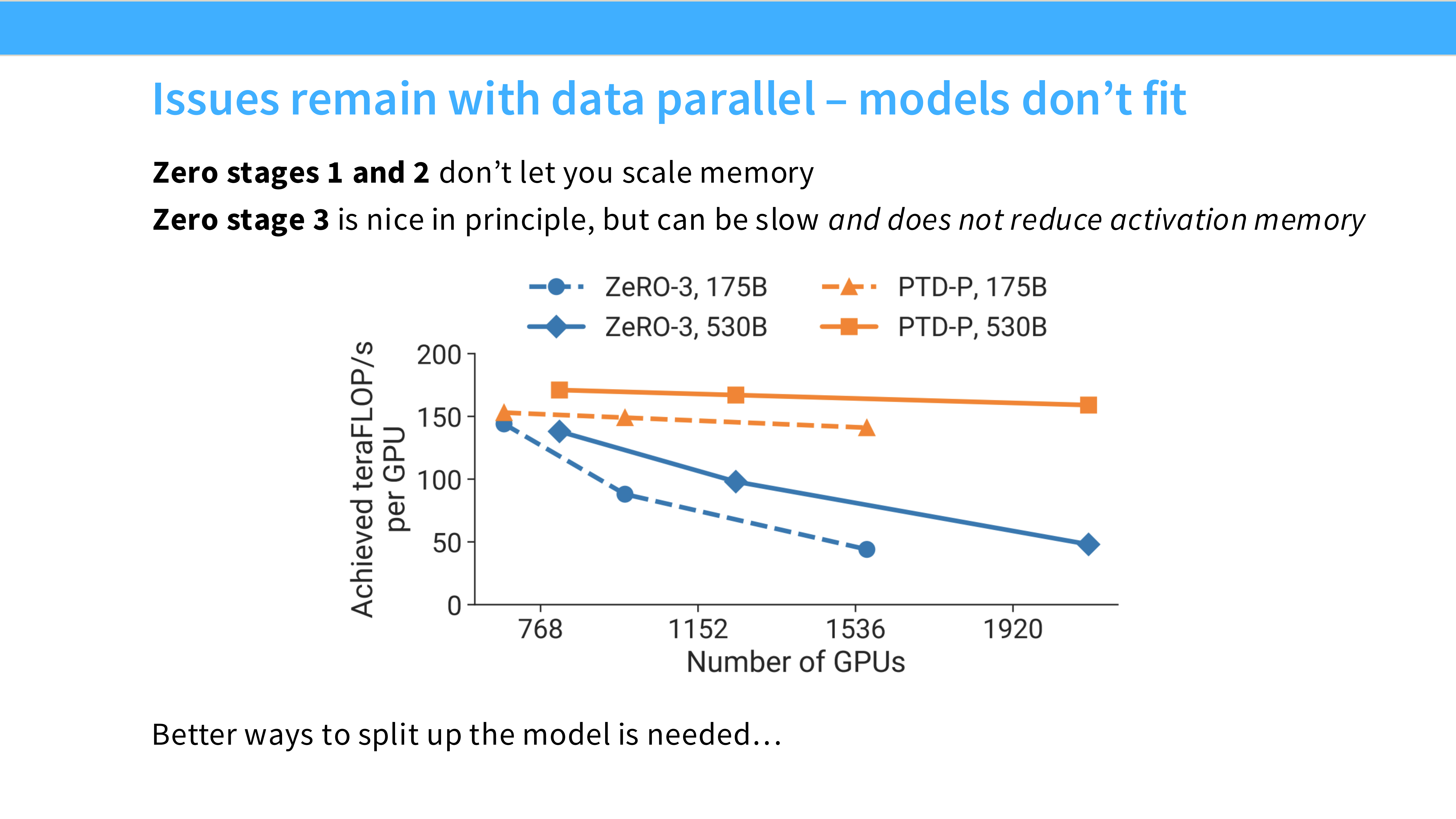
Page 27: ZeRO Stage 2 - 切分梯度
- 深度解析:
- 切分对象: Optimizer States + Gradients。
- 机制: 使用 Reduce-Scatter 替代 All-Reduce。求和后,每个 GPU 只保留自己那份梯度。
- 显存收益: 进一步减少。
- 通信代价: 与 Naive DP 持平。

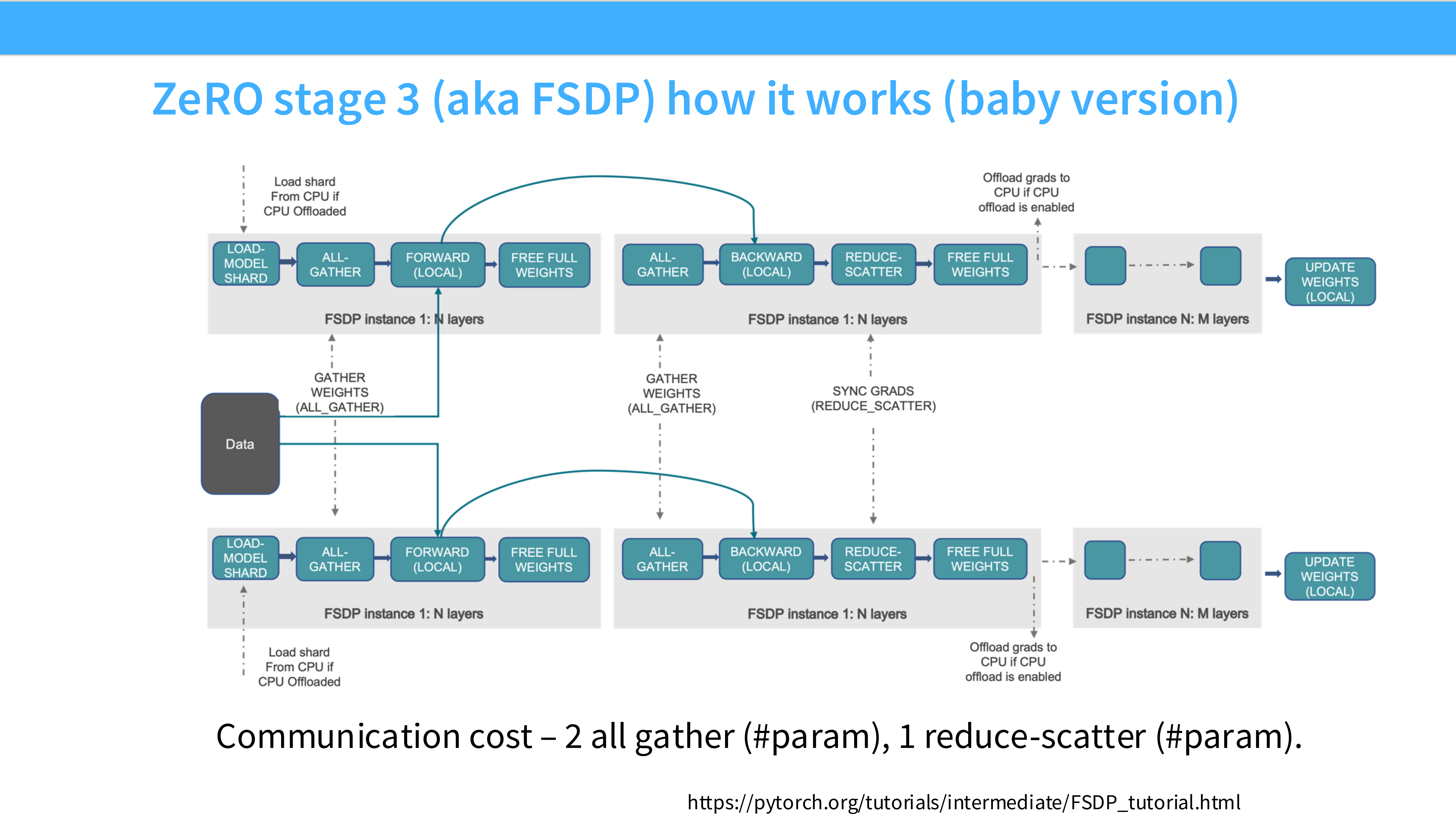
Page 28: ZeRO Stage 3 (FSDP) - 切分参数
- 深度解析: **FSDP (Fully Sharded Data Parallel)**。
- 切分对象: Everything (Params + Grads + Opt)。
- 显存收益: 显存占用随 GPU 数量线性下降。理论上 GPU 足够多,可以训练无限大的模型。
- 工作流: “High level idea” —— 在做前向计算时,临时把参数 All-Gather 回来;算完这层,马上删掉(Free),只保留分片。
Page 29: FSDP 详细工作流
- 深度解析: 流程图展示了 FSDP 的动态过程。
- Fetch: GPU 发现要算 Layer 1 了,发起 All-Gather 拿到 Layer 1 的完整权重。
- Compute: 计算 Layer 1。
- Discard: 计算完,立刻释放 Layer 1 的完整权重,省出显存给 Layer 2 用。
- 反向传播同理。这种“随用随取,用完即弃”的策略是用通信换显存。
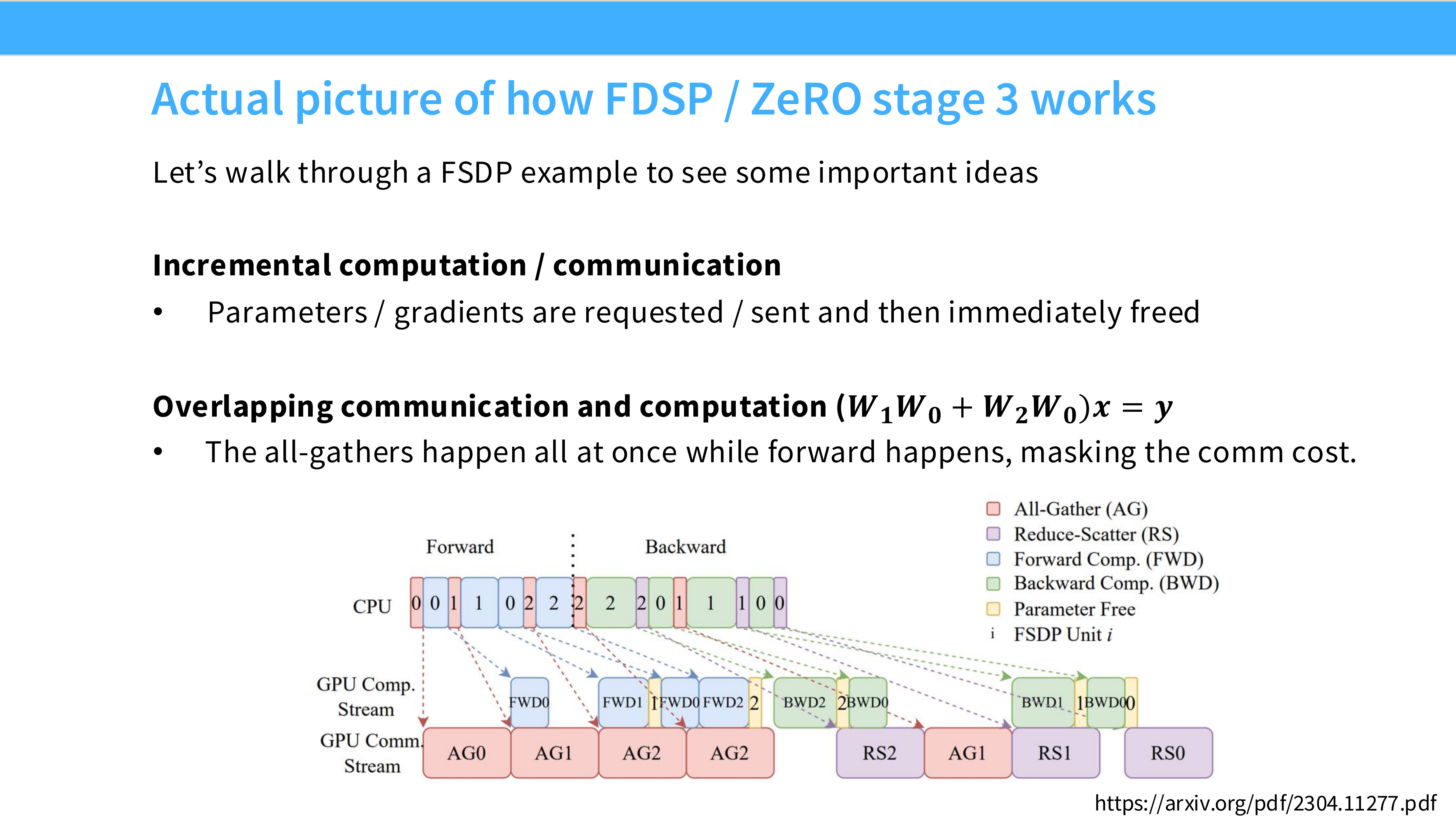
Page 30: FSDP 的通信开销
- 深度解析: FSDP 是不是完美的?不是,它增加了通信。
- Naive DP 通信量:$2 \Phi$ (All-Reduce)。
- FSDP 通信量:$3 \Phi$ (Forward All-Gather + Backward All-Gather + Gradient Reduce-Scatter)。
- 结论: 通信量增加了 1.5 倍。但在显存是瓶颈的情况下,这是唯一的出路。
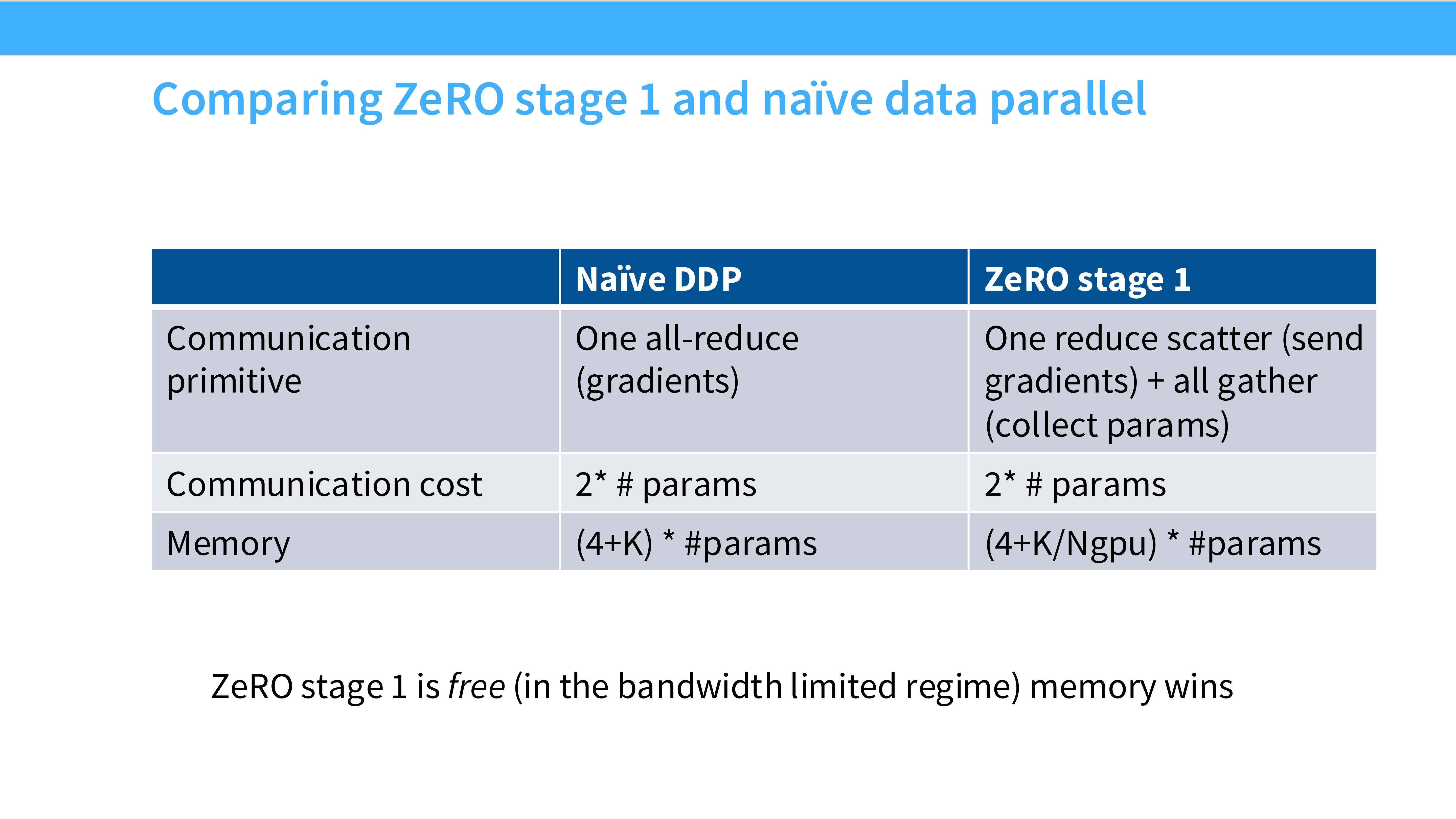
Page 31: 并行策略对比总结
- 深度解析: 表格对比了 Naive DDP 和 ZeRO Stage 1。
- 关键点: ZeRO Stage 1 在不增加任何通信开销的前提下,大幅节省了显存。在实际工程中,几乎总是应该开启 ZeRO-1/2。

Page 32: 代码实现
- 深度解析: 现代框架(如 PyTorch Lightning, HuggingFace Accelerate)已经封装好了 FSDP。通常只需要一行配置
strategy="fsdp"即可开启。
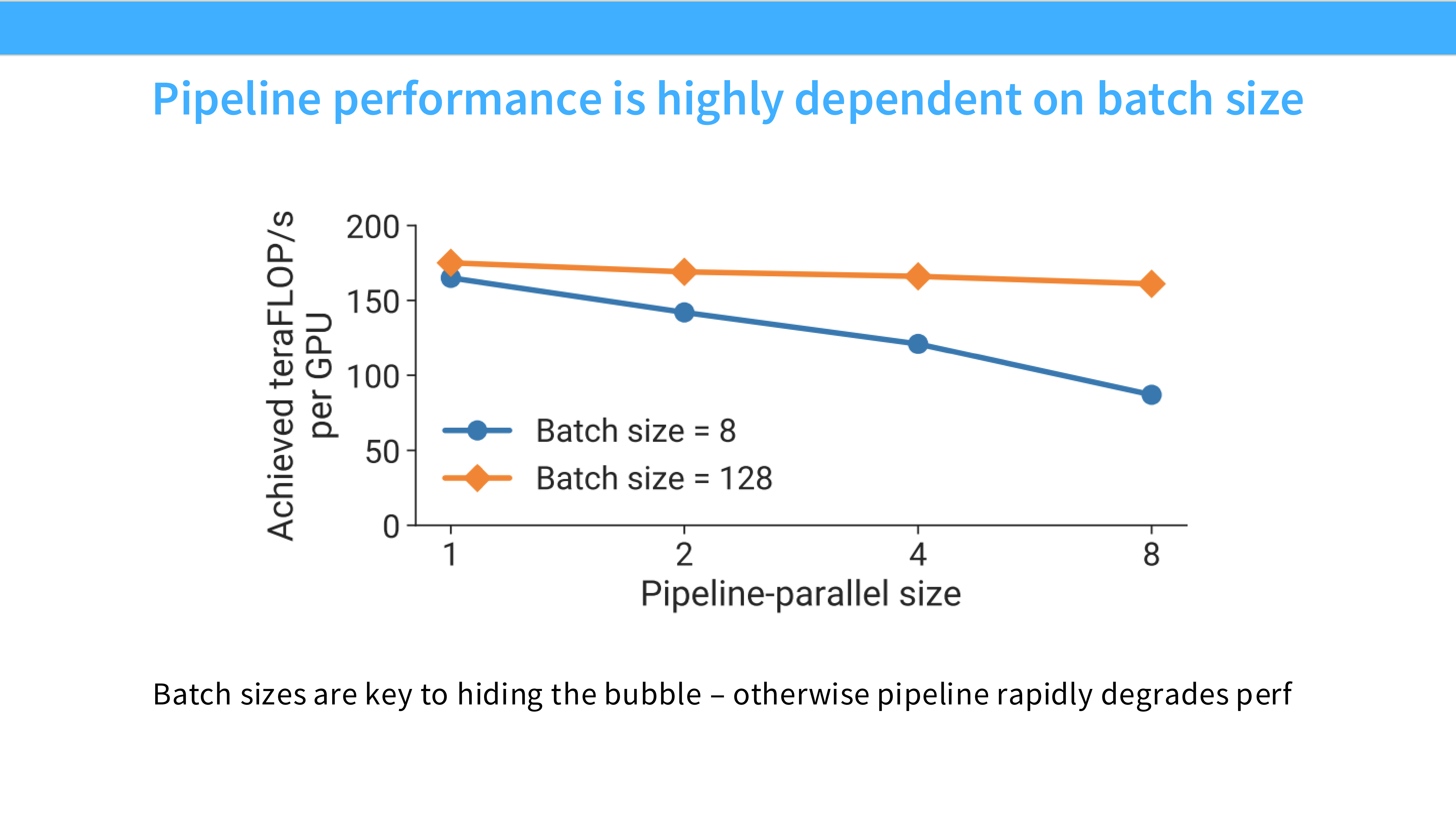
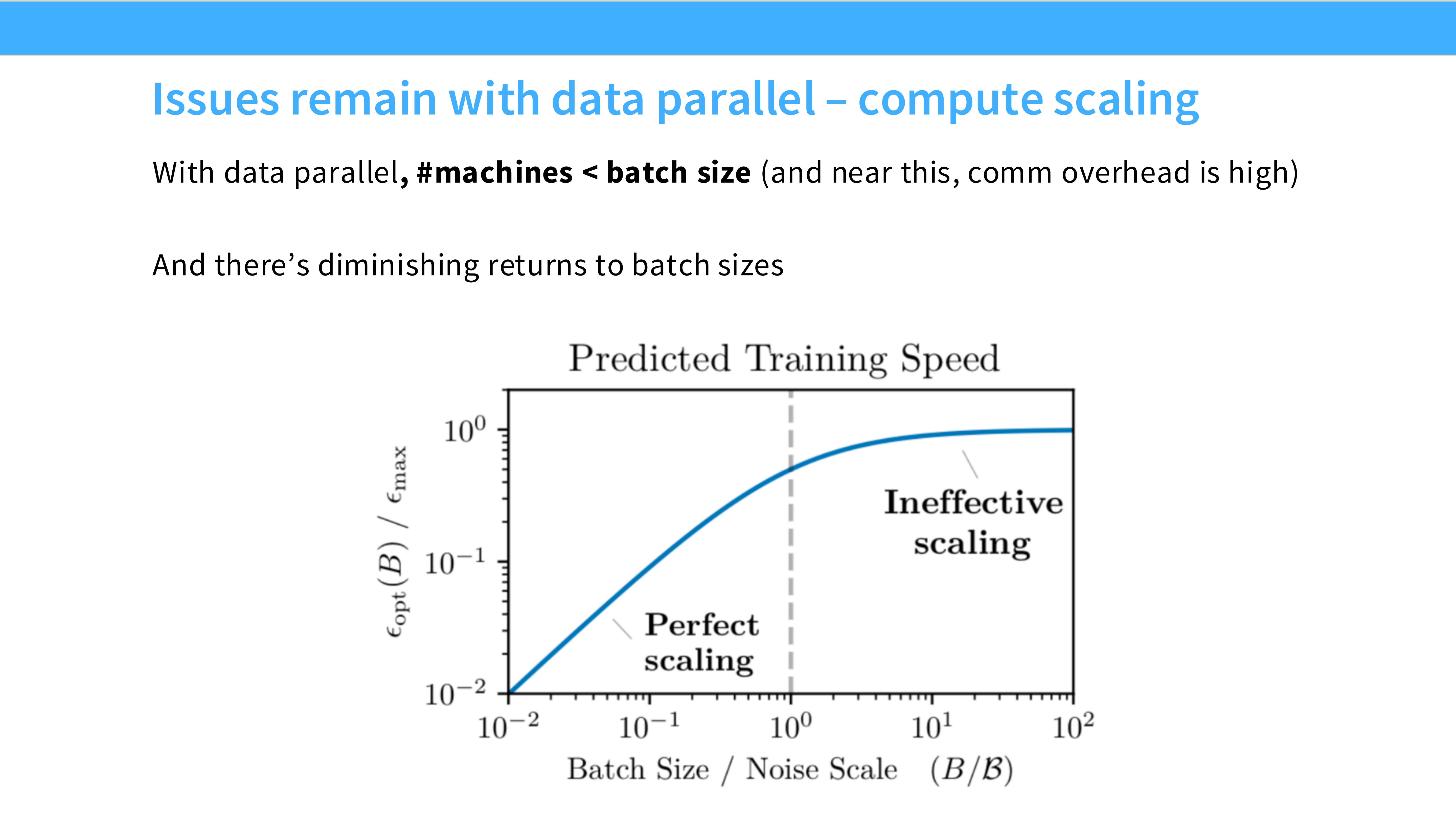
Page 33: DP 的隐形墙 - Batch Size
- 深度解析: 即使 FSDP 解决了显存问题,DP 还有一个数学限制。
- Global Batch Size = Num GPUs × Local Batch Size。
- 为了保证 GPU 效率(矩阵乘法不空转),Local Batch Size 不能太小。
- 当 GPU 数量达到数千张时,Global Batch Size 会变得巨大(如几百万 token),这可能会导致模型收敛变慢或泛化能力下降。
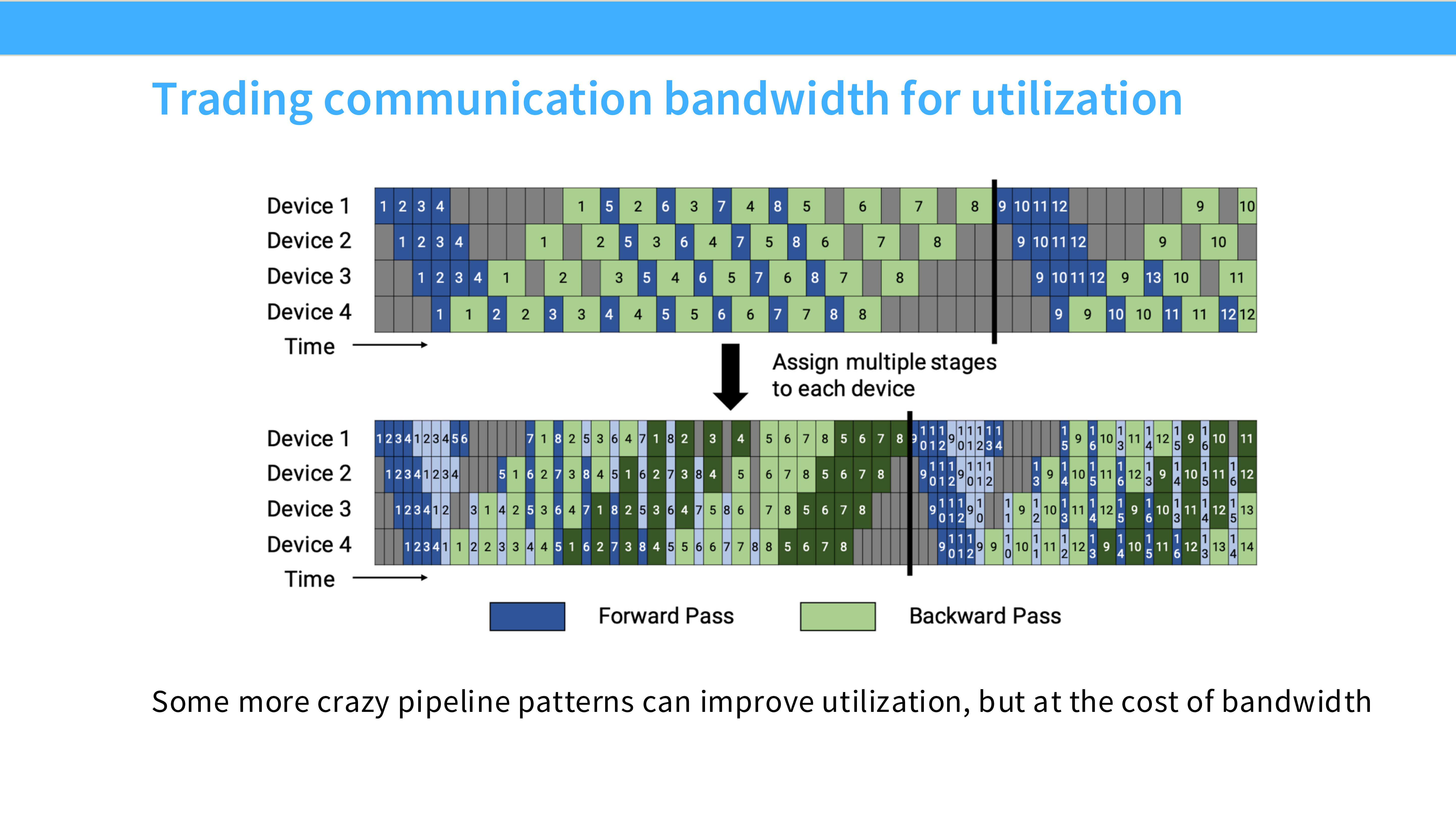
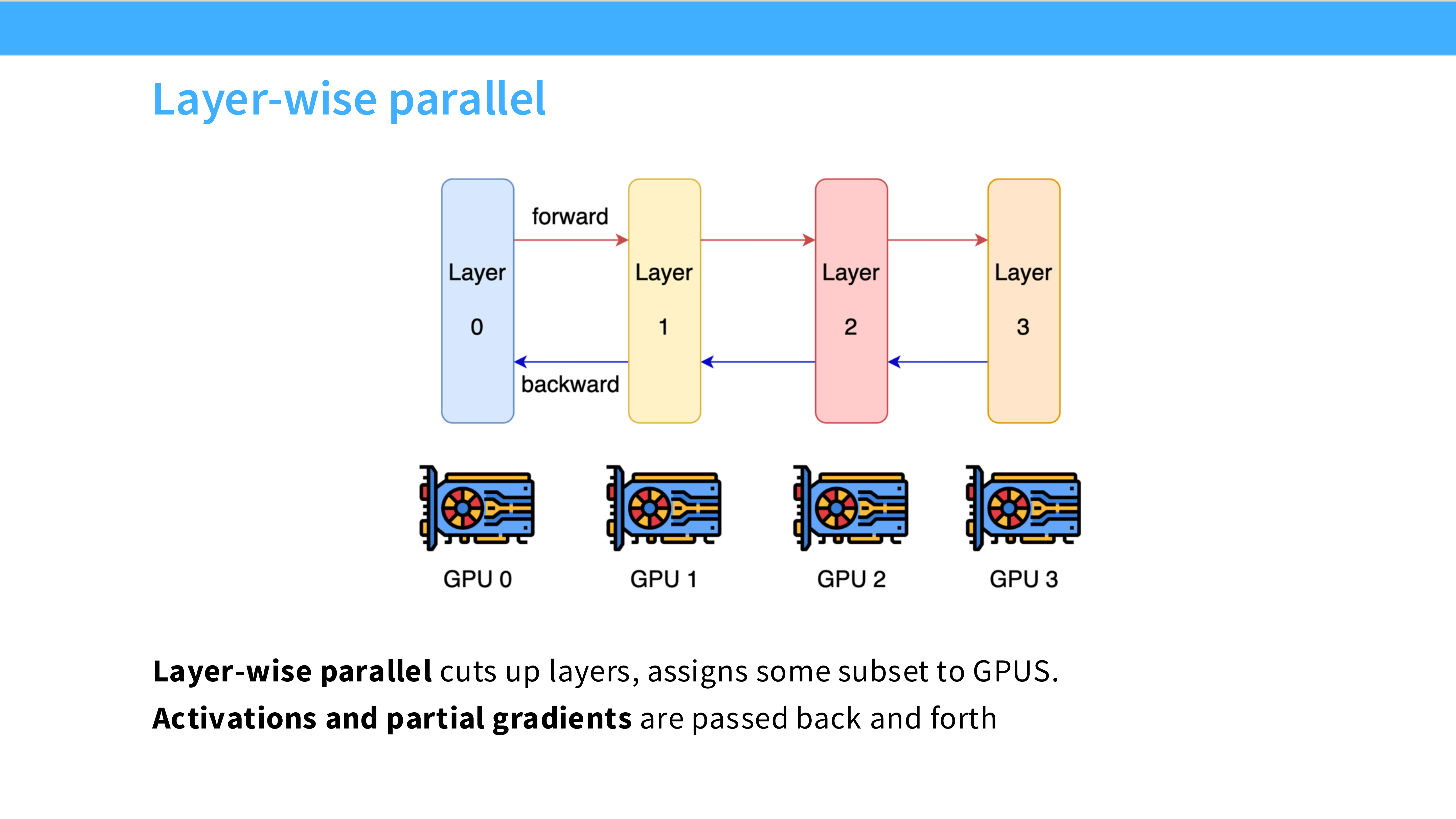
Page 34: 流水线并行 (Pipeline Parallelism, PP)
- 深度解析: 当模型大到单机(8卡)都装不下,需要跨机器扩展时,PP 登场。
- 切分维度: **Layers (深度)**。
- 直观理解: 就像汽车组装流水线。机器 A 装发动机(Layer 1-10),机器 B 装轮胎(Layer 11-20)。
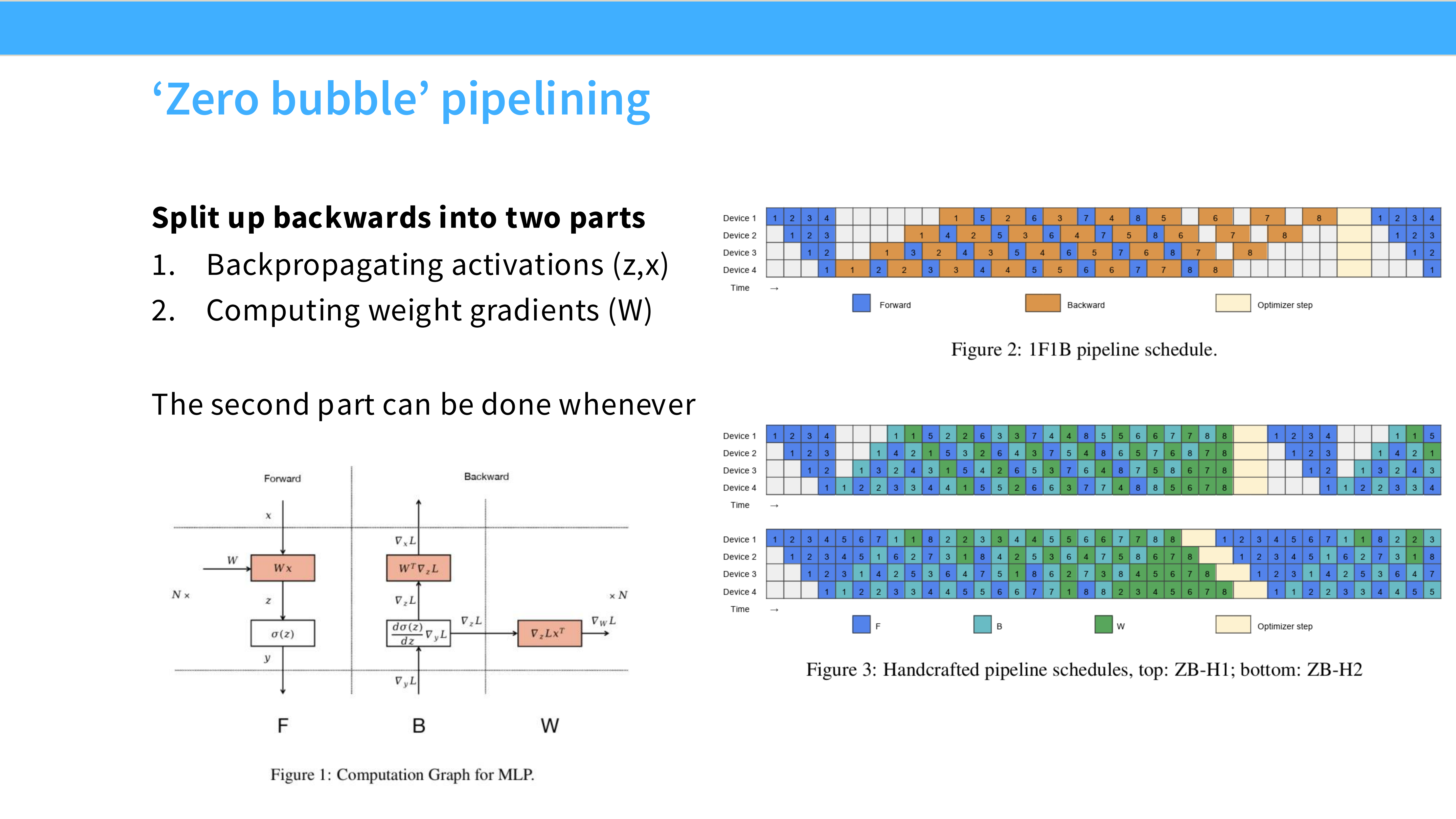
Page 35: Layer-wise Parallel 示意图
- 深度解析:
- GPU 0 计算完 Layer 0-3 的激活值(Forward),传给 GPU 1。
- GPU 1 计算 Layer 4-7…
- 反向传播时,梯度从 GPU 3 传回 GPU 2…
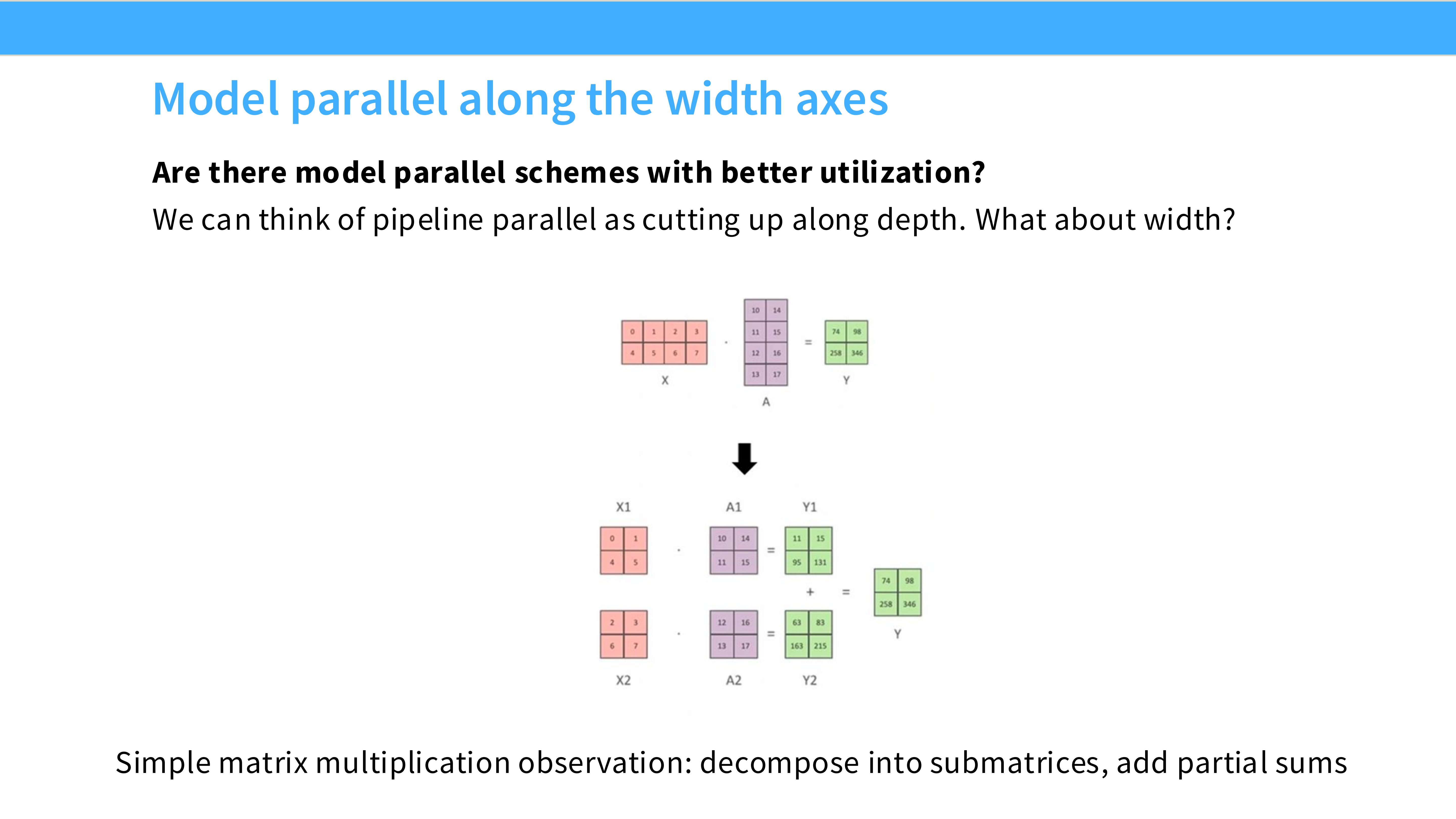
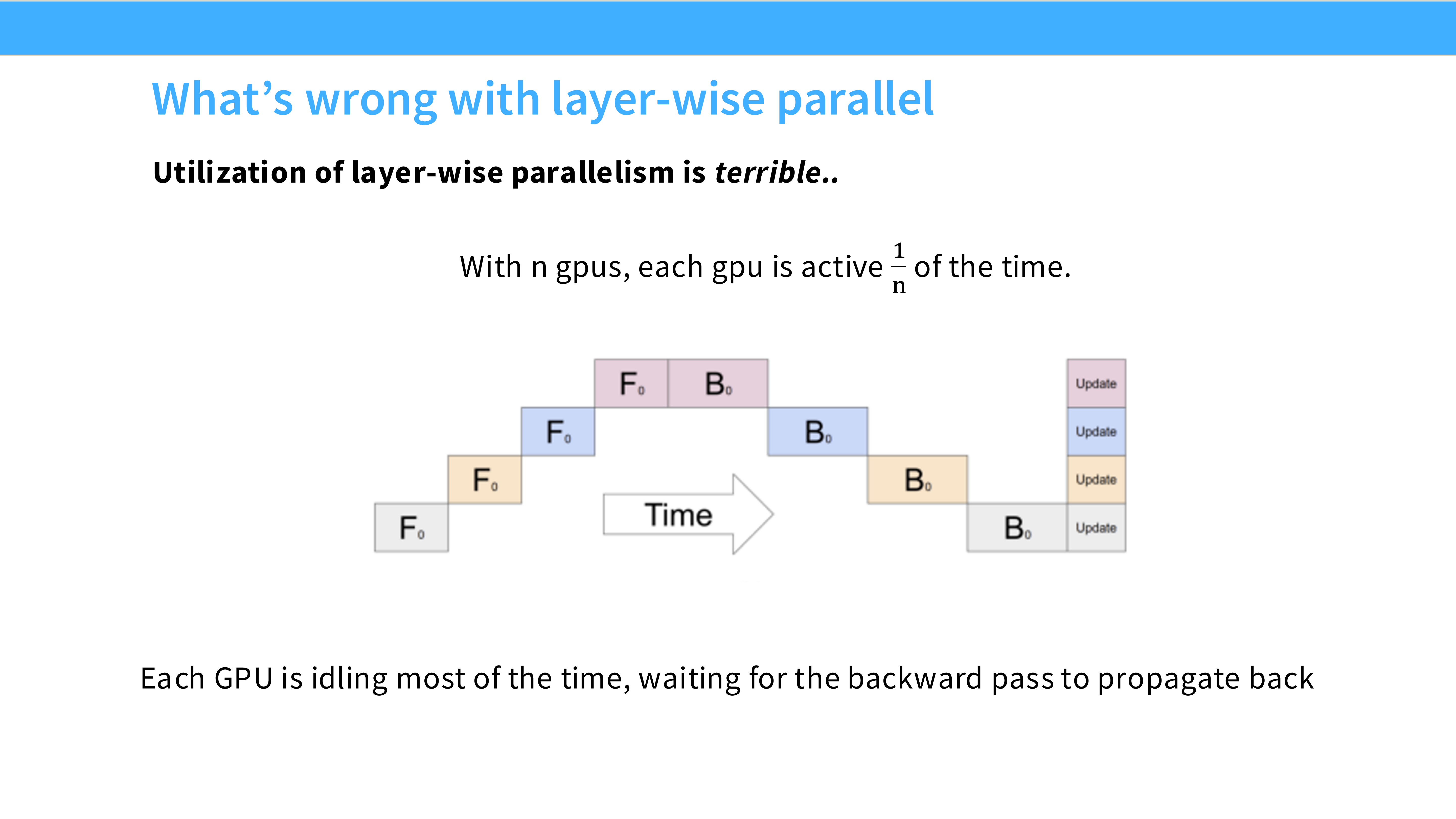
Page 36: 朴素 PP 的灾难 - 气泡 (Bubble)
- 深度解析: 这种简单做法效率极低。
- 当 GPU 0 在工作时,GPU 1, 2, 3 都在干等(因为数据还没传过来)。
- 利用率: 几乎是 $1/N$。这被称为 “Pipeline Bubble”。
Page 37: 气泡可视化
- 深度解析: 图中大片的空白区域就是 GPU 空转的时间。只有对角线上的色块在计算。这是不可接受的资源浪费。
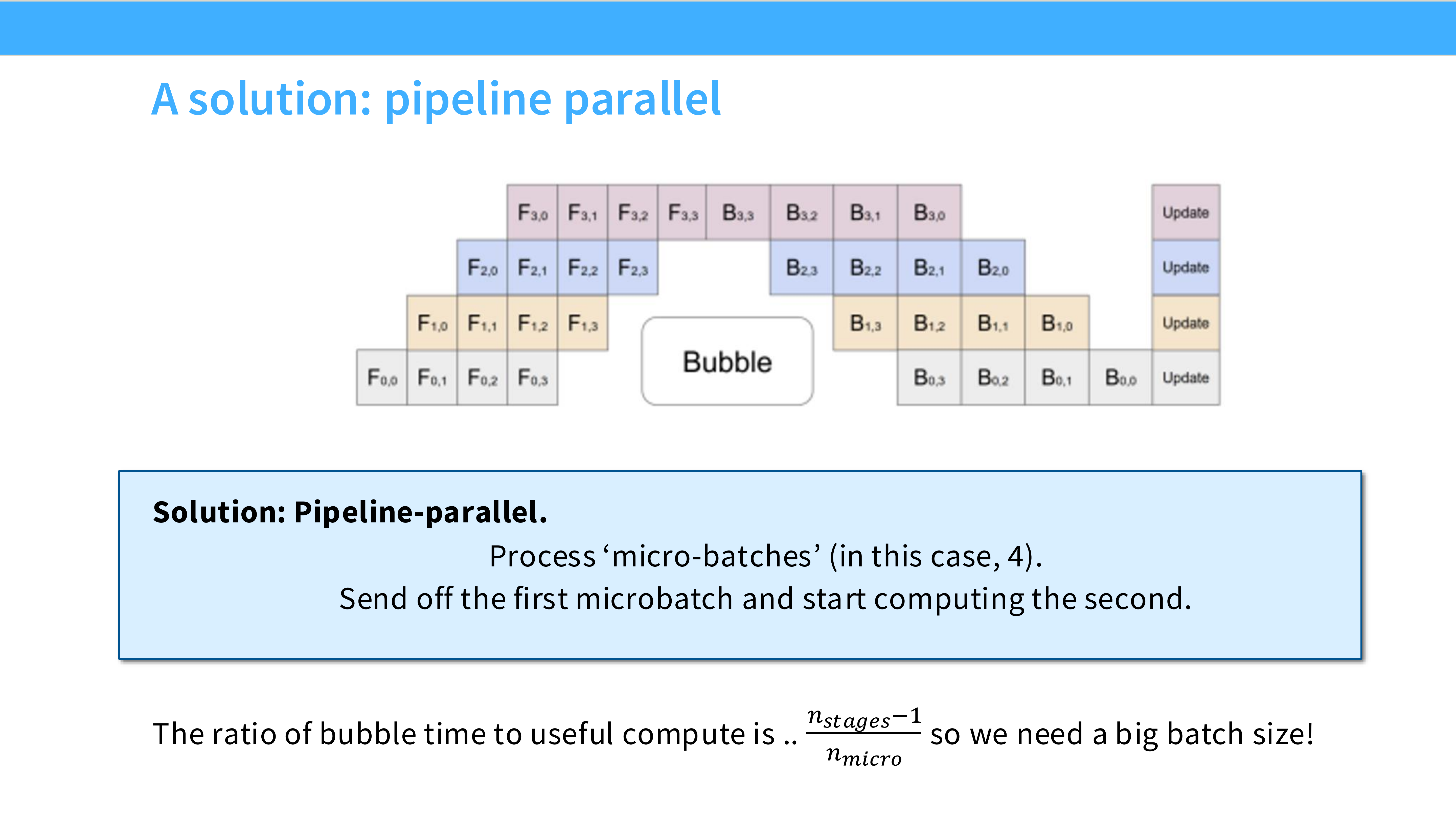
Page 38: 救星 - Micro-batches
- 深度解析: 如何填补气泡?
- 策略: 把一个大 Batch 切成很多个 Micro-batches。
- 流水线化: GPU 0 算完 Micro-batch 1 立即发给 GPU 1,然后马上转头算 Micro-batch 2。让 GPU 动起来。

Page 39: GPipe 调度
- 深度解析: 这是 Google 提出的 GPipe 方案。
- F (Forward): 连续执行所有 Micro-batch 的前向。
- B (Backward): 连续执行所有 Micro-batch 的反向。
- 虽然比朴素 PP 好,但中间仍然有较大的显存开销(需要存所有 MB 的激活值)。
Page 40: Bubble 的数学极限
- 深度解析: 即使有 Micro-batch,启动和结束时的气泡依然存在。
- 气泡占比公式:$\text{Bubble Fraction} \approx \frac{p-1}{m}$。($p$=GPU数, $m$=Micro-batch数)。
- 启示: 想要气泡小,Micro-batch 数量 $m$ 必须远大于 $p$。这又逼迫我们增大 Global Batch Size。
Page 41: 1F1B 调度 (Interleaved)
- 深度解析: 工业界更常用的调度(Megatron-LM)。
- 策略: 算一个前向,马上算一个反向(One Forward, One Backward)。
- 优势: 及时释放显存。反向传播算完梯度后,前向传播的激活值就可以删了。这大大降低了峰值显存占用。

Page 42: 零气泡流水线 (Zero Bubble)
- 深度解析: 学术界的前沿探索。通过把前向和反向进一步拆分(F -> B -> W),并采用复杂的“U型”或“V型”调度,试图完全填满气泡。

Page 43: PP 的权衡
- 深度解析: 为什么我们还是讨厌 PP?
- 优点: 通信量小(只传边界的激活值),点对点通信,适合跨机。
- 缺点: 气泡难以消除;实现极其复杂;Batch Size 被迫很大;需要模型分层。
Page 44: 张量并行 (Tensor Parallelism, TP)
- 深度解析: 如果单机显存不够,又不想用 PP(因为有气泡),怎么办?
- 切分维度: **Tensor (矩阵内部)**。
- 场景: 主要是 **Intra-node (单机多卡)**。因为 TP 通信太频繁了,必须跑在 NVLink 上。
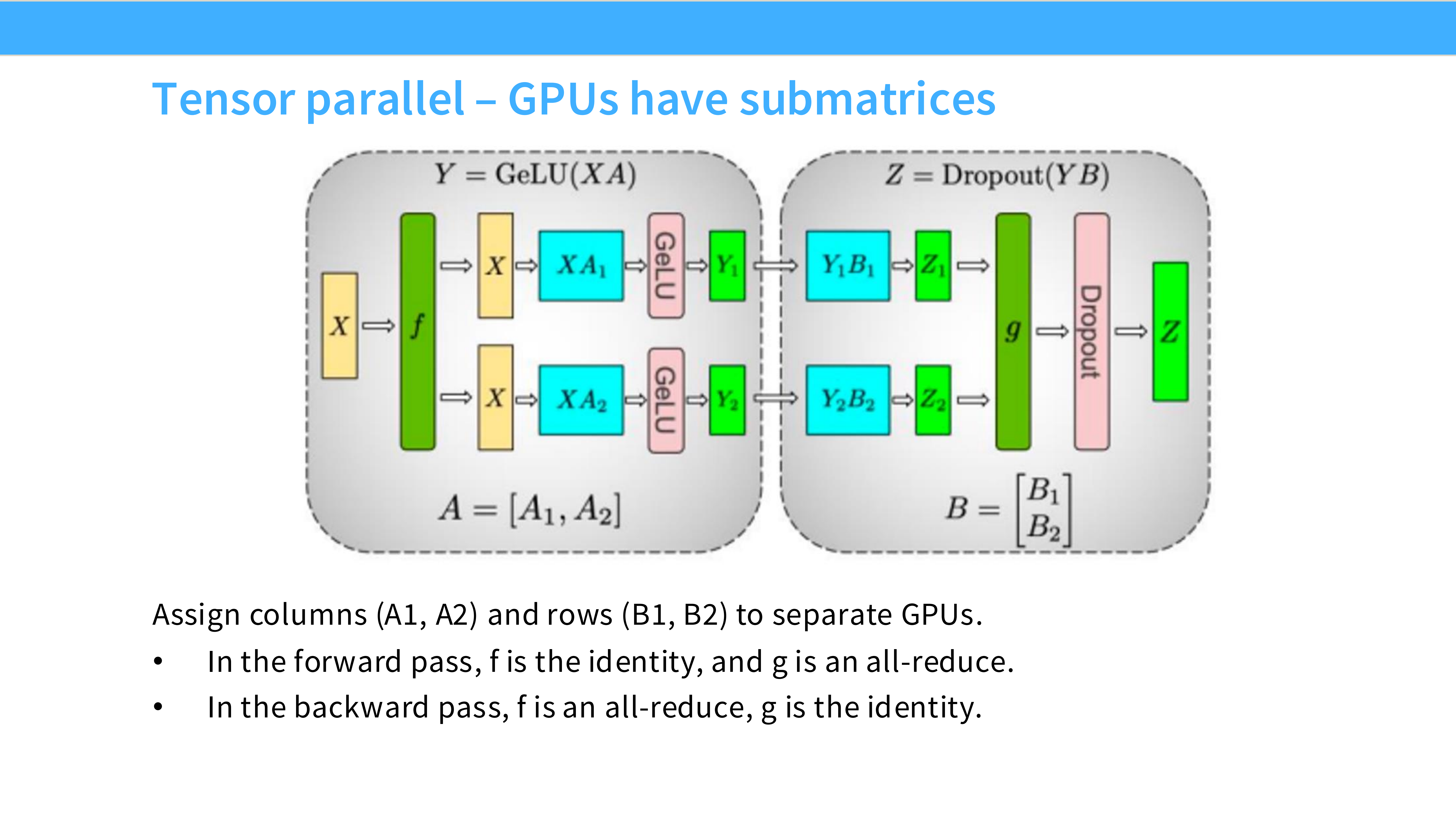
Page 45: 矩阵乘法切分原理
- 深度解析: 核心是 $Y = X \cdot A$。
- 列并行 (Column Parallel): 把权重矩阵 $A$ 竖着切两半 $[A_1, A_2]$。GPU 1 算 $X \cdot A_1$,GPU 2 算 $X \cdot A_2$。输出拼接起来。
- 行并行 (Row Parallel): 把权重矩阵 $A$ 横着切。需要把输入 $X$ 也切了。算出来结果需要相加。
Page 46: MLP 层的 TP 设计
- 深度解析: Megatron-LM 的经典设计。MLP 包含两个 Linear 层。
- 第一层: 使用 列并行。输出被 Split 了,没关系,GELU 是逐元素的,可以直接算。
- 第二层: 使用 行并行。直接吃 Split 的输入,算出结果后,进行一次 All-Reduce。
- 精妙之处: 中间不需要通信!两个 Linear 层之间完全并行,只有最后需要同步一次。

Page 47: Attention 层的 TP 设计
- 深度解析: Multi-head Attention 天生适合 TP。
- 策略: 直接切 Head。
- 比如有 16 个 Head,4 张卡。每张卡负责计算 4 个 Head 的 Q, K, V 和 Attention Score。
- 最后输出 Linear 层再用行并行合并结果。
Page 48: Cross Entropy 也能并行
- 深度解析: 许多人忽略的点。
- 词表(Vocab)通常很大(如 10万+)。最后一层的 Logits 矩阵非常占显存。
- TP 可以把词表切分,每个 GPU 只计算一部分词的 Logits 和 Loss,最后 Reduce。这避免了在单卡上生成巨大的 Logits 矩阵。
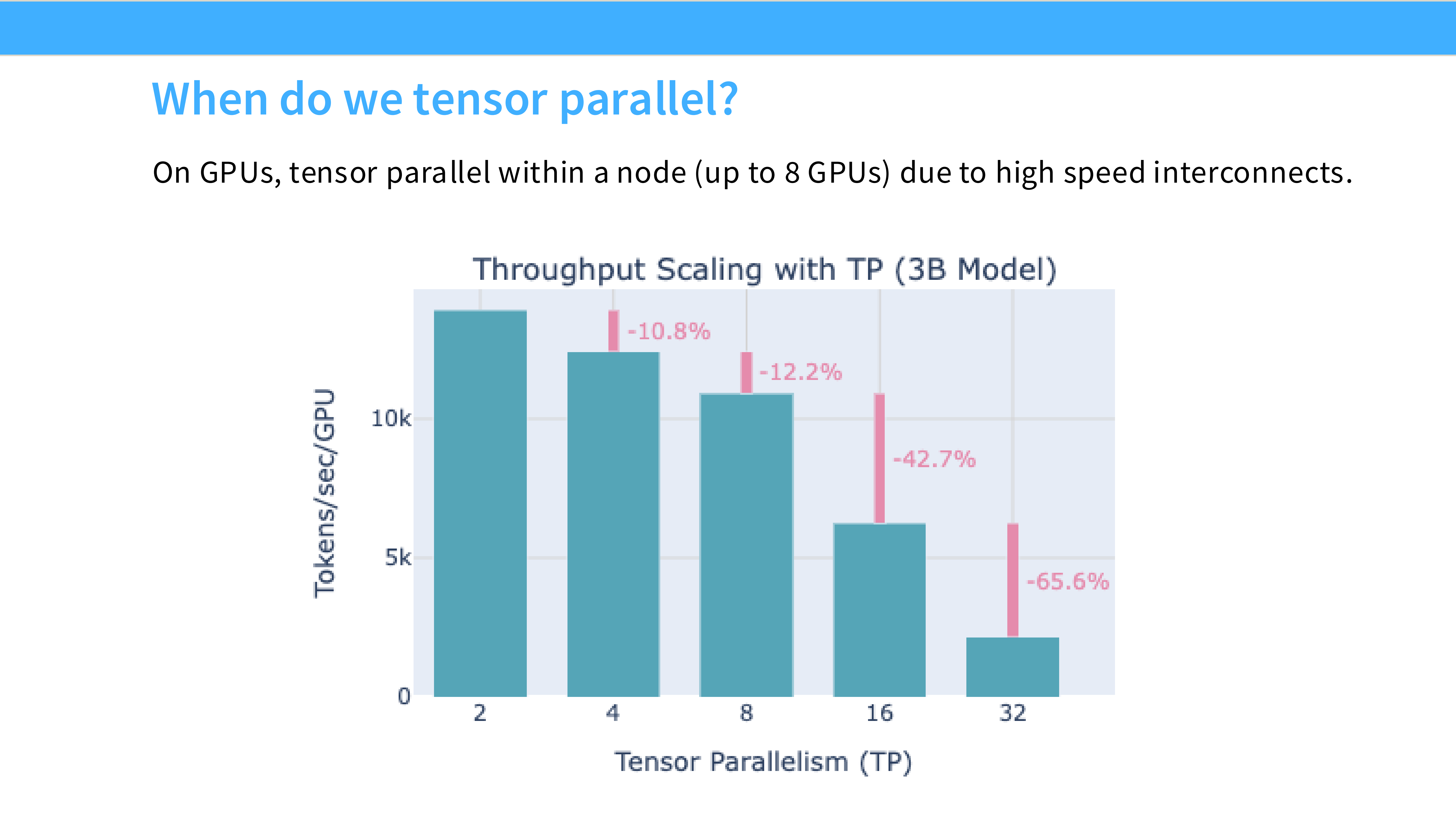
Page 49: TP 的通信特性
- 深度解析:
- 优点: 没有气泡(No Bubble),显存利用率高。
- 缺点: 通信地狱。每次前向/反向都要做 All-Reduce。每层都要!
- 限制: 这就是为什么 TP 只能设为 8(单机卡数)。跨机跑 TP 会因为网络延迟导致速度极慢。
Page 50: TP vs PP 对比
- 深度解析:
- TP: 低延迟互联(NVLink),高频通信,无气泡。
- PP: 高延迟互联(Ethernet/IB),低频通信,有气泡。
- 两者互补,常结合使用。
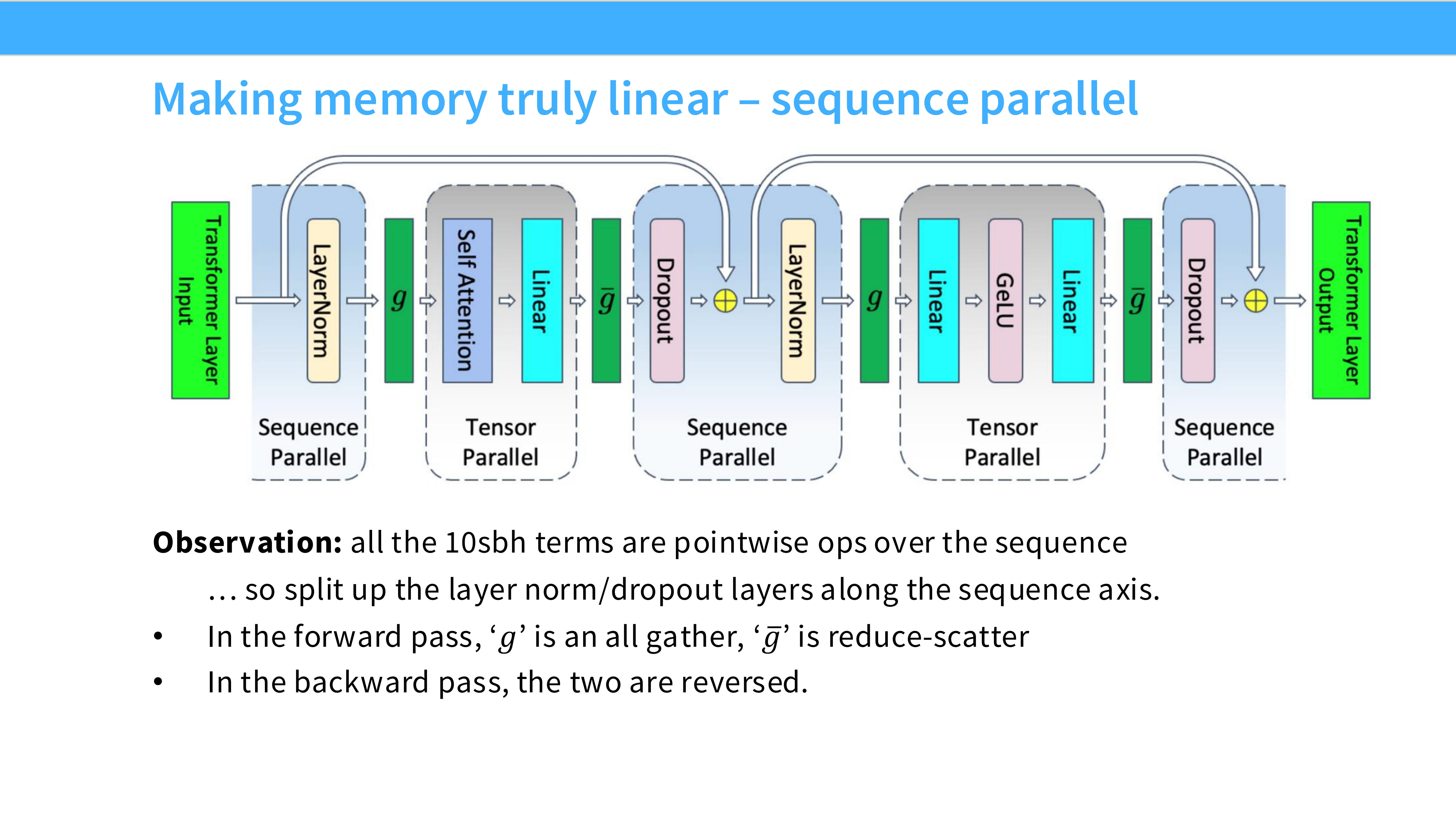
Page 51: 序列并行 (Sequence Parallelism, SP)
- 深度解析: TP 的补丁。
- 背景: 在 TP 中,LayerNorm 和 Dropout 是在所有卡上重复计算的(Replicated),这部分显存没有被切分。
- SP: 沿着 Sequence Length 维度把这些操作也切分了。配合 TP,真正实现了“显存全切分”。
- 这也是 Ring Attention(支持百万级长文本)的基础技术。
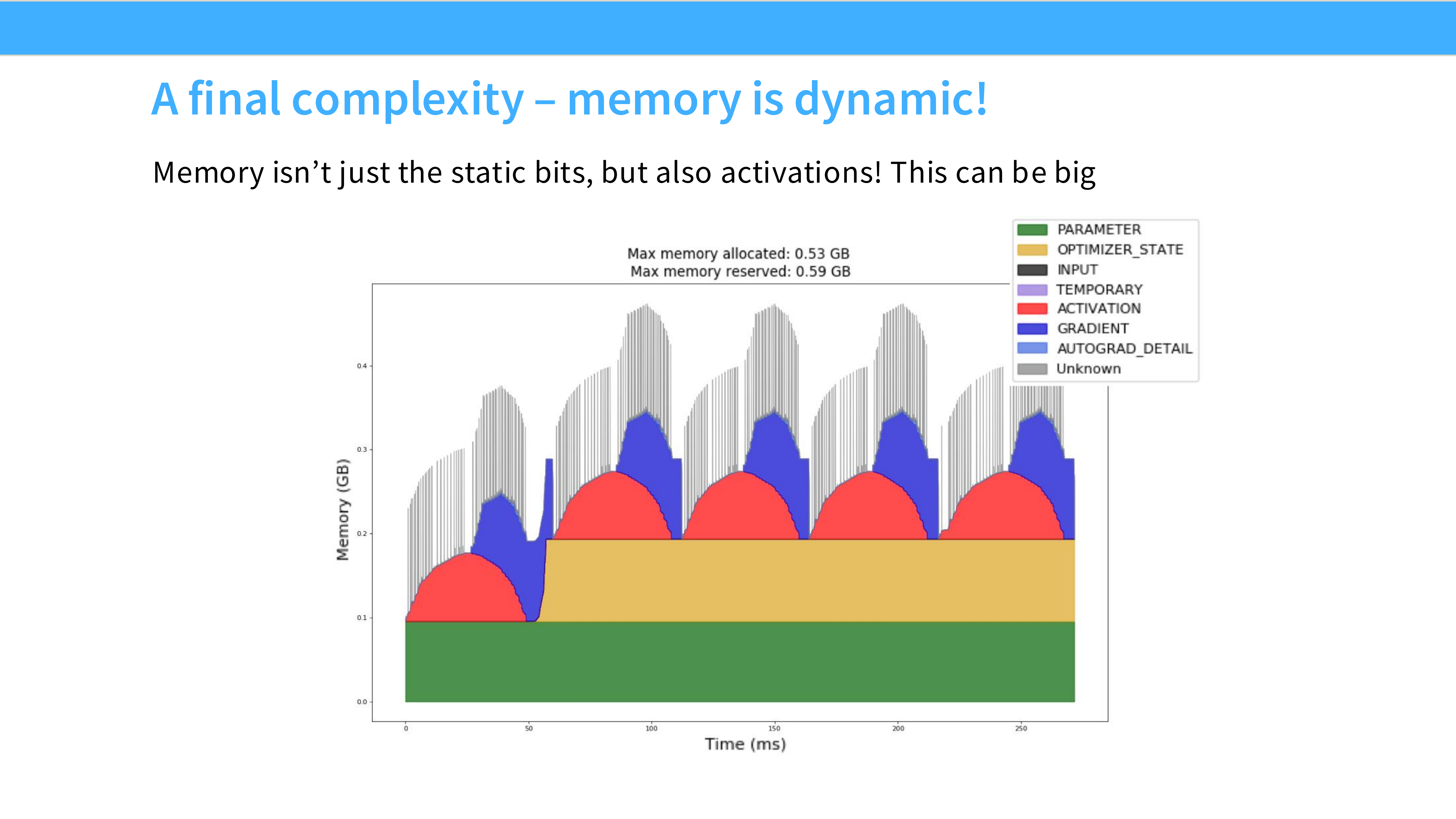
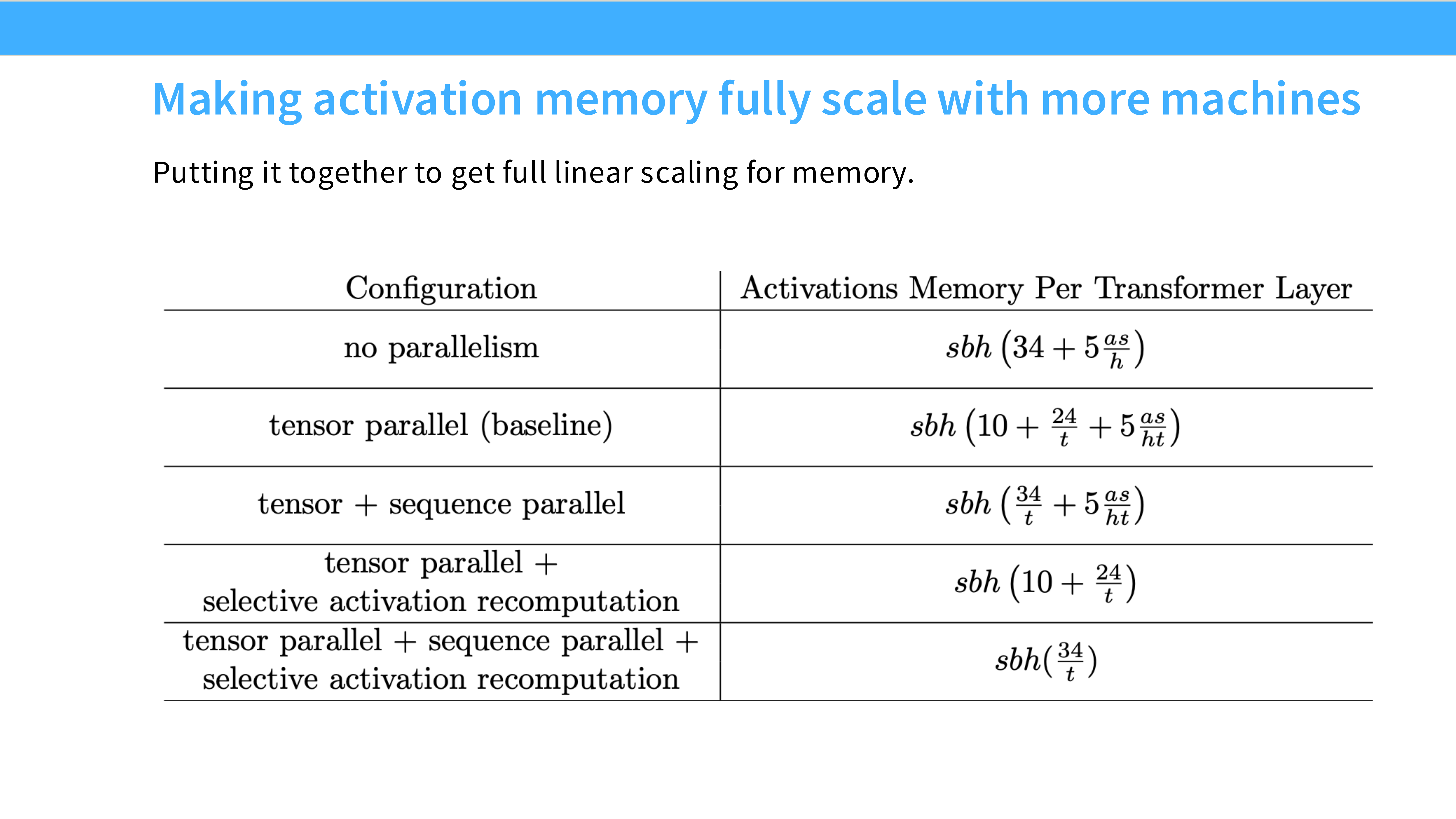
Page 52: 激活重计算 (Activation Recomputation)
- 深度解析: 这是一个纯软件层面的优化,也是显存救星。
- 常识: 为了反向传播算梯度,我们必须在前向传播时把每一层的激活值(Output)存下来。这占用了大量显存($O(Layers \times Seq \times Hidden)$)。
- 技巧: 不存了! 只存每层的输入(Checkpoint)。反向传播时,临时重新计算这一层的前向过程,算出激活值,用完即扔。
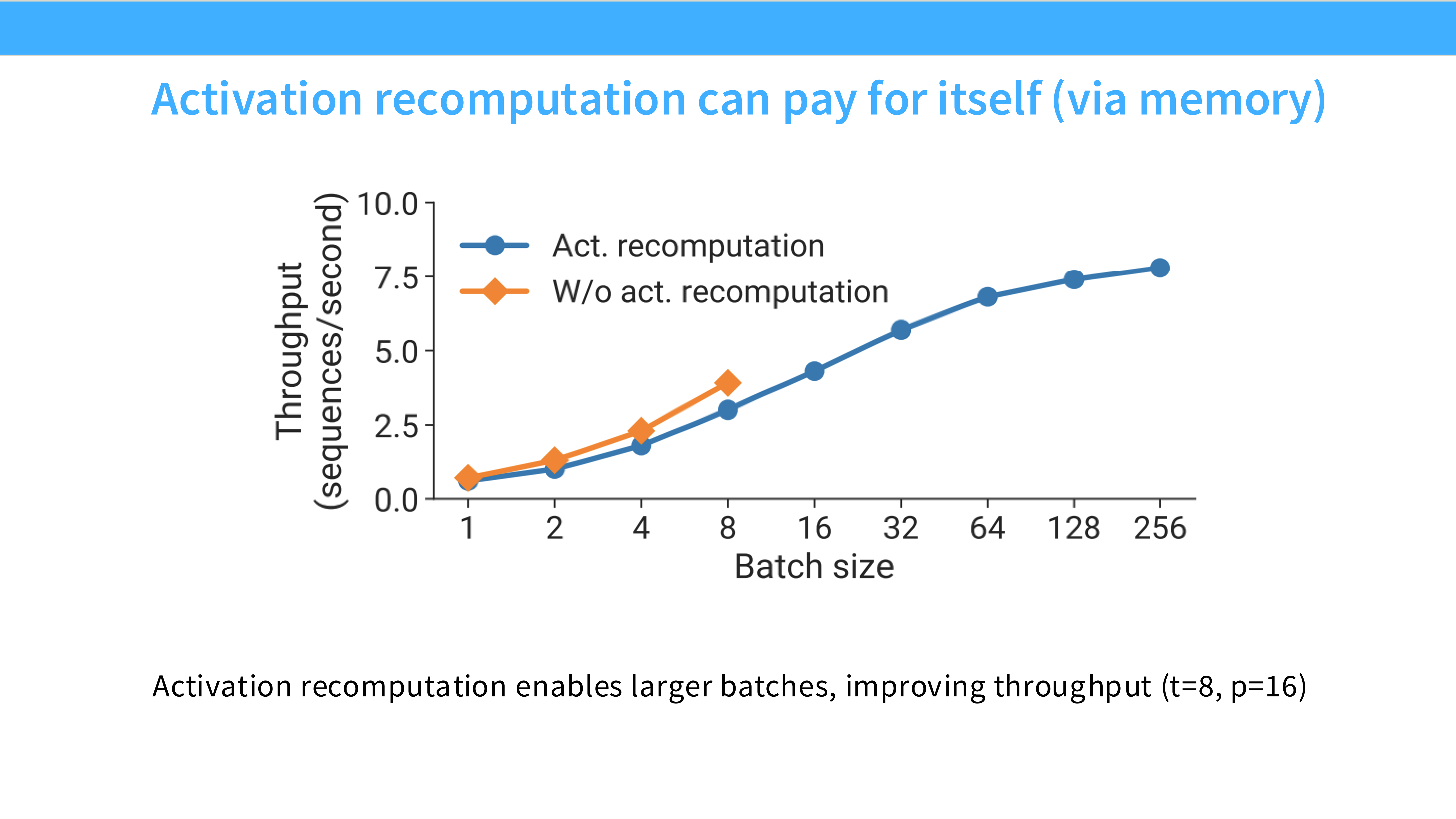
Page 53: 重计算的收益
- 深度解析:
- Trade-off: 用计算换显存。计算量增加约 33%(多做了一次前向),但显存占用可以减少 5-10 倍。
- 现状: 在大模型训练中,显存(决定能不能跑、Batch 能开多大)比算力(决定跑多快)更紧缺。所以重计算几乎是默认开启的。
Part 3: 实战扩展 (Scaling and Training Big LMs)

Page 54: Part 3 标题
- 深度解析: 既然我们手握 DP, PP, TP 三把武器,如何组合它们来打倒万亿参数的 BOSS?这就是 3D Parallelism。

Page 55: 3D 并行示意图
- 深度解析: 一个巨大的立方体模型。
- 宽 (Hidden size): 用 TP 切分。
- 深 (Layers): 用 PP 切分。
- 长 (Batch): 用 DP 切分。
- 通过正交切分,我们可以把一个巨无霸模型塞进成千上万个小 GPU 里。

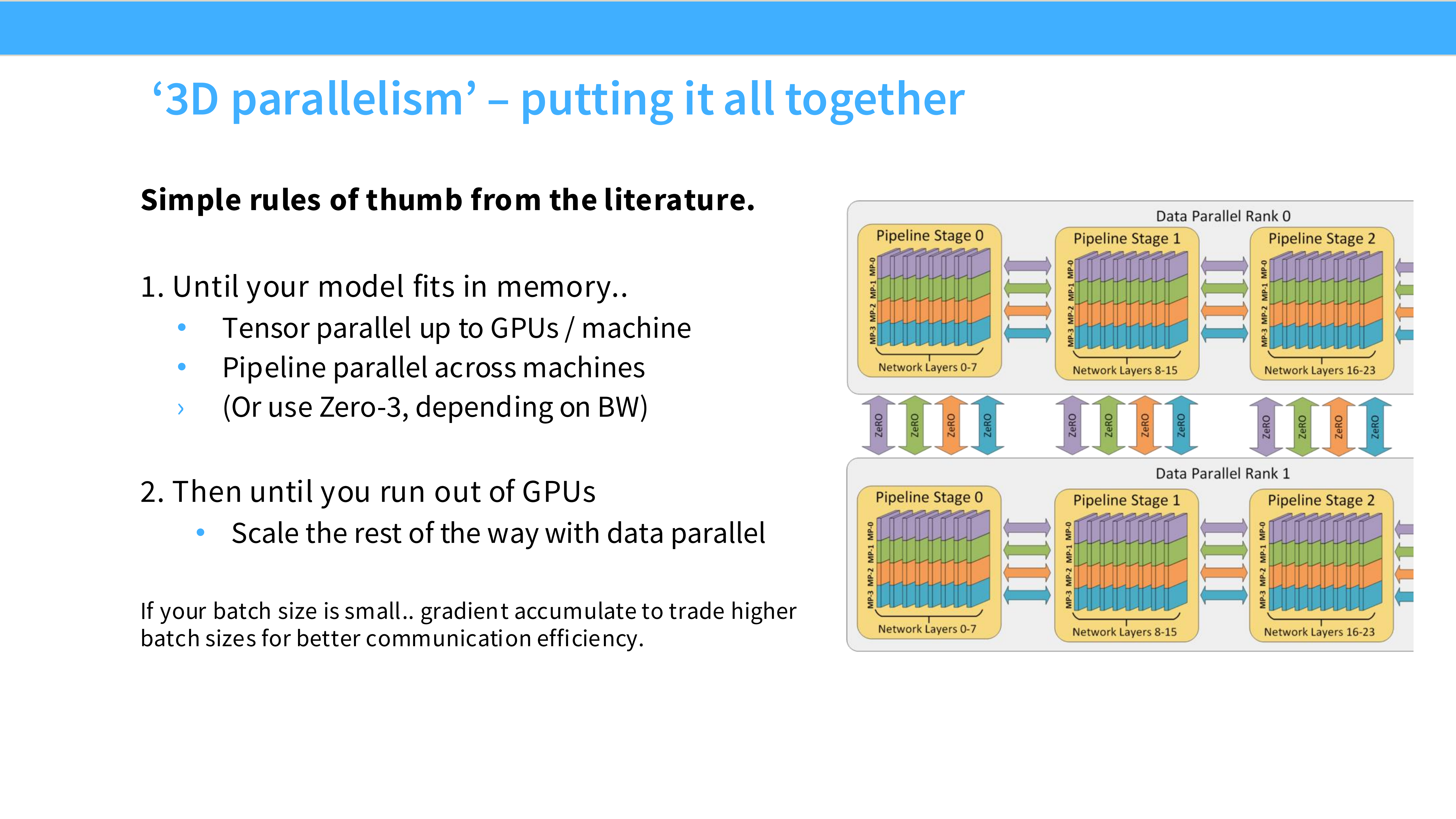
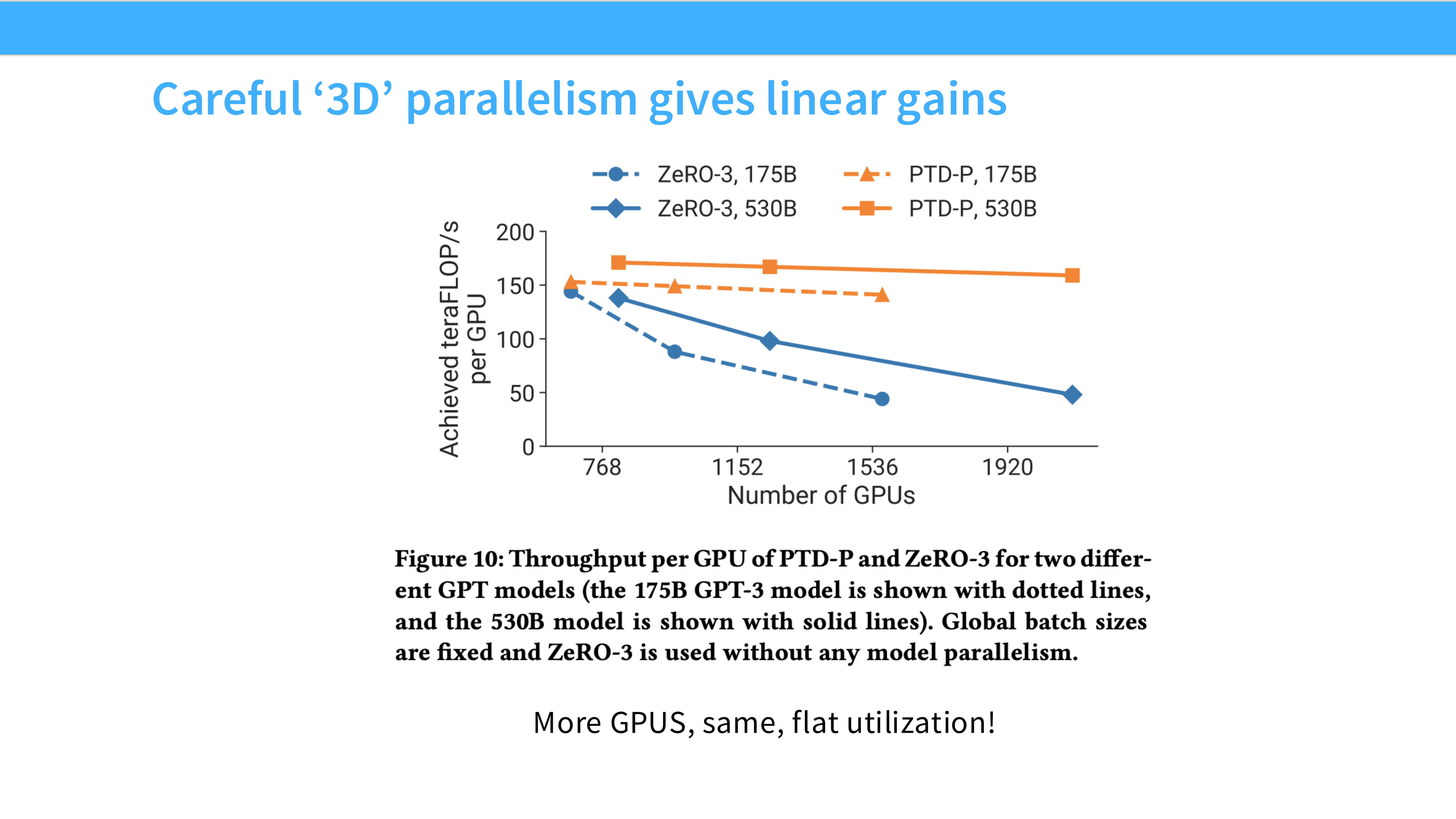
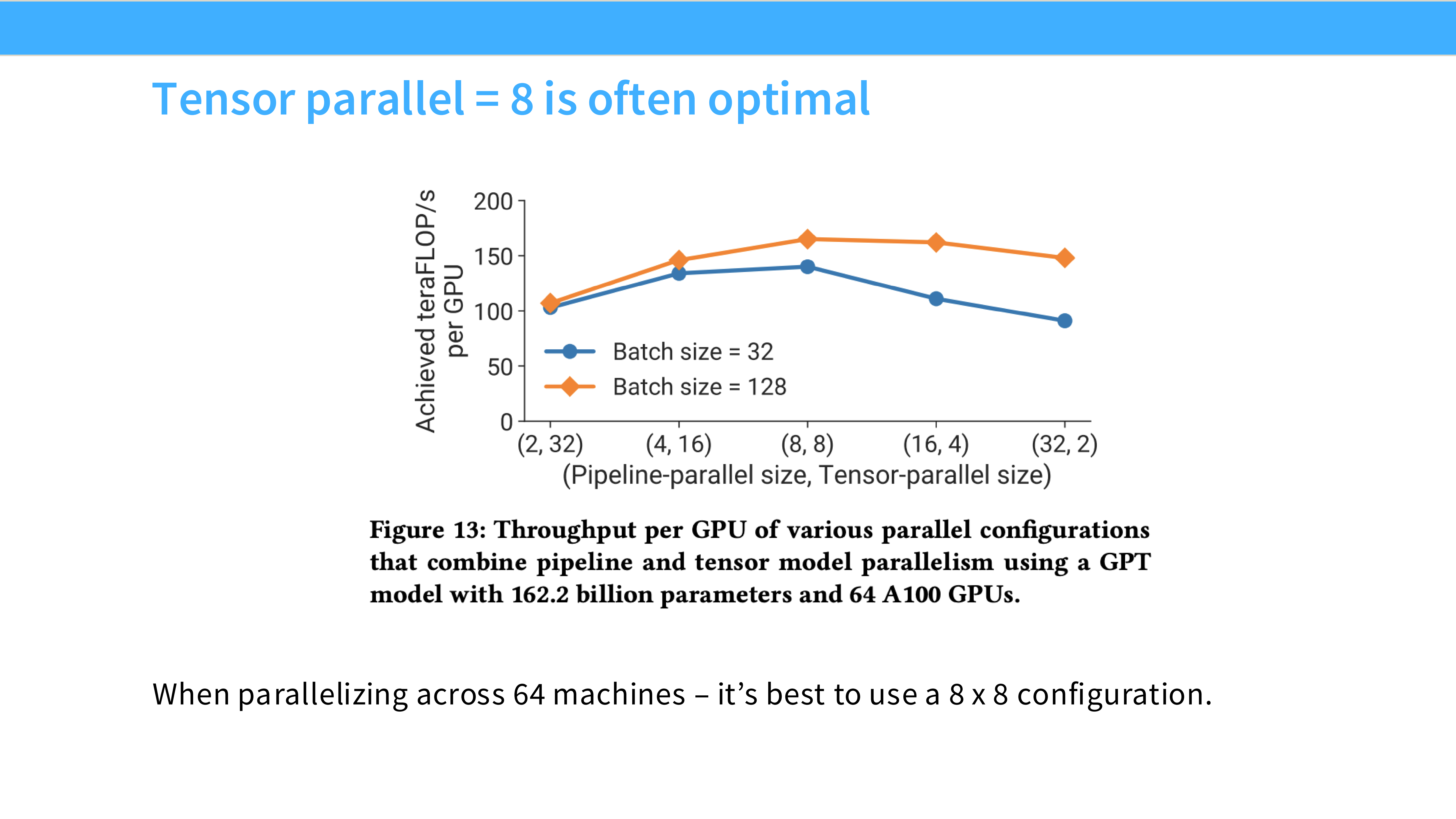
Page 56: 经验法则 (Rules of Thumb)
- 深度解析: 拿到一个模型,该怎么配置并行策略?
- 单卡能跑: 用 DDP 或 ZeRO-1。别折腾别的。
- 单卡跑不动,但单机能跑: 首选 **FSDP (ZeRO-3)**,因为它简单且灵活。如果对延迟极其敏感,用 TP。
- 单机跑不动(超大模型):
- Step 1: 开 TP (通常 TP=8),把单机显存和 NVLink 带宽吃满。
- Step 2: 如果还不够,开 PP,跨机扩展层数。
- Step 3: 在此基础上,开 DP,增加更多机器来并行处理数据,加速训练。
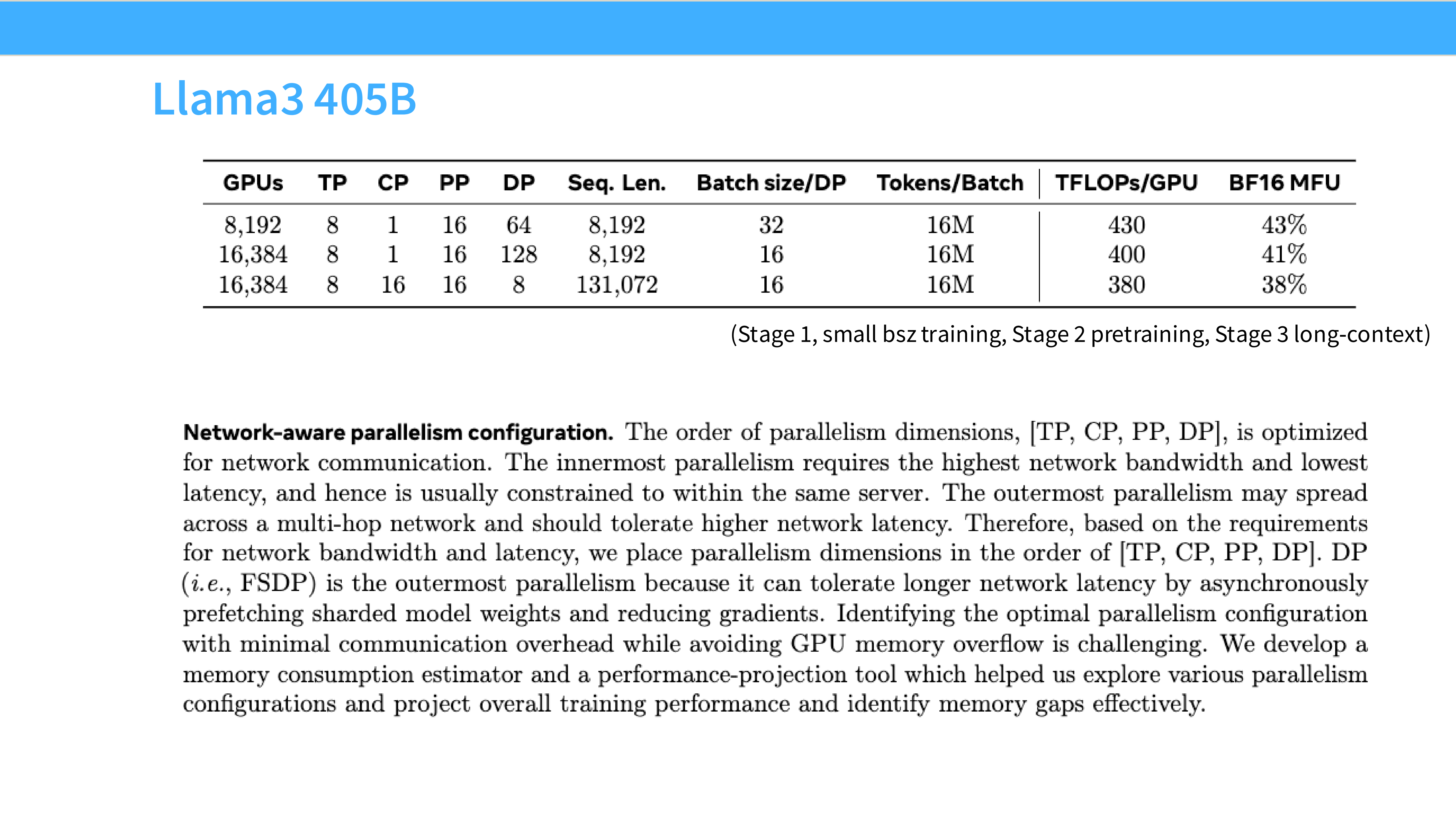
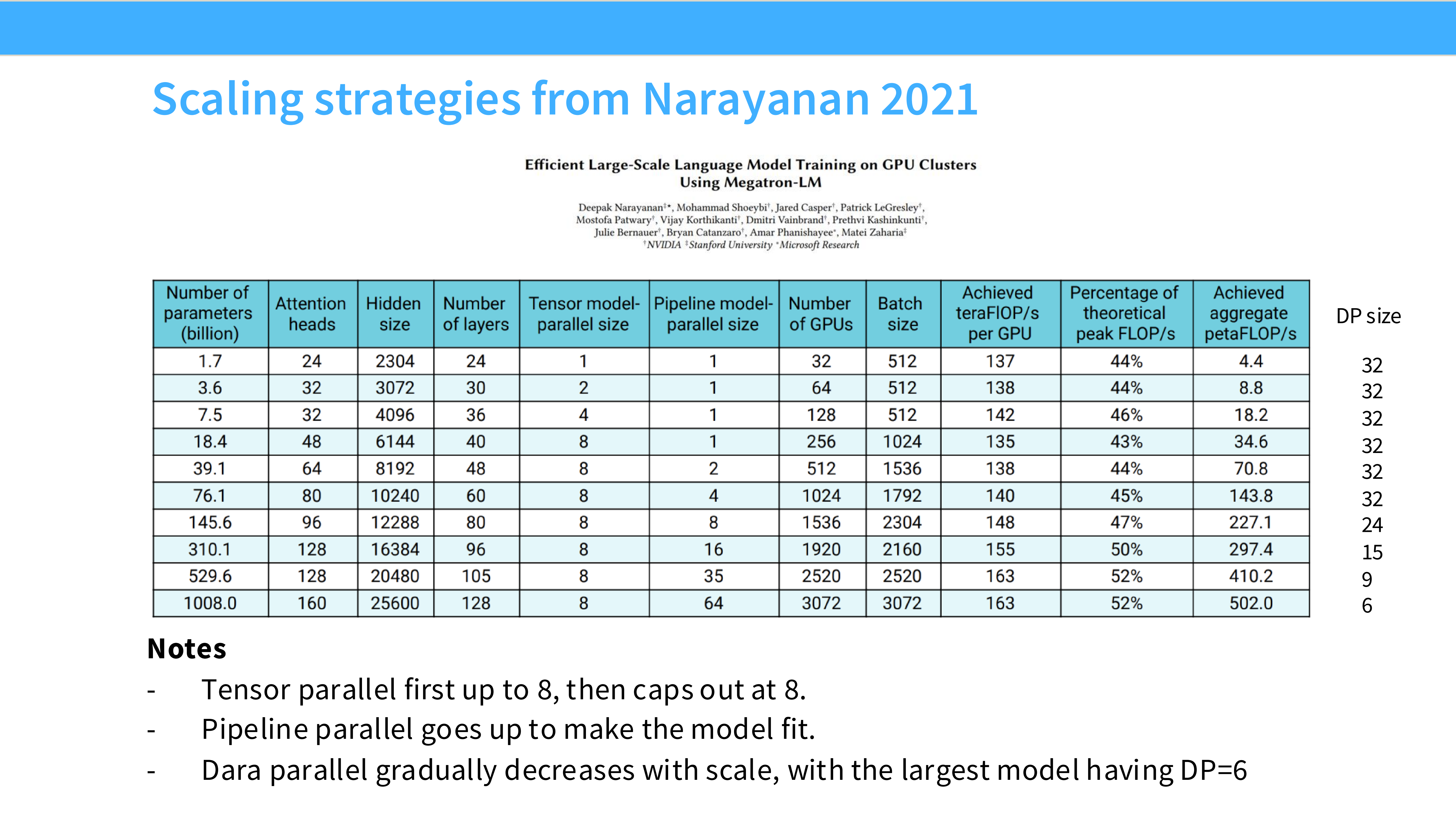
Page 57: 业界案例 - Llama 3 405B
- 深度解析: Meta 是怎么训练 Llama 3 的?
- 规模: 16,384 张 H100。
- 策略: 4D 并行。
- TP=8: 单机内。
- CP=1 (Context Parallel): 处理长文本。
- PP=16: 跨 16 个节点流水线。
- DP=64: 数据并行扩展。
- 设计哲学: 把高频通信(TP)锁在节点内,把低频通信(PP/DP)放在节点间。
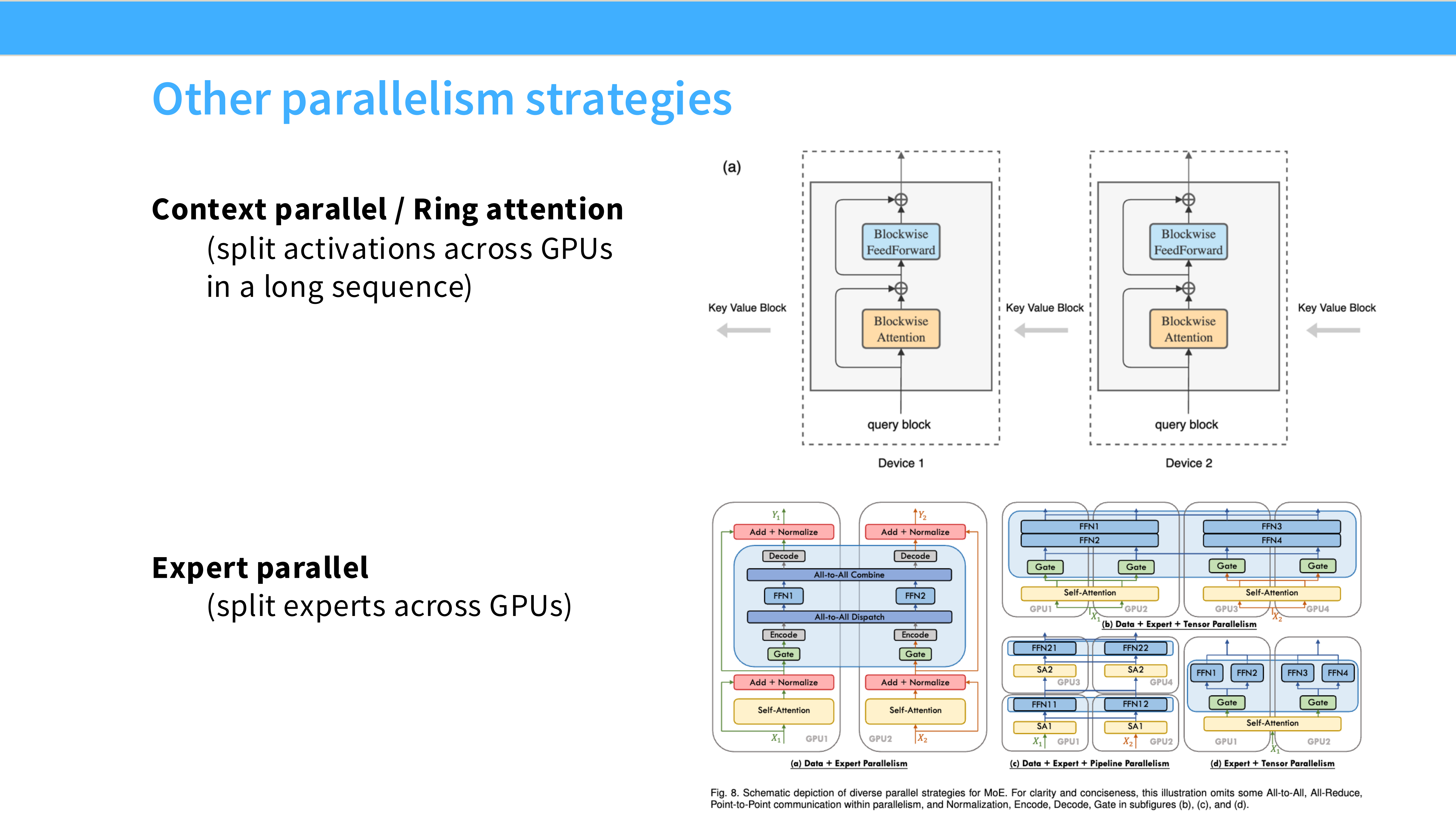
Page 58: 业界案例 - DeepSeek V3
- 深度解析: DeepSeek 的策略非常独特,针对 MoE 进行了优化。
- 策略: No TP! (TP=1)。这是反直觉的。
- EP=64 (Expert Parallel): 专家并行,这是 MoE 特有的。
- PP=16: 深度流水线。
- ZeRO-1: 优化器切分。
- 原因: TP 通信开销大。DeepSeek 采用了 DualPipe 和重叠通信策略,证明了不用 TP 也能高效训练超大 MoE 模型。

Page 59: 业界案例 - Gemma 2 / Yi
- 深度解析:
- Yi (零一万物): 传统的 ZeRO-1 + TP + PP 组合,稳扎稳打。
- Gemma 2 (Google): 使用 TPU。TPU 独特的网络拓扑让它们更倾向于使用 GSPMD(一种自动并行的编译器技术)和 ZeRO-3 风格的参数切分,而不是手写复杂的 TP/PP。

Page 60: 全课总结 (Recap)
- 深度解析:
- Scaling is hard: 超过一定规模(单机),必须引入多机并行。
- Hybrid is necessary: 没有一种并行策略是完美的。TP 费带宽,PP 有气泡,DP 费显存。3D 并行是平衡这三者的艺术。
- First Principles: 所有的策略选择,归根结底都是在算 带宽 (Bandwidth)、延迟 (Latency) 和 显存 (Memory) 的账。理解了硬件特性,就理解了并行策略。
大模型从0到1|第七讲:详解大模型并行化策略
https://realwujing.github.io/linux/drivers/gpu/stanford-cs336/大模型从0到1|第七讲:详解大模型并行化策略/