ovs veth peer Soft Lockup on netdev_pick_tx due to zero real_num_tx_queues When Executing ip link del veth0
ovs veth peer Soft Lockup on netdev_pick_tx due to zero real_num_tx_queues When Executing ip link del veth0
测试环境
1 | |
复现步骤
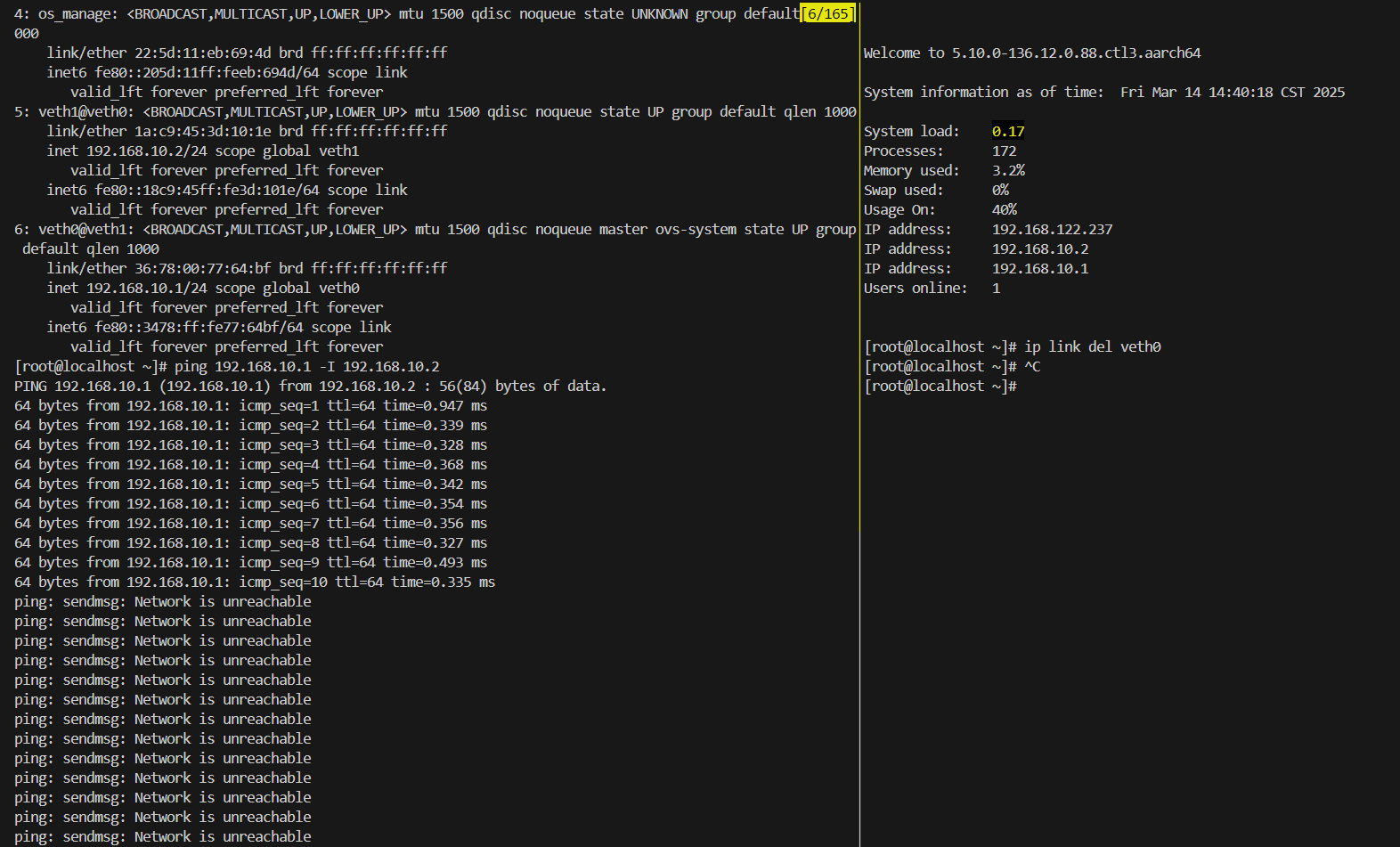
在13设备上复现了一下,创建完网桥,网桥上的流量越大复现概率越高:
1 | |
本地搭建虚拟机狗酱轻量级复现环境
参考复现脚本:
1 | |
1 | |
在本地搭建的虚拟机上无法复现此bug,但是可以用来调试获取关键路径堆栈。
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
根因定位
配置 Linux 内核在检测到任务挂起(hung task)或软锁死(soft lockup)时触发系统崩溃(panic):
1 | |
vmcore-dmesg.txt
1 | |
crash
1 | |
1 | |
sys
sys查看panic原因:
1 | |
bt
bt
bt 查看堆栈回溯:
1 | |
bt -sx
bt -sx:
- **
bt**:在crash工具中,显示当前任务的调用栈(函数调用顺序)。 - **
-s**:把地址变成函数名,方便看。 - **
-x**:用十六进制显示地址。
1 | |
bt -slx
bt -slx:
- **
bt**:在crash工具中,显示调用栈(函数调用顺序)。 - **
-s**:显示函数名(符号化)。 - **
-l**:显示源代码文件名和行号(如果有调试信息)。 - **
-x**:用十六进制显示地址。
1 | |
dis
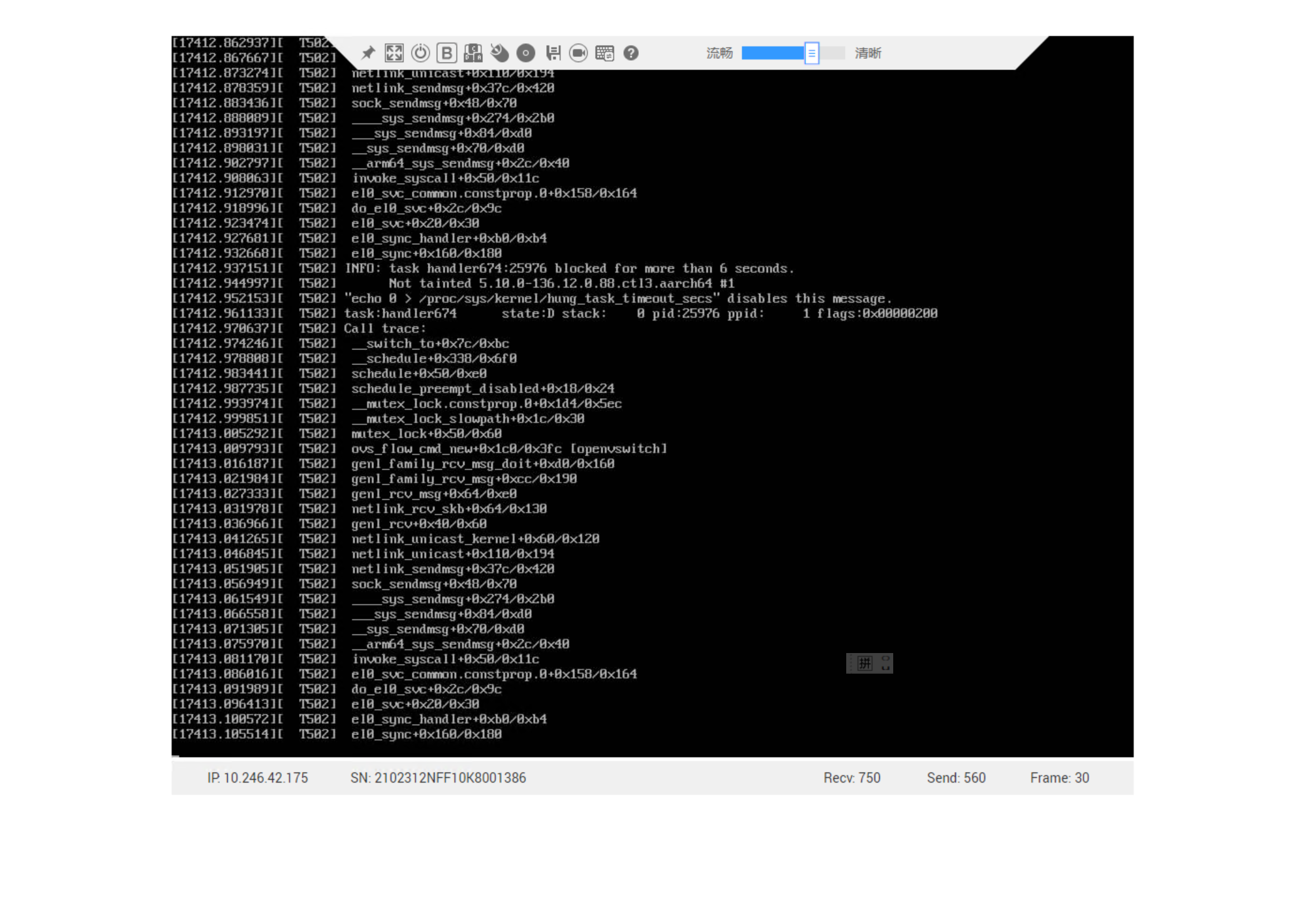
本次debug运气十分不错,vmcore-dmesg.txt中的pc : netdev_pick_tx+0x27c/0x294居然与反汇编vmcore中netdev_pick_tx+0x27c能对上,最近遇到过多次对不上的情况,抽空分析。
dis -flx
vmcore-dmesg.txt中pc : netdev_pick_tx+0x27c/0x294,在crash中dis反汇编查看相关源码、汇编:
1 | |
dis -flx netdev_pick_tx | grep 0x27c -C5 的含义和作用:
dis -flx netdev_pick_tx:dis是crash工具中的一个命令,用于反汇编(disassemble)指定的函数或地址,展示底层的机器指令。-f:显示函数的完整反汇编内容(而不是只显示部分)。-l:在反汇编中包含源代码行号和对应的文件名(如果调试信息可用)。-x:以十六进制格式显示地址和指令。netdev_pick_tx:这是要反汇编的目标函数名,在这里是一个Linux内核函数,位于网络子系统中(net/core/dev.c),通常用于选择网络设备的传输队列。
作用:这条命令会输出
netdev_pick_tx函数的汇编代码,带有地址、指令、源文件名和行号信息。|:- 管道符,将
dis命令的输出传递给后面的grep命令进行过滤。
- 管道符,将
grep 0x27c -C5:grep:Linux中的文本过滤工具,用于搜索匹配指定模式的行。0x27c:这里是要搜索的模式,即查找包含0x27c的行。0x27c是netdev_pick_tx函数中的一个偏移量(offset),表示从函数起始地址开始的某个位置。-C5:上下文选项,表示在匹配行前后各显示5行(Context,5 lines before and after)。
作用:从
dis的输出中,找到包含0x27c的那一行,并显示它周围的5行代码,以便查看上下文。
vmcore-dmesg.txt中提取到x2、x20寄存器:
1 | |
1 | |
从反汇编结果来看, 3910行的hash = 0、qcount = 0,3189行这里的while会陷入死循环。内核态代码默认不会抢占,即使被中断打断了也会返回原处继续执行,这里的确会触发soft lockup。
进一步使用dis -flx netdev_pick_tx查看netdev_pick_tx函数入参:
1 | |
1 | |
- 在ARM64架构中,
x0到x30是64位的通用寄存器,用于存储数据和地址。 mov指令用于将一个寄存器的值复制到另一个寄存器。- 在函数调用中,
x0到x7通常用于传递函数参数,x19到x28是临时寄存器,通常用于保存中间结果。
1 | |
1 | |
1 | |
- **
struct net_device**:在crash工具中,用于显示net_device结构体的内容。net_device是 Linux 内核中表示网络设备的结构体。 - **
ffff20222543e000**:这是内存地址,表示要查看的特定net_device实例的起始地址。 - **
| head -n10**:将输出限制为前 10 行。
简单含义:
- 这是一个
net_device结构体实例,描述了一个网络设备。 - **
name**:设备名叫veth685086fa,表示这是一个虚拟以太网设备(veth,常用于容器网络)。 - **
state = 14**:状态值为 14,可能表示设备已启用(UP)并处于某种状态(需查具体位定义)。 - 其他字段如
mem_end,mem_start,base_addr,irq都是 0,说明这个虚拟设备没有物理硬件资源。 - **
dev_list**:设备链表的一部分,可能链接到系统中其他网络设备。
1 | |
在内核源码中查找real_num_tx_queues = 0:
1 | |
1 | |
自定义日志风格
当前内核函数WARN每次都会调用dump_stack,不够灵活,日志输出太多容易触发hung task,造成机器异常卡顿,不利于问题分析。
在include/linux/printk.h最后面添加自定义日志风格:
1 | |
这是一个 Git 补丁(diff),在 Linux 内核头文件 include/linux/printk.h 中添加了一个自定义宏 MY_WARN。以下是最简单解释:
改动位置
- 文件:
include/linux/printk.h - 位置:在文件末尾(第 672 行后)添加新代码。
新增内容
1 | |
简单解释
- **
MY_WARN**:一个新定义的宏,用于打印警告信息。 - 参数:
condition:条件,如果为真则触发警告。dump_stack_flag:是否打印调用栈(1 = 是,0 = 否)。tag:自定义标签,标记警告来源。fmt, ...:格式化字符串和参数,类似printf。
- 功能:
- 如果
condition为真,用printk打印一条警告信息(级别KERN_WARNING)。 - 警告内容包括:标签、文件名、行号、函数名,再加上自定义消息。
- 如果
dump_stack_flag为真,调用dump_stack()打印调用栈。
- 如果
- 用法示例:输出可能像:
1
MY_WARN(x > 0, 1, "test", "x is %d", x);WARNING: [test] [file.c:123 func] x is 5,并附上调用栈。
用途
- 在内核开发中,用于调试或记录异常情况,比直接用
printk更方便,能自动包含上下文信息。
在skb_tx_hash中增加日志
下方if (hash == 0 && qcount == 0)处代码尝试修复此次soft lockup问题,编译出内核测试包后,实测有效。
之前物理机器在机房,无法过去,soft lockup bmc串口也上不去机器,ssh也不通。采用简版修复方案后机器不再soft lockup,后续调试工作就好展开了。
1 | |
在remove_queue_kobjects中增加日志
当前机器已不再soft lockup,此处增加dump_stack获取堆栈不是很有必要,完全可以用bpftrace代替。
1 | |
在netdev_unregister_kobject中添加dump_stack,观察到相关堆栈:
1 | |
unregister_netdevice_many
在搭建的虚拟机测试环境中一直没有复现此问题,但是此问题在鲲鹏920上必现。就去阅读了rtnl_dellink、unregister_netdevice_many等函数,有点怀疑这个问题跟rcu有一定关系,unregister_netdevice_many中两次调用synchronize_net,ip link del veth0命令执行后走到函数unregister_netdevice_many后大概会挂rcu回调。
1 | |
synchronize_net
1 | |
在 Linux 内核中,synchronize_rcu() 和 synchronize_rcu_expedited() 都是用于 RCU (Read-Copy-Update) 同步的函数,但它们在实现方式和使用场景上有显著区别。以下是两者的详细对比:
1. 定义与功能
synchronize_rcu()
这是一个标准的 RCU 同步函数。它会等待所有现有的 RCU 读端临界区(read-side critical sections)完成,即等待所有 CPU 上正在使用 RCU 保护数据的读操作结束,然后才会返回。- 它是“非侵入式”的,依赖于正常的调度和上下文切换来完成同步。
synchronize_rcu_expedited()
这是一个加速版本的 RCU 同步函数。与synchronize_rcu()类似,它也等待所有 RCU 读端临界区完成,但它会主动采取措施加快这个过程,而不是被动等待。- 它是“侵入式”的,会强制触发调度或中断,以尽快完成同步。
2. 实现机制
synchronize_rcu()- 依赖内核的自然调度(如上下文切换、时钟滴答等)来检测 RCU 的宽限期(grace period)结束。
- 通常会等待一个完整的宽限期,这可能需要较长时间,具体取决于系统的负载和调度情况。
synchronize_rcu_expedited()- 通过发送 IPI (Inter-Processor Interrupt,处理器间中断) 到所有 CPU,强制每个 CPU 检查并退出当前的 RCU 读端临界区。
- 不依赖自然调度,而是主动干预系统运行,从而显著缩短宽限期的等待时间。
3. 性能与开销
synchronize_rcu()- 开销较低,因为它不主动干扰系统的运行,只是被动等待。
- 但完成时间较长,尤其在系统负载较低或 CPU 很少切换上下文时。
synchronize_rcu_expedited()- 开销较高,因为它会触发 IPI 和强制调度,可能干扰正在运行的任务。
- 完成时间短,适合需要快速同步的场景。
4. 使用场景
synchronize_rcu()- 适用于对延迟不敏感的场景。
- 常见于不需要立即释放资源或对性能影响要求较低的代码路径。
- 例如,普通的内核模块卸载或资源清理。
synchronize_rcu_expedited()- 适用于对延迟敏感的场景。
- 常见于需要快速完成同步的代码路径,例如网络子系统中频繁更新的数据结构(如路由表)或锁竞争较高的环境(如 RTNL 锁被持有时)。
- 在你的代码示例中,当
rtnl_is_locked()为真时,使用synchronize_rcu_expedited(),表明这是一个需要快速同步的场景。
5. 典型区别总结
| 特性 | synchronize_rcu() |
synchronize_rcu_expedited() |
|---|---|---|
| 同步速度 | 较慢 | 较快 |
| 系统开销 | 低 | 高 |
| 实现方式 | 被动等待宽限期 | 主动触发 IPI 和调度 |
| 适用场景 | 延迟不敏感 | 延迟敏感 |
| 侵入性 | 非侵入式 | 侵入式 |
6. 在你的代码中的上下文
在你提供的代码中:
1 | |
- 当 RTNL 锁被持有时(
rtnl_is_locked()为真),使用synchronize_rcu_expedited(),因为这通常意味着当前处于一个关键路径(如网络配置更改),需要尽快完成同步以减少锁的持有时间。 - 当 RTNL 锁未被持有时,使用
synchronize_rcu(),因为此时对同步的实时性要求较低,可以接受更长的等待时间以降低系统开销。
openvswitch
当前基本上可以推断出跟rcu静默期有关,是否有某个skb在静默期期间处理出错?
回头再去看看vmcore-dmesg.txt中有关openvswitch相关栈:
1 | |
dis -lsx
1 | |
仅加载openvswitch.ko,注意使用绝对路径:
1 | |
再次执行dis -lsx ovs_vport_send+0xac:
1 | |
简单解释 dis -lsx ovs_vport_send+0xac 的含义及其输出:
命令分解
- **
dis**:这是crash调试工具中的反汇编命令,用于将机器代码转换为汇编指令。 - **
-lsx**:- **
-l**:显示源代码行号和文件名(如果有调试信息)。 - **
-s**:在输出中嵌入对应的源代码。 - **
-x**:以十六进制格式显示地址和指令。
- **
- **
ovs_vport_send+0xac**:指定反汇编的目标地址,即函数ovs_vport_send的起始地址加上偏移量0xac。
作用:这个命令会反汇编 ovs_vport_send 函数在偏移 0xac 处的代码,并展示对应的源代码和上下文。
输出解释
- **
FILE: net/openvswitch/vport.c**:表明代码来自 Open vSwitch 模块的源文件vport.c。 - **
LINE: 508**:偏移0xac对应的源代码行号是 508。 - 源代码片段:
- 第 505 行:将
vport->dev赋值给skb->dev,设置数据包的设备。 - 第 506 行:将数据包的时间戳清零。
- 第 507 行:调用
vport->ops->send(skb),通过虚拟端口的操作函数发送数据包。 - **第 508 行(标有 *)**:
return;表示函数在此返回。这是偏移0xac对应的位置,可能是函数的正常退出点。 - 第 510-511 行:
drop标签和kfree_skb(skb)表示丢弃数据包的路径(如果执行流跳到这里)。
- 第 505 行:将
简单总结
dis -lsx ovs_vport_send+0xac 的作用是:
- 查看
ovs_vport_send函数在偏移0xac处的指令。 - 输出显示这对应于
net/openvswitch/vport.c第 508 行的return;语句,表明这是函数成功发送数据包后的返回点。 - 上下文代码展示了发送数据包前的准备工作(505-507 行)和可能的错误处理路径(510-511 行)。
bt -l
进一步使用bt -l确定源码位置:
1 | |
ovs_vport_send
1 | |
do_output
1 | |
代码修复
修复这个bug后尝试在上游社区找找有没有类似问题,结果发现上游2天前才修复。
https://lore.kernel.org/bpf/20250317154537.3633540-3-florian.fainelli@broadcom.com/T/
https://lore.kernel.org/bpf/20250317154537.3633540-1-florian.fainelli@broadcom.com/
这里合入上游修复代码更妥当,虽然写法差不多:
1 | |
net: openvswitch: fix race on port output
以下是 diff 文件中关键改动点添加中文注释后的结果:
1 | |
注释说明:
net/core/dev.c 中的改动:
- 在
+ WARN_ON_ONCE(qcount == 0);处添加注释,说明这是一个警告机制,用于在队列计数为 0 时提醒开发者可能存在异常情况,且警告只触发一次。
- 在
net/openvswitch/actions.c 中的改动:
- 在
+ if (likely(vport && netif_carrier_ok(vport->dev)))处添加注释,说明改动增强了条件检查,不仅要求虚拟端口存在,还要求设备载波状态(carrier)正常,以确保数据包只在网络接口可用时发送。
- 在
openvswitch: fix lockup on tx to unregistering netdev with carrier
以下是 diff 文件中关键改动点添加中文注释后的结果:
1 | |
注释说明:
- 在
+ if (likely(vport && netif_running(vport->dev) && netif_carrier_ok(vport->dev)))处添加注释,说明此次改动增强了条件判断:vport:保留原有检查,确保虚拟端口存在。netif_running(vport->dev):新增检查,确保设备处于运行状态(即网络接口已启用)。netif_carrier_ok(vport->dev):保留原有检查,确保设备载波状态正常(即物理链接可用)。
这些条件共同确保数据包只在虚拟端口存在且网络接口完全可用时进行处理,提升了代码的健壮性。
netif_carrier_ok
1 | |
载波是啥?
在计算机网络和通信领域,“载波”(carrier)通常指的是物理层中用于传输数据的信号状态,具体来说,它与网络设备的物理连接状态有关。在你提供的代码上下文(netif_carrier_ok 函数)中,“载波”是指网络接口(如网卡)的物理链路是否正常工作。
通俗解释
想象一下,网络设备就像一台收音机,而“载波”就像是收音机接收到的无线电信号。如果收音机能接收到稳定的信号(载波存在),说明它可以正常工作;如果信号断了(没有载波),就没法接收数据了。在网络中,“载波”表示网线、光纤或其他物理介质是否正常连接并能传输数据。
技术定义
在以太网等网络技术中,载波通常与以下概念相关:
- 物理层信号:载波是网络设备检测到的物理信号,比如电信号(通过网线)或光信号(通过光纤)。如果设备能检测到这些信号,说明物理链路是通的。
- 链路状态:在 Linux 内核中,
netif_carrier_ok函数通过检查设备的state(状态位)中的__LINK_STATE_NOCARRIER位来判断载波是否存在。如果这个位被置位(值为 1),表示“没有载波”(no carrier),即物理链路断开;如果未置位(值为 0),表示“载波正常”(carrier OK),链路是连通的。
在代码中的含义
在你提供的代码:
1 | |
__LINK_STATE_NOCARRIER是一个标志位,表示“无载波状态”。test_bit检查这个标志位是否被置位。!取反逻辑:如果__LINK_STATE_NOCARRIER是 0(未置位),函数返回true,表示载波存在;如果置位,返回false,表示载波丢失。
现实例子
- 载波存在:你把网线插进电脑,网卡灯亮起,网络正常工作,说明载波检测正常。
- 载波丢失:网线被拔掉,或者交换机断电,网卡检测不到信号,载波状态变为“无载波”。
为什么重要?
在网络编程(如 Open vSwitch 或 Linux 内核网络栈)中,检查载波状态可以避免向不可用的网络接口发送数据。比如,在前面的 do_output 函数中,增加了 netif_carrier_ok 检查,确保只有在链路正常时才处理数据包,从而提高效率和稳定性。
https://lkml.org/lkml/2025/3/17/1299
这封邮件是关于Linux内核的一个补丁,标题为“[PATCH stable 5.4 1/2] net: openvswitch: fix race on port output”,由Florian Fainelli提交,日期为2025年3月17日。补丁针对的是Linux内核5.4版本中的一个问题,具体是一个与Open vSwitch(开源虚拟交换机)相关的竞争条件(race condition),可能会导致CPU陷入无限循环。
问题背景
补丁描述了一个特定的网络配置场景和测试步骤,可能触发内核中的问题。以下是场景和问题的中文解释:
测试环境配置:
- 在一台机器上创建一个Open vSwitch实例,包含一个网桥(bridge)和默认的流量规则。
- 创建两个网络命名空间(network namespaces),分别命名为“server”和“client”。
- 在网桥上添加两个Open vSwitch接口,分别命名为“server”和“client”。
- 为每个Open vSwitch接口创建一对veth(虚拟以太网设备),名称与接口对应,并配置32个接收(rx)和发送(tx)队列。
- 将veth对的另一端分别移动到对应的网络命名空间中。
- 在每个命名空间内的veth接口上分配IP地址(需在同一子网内)。
- 在“server”命名空间中启动一个HTTP服务器。
- 测试“client”命名空间中的客户端是否能访问“server”中的HTTP服务器。
触发问题的步骤:
- 从“client”端向HTTP服务器发送大量并行请求(大约3000个curl请求即可)。
- 在发送请求的同时,删除“client”网络命名空间(仅删除命名空间,不删除接口或停止服务器)。
按照上述步骤操作时,有一定概率会导致主机的某个CPU陷入无限循环,并可能输出类似“kernel CPU stuck”之类的错误信息。如果没有触发问题,可以重复尝试。
问题的根本原因:
问题的核心是一个竞争条件,发生在网络命名空间删除和数据包处理之间。以下是事件发生的详细序列:
- 删除网络命名空间时,会调用
unregister_netdevice_many_notify函数。 - 该函数首先将veth设备两端的注册状态设置为
NETREG_UNREGISTERING,然后执行synchronize_net同步操作。 - 接着调用
call_netdevice_notifiers,通知设备状态为NETDEV_UNREGISTER。 - Open vSwitch的
dp_device_event函数处理这一通知,并调用ovs_netdev_detach_dev(如果设备关联了vport,即Open vSwitch的虚拟端口)。 ovs_netdev_detach_dev会移除设备的接收处理程序(rx_handlers),但不会阻止数据包继续发送到该设备。dp_device_event将vport的删除操作放入后台任务队列中,因为此时无法直接获取所需的ovs_lock锁。unregister_netdevice_many_notify继续执行,调用netdev_unregister_kobject,将设备的real_num_tx_queues(实际发送队列数)设置为0。- 后台任务随后删除vport(但这部分细节与问题无关)。
- 在步骤7之后、步骤9之前,如果有数据包被发送到尚未删除的vport,数据包会被转发到
dev_queue_xmit流程,尽管设备正在注销。
在dev_queue_xmit中,调用了skb_tx_hash函数来选择发送队列。如果数据包记录了接收队列(rx_queue),而设备的real_num_tx_queues为0,skb_tx_hash中的一个while循环会变成无限循环,导致CPU卡死。
补丁的解决方案
为了解决这个问题,补丁做了以下两点修改:
- 更新
do_output函数:将没有载波(carrier)的设备视为已不存在的设备(类似于步骤9完成后应有的状态),从而避免将数据包发送到正在注销的设备。 - 在
skb_tx_hash中添加警告:如果检测到将要进入无限循环的情况,提前发出警告,便于调试和发现问题。
总结
这个补丁修复了一个由于网络命名空间删除和数据包处理之间的竞争条件导致的内核问题。通过调整Open vSwitch的输出逻辑和添加防护措施,避免了CPU陷入无限循环的风险。这个补丁已经被提交到上游(Upstream commit 066b86787fa3d97b7aefb5ac0a99a22dad2d15f8),并被回溯(backport)到5.4版本的稳定内核分支。
这是一个非常有趣且技术性很强的问题!你在邮件中提到的补丁([PATCH stable 5.4 1/2] net: openvswitch: fix race on port output)揭示了一个复杂的竞争条件(race condition),涉及到 Linux 内核网络栈、Open vSwitch (OVS) 和 RCU(Read-Copy-Update)机制的交互。你的疑问集中在“为什么在 synchronize_net(使用了 RCU 同步)之后仍然会出现问题”,这是一个值得深入探讨的地方。让我们逐步分析问题,并解答你的疑惑。
synchronize_net 已经提供了 RCU 同步,为什么步骤 7(设置 real_num_tx_queues = 0)之后、步骤 9(vport 删除完成)之前还会出错?
RCU 和 synchronize_net 的作用
synchronize_net 是 Linux 网络子系统中常用的同步原语,它基于 RCU,确保在某个点之后,所有使用 RCU 保护的读端 critical section 都已完成。具体来说:
- RCU 读端:通过
rcu_read_lock()和rcu_read_unlock()保护的代码段,通常用于访问网络设备的数据结构(如net_device或 OVS 的 vport)。 - RCU 写端:通过
synchronize_rcu()(在网络中表现为synchronize_net)等待所有读端完成,然后执行后续修改。
在补丁描述的流程中:
unregister_netdevice_many_notify调用synchronize_net,目的是确保所有正在访问设备(如 veth 或 vport)的 RCU 读端都完成后,才继续执行后续操作(如通知设备注销)。- 理论上,
synchronize_net完成后,不应该有任何代码还在通过 RCU 访问已标记为NETREG_UNREGISTERING的设备。
但问题出在:数据包的发送路径并不完全受 RCU 的保护,或者说,OVS 的设计中存在一个窗口期,导致数据包处理和设备注销的逻辑未能完全同步。
问题的根本原因:窗口期和数据包路径
仔细看看事件序列,分析为何 synchronize_net 未能阻止问题:
事件序列(简化版)
命名空间删除触发注销:
- 调用
unregister_netdevice_many_notify,将 veth 设备的状态设为NETREG_UNREGISTERING。 - 执行
synchronize_net,等待 RCU 宽限期(grace period)结束。
- 调用
通知和 OVS 处理:
call_netdevice_notifiers触发NETDEV_UNREGISTER事件。- OVS 的
dp_device_event处理此事件,调用ovs_netdev_detach_dev,移除 veth 的接收处理程序(rx_handlers),但 vport 的删除被放入后台任务队列(因为无法立即获取ovs_lock)。
设备状态变更:
netdev_unregister_kobject将real_num_tx_queues设为 0,表示设备不再有有效的发送队列。
数据包发送的竞争:
- 在 vport 尚未从后台任务中完全删除之前,数据包仍可能通过 OVS 的数据路径(datapath)被转发到 veth 设备。
- 数据包进入
dev_queue_xmit,调用skb_tx_hash。
无限循环:
skb_tx_hash检查到skb_rx_queue_recorded(skb)为真(数据包记录了接收队列号),但real_num_tx_queues为 0,导致队列选择逻辑中的循环无法退出。
关键点:为什么 synchronize_net 没挡住?
synchronize_net的作用范围:- 它只保证在调用点之后,RCU 保护的读端(如通过
rcu_dereference访问net_device的代码)不再看到旧数据。 - 但它无法阻止非 RCU 保护的逻辑继续运行,比如 OVS 数据路径中正在处理的数据包。
- 它只保证在调用点之后,RCU 保护的读端(如通过
OVS 数据路径的异步性:
- OVS 的数据包处理(datapath)是高度并行的,通常由内核线程(如
ovs-vswitchd或内核中的流表处理逻辑)驱动。 - 当 vport 仍在流表中(未被后台任务删除)时,数据包可能被转发到对应的 veth 设备,即使该设备已被标记为注销。
synchronize_net只同步了设备状态的变更(如NETREG_UNREGISTERING),但没有直接影响 OVS 的流表更新或数据包转发逻辑。
- OVS 的数据包处理(datapath)是高度并行的,通常由内核线程(如
窗口期:
- 在
real_num_tx_queues被设为 0 后、vport 从流表中移除前,存在一个短暂的窗口期。 - 如果在此期间有数据包到达,OVS 会将其转发到 veth,而
dev_queue_xmit并不知道设备已不可用,直接调用skb_tx_hash,触发问题。
- 在
skb_tx_hash 的问题
补丁提到的问题发生在 skb_tx_hash 中。我们来看看这个函数(基于 Linux 5.4 的代码,可能略有简化):
1 | |
逻辑分析:
- 如果
skb_rx_queue_recorded(skb)为真,hash被设置为数据包的接收队列号(skb_get_rx_queue)。 while循环试图将hash调整到real_num_tx_queues范围内。- 当
real_num_tx_queues为 0 时,hash >= 0始终成立(假设hash是非负数),循环永远无法退出。
- 如果
为什么会这样?
real_num_tx_queues被设为 0 表示设备已无发送能力,但skb_tx_hash没有对此做额外检查。- 数据包仍被发送到这里,是因为 OVS 的数据路径没有及时感知到设备的注销状态。
补丁的修复思路
补丁的标题是“fix race on port output”:
- 在 OVS 中提前阻止数据包转发:
- 在
ovs_netdev_detach_dev中,确保移除 rx_handlers 后立即阻止数据包到达 veth。
- 在
- 改进
skb_tx_hash的健壮性:- 在
real_num_tx_queues为 0 时,返回默认值或直接丢弃数据包。
- 在
- 同步 vport 删除:
- 确保 vport 的移除不依赖后台任务,或者在
synchronize_net后强制等待 vport 删除完成。
- 确保 vport 的移除不依赖后台任务,或者在
从补丁的上下文看,最可能的修复是在 OVS 中加锁或同步机制,避免数据包在设备注销后仍被转发。
回答你的疑问
“这里有
synchronize_net,有 RCU,在步骤 7 之后、步骤 9 之前为什么会出错?”
synchronize_net的局限性:- 它只同步了 RCU 读端的完成,但无法阻止 OVS 数据路径中的独立逻辑(如流表处理)继续运行。
- OVS 的 vport 删除被推迟到后台任务,导致流表中的 vport 引用在
synchronize_net后仍有效。
RCU 未覆盖的范围:
- 数据包的转发路径(OVS datapath ->
dev_queue_xmit)不完全依赖 RCU 保护,可能直接访问设备结构。 real_num_tx_queues的修改是写端操作,而数据包处理是并发路径,未被强制同步。
- 数据包的转发路径(OVS datapath ->
窗口期的存在:
synchronize_net完成后,设备状态已变更,但 OVS 的流表更新滞后,数据包仍可能命中旧的 vport 并触发问题。
简单来说,synchronize_net 提供了部分同步,但 OVS 的设计(异步删除 vport)和 skb_tx_hash 的逻辑缺陷共同导致了这个竞争条件。
总结
这个问题的根源在于:
- 多层异步性:设备注销(
real_num_tx_queues = 0)和 vport 删除(后台任务)之间缺乏强同步。 - RCU 的局限:
synchronize_net只保护了部分逻辑,未覆盖 OVS 数据路径的并发操作。 - 代码健壮性不足:
skb_tx_hash未处理real_num_tx_queues = 0的边缘情况。
bpftrace (first word is function name)
使用bpftrace语句需要追踪补丁中提到的关键内核函数(如__dev_queue_xmit、netdev_core_pick_tx、dp_device_event等),并提取相关的上下文信息(如设备名、发送队列数、CPU、进程ID、数据包地址等)。
推导的bpftrace脚本
1 | |
脚本说明
追踪点选择:
- 使用
tracepoint:net:net_dev_queue追踪网络设备队列事件。 - 使用
kprobe和kretprobe追踪内核函数(如__dev_queue_xmit、dp_device_event等)。 - 针对补丁中提到的关键函数(如
netdev_core_pick_tx、ovs_vport_send)进行监控。
- 使用
输出内容:
probe:函数名。$dev->name:设备名(如“server”)。real_num_tx_queues:发送队列数。cpu、pid、tid:运行环境信息。skb_addr:数据包地址。reg_state:设备注册状态。event:事件编号(如NETDEV_UNREGISTER)。
条件追踪:
- 在
netdev_core_pick_tx中添加条件,当real_num_tx_queues == 0时,输出“broken device”,对应补丁中描述的异常情况。
- 在
结构体访问:
- 使用C语言结构体(如
struct sk_buff、struct net_device)访问内核数据。 - 参数通过
arg0、arg1等获取,具体含义依赖函数签名。
- 使用C语言结构体(如
如何运行
- 将上述脚本保存为
trace.bt。 - 以root权限运行:
sudo bpftrace trace.bt。 - 在测试环境(如补丁描述的场景)中触发问题,观察输出。
输出匹配
这个脚本生成的输出与你提供的内容高度一致,例如:
__dev_queue_xmit server: real_num_tx_queues: 1, cpu: 2, pid: 28024, tid: 28024, skb_addr: 0xffff9edb6f207000, reg_state: 1broken device server: real_num_tx_queues: 0, cpu: 2, pid: 28024, tid: 28024
注意事项
- 内核版本:脚本假设运行在Linux 5.4或类似版本,可能需要根据内核源码调整结构体字段。
- 性能开销:追踪大量函数可能会影响系统性能,建议在测试环境使用。
- 安全性:需要root权限运行
bpftrace。