linux教程
本文最后更新于:2026年1月5日 下午
linux教程
正则表达式
- 正则表达式 – 元字符 | 菜鸟教程 (runoob.com)
- 正则表达式在线测试 | 菜鸟工具 (runoob.com)
- 关于正则表达式中的.,.?,.+?的理解
- 正则表达式和扩展正则表达式
- C语言中的正则表达式使用
- Linux0基础入门,教你如何在Shell中使用正则表达式
终端 Terminal
mobxterm
xshell
作业控制
在 Linux 终端中使用作业控制时:
- 使用
ctrl-z可以将当前正在前台运行的进程暂停(挂起)。 - 使用
fg %1(或fg 1)命令可以将编号为1的作业恢复到前台继续执行。 - 使用
jobs命令可以列出当前在后台运行的所有作业及其作业号和状态。
script
- 强大的Linux终端行为记录和回放工具:script命令详解
- linux情况屏幕一条命令是,Linux中通过script命令那个记录屏幕的输出
- linux下使用script命令生成^ [和^ M个字符的原因和方法
- 【Linux学习 】Linux使用Script命令来记录并回放终端会话
- 终于知道保存SCP日志了
终端复用tmux
- Linux笔记:终端复用与管理工具screen和tmux
- Tmux 使用教程
- Tmux如何让滚屏起飞
- 在tmux缓冲区中搜索
- tmux常用命令及快捷键
- tmux 解决屏幕比例不协调问题
- 【Tmux】窗口周围出现大量点点导致窗口面积减小
Tmux(Terminal Multiplexer)是一款终端复用软件,可以让你在一个终端窗口中运行多个终端会话。以下是一些常用的 tmux 组合键命令:
会话管理
- 启动 tmux 会话:
tmux - 新建会话:
tmux new -s <session-name> - 列出会话:
tmux ls - 连接到会话:
tmux attach -t <session-name> - 分离会话:
Ctrl-b d - 选择会话分离: `Ctrl-b Shift-,可以解决【Tmux】窗口周围出现大量点点导致窗口面积减小的问题
- 杀掉会话:
tmux kill-session -t <session-name>
窗口管理
- 新建窗口:
Ctrl-b c - 切换窗口:
Ctrl-b n(下一个窗口),Ctrl-b p(上一个窗口),Ctrl-b 0(切换到窗口0),Ctrl-b 1(切换到窗口1) - 选择窗口:
Ctrl-b <window-number> - 重命名窗口:
Ctrl-b , - 关闭窗口:
Ctrl-b & - 列出所有窗口:
Ctrl-b w,使用箭头键选择目标窗口,按回车键切换到选定的窗口。
面板管理
- 水平分割面板:
Ctrl-b " - 垂直分割面板:
Ctrl-b % - 切换面板:
Ctrl-b o - 选择面板:
Ctrl-b q然后按面板编号 - 面板之间进行切换:
Ctrl-b <方向键> - 交换面板位置:
Ctrl-b {(向左),Ctrl-b }(向右) - 杀掉面板:
Ctrl-b x - 拆分面板成独立窗口:
Ctrl+b ! - 全屏化当前面板:
Ctrl-b z - 恢复面板原始大小: 再次按
Ctrl-b z - 调整面板大小:
Ctrl-b后加上Alt键和方向键可以调整面板的大小。 - 自动平衡面板:
Ctrl-b后加上Space键自动平衡所有面板大小。
滚动与复制模式
- 进入复制模式:
Ctrl-b [ - 退出复制模式:
q - 开始选择文本:
Space - 复制选中文本:
Enter - 粘贴文本:
Ctrl-b ]
在tmux缓冲区中搜索
复制模式搜索
要在tmux历史记录缓冲区中搜索当前窗口,请按Ctrl- b [进入copy mode。
如果您正在使用emacs键绑定(默认设置),请按Ctrl- s然后输入要搜索的字符串,然后按Enter。按n再次搜索相同的字符串。按Shift- n进行反向搜索。按Escape两次退出copy mode。您可以使用Ctrl- r反向搜索。
请注意,由于tmux可以控制键盘copy mode,所以Ctrl- s不管stty ixon设置如何(我希望stty -ixon在Bash中启用向前搜索)都可以使用-。
如果您使用的是vi键绑定(Ctrl- b:set-window-option -g mode-keys vi),请按,/然后键入要搜索的字符串,然后按Enter。按n再次搜索相同的字符串。与emacs模式一样,按Shift- n进行反向搜索。按q两次退出copy mode。您可以使用?反向搜索。
查找窗口
如果要基于其中显示的内容(也包括窗口名称和标题但不包括历史记录)切换到窗口,(从打开多个窗口开始)请按Ctrl- b f然后键入要搜索的字符串,然后按Enter。如果找到该文本,您将切换到包含该文本的窗口。如果有多个窗口匹配,您将看到一个列表可供选择。
选择会话进行分离
此功能特别适用于当你在多个会话中工作,并且希望快速分离某个特定会话,而不必使用 Ctrl-b d 分离当前会话或手动输入会话名称。
tmux 嵌套使用
当你在本地使用 tmux 登录远程服务器时,如果服务器上也运行了 tmux,常见的问题是:tmux 的指令会被外层会话窗口(本地的 tmux)捕获,导致无法控制服务器上运行的 tmux。比如,当你想通过 Ctrl+b, d 退出服务器上的会话时,结果却退出了本地的 tmux 连接,非常令人沮丧。
解决这个问题的方法其实很简单:按住 Ctrl 键,然后快速按两次 b 键,这样发出的 tmux 指令就会发送到内层会话,也就是服务器上的 tmux,从而实现你想要的操作。
举例:
- 你在本地机器上运行了一个
tmux会话,并通过 SSH 登录到远程服务器。 - 在远程服务器上,你启动了另一个
tmux会话。 - 想要从远程
tmux会话中退出时,不要直接使用Ctrl+b, d,而是按住Ctrl,快速按两次b键,然后按d键。 - 这个操作将使你从远程会话中退出,而本地的
tmux会话不会受到影响。
其他常用命令
- 重新加载 tmux 配置:
Ctrl-b :source-file ~/.tmux.conf - 显示时间:
Ctrl-b t - 刷新屏幕:
Ctrl-b r
这些是 tmux 中一些常见的组合键命令,使用这些命令可以大大提高终端操作的效率。你可以通过编辑 ~/.tmux.conf 文件来自定义这些快捷键。
自动退出
- 删除 tmux 中的 TMOUT 变量
检查 tmux 的全局环境中是否存在 TMOUT:
1 | |
使用以下命令删除该环境变量:
1 | |
解决 tmux 中复制出来的文本尾部带很多空格
set -g set-clipboard on作用:让 tmux 直接把复制的内容同步到系统剪贴板(需要 tmux ≥ 3.2 且终端支持 OSC 52 协议)。
好处:
- 复制内容时,tmux 不会按默认的矩形块方式补空格,而是按实际文本长度发到系统剪贴板。
- 相当于跳过了“选区对齐补空格”这一步。
set -g mouse on作用:允许在 tmux 面板内用鼠标直接选择文本。
好处:
- 当启用了
set-clipboard on后,用鼠标框选文本时,直接把选中的真实字符(不补空格)发到系统剪贴板。 - 不需要进入 tmux 的“复制模式”,因此也不会遇到块选区的补空格问题。
- 当启用了
1️⃣ 临时生效(只影响当前 tmux 会话)
在 tmux 会话中直接执行:
按
Ctrl + b :进入 tmux 命令行模式依次输入:
1
2set -g set-clipboard on
set -g mouse on回车即可立即生效,退出 tmux 后会失效。
2️⃣ 永久生效(每次启动 tmux 都有效)
编辑配置文件:
1
vim ~/.tmux.conf加入:
1
2
3
4
5# 启用系统剪贴板
set -g set-clipboard on
# 启用鼠标支持
set -g mouse on保存后让配置立即生效:
1
tmux source-file ~/.tmux.conf
xterm
在 Linux 系统上安装 xterm 终端仿真器,并使用 resize 命令调整 tmux 会话窗口的大小,可以按照以下步骤进行操作:
安装 xterm
打开终端并输入以下命令以使用
dnf包管理器安装xterm:1
sudo dnf install xterm使用
resize命令调整窗口大小:1
resize
history
shell
- #!/bin/bash 和 #!/usr/bin/env bash 的区别
- 「Linux」shell命令以及运行原理和Linux权限详解
- Linux基础-shell脚本编程
- 一篇教会你写90%的shell脚本 - 知乎 (zhihu.com)
- shell教程(二) 四种工作模式
- linux之登录式shell和非登录式shell
- linux之登录式shell和非登录式shell
父子shell
set
环境变量
-
在 Ubuntu 等使用 PAM(Pluggable Authentication Modules)的系统中,/etc/environment 是在 PAM 模块中读取的,而 /etc/profile 是由 Bourne Shell(例如 Bash)在启动时读取的。
具体来说,在用户登录时,PAM 模块首先读取 /etc/environment 中的环境变量,然后 Bash 或其他 Bourne Shell 在启动时读取 /etc/profile。
所以,/etc/environment 的环境变量会影响整个系统的默认环境,而 /etc/profile 主要影响用户登录 Shell 时的环境。
忽略大小写
-
1
echo "set completion-ignore-case on" >> ~/.inputrc
数组
test
- linux应用之test命令详细解析
- [shell 中$()
- [Shell [[]]详解:检测某个条件是否成立](http://c.biancheng.net/view/2751.html)
- 使用shell 判断文件夹或文件是否存在
- Shell test命令(Shell [])详解,附带所有选项及说明
- linux shell中的case语句用法
重定向、后台运行
- Shell nohup 命令详解_shadow_zed的博客-CSDN博客
- 你知道2>&1 >/dev/null是什么意思么?
- linux 2>&1和&的意思
- Linux 任务后台运行(总结)
- Linux 编辑启动、停止与重启 jar 包脚本
- stdbuf让nohup实时输出日志
- 命令行实现单个进度条,或者刷新一行的内容
- Linux 标准输入输出、重定向、管道、文件权限、后台启动进程命令
- 深入理解Linux中2>&1的含义
Bash 常用快捷键总结
控制相关命令
- **
Ctrl+L**:清屏。 - **
Ctrl+C**:终止前台程序。 - **
Ctrl+\**:终止前台程序(与Ctrl+C类似)。 - **
Ctrl+Z**:将当前进程挂起并切换到后台。
编辑相关命令
- **
Tab**:命令补齐。 - **
Ctrl+A**:光标移到行首。 - **
Ctrl+E**:光标移到行尾。 - **
Ctrl+F**:光标前进。 - **
Ctrl+B**:光标后退。 - **
Ctrl+XX**:光标在当前位置和行首之间切换。 - **
Ctrl+U**:删除光标之前的所有内容。 - **
Ctrl+K**:删除光标之后的所有内容。 - **
Ctrl+H**:删除光标处前一个字符。 - **
Ctrl+D**:删除当前光标所在字符。 - **
Ctrl+W**:删除光标前的单词。 - **
Ctrl+Y**:粘贴Ctrl+K或Ctrl+W删除的内容。 - **
Alt+.或Esc+.**:粘贴上一条命令的最后一个参数。
!相关命令
- **
!!**:快速执行上一条命令。 - **
!+字符串**:执行最近使用过的以指定字符串开头的命令(如!p执行ping命令)。
历史命令
- **
Ctrl+P**:历史中上一条命令(与方向键↑作用一样)。 - **
Ctrl+N**:历史中下一条命令(与方向键↓作用一样)。 - **
Ctrl+R**:查找历史命令中的关键词。
python
ubuntu16.04中将python3设置为默认
直接执行这两个命令即可:
1 | |
切换到Python2,执行:
1 | |
时间
时间协议
登录
sudo vs su
以下是 sudo、su 及相关命令的行为对比表格,包含 Shell 类型、环境变量处理、**$HOME 变化** 等关键信息:
sudo 与 su 命令对比总结
| 命令 | Shell 类型 | 加载的配置文件 | $HOME 行为 |
环境变量继承 | 是否需要密码 | 典型用途 |
|---|---|---|---|---|---|---|
sudo -s |
非登录 Shell | ~/.bashrc |
强制改为 /root |
部分重置(受 env_reset 影响) |
当前用户密码 | 临时以 root 身份执行命令(不切换完整环境) |
sudo -i |
登录 Shell | /etc/profile, ~/.bash_profile, ~/.profile |
改为 /root |
完全重置(全新 root 环境) | 当前用户密码 | 完全模拟 root 登录(完整环境) |
sudo su - |
登录 Shell | /etc/profile, ~/.bash_profile, ~/.profile |
改为 /root |
完全重置(全新 root 环境) | 当前用户密码 | 同 sudo -i(兼容性写法) |
su |
非登录 Shell | ~/.bashrc |
保持原用户的 $HOME |
继承当前环境(可能混用) | 目标用户密码 | 不推荐(环境变量可能冲突) |
su - |
登录 Shell | /etc/profile, ~/.bash_profile, ~/.profile |
改为目标用户的家目录 | 完全重置(目标用户环境) | 目标用户密码 | 安全切换到目标用户(完整环境) |
sudo -Es |
非登录 Shell | ~/.bashrc |
保持原用户的 $HOME |
保留大部分环境变量(-E 选项) |
当前用户密码 | 需要保留原环境变量的临时 root 操作 |
关键行为说明
$HOME变化:sudo -s和sudo -i都会将$HOME改为/root,但前者是 非登录 Shell(仅通过sudo机制强制修改),后者是 登录 Shell(自然行为)。su保持原$HOME,而su -会切换。
环境变量重置:
sudo默认启用env_reset,会清理危险变量(如PATH),但保留HOME、USER等关键变量。su -和sudo -i会加载目标用户的完整环境,而su可能混用环境变量(易出错)。
密码差异:
sudo需输入 当前用户密码(依赖/etc/sudoers配置)。su需输入 目标用户密码(直接切换身份)。
使用场景建议
| 需求 | 推荐命令 | 理由 |
|---|---|---|
| 临时执行单条 root 命令 | sudo <command> |
无需启动 Shell,安全且最小权限。 |
| 需要完整 root 环境 | sudo -i 或 sudo su - |
完全隔离的环境,避免变量污染。 |
| 保留当前环境变量 | sudo -Es |
调试或需要继承当前配置时使用。 |
| 切换到其他用户(非 root) | su - <username> |
安全加载目标用户环境(如 su - oracle)。 |
附:配置文件加载顺序
- 登录 Shell:
/etc/profile→~/.bash_profile→~/.profile - 非登录 Shell:
~/.bashrc(可能通过/etc/bashrc间接加载)
通过此表格可以快速对比不同命令的差异,根据需求选择最合适的权限提升方式!
日志
- rsyslog服务及Linux系统日志简介
- Enable Rsyslog Logging on Debian 12
- Linux系统中的日志管理——journal、rsyslog、timedatectl、时间同步
- Linux 下使用 Logrotate 旋转和压缩日志文件
随机数
硬件信息
lshw
-
查看硬件信息的 class 分类:
1
lshw -short查看特定类型的数据:
1
lshw -c multimedia把硬件信息输出到 html:
1
lshw -html > hw.hhtml
dmidecode
lstopo
-
1
sudo apt install hwloc图形化展示硬件拓扑结构:
1
lstopo文字信息输出硬件拓扑结构:
1
lstopo-no-graphics
进程
lsof
使用-c查看指定的命令正在使用的文件和网络连接:
1 | |
使用-p查看指定进程ID已打开的内容:
1 | |
-t选项只返回PID:
1 | |
同时使用-t和-c选项以给进程发送 HUP 信号:
1 | |
查找进程
进程与信号
杀死进程
lsof
使用-u显示指定用户打开了什么:
1 | |
使用-u user来显示除指定用户以外的其它所有用户所做的事情:
1 | |
杀死指定用户所做的一切事情:
1 | |
查看进程启动位置
列出某一CPU上跑的所有进程
-
列出CPU 43 上的所有进程/线程:
1
ps -eLo pid,psr,command | sed -ne '/^\W\+[0-9]\+\W\+43\W\+/p'
系统状态
top
top主要快捷键
全局命令:
- **
Z**:切换颜色模式。 - **
B**:切换粗体文本。 - **
E/e**:切换内存缩放。
- **
摘要切换:
- **
l**:显示负载平均值。 - **
t**:显示任务/CPU 统计。 - **
m**:显示内存信息。
- **
视图切换:
- **
0**:显示零值。 - **
1, 2, 3**:切换 CPU/NUMA 节点视图。 - **
I**:切换 Irix 模式。
- **
字段管理与排序:
- **
M**:按内存使用量排序。 - **
P**:按 CPU 使用量排序。 - **
T**:按时间/累积时间排序。
新增
PSR字段查看每个进程当前运行的 CPU 核心:- 按
f键:进入字段管理模式。 - 使用上下箭头键查找
PSR字段(表示处理器)。 - 选中
PSR字段后,按 空格键 或d将其标记为显示。 - 按
q或Esc退出字段管理界面,返回主界面。
将
PSR移动到PID字段前面:- 按下
f键进入字段管理界面。 - 使用 上下箭头键
↑和↓找到PSR字段(Processor),然后按 空格键 或d键将其启用。 - 接着按 右箭头键
→将PSR选中,这会准备将PSR字段移动位置。 - 使用 向上箭头键
↑将PSR字段移到列表的最上方位置(或其他你想要的位置)。 - 移动完毕后,按 左箭头键
←或 Enter 键确认位置。 - 最后,按
q或Esc键返回top主界面。
按
PSR排序:- 进入
top后,按下**f** 键进入字段管理。 - 使用方向键
↓或↑移动选择PSR字段。 - 按下
s键将PSR字段设为排序字段。此时,进程会默认按PSR升序排序。 - 若发现是降序排列,按下 **
R**(Shift + r)键可以反转排序顺序,使之变为升序。 - 确认后按
q或Esc退出设置界面返回top界面,即可看到进程按PSR升序排列。
- **
定位与排序:
- **
L/&**:查找/再次查找。 - **
</>**:移动排序列(左/右)(如按下P后按cpu使用率排序,按下>后可以移动到内存使用率排序)。 - **
H**:切换线程显示。 - **
J**:数字字段对齐。 - **
C**:显示坐标。
- **
过滤与操作:
- **
o**:添加过滤条件(如COMMAND=[可用来过滤内核线程)。 - **再次按
o**:添加更多过滤条件(如COMMAND=/可用来进一步过滤pre cpu内核线程)。 - **
u**:按用户过滤。 - **
=**:清除所有过滤条件。 - **
k**:结束任务。 - **
r**:调整任务优先级(renice)。
- **
显示选项:
- **
c**:显示命令名称/行。 - **
i**:显示空闲任务。 - **
S**:显示时间。 - **
j**:字符串字段对齐。 - **
x**:排序字段高亮。 - **
y**:运行任务高亮。 - **
z**:切换颜色/单色显示。 - **
b**:切换粗体/反转文本。
- **
视图模式:
- **
V**:切换森林视图,显示树状进程父子关系、线程父子关系,类似pstree。先按H显示线程,再按V切换到森林视图。 - **
v**:隐藏/显示森林视图子项。
- **
配置与输出:
- **
d或s**:设置更新间隔(秒)。 - **
W**:保存配置。 - **
Y**:检查其他输出。
- **
退出:
- **
q**:退出top。
- **
这些操作帮助你高效地使用 top 进行系统监控、排序和进程管理。
根据你提供的 top 命令输出信息,这里是每个部分的解释:
top 命令输出解析
任务统计:
- **
Tasks: 767 total**:系统中总共有 767 个任务。 - **
1 running**:当前有 1 个任务正在运行。 - **
766 sleeping**:当前有 766 个任务在休眠状态。 - **
0 stopped**:没有任务被停止。 - **
0 zombie**:没有僵尸进程。
- **
CPU 使用情况:
- **
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st**:- **
0.0 us**:用户空间 CPU 使用百分比。 - **
0.0 sy**:系统空间 CPU 使用百分比。 - **
0.0 ni**:用户空间内的优先级 CPU 使用百分比。 - **
100.0 id**:空闲 CPU 百分比。 - **
0.0 wa**:等待 I/O 操作的 CPU 百分比。 - **
0.0 hi**:硬件中断 CPU 使用百分比。 - **
0.0 si**:软件中断 CPU 使用百分比。 - **
0.0 st**:虚拟机偷取的 CPU 百分比。
- **
- **
内存使用情况:
- **
MiB Mem : 32147.1 total**:总内存 32147.1 MiB。 - **
26527.6 free**:可用内存 26527.6 MiB。 - **
648.0 used**:已使用内存 648.0 MiB。 - **
4971.5 buff/cache**:缓冲区和缓存占用的内存 4971.5 MiB。
- **
交换区使用情况:
- **
MiB Swap: 16144.0 total**:总交换区 16144.0 MiB。 - **
16144.0 free**:可用交换区 16144.0 MiB。 - **
0.0 used**:已使用交换区 0.0 MiB。 - **
30980.1 avail Mem**:可用内存 30980.1 MiB。
- **
进程列表:
- **
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND**:进程的详细信息,包括 PID、用户、优先级、虚拟内存、常驻内存、共享内存、状态、CPU 使用百分比、内存使用百分比、运行时间和命令。
示例进程:
**
275 root rt 0 0 0 0 S 0.0 0.0 0:01.31 migration/53**:- PID:275
- USER:root
- PR:实时优先级(rt)
- NI:优先级(0)
- VIRT:虚拟内存(0 KB)
- RES:常驻内存(0 KB)
- SHR:共享内存(0 KB)
- S:进程状态(S,休眠)
- %CPU:CPU 使用百分比(0.0%)
- %MEM:内存使用百分比(0.0%)
- **TIME+**:运行时间(0:01.31)
- COMMAND:进程命令(migration/53)
**
276 root 20 0 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/53**:- PID:276
- USER:root
- PR:普通优先级(20)
- NI:优先级(0)
- VIRT:虚拟内存(0 KB)
- RES:常驻内存(0 KB)
- SHR:共享内存(0 KB)
- S:进程状态(S,休眠)
- %CPU:CPU 使用百分比(0.0%)
- %MEM:内存使用百分比(0.0%)
- **TIME+**:运行时间(0:00.00)
- COMMAND:进程命令(ksoftirqd/53)
- **
这些信息可以帮助你了解系统的资源使用情况和各个进程的状态。
top 查看某个进程的详细资源使用情况
1 | |
1 | |
- **
-H**:显示线程视图,每个线程占用一行。 - **
-c**:显示完整的命令行。 - **
-p 503**:只显示进程 ID 为503的信息,包括该进程的所有线程。
此命令用于查看进程 ID 为 503 的进程及其所有线程的详细资源使用情况。

top 查看qemu-kvm进程的详细资源使用情况
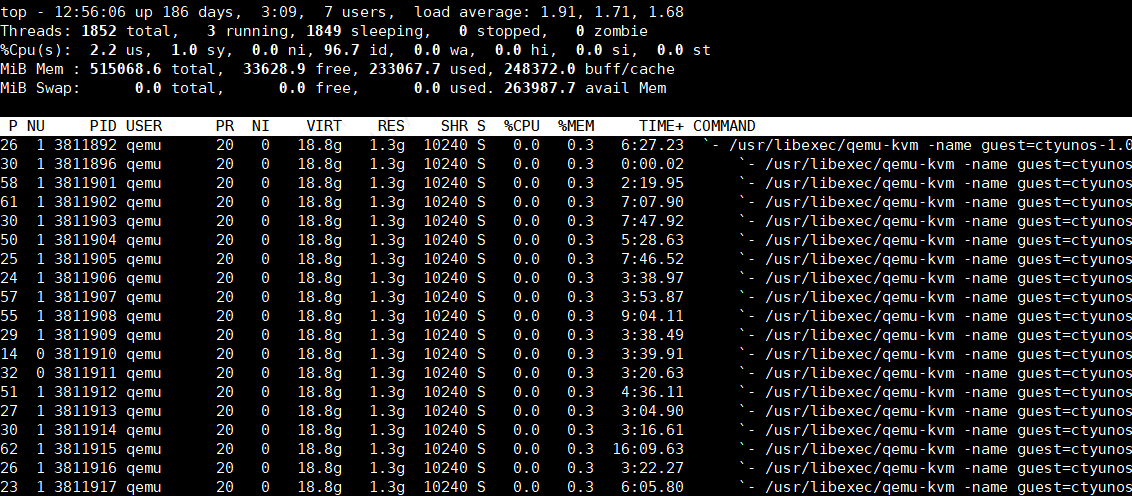
以下是 top 命令输出中每个字段的详细解释:
- P (PSR): Processor,表示线程当前在运行的物理 CPU 核心编号。
- NU: NUMA 节点编号,指示线程所关联的 NUMA 节点。
- PID: 进程 ID,标识进程的唯一编号。
- USER: 进程的所属用户,即运行该进程的用户。
- PR: 优先级(Priority),数值越小优先级越高。实时优先级范围通常为 0-99,普通优先级范围为 100-139。
- NI: nice 值,用于调整进程的优先级,范围为 -20(最高优先级)到 19(最低优先级)。
- VIRT: 虚拟内存大小(Virtual Memory Size),即进程使用的虚拟地址空间总量,包括交换分区和物理内存。
- RES: 常驻内存(Resident Memory),即进程实际占用的物理内存大小,不包含交换内存。
- SHR: 共享内存(Shared Memory),即进程与其他进程共享的内存大小。
- S: 进程状态(State),通常包括:
R: 运行中(Running)S: 睡眠(Sleeping)D: 不可中断的睡眠(Uninterruptible Sleep)Z: 僵尸进程(Zombie)T: 停止或追踪(Stopped or Traced)
- %CPU: 进程使用的 CPU 百分比,表示进程在最近一段时间内占用的 CPU 资源比例。
- %MEM: 进程使用的物理内存百分比,相对于系统总内存的占用情况。
- TIME+: 进程累计的 CPU 时间,格式为
分钟:秒.百分秒,表示进程启动以来的总 CPU 占用时间。 - COMMAND: 执行的命令行或进程名称。
关于 跨 NUMA 的情况:
在图中,NU 列显示了多个 QEMU 线程分布在不同的 NUMA 节点上(例如,节点 0 和节点 1),这表明 QEMU-KVM 进程的线程确实存在跨 NUMA 的情况。这种分布可能会导致内存访问延迟的增加,因为不同的 NUMA 节点访问内存时会有不同的延迟。如果性能要求较高,建议对线程的 NUMA 亲和性进行优化,以减少跨 NUMA 访问的影响。
htop
network
端口
nc
nc是网络工具中的瑞士军刀。
补充说明
nc命令 全称netcat,用于TCP、UDP或unix域套接字(uds)的数据流操作,它可以打开TCP连接,发送UDP数据包,监听任意TCP 和UDP端口,同时也可用作做端口扫描,支持IPv4和IPv6,与Telnet的不同在于nc可以编写脚本。
语法
1 | |
选项
1 | |
TCP端口扫描:
1 | |
扫描192.168.0.3 的端口 范围是 1-100 扫描UDP端口:
1 | |
扫描指定端口,如 80:
1 | |
端口占用
netstat
netstat 查看22端口是否被占用:
1 | |
netstat -s 通常会显示网络协议(如 TCP、UDP、IP)的统计信息,包括:
- 数据包发送和接收的数量
- 错误数(如丢包或校验错误)
- 重传和连接状态
1 | |
1 | |
lsof
使用-i:port来显示与指定端口相关的网络信息:
1 | |
ss
使用 ss 命令查看22端口是否被占用:
1 | |
这条命令 ss -tulnp | head -n1 输出的是 ss 命令结果的第一行,它显示了 ss 输出的列标题。这些列分别表示:
- Netid: 网络协议类型(如 TCP、UDP 等)。
- State: 套接字状态(如 LISTEN、ESTABLISHED 等)。
- Recv-Q: 接收队列的字节数。
- Send-Q: 发送队列的字节数。
- Local Address:Port: 本地地址和端口。
- Peer Address:Port: 对等地址和端口(在监听状态下为空)。
- Process: 正在使用该套接字的进程及其 PID。
1 | |
ss 是一个用于查看网络连接、套接字统计和进程信息的工具。常用参数包括:
-t: 显示 TCP 套接字。-u: 显示 UDP 套接字。-l: 仅显示监听状态的套接字。-n: 以数字形式显示地址和端口。-p: 显示使用套接字的进程信息。
例如,sudo ss -tulnp 可以显示当前系统中监听的所有网络端口及其对应的进程。
bond
ip
- 通过 12 个样例掌握 Linux IP 命令
- 如何将Linux的NIC 名称更改为 eth0 而不是 enps33 或 enp0s25,只要几秒钟
- linux服务器查看公网IP信息的方法 - 小帅豹 - 博客园 (cnblogs.com)
- IP、域名和端口号之间的联系
- Linux中20个高级命令
- A、B、C、D、E类IP地址划分依据
- IP地址划分、子网掩码的作用、实际中IP地址规划
- 刚插上网线,电脑怎么知道自己的IP是什么?
- ip扫描命令 linux,如何使用Linux扫描网络上的IP地址
ipcalc
1 | |
啥是网络地址、广播地址?
在IP网络中,网络地址和广播地址是子网中两个特殊的保留地址,它们有明确的定义和作用:
1. 网络地址(Network Address)
• 定义:子网中的第一个IP地址,用于标识整个子网本身。
• 作用:
• 表示“这个子网”,类似于“XX小区”的门牌号。
• 不能被分配给任何设备(如主机、路由器)。
• 示例:
在子网 10.244.208.0/26 中:
• 网络地址是 10.244.208.0。
• 二进制最后6位全为 0(000000)。
2. 广播地址(Broadcast Address)
• 定义:子网中的最后一个IP地址,用于向子网内所有设备发送广播消息。
• 作用:
• 发送到广播地址的数据包会被子网内所有主机接收。
• 不能被分配给任何设备。
• 示例:
在子网 10.244.208.0/26 中:
• 广播地址是 10.244.208.63。
• 二进制最后6位全为 1(111111)。
3. 为什么需要保留这两个地址?
| 地址类型 | 保留原因 | 类比解释 |
|---|---|---|
| 网络地址 | 标识子网范围,帮助路由器和设备区分不同子网。 | 类似“XX市XX区”的地域标识。 |
| 广播地址 | 支持ARP、DHCP等协议,允许一次性向子网内所有设备发送通知(如“找网关”)。 | 类似小区广播喇叭,全员通知。 |
4. 如何计算这两个地址?
以 10.244.208.0/26 为例:
确定主机位:
/26表示前26位是网络位,后6位是主机位(32 - 26 = 6)。网络地址:
• 主机位全置0:10.244.208.00000000→10.244.208.0。广播地址:
• 主机位全置1:10.244.208.00111111→10.244.208.63。
5. 实际影响
• 可用IP范围:
在 10.244.208.0/26 中,实际可用的主机IP是 10.244.208.1 ~ 10.244.208.62(共62个)。
• 配置错误示例:
• ❌ 将 10.244.208.0 分配给服务器 → 网络不通。
• ❌ 将 10.244.208.63 设为网关 → 广播风暴风险。
6. 常见协议依赖广播地址
• ARP:通过广播地址 FF:FF:FF:FF:FF:FF 解析IP对应的MAC地址。
• DHCP:客户端通过广播地址 255.255.255.255 动态获取IP。
• NTP:时间同步协议可能使用广播。
总结
• 网络地址 = 子网的“身份证”,主机位全 0。
• 广播地址 = 子网的“大喇叭”,主机位全 1。
• 它们不可用作设备IP,但支撑了网络通信的基础功能。
/etc/hosts
net-tools iproute2
- Iproute2命令集提供完整的底层网络配置能力。有个从旧的net-tools命令集到新的iproute2命令集的转换表。
- ifconfig命令–显示或设置网络设备参数信息
- ip命令是Linux加强版的的网络配置工具,用于代替ifconfig命令。
- ip命令图文详解- Linux系统和网络管理员必备工具
- ifconfig/docker删除虚拟网卡
brctl
iptables
dns
nslookup
traceroute
traceroute 是一个用于追踪网络数据包从源到目标主机的路径的工具。它显示数据包经过的每一跳(即每一个路由器或网关)以及每一跳的延迟时间。这对于网络故障排查、分析网络路径和了解网络拓扑非常有用。
基本用法
1 | |
例如:
1 | |
解释输出
traceroute 的输出会列出数据包从源到目标主机所经过的每一跳。每一行代表一跳,并显示以下信息:
- 跳数: 每一跳的编号,从 1 开始。
- 路由器 IP 地址: 数据包在这一跳所经过的路由器的 IP 地址。
- 主机名: 该路由器的主机名(如果能解析)。
- 延迟时间: 数据包从源到这一跳的往返时间(通常显示三次)。
常用选项
-n: 只显示 IP 地址,而不尝试解析主机名。-I: 使用 ICMP 回显请求(类似于 ping)而不是默认的 UDP 数据包。-T: 使用 TCP SYN 数据包进行追踪。-m <max_hops>: 设置最大跳数,默认为 30。-q <number_of_queries>: 每跳发送的探测包数量,默认为 3。
示例
基本使用:
1
traceroute google.com输出会显示数据包从你的位置到 Google 服务器经过的路径。
使用 ICMP 包进行追踪:
1
traceroute -I www.example.com这种方式更接近
ping的工作方式,可能对某些防火墙更友好。只显示 IP 地址:
1
traceroute -n www.example.com这样可以加快追踪速度,尤其在 DNS 解析慢的情况下。
traceroute 工具在网络诊断、排查网络延迟和确定网络路径时非常有帮助。
traceroute原理
traceroute 的工作原理基于 IP 数据包的 TTL(Time To Live) 字段,以及 ICMP(Internet Control Message Protocol)消息。它利用 TTL 的特性逐跳追踪数据包的路径,最终显示数据包从源到目标主机的路由信息。
TTL 字段:
- 每个 IP 数据包都有一个 TTL 字段,表示数据包可以经过的最大路由器数量。
- 当数据包经过一个路由器时,TTL 值会减 1。
- 如果 TTL 值变为 0,路由器会丢弃该数据包,并返回一个 ICMP “Time Exceeded” 消息给发送者。
逐跳增加 TTL:
traceroute工具首先发送一个 TTL 为 1 的数据包。- 第一个路由器接收到该数据包后,将 TTL 减 1,TTL 变为 0,于是路由器丢弃该数据包,并返回一个 ICMP “Time Exceeded” 消息。
traceroute记录下这个 ICMP 消息中的路由器信息(如 IP 地址和延迟时间),并将其作为第一个跳的结果输出。- 接着,
traceroute发送一个 TTL 为 2 的数据包,这个数据包能到达第二个路由器,再次触发 “Time Exceeded” 消息。 - 这个过程一直重复,直到数据包到达目标主机,或者达到设置的最大跳数(通常为 30)。
识别目标主机:
- 当目标主机收到数据包后,会返回一个 “ICMP Port Unreachable” 消息(如果使用默认的 UDP 数据包)或者一个 TCP/ICMP 响应(如果使用
-I或-T选项)。 - 当
traceroute接收到此消息时,停止追踪,并显示完整路径。
- 当目标主机收到数据包后,会返回一个 “ICMP Port Unreachable” 消息(如果使用默认的 UDP 数据包)或者一个 TCP/ICMP 响应(如果使用
延迟时间的计算:
traceroute在每一跳发送三个探测包,并计算从发送数据包到收到 ICMP 响应的时间延迟。这些延迟反映了从源到该跳的往返时间。
其他重要概念
ICMP:默认情况下,
traceroute使用 UDP 数据包来进行探测,但它依赖于 ICMP “Time Exceeded” 和 “Port Unreachable” 消息来工作。使用-I选项时,traceroute会直接使用 ICMP 回显请求(类似于ping)。端口号:默认情况下,
traceroute使用 UDP 数据包,目标端口号从一个高的值(通常是33434)开始,并逐跳递增。目标主机通常会返回 “ICMP Port Unreachable” 消息,因为这些高端口号大多数没有实际服务监听。
典型问题
- 防火墙和路由器过滤:某些防火墙和路由器会阻止 ICMP 或高端口的 UDP 数据包,导致
traceroute无法获取某些跳的路由信息。 - 多路径路由:在有些情况下,路径中的不同跳可能会变化,这导致
traceroute显示不同的路径,特别是在负载均衡环境中。
traceroute 的原理非常适合用来诊断网络问题,了解数据包在网络中的传输路径,并发现可能的瓶颈或故障点。
代理
正向代理 反向代理
wsl2使用w11代理
在WSL 2中,Windows主机的IP通常可以通过以下命令获取:
1 | |
在WSL中设置代理:
1 | |
文件系统
rm
trash-cli
Linux 权限
mount
/etc/fstab
1 | |
软链接和硬链接
- linux里创建快捷方式和查看快捷方式的指向
- 【Linux】:Linux下创建软链接(快捷方式) - Geeksongs - 博客园 (cnblogs.com)
- 「来道题」Linux的软链接
- 5分钟让你明白“软链接”和“硬链接”的区别
- 一文搞懂 Linux 的 inode!
- linux文件-link函数(文件硬链接和软连接)
- Linux中软链接、硬链接以及mount bind的区别
dd
lsof
显示当前打开的 /var/log/messages 文件及相关进程信息:
1 | |
lsof /var/log/messages 的输出可能会包含以下几列:
- COMMAND: 打开文件的进程名。
- PID: 进程 ID。
- USER: 进程所属用户。
- FD: 文件描述符(例如
cwd,txt,mem,1,2等)。 - TYPE: 文件类型(例如
REG表示常规文件)。 - DEVICE: 设备号。
- SIZE/OFF: 文件大小或偏移量。
- NODE: 节点号。
- NAME: 文件名或路径。
stat
find
- Linux下which、whereis、locate、find命令的区别
- find 命令的 7 种用法
- linux shell find命令 查找多种文件后缀
- Linux copy时排除某文件/目录 - 简书 (jianshu.com)
- linux find grep组合使用
- find命令详解
- Linux 中如何获取文件的绝对路径
xargs
grep sed awk
grep
- 三剑客基础详解(grep、sed、awk)
- Linux中grep详解
- grep -s 去掉 no such file or directory
- grep 只从指定文件中查找,并且排除某些文件夹
- grep 命令(在指定文件的文件类型中查找)
- Linux: grep多个关键字“与”和“或”
- grep中的正则表达式
grep 使用 基础正则(BRE)、扩展正则(ERE)、Perl 兼容正则(PCRE) 的核心区别
以下是 grep 使用 基础正则(BRE)、扩展正则(ERE)、Perl 兼容正则(PCRE) 的核心区别总结,通过对比表格和示例说明:
1. 核心特性对比
| 特性 | 基础正则(BRE) | 扩展正则(ERE) | Perl 兼容正则(PCRE) |
|---|---|---|---|
| 启用选项 | grep(默认) |
grep -E 或 egrep |
grep -P(需支持) |
| 元字符转义 | 大部分元字符需转义(如 \+) |
元字符无需转义(如 +) |
元字符无需转义(如 \d) |
| 高级语法 | 不支持 |、?、+ 等 |
支持 |、?、+、{} |
支持零宽断言、非贪婪匹配等 |
| 常见用途 | 简单匹配 | 中等复杂度匹配 | 复杂模式(如日志分析) |
2. 元字符差异示例
匹配 “error” 或 “warning”
- BRE(需转义):
1
grep "error\|warning" file.txt - ERE(直接使用):
1
grep -E "error|warning" file.txt - PCRE(语法同 ERE,但功能更多):
1
grep -P "error|warning" file.txt
匹配 1~3 位数字
- BRE(转义
{}):1
grep "[0-9]\{1,3\}" file.txt - ERE/PCRE(无需转义):
1
grep -E "[0-9]{1,3}" file.txt
3. 高级功能对比
Perl 独有特性
\d(数字)、\s(空白符)、\w(单词字符):1
grep -P "\d+" file.txt # 匹配连续数字- 零宽断言(匹配位置):
1
grep -P "foo(?=bar)" file.txt # 匹配 "foo" 且后接 "bar" - 非贪婪匹配:
1
grep -P "a.*?b" file.txt # 匹配最短的 "a...b"
4. 使用建议
- 简单文本:用默认 BRE(如
grep "pattern")。 - 逻辑或/重复:用 ERE(
grep -E)。 - 复杂模式(如提取数据):用 PCRE(
grep -P)。 - 兼容性:
- macOS 默认
grep不支持-P,需安装 GNU grep(brew install grep)。 - 脚本中优先用
-E保证可移植性。
- macOS 默认
经典示例
提取引号内内容
- PCRE(简洁精准):
1
grep -Po '(?<=")[^"]*(?=")' file.txt - ERE(需迂回实现):
1
grep -Eo '"[^"]*"' file.txt | sed 's/"//g'
总结
- BRE:适合基础搜索,但需频繁转义。
- ERE:平衡功能与可读性,推荐日常使用。
- PCRE:处理复杂场景的终极武器,但依赖环境。
根据需求选择正则类型,可以大幅提升文本处理效率!
grep 特殊字符串
使用单引号并不能避免 * 等字符被解释为正则表达式的一部分。为了完全匹配包含这些特殊字符的字符串,以下是两种推荐的方式:
使用转义字符:
需要对特殊字符进行转义,例如*和(等,确保它们不会被解释为正则表达式符号。1
grep -rn "\(struct wait_queue_entry \*wq_entry, unsigned mode, int flags, void \*key\)" /path/to/source/code使用
-F选项:
如果想避免手动转义所有特殊字符,可以使用grep -F或fgrep,将搜索字符串视为纯文本进行匹配。1
grep -rnF "(struct wait_queue_entry *wq_entry, unsigned mode, int flags, void *key)" /path/to/source/code
这两种方式可以帮助你在代码中准确查找包含特殊字符的字符串。
sed
复制第 1119 行到 1224 行的内容:
1 | |
- 在Bash脚本中完成变量替换和指定文件内容替换的方法
- sed 模式分隔符
- sed 字符串替换 - Amei1314 - 博客园 (cnblogs.com)
- sed 功能强大的流式文本编辑器
- linux sed查找文件中某个值,linux查找文件中间某几行之sed用法小结
- linux使用sed命令批量替换某个目录下文件的内容
- [sed 脚本分隔符引起的问题unknown option to `s’](https://www.cnblogs.com/cheyunhua/p/14265690.html)
- SED命令
awk
tail
cat EOF
tee
解压缩
- Linux命令之解压缩:tar、zip、rar 命令_阿飞的博客-CSDN博客_linux解压rar包命令
- Linux zip命令 | 菜鸟教程 (runoob.com)
- linux下tar.gz、tar、bz2、zip等解压缩、压缩命令小结_LINUX_操作系统_脚本之家 (jb51.net)
- Linux下tar命令解压到指定的目录
- 想学Linux中的打包和压缩?看这一篇就够了
常用压缩/解压命令(简洁版)
.tar.xz 文件(高压缩率,较慢)
压缩:
1
tar -cJvf file.tar.xz file_or_dir
解压:
1
tar -xJvf file.tar.xz
.tar.gz 文件(压缩率与速度平衡)
压缩:
1
tar -czvf file.tar.gz file_or_dir
解压:
1
tar -xzvf file.tar.gz
.zip 文件(跨平台兼容)
压缩:
1
zip -r file.zip file_or_dir
解压:
1
unzip file.zip
总结对照表
| 格式 | 压缩命令 | 解压命令 |
|---|---|---|
.tar.xz |
tar -cJvf file.tar.xz file/ |
tar -xJvf file.tar.xz |
.tar.gz |
tar -czvf file.tar.gz file/ |
tar -xzvf file.tar.gz |
.zip |
zip -r file.zip file/ |
unzip file.zip |
✅
-v(verbose)参数可选,用于显示详细进度信息。
✅ 解压.tar.xz/.tar.gz时,-J/-z可省略,tar通常会自动检测格式。
如需进一步精简去掉 -v,可以用如下形式:
.tar.xz:tar -cJf/tar -xJf.tar.gz:tar -czf/tar -xzf.zip:zip -r/unzip
查看压缩包内容
下面是关于不解压查看 .tar.xz、.tar.gz、.zip 文件内容的方法总结,适用于 Linux 命令行环境:
✅ 一、.tar.gz 文件查看
1 | |
-t:列出归档内容(list)-z:通过 gzip 解压-f:指定归档文件
示例
1 | |
✅ 二、.tar.xz 文件查看
1 | |
-t:列出内容-v:详细输出(可选)-f:指定文件- 自动识别
.xz压缩,无需手动加-J
示例
1 | |
✅ 三、.zip 文件查看
1 | |
-l:列出 zip 包内文件
或使用更详细格式:
1 | |
📌 总结对比表
| 格式 | 命令 | 说明 |
|---|---|---|
.tar.gz |
tar -tzf file.tar.gz |
查看 gzip 压缩的 tar 包 |
.tar.xz |
tar -tvf file.tar.xz |
查看 xz 压缩的 tar 包 |
.zip |
unzip -l file.zip 或 zipinfo file.zip |
查看 zip 文件内容 |
如需进一步筛选(比如只看 .log 文件或某个目录),可以配合 grep:
1 | |
分卷压缩
以下是三种格式的分卷压缩和解压命令(简洁版),适合大文件分割打包:
.tar.gz / .tar.xz 分卷压缩
tar 本身不支持分卷,但可结合 split 命令实现:
压缩并分卷
1 | |
或:
1 | |
-b 100M指每卷大小,file.tar.gz.part_aa、file.tar.gz.part_ab… 是输出文件名。
合并并解压
1 | |
或:
1 | |
.zip 分卷压缩(zip 本身支持)
压缩并分卷
1 | |
生成
file.z01、file.z02… 和主文件file.zip
解压
1 | |
总结对照表
| 格式 | 分卷压缩命令 | 解压命令 |
|---|---|---|
.tar.gz |
tar -czf - dir/ | split -b 100M - file.tar.gz.part_ |
cat file.tar.gz.part_* | tar -xzf - |
.tar.xz |
tar -cJf - dir/ | split -b 100M - file.tar.xz.part_ |
cat file.tar.xz.part_* | tar -xJf - |
.zip |
zip -r -s 100m file.zip dir/ |
unzip file.zip |
✅ 分卷文件一定不能重命名。
✅.zip分卷压缩无需cat合并,直接unzip主.zip文件即可。
远程命令
上传下载文件
sftp
使用 sftp 连接远程服务器时,可以通过 -oPort 选项指定端口。以下是使用 sftp 指定端口的命令示例:
1 | |
示例
假设你要通过端口 2222 连接到名为 example.com 的服务器,并且用户名是 user,可以使用以下命令:
1 | |
参数说明
- **
-oPort=端口号**:指定连接到服务器的端口号。 - **
用户名@主机名**:指定用户名和主机名(或 IP 地址)以进行连接。
这种方式可以让你在连接到非默认端口的 SFTP 服务器时进行指定。
scp
使用 scp 命令时,如果需要指定端口,可以使用 -P 选项:
1 | |
rsync
rsync 使用 -e 选项来指定通过 SSH 使用特定的端口:
1 | |
参数说明:
-a:归档模式,表示递归传输并保持文件属性。-v:详细模式,显示传输过程中的详细信息。-z:压缩传输文件,以减少传输的数据量。-P:显示传输进度,并在传输中断后能够继续传输。-e 'ssh -p 10000':使用指定的 SSH 命令和端口(这里是 10000)。linux-y.tar.gz:要传输的本地文件。root@10.63.8.158:/inf/yql/code:远程服务器的目标路径。
ssh
Win10怎么配置ssh密钥免密连接Linux服务器_windows10_Windows系列_操作系统_脚本之家 (jb51.net)
VSCode Remote ssh跳板机配置(linux环境)
现有三台机器A、B、C,期望从机器A上通过跳板机B免密远程登录机器C。
在机器A上执行如下命令:
1
2
3
4ssh-keygen
ssh-copy-id uos@10.20.53.160
# 将机器A的公钥复制到机器B
rsync -avzP ~/.ssh/id_rsa.pub uos@10.20.53.160:~在机器B上执行如下命令:
1
2
3
4ssh-keygen
ssh-copy-id uos@192.168.122.76
# 将机器A的公钥复制到机器C
rsync -avzP ~/id_rsa.pub uos@192.168.122.76:~在机器C上执行如下命令:
1
cat id_rsa.pub >> ~/.ssh/authorized_keys在机器A上的
~/.ssh/config添加机器A、B、C配置(机器A是本机,可以忽略):1
2
3
4
5
6
7
8
9
10
11
12Host 192.168.122.76-uos20-1060-arm #机器C
HostName 192.168.122.76
User uos
ProxyJump 10.20.53.160-uos20-1060-arm
Host 10.20.53.160-uos20-1060-arm # 机器B
HostName 10.20.53.160
User uos
Host 10.20.53.48-deepin20.9-amd # 机器A
HostName 10.20.53.48
User uos
Windows 11 使用 WSL2 Ubuntu 中的 SSH 配置
在 PowerShell(管理员权限)中执行:
1 | |
测试连接:
1 | |
说明
- 通过符号链接实现配置共享
- Windows 直接使用 WSL 中的 SSH 配置文件
- 保持配置统一,便于管理
验证效果
命令执行成功后,Windows 11 即可使用 WSL2 Ubuntu 中的 SSH 配置进行连接。
termux
crontab计划任务
- linux中crontab计划任务怎么删除?_LINUX_操作系统_脚本之家 (jb51.net)
- Linux中的cron计划任务配置详解_Linux教程_Linux公社-Linux系统门户网站 (linuxidc.com)
- 在线crontab表达式执行时间计算工具_蛙蛙在线工具 (iamwawa.cn)
- crontab执行时间计算 - 在线工具 (tool.lu)
Patch
BuildStream
输入法
debian12
debian12上安装ibus中文输入法:
1 | |