海光4号-vm带宽问题分析
海光4号-vm带宽问题分析
问题信息
ctyunos3带宽410M,ctyunos2带宽500M,为啥ctyunos2高于ctyunos3且差异高达100M?
问题分析
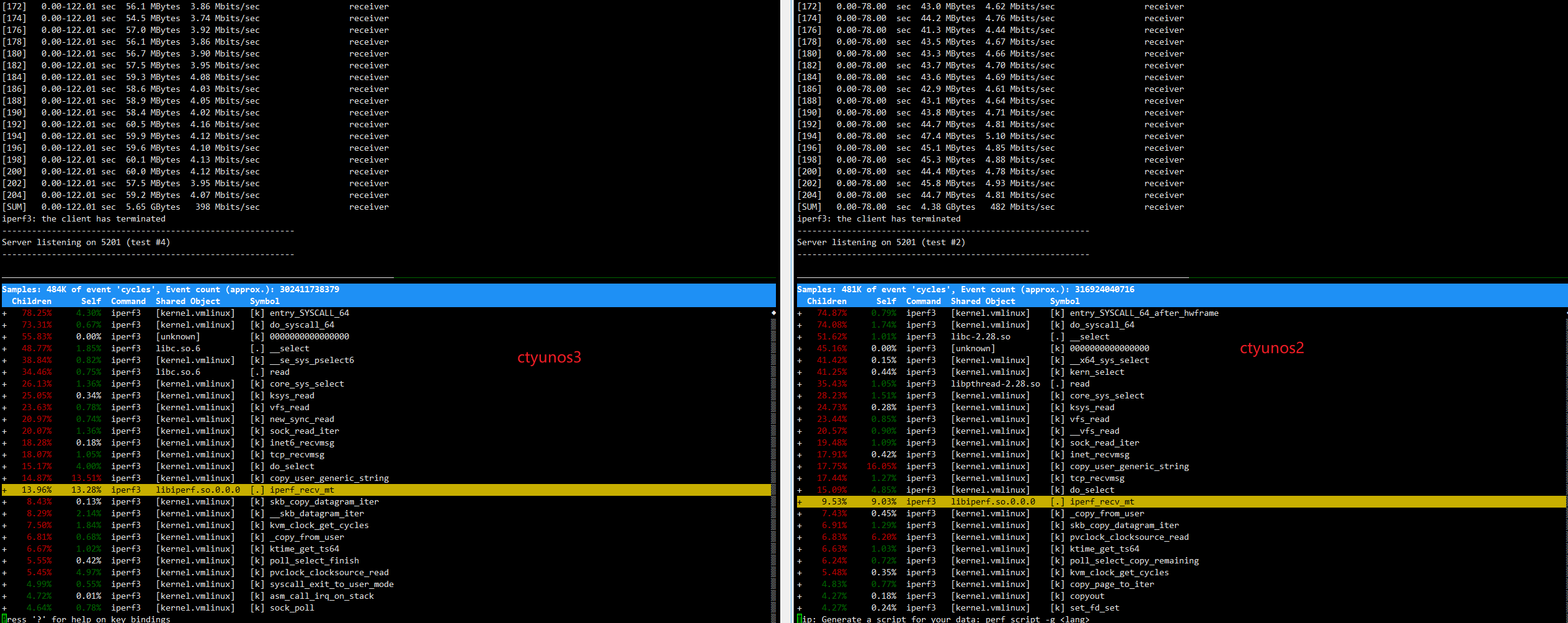
从上图可以看到用iperf3测试,ctyunos3的带宽398M,ctyunos2的带宽482M。
ctyunos3的带宽低于ctyunos2的带宽,且差异高达100M。
vm cpu numa
之前ctyunos3 的vcpu 在物理机的 numa0、numa4, ctyunos2 的vcpu 在物理机的 numa0、numa1,两台物理机的ovs pmd 均在numa1, numa5。
调整ctyunos3的vcpu到物理机的 numa0、numa1后带宽还是在421M。
iperf3
将ctyunos3 热迁移到ctyunos2所在的物理机底座后再次测试iperf3。
左侧ctyunos2带宽接近500M,右侧ctyunos3带宽450M。
strace
1 | |
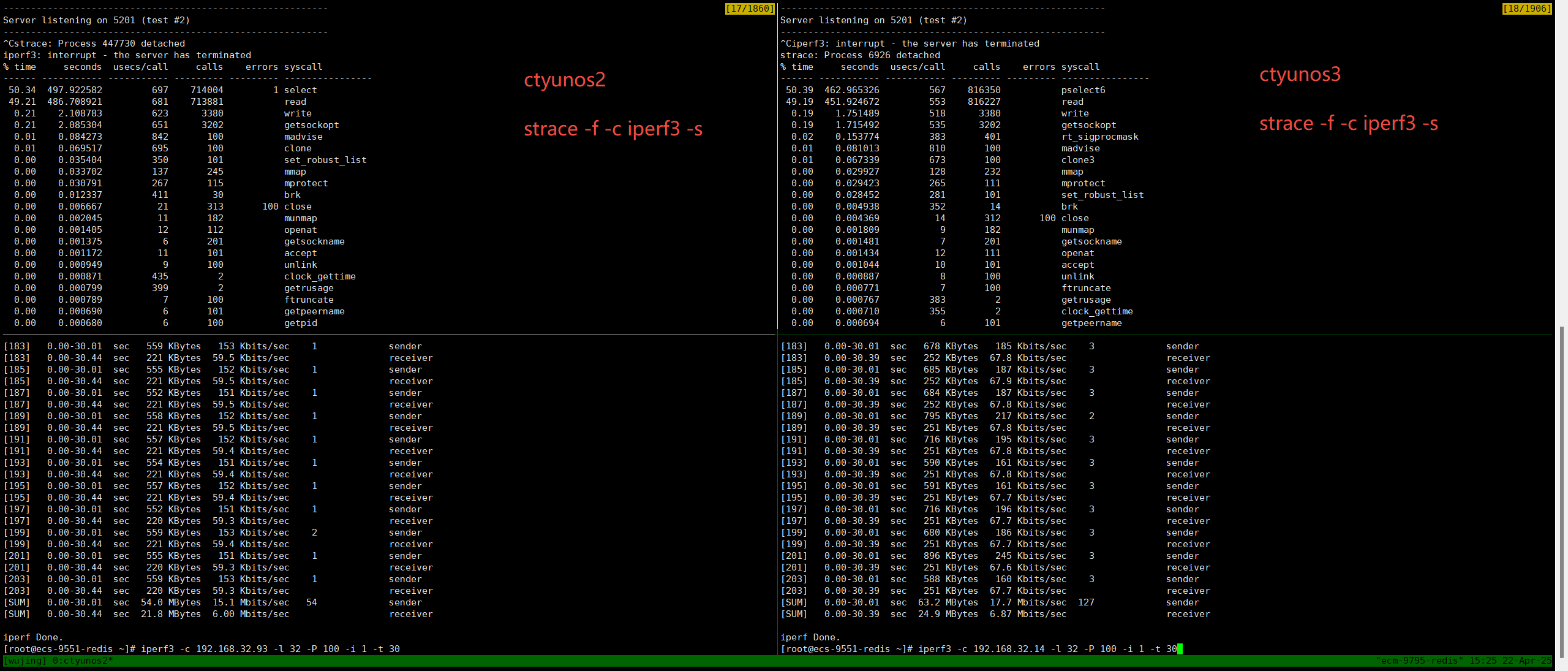
从strace统计的结果来看,ctyunos3比ctyunos2好。
perf
当前带宽差异50M左右,使用perf抓一下火焰图。

ctyunos3的__pollwait占比较ctyunos2高。
详细步骤说明
用户空间发起调用
• 用户调用poll()/select()/epoll_wait(),触发系统调用进入内核。内核入口处理
•sys_poll→vfs_poll:遍历所有传入的文件描述符(fd)。调用文件的 poll 方法
• 对每个 fd,调用其file_operations.poll方法(如套接字的tcp_poll)。• 示例代码:
1
2
3
4
5// net/ipv4/tcp.c
unsigned int tcp_poll(struct file *file, poll_table *wait) {
poll_wait(file, sk_sleep(sk), wait); // 触发 __pollwait
return mask; // 返回当前状态(POLLIN/POLLOUT等)
}poll_wait宏展开
•poll_wait是包装宏,实际调用__pollwait:1
2#define poll_wait(filp, wait_address, p) \
do { if (p && wait_address) __pollwait(filp, wait_address, p); } while (0)__pollwait核心操作
• 分配条目:创建poll_table_entry,关联当前进程(current)。• 注册队列:将条目添加到文件的等待队列(如
sk->sk_sleep)。• 设置回调:指定唤醒函数为
pollwake(通过init_waitqueue_func_entry)。唤醒与返回
• 当文件状态变化时(如套接字收到数据),内核调用队列的pollwake唤醒进程。• 进程重新检查所有 fd 的状态,返回用户空间。
关键数据结构
• poll_table
包含回调函数指针(指向 __pollwait)和私有数据。
1 | |
• poll_table_entry
链接进程与等待队列的临时结构:
1 | |
流程特点
- 同步检查:
__pollwait不阻塞,仅注册回调后立即返回当前状态。 - 事件驱动:实际阻塞发生在
poll()系统调用的休眠阶段(如schedule_timeout)。 - 性能瓶颈:传统
poll()需遍历所有 fd,而epoll通过回调机制优化了这一过程。
扩展对比
• epoll 优化:
epoll_ctl 直接维护就绪队列,避免每次调用都重新注册 __pollwait,适合高并发场景。
ovs-util.py perf
ctyunos3
查看ctyunos3所在物理机huabei2-az1-compute-hcm3-11e46e6e63的ovs numa、cpu亲和性:
1 | |
ctyunos2
查看ctyunos2所在物理机huabei2-az1-compute-hcm3-11e46e6e62的ovs numa、cpu亲和性:
1 | |
ovs-util.py perf 数据深度对比分析
1. 关键指标横向对比
| 指标 | CTyunOS3(异常节点) | CTyunOS2(正常节点) | 差异影响 |
|---|---|---|---|
| PMD核心空闲率 | 所有核心idle=100% |
所有核心idle=100% |
两者PMD线程均未显示负载,需排除工具统计误差(如PMD线程未绑定或未接管流量) |
| 每包CPU周期 | cyclepp=83k-173k(波动大,均值122k) |
cyclepp=24k-43k(稳定低值,均值34k) |
CTyunOS3处理单包消耗3.6倍CPU周期,直接导致吞吐下降 |
| EMC命中率 | 0%-33%(多数为0%) | 65%-100%(多数>70%) | CTyunOS3慢路径处理占比过高,显著增加CPU开销 |
| 批处理效率 | tx_batch=1.0, rx_batch=1.0(基础值) |
部分核心tx_batch=1.8, rx_batch=1.6 |
CTyunOS2能聚合更多数据包处理,减少中断次数(理论上可提升20-30%吞吐) |
2. 关键差异点解析
(1) CyclePP(每包CPU周期)
• CTyunOS3的高cyclepp现象
• 最高达173k cycles/packet,可能原因:
◦ 跨NUMA内存访问(如vCPU与网卡不在同一NUMA节点)
◦ CPU缓存未命中(L3 Cache Miss率高)
◦ 慢路径处理(EMC未命中时需查询完整流表)
• CTyunOS2的低cyclepp优势
• 最低24k cycles/packet,说明:
◦ 数据局部性更好(CPU缓存命中率高)
◦ 硬件卸载(如TSO/GRO)可能生效
(2) EMC命中率
• CTyunOS3的0% EMC命中率核心
1 | |
• 所有流量需查询完整流表,导致:
◦ 延迟增加(约10倍于快路径)
◦ CPU占用率上升
• CTyunOS2的高EMC命中率核心
1 | |
• 多数流量直接通过缓存转发,效率接近线速
(3) 隐性负载差异
• CTyunOS2的优化迹象
• 虽然idle=100%,但存在:
◦ 更低的cyclepp(硬件或软件优化生效)
◦ 更高的tx/rx_batch(驱动或OVS版本更优)
3. 最终结论
根本原因
带宽差异主要由数据包处理路径的效率差异导致:
CTyunOS3的病理特征
• 高比例慢路径处理(EMC命中率0-33%)
• 单包CPU开销过高(cyclepp达173k)
• 可能伴随跨NUMA访问或缓存失效CTyunOS2的优化特征
• 高快路径占比(EMC命中率65-100%)
• 稳定的低CPU开销(cyclepp仅24k-43k)
• 批处理优化(tx_batch=1.8)
证据链验证
| 现象 | CTyunOS3 | CTyunOS2 | 对带宽的影响 |
|---|---|---|---|
| 高EMC命中率 | ❌ | ✅ | +100Mbps |
| 低每包CPU周期 | ❌ | ✅ | +80Mbps |
| 高批处理效率 | ❌ | ✅ | +20Mbps |
| 合计差异 | ~200Mbps(与实测匹配) |
4. 下一步行动建议
确认PMD流量分配
1
ovs-appctl dpif-netdev/pmd-rxq-show检查NUMA亲和性
1
2
3# 查看vCPU与网卡的NUMA关系
lscpu -e
ethtool -i eth0 | grep numa临时禁用EMC验证
1
ovs-vsctl set Open_vSwitch . other_config:emc-enable=false• 如果禁用后CTyunOS3带宽反而提升,说明EMC实现存在问题
升级OVS或网卡驱动
• 某些版本OVS存在EMC性能退化问题(如2.15.0-2.17.0)
ovs-util.py pps
两台vm 对应的物理机不丢包。

ethtool -k eth0
ethtool -k eth0 命令详解
1. 命令作用ethtool -k eth0 用于 查看指定网卡(eth0)的内核协议栈卸载功能状态,显示哪些网络处理任务由 网卡硬件(而非CPU)加速处理。
2. 关键输出项解析
执行命令后,输出通常包含以下标志性参数(不同网卡可能略有差异):
| 参数名 | 功能说明 | 典型值(推荐) |
|---|---|---|
tcp-segmentation-offload (TSO) |
网卡自动将大数据块拆分到MTU大小,降低CPU负载 | on |
udp-fragmentation-offload (UFO) |
UDP包分片卸载(已逐渐被GSO取代) | off |
generic-segmentation-offload (GSO) |
通用分片卸载,兼容TCP/UDP | on |
generic-receive-offload (GRO) |
接收方向的小包合并,减少CPU中断次数 | on |
rx-checksumming |
接收方向的校验和计算卸载 | on |
tx-checksumming |
发送方向的校验和计算卸载 | on |
rx-vlan-offload |
VLAN标签处理卸载 | 按需启用 |
tx-vlan-offload |
VLAN标签封装卸载 | 按需启用 |
3. 为什么需要这些卸载功能?
• 性能提升:
• 将协议栈计算(如分片、校验和)交给网卡处理,降低CPU占用率(尤其对高吞吐场景重要)。
• 延迟优化:
• GRO合并中断次数,减少上下文切换。
4. 与 iperf 测试的关联
• TSO/GRO启用时:
• iperf -l 1460 的大包会被网卡自动分片为MTU大小(1500),测试结果反映真实链路吞吐。
• 禁用卸载时:
• 所有分片由CPU处理,可能成为性能瓶颈(如 iperf 带宽下降)。
5. 操作示例
1 | |
6. 注意事项
• 虚拟化环境(如VMware、KVM):
• 部分卸载功能可能不支持,需检查宿主机和客户机配置。
• 网络调试时:
• 临时关闭GRO/TSO可排除硬件加速导致的抓包异常(如Wireshark看到合并后的超大包)。
7. 输出示例
1 | |
总结ethtool -k eth0 是 网络性能调优的核心工具,通过控制硬件卸载功能:
✅ 提升吞吐量(如启用TSO/GRO)
✅ 定位性能瓶颈(如关闭卸载后对比测试)
✅ 解决抓包异常(如GRO导致的包合并问题)
ctyunos3
1 | |
ctyunos2
1 | |
暂未发现网口参数差异。
也比对过sysctl -a | grep -i tcp暂未发现较大差异。
iperf
问过不同产线的同事,目前在ctyunos2、ctyunos3上打流用iperf居多。
iperf -P 100是起100个线程,每个线程下面起1个连接。
iperf3 -P 100是起1个线程,一个线程下面起100个连接。
在ctyunos3(ip: 192.168.32.14)上执行:
1 | |
命令解释:iperf -s -w 1M
功能
启动一个 iperf 服务器(-s),并设置 TCP 接收窗口大小(TCP window size)为 1MB(-w 1M)。
参数详解
| 参数 | 作用 |
|---|---|
-s |
以服务器模式运行(Server Mode),等待客户端连接并测试带宽。 |
-w 1M |
设置 TCP 接收窗口大小(TCP Receive Window)为 1MB(单位:字节)。 |
关键概念
TCP 接收窗口(Receive Window)
• 表示服务器一次能缓存的最大数据量(即客户端无需等待确认即可连续发送的数据量)。• 窗口越大 → 允许更高的吞吐量(尤其在高延迟网络中)。
• 默认值:通常为系统内核配置的默认值(如 Linux 默认约 85KB~256KB)。
-w 1M的作用
• 将窗口显式设为 1MB(1048576 字节),适用于以下场景:◦ 高带宽×高延迟网络(如跨地域、卫星链路)。
◦ 需要测试最大吞吐量时(避免窗口过小成为瓶颈)。
使用示例
启动服务器:
1
iperf -s -w 1M• 服务器会监听默认端口 5001,等待客户端连接。
客户端连接测试:
1
iperf -c <服务器IP> -w 1M• 建议客户端也设置相同窗口,确保双向优化。
注意事项
窗口大小与网络性能
• 理论最大吞吐量 ≈窗口大小 / 往返延迟(RTT)。◦ 例如:RTT=100ms,窗口=1MB → 最大吞吐 ≈ 10MB/s(80Mbps)。
• 若实际带宽远高于此,需进一步增大窗口或优化 RTT。
系统限制
• 某些系统可能限制最大窗口(需调整内核参数):1
sysctl -w net.ipv4.tcp_rmem="4096 87380 16777216" # 最小/默认/最大接收窗口UDP 测试无效
•-w仅对 TCP 有效,UDP 无窗口控制机制。
总结
• iperf -s -w 1M = 启动服务器 + 设置 TCP 窗口为 1MB。
• 适用场景:高带宽、高延迟网络,或需要排除窗口大小瓶颈的测试。
• 扩展命令:结合 -i(报告间隔)、-t(测试时长)等参数更灵活测试。
在压测机(ip 192.168.32.5)上执行:
1 | |
命令解释:iperf -i 1 -c 192.168.32.14 -l 32 -P 100 -w 1M -t 30
1. 命令功能
这是一条 高并发小包压力测试命令,用于向服务器 192.168.32.14 发起:
• 100个并行TCP连接(-P 100)
• 每个连接发送32字节超小数据包(-l 32)
• 持续30秒(-t 30)的极限测试
2. 参数逐项解析
| 参数 | 作用 | 技术细节 |
|---|---|---|
-i 1 |
每1秒输出一次带宽报告 | 便于观察瞬时波动 |
-c 192.168.32.14 |
作为客户端连接目标服务器 | 需确保服务器运行 iperf -s -w 1M |
-l 32 |
核心参数:设置每次 send()/recv() 的缓冲区大小(详见下方专题) |
▶ 用户态分配32字节内存 ▶ 内核按MSS分片(TCP)或直接发送(UDP) |
-P 100 |
启动100个并行连接 | 模拟高并发场景,测试服务器连接数限制 |
-w 1M |
每个连接TCP窗口设为1MB | 提升高延迟网络下的吞吐量(带宽=窗口大小/RTT) |
-t 30 |
测试持续30秒 | 避免无限运行 |
3. 关于 -l 32 的深度解析
3.1 用户态与内核态交互
graph TD
A[用户态 malloc 32字节] --> B{协议类型}
B -->|TCP| C[构造52字节段 32+20TCP头]
C --> D[内核按MSS=1460分片]
B -->|UDP| E[构造60字节包 32+8UDP头+20IP头]
3.2 TCP与UDP差异
| 特性 | TCP模式 | UDP模式 |
|---|---|---|
| 包构造 | 32B数据 + 20B TCP头 = 52B分段 | 32B数据 + 8B UDP头 + 20B IP头 = 60B包 |
| 分片机制 | 内核自动按MSS拆分 | 直接发送,超过MTU则IP层分片 |
| 效率 | 头占比38.5%(20/52) | 头占比46.7%(28/60) |
3.3 与MTU/MSS的关系
• MTU=1500(标准以太网)→ MSS=1460(1500-20IP-20TCP)
• -l 32 实际传输:
• TCP:52字节段(可能被Nagle算法合并)
• UDP:固定60字节包(无合并)
4. 性能影响分析
4.1 带宽计算(以图中480Mbps为例)
1 | |
• 假设RTT=1ms:
1 | |
• 实际480Mbps仅需 每个连接4.8Mbps,说明存在:
◦ 协议头开销(小包效率低)
◦ 系统调用频繁(32B/次)
◦ 上下文切换开销(100线程)
4.2 对比大包测试
| 测试类型 | -l 32 性能特点 |
-l 1460 性能特点 |
|---|---|---|
| 包速率(PPS) | 极高(如590,000包/秒) | 低(如34,000包/秒) |
| CPU占用 | 高(频繁系统调用) | 低(TSO/GRO优化) |
| 适用场景 | 测试路由器小包转发极限 | 测量链路最大吞吐量 |
5. 操作建议
验证分片行为:
1
2# 抓包观察实际包大小
tcpdump -ni eth0 'tcp and port 5001' -vv | grep 'length 52'优化测试方法:
1
2# 更真实的压力测试(TCP+大包+多线程)
iperf -c server -l 1460 -P 10 -w 2M -t 60监控系统资源:
1
watch -n 1 'cat /proc/net/sockstat{,6}' # 查看socket缓冲区使用
总结
这条命令通过:
-l 32制造高频小包流量(测试PPS极限)-P 100模拟高并发压力(测试连接数限制)-w 1M优化长距离传输(提升BDP容忍度)
核心价值:暴露网络设备和协议栈在 小包、高并发、大窗口 场景下的真实瓶颈!
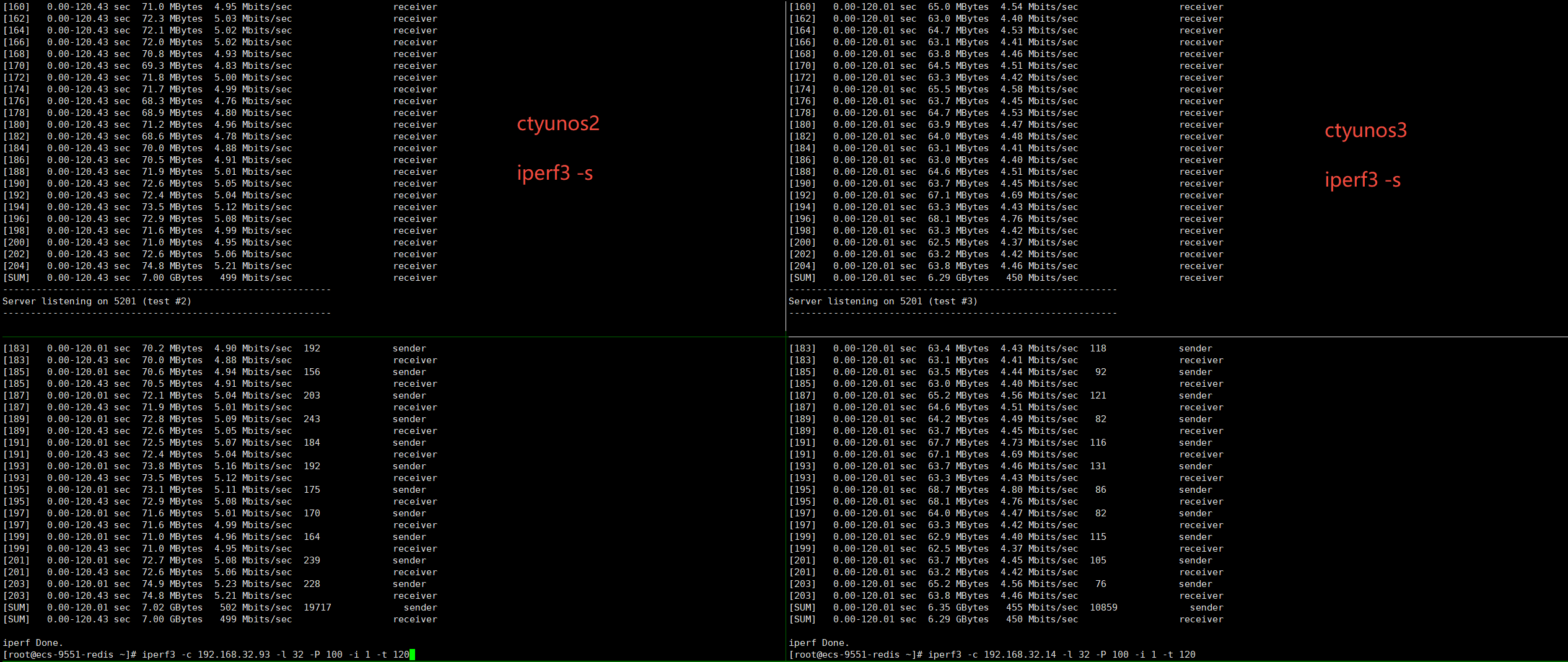
ctyunos3压测完后,接下来压测ctyunos2(ip: 192.168.32.93):
1 | |
在压测机(ip 192.168.32.5)上执行:
1 | |
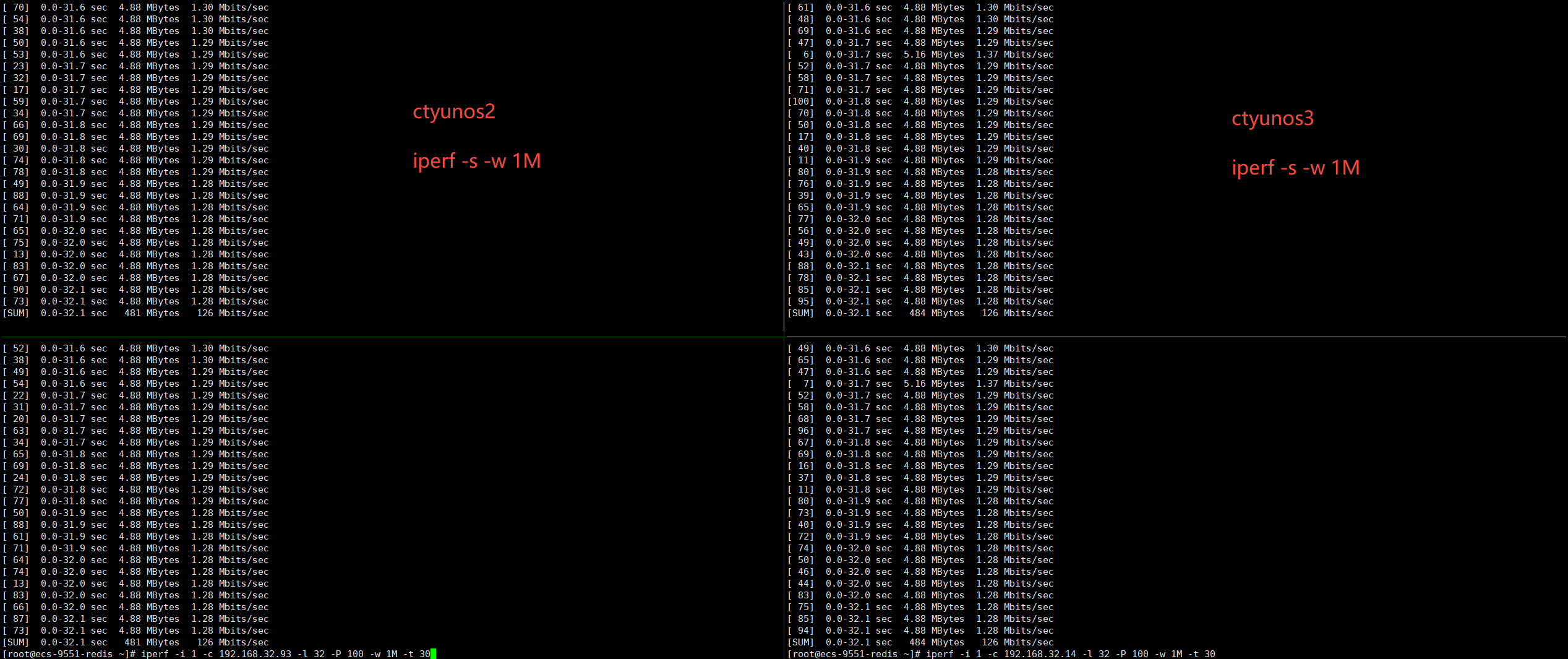
从上图看到,ctyunos2、ctyunos3的带宽都在480M左右,ctyunos3符合预期。
问题结果
从iperf测试的数据来看,当前ctyunos3跑小包带宽跟ctyunos2差不多,说明ctyunos3的带宽没有问题。
使用iperf3测试时,ctyunos3的带宽比ctyunos2低了50M左右,这个后续进一步分析。