linux-kernel
本文最后更新于:2025年2月20日 上午
linux-kernel
理解Linux内核是一项复杂而深刻的任务,因为它涉及到操作系统的核心功能。以下是对你提到的几个关键方面的详细解释:
进程调度:
- 调度器: Linux内核使用调度器来管理系统中运行的进程。CFS(完全公平调度器)是Linux中常用的调度器之一,它旨在实现对处理器的公平分配。
- 进程状态: 进程可以处于运行、就绪、阻塞等状态。调度器的任务是按照一定的算法从就绪队列中选择一个进程并将其分配给CPU执行。
同步机制:
- 原子操作: Linux内核提供原子操作来确保某些操作的不可分割性,以防止多个进程同时执行这些操作。
- 信号量和互斥体: 用于控制对共享资源的访问,以避免竞态条件和数据损坏。
内存管理:
- 虚拟内存: Linux使用虚拟内存来扩展可用的物理内存。这涉及到分页和分段机制,使得每个进程都有自己的虚拟地址空间。
- 内存映射和页面置换: Linux内核使用内存映射来管理进程的虚拟地址空间,而页面置换策略确保物理内存的有效使用。
中断系统:
- 中断处理: 中断是硬件或软件引起的事件,需要立即处理。Linux内核有中断处理程序来响应中断事件。
- 中断向量表: 内核维护一个中断向量表,将中断号映射到相应的中断服务例程,以执行特定的处理。
Linux操作系统整体框架和原理:
模块化设计: Linux内核采用模块化设计,允许动态加载和卸载内核模块,以减小内核的大小并提高灵活性。
文件系统: Linux支持多种文件系统,如EXT4、Btrfs等,提供对磁盘上数据的组织和管理。
系统调用: 用户空间程序通过系统调用与内核进行通信,请求执行特权操作。
在应用程序开发、驱动开发、网络通信协议开发、性能调优、中间件和虚拟化等领域,对Linux内核的深入理解是至关重要的。
- 例如,在驱动开发中,你可能需要理解设备驱动模型、I/O 系统和中断处理;
- 在网络通信协议开发中,你需要了解套接字编程和网络协议栈;
- 在性能调优中,你需要深入了解系统的性能瓶颈并优化相关参数。对于中间件和虚拟化,你需要了解相关的技术和实现原理。
文件系统
传统的文件系统在磁盘上的布局如下:

由上图可知,文件系统的开头通常是由一个磁盘扇区所组成的引导块,该部分的主要目的是用于对操作系统的引导。一般只在启动操作系统时使用。
随后是超级块,超级块主要存放了该物理磁盘中文件系统结构的相关信息,并且对各个部分的大小进行说明。
最后由i节点位图,逻辑块位图、i节点、逻辑块这几部分分布在物理磁盘上。
Linux为了对超级块,i节点,逻辑块这三部分进行高效的管理,Linux创建了几种不同的数据结构,分别是文件系统类型、inode、dentry等几种。
其中,文件系统类型规定了某种文件系统的行为,利用该数据结构可以构造某种文件系统类型的实例,另外,该实例也被称为超级块实例。
超级块则是反映了文件系统整体的控制信息。超级块能够以多种的方式存在,对于基于磁盘的文件系统,它以特定的格式存在于磁盘的固定区域(取决于文件系统类型)上。在挂载文件系统时,该超级块中的内容被读入磁盘中,从而构建出位于内存中的新的超级块。
inode则反映了文件系统对象中的一般元数据信息。dentry则是反映出某个文件系统对象在全局文件系统树中的位置。
四个对象
超级块(super block)
超级块:一个超级块对应一个文件系统(已经安装的文件系统类型如ext2,此处是实际的文件系统,不是VFS)。
之前我们已经说了文件系统用于管理这些文件的数据格式和操作之类的,系统文件有系统文件自己的文件系统,同时对于不同的磁盘分区也有可以是不同的文件系统。那么一个超级块对于一个独立的文件系统。保存文件系统的类型、大小、状态等等。
(“文件系统”和“文件系统类型”不一样!一个文件系统类型下可以包括很多文件系统即很多的super_block)
索引节点(inode)
索引节点inode:保存的其实是实际的数据的一些信息,这些信息称为“元数据”(也就是对文件属性的描述)。
例如:文件大小,设备标识符,用户标识符,用户组标识符,文件模式,扩展属性,文件读取或修改的时间戳,链接数量,指向存储该内容的磁盘区块的指针,文件分类等等。
( 注意数据分成:元数据+数据本身 )
同时注意:inode有两种,一种是VFS的inode,一种是具体文件系统的inode。前者在内存中,后者在磁盘中。所以每次其实是将磁盘中的inode调进填充内存中的inode,这样才是算使用了磁盘文件inode。
inode怎样生成的?
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定(现代OS可以动态变化),一般每2KB就设置一个inode。
一般文件系统中很少有文件小于2KB的,所以预定按照2KB分,一般inode是用不完的。所以inode在文件系统安装的时候会有一个默认数量,后期会根据实际的需要发生变化。
注意inode号:inode号是唯一的,表示不同的文件。其实在Linux内部的时候,访问文件都是通过inode号来进行的,所谓文件名仅仅是给用户容易使用的。
当我们打开一个文件的时候,首先,系统找到这个文件名对应的inode号;然后,通过inode号,得到inode信息,最后,由inode找到文件数据所在的block,现在可以处理文件数据了。
inode和文件的关系?
当创建一个文件的时候,就给文件分配了一个inode。一个inode只对应一个实际文件,一个文件也会只有一个inode。inodes最大数量就是文件的最大数量。
目录项(dentry)
目录项是描述文件的逻辑属性,只存在于内存中,并没有实际对应的磁盘上的描述,更确切的说是存在于内存的目录项缓存,为了提高查找性能而设计。
注意不管是文件夹还是最终的文件,都是属于目录项,所有的目录项在一起构成一颗庞大的目录树。
例如:open一个文件/home/xxx/yyy.txt,那么/、home、xxx、yyy.txt都是一个目录项,VFS在查找的时候,根据一层一层的目录项找到对应的每个目录项的inode,那么沿着目录项进行操作就可以找到最终的文件。
注意:目录也是一种文件(所以也存在对应的inode)。打开目录,实际上就是打开目录文件。
文件对象(file)
文件对象描述的是进程已经打开的文件。因为一个文件可以被多个进程打开,所以一个文件可以存在多个文件对象。但是由于文件是唯一的,那么inode就是唯一的,目录项也是定的!
进程其实是通过文件描述符来操作文件的,每个文件都有一个32位的数字来表示下一个读写的字节位置,这个数字叫做文件位置。
一般情况下打开文件后,打开位置都是从0开始,除非一些特殊情况。Linux用file结构体来保存打开的文件的位置,所以file称为打开的文件描述。file结构形成一个双链表,称为系统打开文件表。
I/O 调度器
I/O 调度器用来决定读写请求的提交顺序,针对不同的 使用场景提供了多种调度算法:NOOP(No Operation)、CFQ(完全公平排队,Complete Fair Queuing)和 deadline(限期)。NOOP 调度算法适合闪存类块设备,CFQ 和 deadline 调度算 法适合机械硬盘。
NOOP调度算法:适用于闪存类块设备,如固态硬盘(SSD)。简单地按照FIFO方式处理I/O请求,不进行排序或调度操作,以最大程度地利用固态硬盘的性能优势。
CFQ调度算法:适用于机械硬盘(HDD)。通过完全公平排队(CFQ),公平分配磁盘访问时间片,以确保多任务环境下的公平性和稳定性。
Deadline调度算法:同样适用于机械硬盘(HDD)。根据I/O请求的截止时间进行排序和调度,以满足对实时性要求较高的应用场景,提供更好的性能保证。
super_block与物理设备
每个块设备或者块设备的分区都对应有自身的request_queue,从I/O调度器合并和排序出来的请求会被 分发(Dispatch)到设备级的request_queue。图13.3描述了request_queue、request、bio、bio_vec之间的关系。

超级块(superblock)与具体的物理设备之间的交互主要通过文件系统驱动程序和底层存储设备驱动程序完成。下面是一些关键的函数,用于超级块与物理设备之间的交互:
generic_make_request():
- 函数原型:blk_qc_t generic_make_request(struct bio *bio)
- 描述:该函数用于将输入/输出请求(I/O request)发送到底层块设备队列。它将bio结构体表示的请求传递给底层的块设备队列,由底层设备驱动程序负责实际的I/O操作。
submit_bio():
- 函数原型:void submit_bio(int rw, struct bio *bio)
- 描述:该函数用于将bio结构体表示的I/O请求提交给底层的块设备队列。它将请求添加到队列中,并触发底层设备驱动程序执行相应的I/O操作。
blkdev_issue_flush():
- 函数原型:int blkdev_issue_flush(struct block_device bdev, gfp_t gfp_mask, sector_t error_sector)
- 描述:该函数用于向底层块设备发送刷新(flush)请求,以确保数据被持久化到存储设备中。它将请求添加到队列中,并等待底层设备完成刷新操作。
blkdev_issue_discard():
- 函数原型:int blkdev_issue_discard(struct block_device *bdev, sector_t sector, sector_t nr_sects, gfp_t gfp_mask)
- 描述:该函数用于向底层块设备发送丢弃(discard)请求,以释放已使用的块。它将请求添加到队列中,并等待底层设备完成丢弃操作。
ext4
Ext4文件系统的初始化流程涉及多个关键代码和函数。以下是大致的初始化流程以及其中的关键代码:
注册文件系统类型:
1 | |
初始化超级块:
1 | |
初始化目录索引:
1 | |
初始化文件系统操作函数:
1 | |
1 | |
ext4比ext3索引快的原因
多级索引(Multilevel Indexing):Ext4引入了多级索引的概念,允许更大的文件系统和更高效的索引访问。相比之下,Ext3使用的是单级索引,对于大型文件系统来说,单级索引可能会导致索引节点(inode)表过大,从而影响性能。
Extents:Ext4引入了Extents的概念,它将连续的数据块组织成一个Extent,而不是使用传统的单个数据块。这样可以减少索引节点的数量,提高索引访问的效率。相比之下,Ext3使用传统的间接块(indirect block)方式来组织数据块。
ext4 journal 模式
当Ext4文件系统以日志(journal)模式进行数据落盘时,以下是关键函数和其执行流程的概述:
ext4_journal_start():该函数用于启动日志事务,它通常由文件系统操作(如文件创建、写入等)的关键路径调用。在启动日志事务之前,它会检查是否已经存在活动的事务,如果存在则等待其完成。
ext4_handle_dirty_metadata():该函数用于处理需要写入日志的元数据块(如inode、目录结构等)。它将元数据块标记为"dirty"(脏块),表示需要更新。此函数通常在文件系统操作期间被调用,以确保相关的元数据更改被记录到日志中。
ext4_journal_dirty_metadata():该函数将标记为"dirty"的元数据块添加到日志中。它将元数据块的内容复制到日志中,并更新元数据块的状态,以反映其已经在日志中。
ext4_journal_stop():该函数用于完成日志事务并将日志中的更改应用于文件系统。它通常在文件系统操作完成后被调用,以确保日志中的更改被提交和应用。该函数将写入一个特殊的日志记录,称为"commit record",该记录包含着所有在事务期间发生的元数据更改。
ext4_journal_commit_callback():该函数是一个回调函数,在日志提交完成后被调用。它用于执行与日志提交相关的清理操作,例如释放占用的资源或更新文件系统状态。
进程调度

内核默认提供了5个调度器,Linux内核使用struct sched_class来对调度器进行抽象:
- Stop调度器, stop_sched_class:优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占;
- Deadline调度器, dl_sched_class:使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进行调度运行;
- RT调度器, rt_sched_class:实时调度器,为每个优先级维护一个队列;
- CFS调度器, cfs_sched_class:完全公平调度器,采用完全公平调度算法,引入虚拟运行时间概念;
- IDLE-Task调度器, idle_sched_class:空闲调度器,每个CPU都会有一个idle线程,当没有其他进程可以调度时,调度运行idle线程;
Linux内核提供了一些调度策略供用户程序来选择调度器,其中Stop调度器和IDLE-Task调度器,仅由内核使用,用户无法进行选择:
- SCHED_DEADLINE:限期进程调度策略,使task选择Deadline调度器来调度运行;
- SCHED_RR:实时进程调度策略,时间片轮转,进程用完时间片后加入优先级对应运行队列的尾部,把CPU让给同优先级的其他进程;
- SCHED_FIFO:实时进程调度策略,先进先出调度没有时间片,没有更高优先级的情况下,只能等待主动让出CPU;
- SCHED_NORMAL:普通进程调度策略,使task选择CFS调度器来调度运行;
- SCHED_BATCH:普通进程调度策略,批量处理,使task选择CFS调度器来调度运行;
- SCHED_IDLE:普通进程调度策略,使task以最低优先级选择CFS调度器来调度运行;
Stop调度器
Stop 调度器是 Linux 内核中的一种调度策略,它可以被用于特殊情况下的进程,通常是用于调试或者诊断目的。使用 Stop 调度器时,被停止的进程不会被调度执行,但是它们的状态会被保留在内存中,以便之后恢复执行。Stop 调度器通常用于以下情况:
调试工具: 调试器(如GDB)通常会使用 Stop 调度器来暂停进程的执行,以便调试人员可以检查其状态、内存和寄存器等信息。
系统诊断: 在某些系统诊断场景下,需要暂停某些进程以收集信息、分析问题或执行修复操作。Stop 调度器可以用于这些目的。
性能分析: 某些性能分析工具可能会使用 Stop 调度器来停止某些进程,以便收集性能数据或执行性能分析操作。
实验和测试: 在实验和测试环境中,Stop 调度器可以用于暂停进程以执行特定的实验、测试用例或场景。
总的来说,Stop 调度器通常被用于特殊的调试、诊断、性能分析、实验和测试等场景,普通用户进程通常不会直接使用 Stop 调度器。
给出具体场景下的案例分析,如perf是怎么使用Stop调度器的,实现了什么功能?
在性能分析场景中,perf(Performance Counters for Linux)工具通常使用 Stop 调度器来暂停正在运行的进程,以收集性能数据。具体来说,perf 使用 Stop 调度器实现了以下功能:
采样事件: Perf 通过配置硬件性能计数器来监视各种事件(如指令执行、缓存命中、缓存失效等),当事件发生时,Stop 调度器会暂停当前正在运行的进程,perf 则会在进程暂停时获取相关的性能数据。
堆栈跟踪: Perf 可以在进程暂停时获取其堆栈信息,包括函数调用关系和指令执行路径。这些堆栈信息对于分析程序的性能瓶颈和优化代码非常有帮助。
计数器数据采集: Perf 可以利用 Stop 调度器来收集硬件性能计数器的计数数据,这些数据用于分析程序的性能特征,如 CPU 使用率、缓存命中率等。
事件统计: Perf 可以统计各种事件的发生次数,并生成相应的报告,帮助用户了解程序的性能特征和行为。
总的来说,Perf 使用 Stop 调度器实现了对运行中进程的暂停和性能数据收集,为用户提供了丰富的性能分析功能,帮助用户理解和优化程序的性能表现。
红黑树
红黑树是一种自平衡的二叉搜索树,它具有以下特性:
时间复杂度:
- 查找(Search): O(log n)
- 插入(Insert): O(log n)
- 删除(Delete): O(log n)
这里的 n 表示红黑树中节点的数量。由于红黑树是自平衡的,其高度受到对数级别的限制,因此这些操作的时间复杂度是对数级别的。
空间复杂度:
- 空间复杂度主要由节点本身的存储和额外的颜色信息组成。
- 每个节点通常需要存储指向左右子节点的指针、键值(或数据)、父节点指针、以及表示节点颜色的额外信息。这些信息的空间复杂度是 O(1)。
- 因此,红黑树的总体空间复杂度是 O(n),其中 n 是树中节点的数量。
需要注意的是,虽然红黑树的常规操作(查找、插入、删除)的平均时间复杂度是 O(log n),但在最坏情况下的时间复杂度也是 O(log n)。这是由于红黑树的自平衡性质,使得树的高度保持在对数级别。
runqueue 运行队列

- 每个CPU都有一个运行队列,每个调度器都作用于运行队列;
- 分配给CPU的task,作为调度实体加入到运行队列中;
- task首次运行时,如果可能,尽量将它加入到父task所在的运行队列中(分配给相同的CPU,缓存affinity会更高,性能会有改善);
task_group 任务分组

利用任务分组的机制,可以设置或限制任务组对CPU的利用率,比如将某些任务限制在某个区间内,从而不去影响其他任务的执行效率;
引入task_group后,调度器的调度对象不仅仅是进程了,Linux内核抽象出了sched_entity/sched_rt_entity/sched_dl_entity描述调度实体,调度实体可以是进程或task_group;
使用数据结构struct task_group来描述任务组,任务组在每个CPU上都会维护一个CFS调度实体、CFS运行队列,RT调度实体,RT运行队列;
运行队列、调度类、调度策略之间的关系?
在Linux内核中,运行队列、调度类和调度策略是相关的概念,它们之间存在一定的关系:
运行队列:
- 运行队列是指处于就绪态的任务(进程或线程)的集合,它们已经准备好并且正在等待被调度执行。
- 在Linux内核中,运行队列通常被组织成多个优先级队列,每个队列对应一个调度类。
调度类:
- 调度类是指对任务进行调度的一组规则和数据结构。在Linux内核中,有多种调度类,例如CFS(Completely Fair Scheduler)、实时调度类(Real-Time Schedulers)等。
- 每个调度类都有自己的运行队列和调度策略,用于管理和调度不同优先级的任务。
调度策略:
- 调度策略是指在特定调度类中用于选择下一个要执行的任务的规则和算法。例如,在CFS调度类中,调度策略是基于虚拟运行时间(Virtual Runtime)的。
- 不同的调度策略会影响任务在运行队列中的排列顺序,进而影响任务的调度顺序。
因此,运行队列包含了处于就绪态的任务,而调度类则定义了对这些任务进行调度的规则和算法。调度策略则是在特定调度类中实现的具体调度算法。这三者之间相互关联,共同决定了任务的调度行为。
调度程序
主动调度 - schedule()

- schedule()函数,是进程调度的核心函数,大体的流程如上图所示。
- 核心的逻辑:选择另外一个进程来替换掉当前运行的进程。进程的选择是通过进程所使用的调度器中的pick_next_task函数来实现的,不同的调度器实现的方法不一样;进程的替换是通过context_switch()来完成切换的,具体的细节后续的文章再深入分析。
周期调度 - schedule_tick()

- 时钟中断处理程序中,调用schedule_tick()函数;
- 时钟中断是调度器的脉搏,内核依靠周期性的时钟来处理器CPU的控制权;
- 时钟中断处理程序,检查当前进程的执行时间是否超额,如果超额则设置重新调度标志(_TIF_NEED_RESCHED);
- 时钟中断处理函数返回时,被中断的进程如果在用户模式下运行,需要检查是否有重新调度标志,设置了则调用schedule()调度;
高精度时钟调度 - hrtick()

- 高精度时钟调度,与周期性调度类似,不同点在于周期调度的精度为ms级别,而高精度调度的精度为ns级别;
- 高精度时钟调度,需要有对应的硬件支持;
进程唤醒时调度 - wake_up_process()
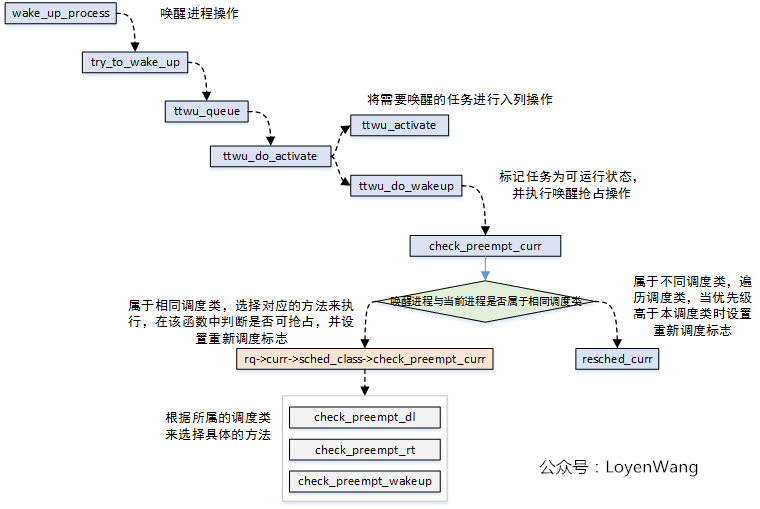
- 唤醒进程时调用wake_up_process()函数,被唤醒的进程可能抢占当前的进程;
三种进程睡眠状态
TASK_KILLABLE
- 进程处于此状态时,可以被信号唤醒。
- 可以响应终止信号(如SIGKILL或SIGTERM)。
- 用于等待某个事件的发生,同时需要对信号做出响应的情况。
TASK_INTERRUPTIBLE
- 进程处于此状态时,可以被信号唤醒。
- 可以响应任何信号。
- 用于等待某个事件的发生,并在接收到信号时做出相应的情况。
TASK_UNINTERRUPTIBLE
- 进程处于此状态时,不响应任何信号。
- 用于等待某个事件的发生,但对于这个事件不可被中断的情况,保证操作的原子性。
抢占
用户抢占
抢占触发点
可以触发抢占的情况很多,比如进程的时间片耗尽、进程等待在某些资源上被唤醒时、进程优先级改变等。Linux内核是通过设置TIF_NEED_RESCHED标志来对进程进行标记的,设置该位则表明需要进行调度切换,而实际的切换将在抢占执行点来完成。
不看代码来讲结论,那都是耍流氓。先看一下两个关键结构体:struct task_struct和struct thread_info。我们在前边的文章中也讲过struct task_struct用于描述任务,该结构体的首个字段放置的正是struct thread_info,struct thread_info结构体中flag字段就可用于设置TIF_NEED_RESCHED,此外该结构体中的preempt_count也与抢占相关。
看看具体哪些函数过程中,设置了TIF_NEED_RESCHED标志吧:

- 内核提供了set_tsk_need_resched函数来将thread_info中flag字段设置成TIF_NEED_RESCHED;
- 设置了TIF_NEED_RESCHED标志,表明需要发生抢占调度;
抢占执行点
用户抢占:抢占执行发生在进程处于用户态。
抢占的执行,最明显的标志就是调用了schedule()函数,来完成任务的切换。
具体来说,在用户态执行抢占在以下几种情况:
- 异常处理后返回到用户态;
- 中断处理后返回到用户态;
- 系统调用后返回到用户态;

- ARMv8有4个Exception Level,其中用户程序运行在EL0,OS运行在EL1,Hypervisor运行在EL2,Secure monitor运行在EL3;
- 用户程序在执行过程中,遇到异常或中断后,将会跳到ENTRY(vectors)向量表处开始执行;
- 返回用户空间时进行标志位判断,设置了TIF_NEED_RESCHED则需要进行调度切换,没有设置该标志,则检查是否有收到信号,有信号未处理的话,还需要进行信号的处理操作;
内核抢占
Linux内核有三种内核抢占模型,先上图:

- CONFIG_PREEMPT_NONE:不支持抢占,中断退出后,需要等到低优先级任务主动让出CPU才发生抢占切换;
- CONFIG_PREEMPT_VOLUNTARY:自愿抢占,代码中增加抢占点,在中断退出后遇到抢占点时进行抢占切换;
- CONFIG_PREEMPT:抢占,当中断退出后,如果遇到了更高优先级的任务,立即进行任务抢占;
抢占触发点
- 在内核中抢占触发点,也是设置struct thread_info的flag字段,设置TIF_NEED_RESCHED表明需要请求重新调度。
- 抢占触发点的几种情况,在用户抢占中已经分析过,不管是用户抢占还是内核抢占,触发点都是一致的;
抢占执行点

总体而言,内核抢占执行点可以归属于两大类:
- 中断执行完毕后进行抢占调度;
- 主动调用preemp_enable或schedule等接口的地方进行抢占调度;
preempt_count
- Linux内核中使用struct thread_info中的preempt_count字段来控制抢占。
- preempt_count的低8位用于控制抢占,当大于0时表示不可抢占,等于0表示可抢占。
- preempt_enable()会将preempt_count值减1,并判断是否需要进行调度,在条件满足时进行切换;
- preempt_disable()会将preempt_count值加1;
此外,preemt_count字段还用于判断进程处于各类上下文以及开关控制等,如图:

上下文切换
- 进程上下文:包含CPU的所有寄存器值、进程的运行状态、堆栈中的内容等,相当于进程某一时刻的快照,包含了所有的软硬件信息;
- 进程切换时,完成的就是上下文的切换,进程上下文的信息会保存在每个struct task_struct结构体中,以便在切换时能完成恢复工作; 进程上下文切换的入口就是__schedule(),分析也围绕这函数展开。
__schedule()
__schedule()函数调用分析如下:
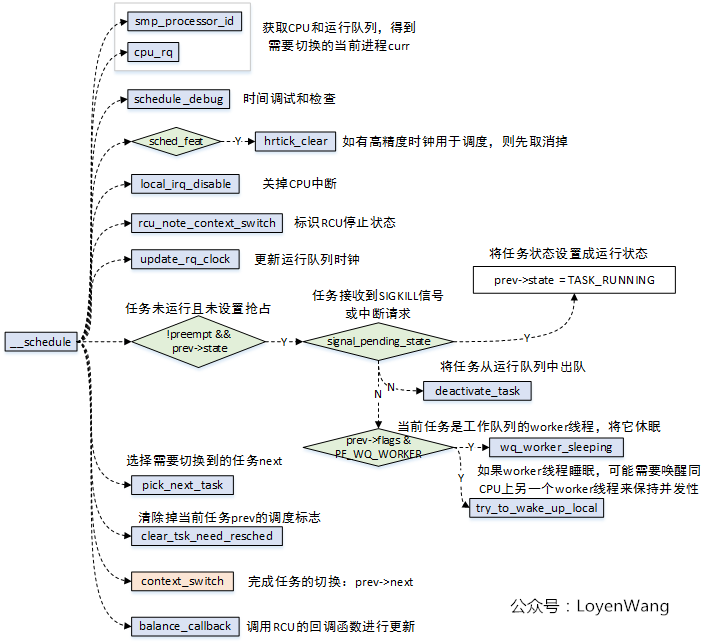
主要的逻辑:
- 根据CPU获取运行队列,进而得到运行队列当前的task,也就是切换前的prev;
- 根据prev的状态进行处理,比如pending信号的处理等,如果该任务是一个worker线程还需要将其睡眠,并唤醒同CPU上的另一个worker线程;
- 根据调度类来选择需要切换过去的下一个task,也就是next;
- context_switch完成进程的切换;
context_switch()
context_switch()的调用分析如下:

核心的逻辑有两部分:
- 进程的地址空间切换:切换的时候要判断切入的进程是否为内核线程;
- 1)所有的用户进程都共用一个内核地址空间,而拥有不同的用户地址空间;
- 2)内核线程本身没有用户地址空间。
- 在进程在切换的过程中就需要对这些因素来考虑,涉及到页表的切换,以及cache/tlb的刷新等操作。
- 寄存器的切换:包括CPU的通用寄存器切换、浮点寄存器切换,以及ARM处理器相关的其他一些寄存器的切换;
进程的切换,带来的开销不仅是页表切换和硬件上下文的切换,还包含了Cache/TLB刷新后带来的miss的开销。在实际的开发中,也需要去评估新增进程带来的调度开销。
内核互斥技术
产生死锁的四个必要条件:
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:进程在已经占有至少一个资源的情况下,又提出新的资源请求,而该请求的资源被其他进程占用,此时进程不会释放自己已占有的资源。
(3) 不可抢占条件:进程已获得的资源,在末使用完之前,不能被其他进程抢占,只能由进程自己释放。
(4) 循环等待条件:存在一组进程{P1, P2, ..., Pn},其中P1等待P2占有的资源,P2等待P3占有的资源,……,Pn等待P1占有的资源,从而形成一个闭环等待。
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之
一不满足,就不会发生死锁。
demo
下面是一个简单的 C 代码示例,演示如何在多线程环境下满足死锁的四个必要条件,导致死锁的发生。
代码示例:
1 | |
如何满足死锁的四个必要条件?
- 互斥条件
pthread_mutex_t互斥锁保证了lockA和lockB资源一次只能被一个线程持有。
- 请求与保持条件
- 线程1获取
lockA后,又请求lockB,但lockB已被线程2持有。
- 线程2获取
lockB后,又请求lockA,但lockA已被线程1持有。
- 两个线程都持有资源并等待额外资源。
- 线程1获取
- 不可抢占条件
- 线程持有的锁不会被其他线程强制释放,只有线程自己释放。
- 循环等待条件
- 线程1持有
lockA,等待lockB。
- 线程2持有
lockB,等待lockA。
- 形成循环等待
Thread1(A → B)→Thread2(B → A)。
- 线程1持有
运行结果(示例)
1 | |
程序会卡住,两个线程互相等待对方释放资源,导致死锁。
解决方案
避免死锁的方法有: 1.
保持锁顺序一致 - 让所有线程总是先锁
lockA,再锁 lockB: 1
2pthread_mutex_lock(&lockA);
pthread_mutex_lock(&lockB);
- 使用
trylock()避免阻塞pthread_mutex_trylock()代替pthread_mutex_lock(),如果获取不到锁,就不继续等待:1
2
3
4
5if (pthread_mutex_trylock(&lockB) == 0) {
// 获取锁成功
} else {
// 获取失败,避免死锁
}
- 使用超时机制
pthread_mutex_timedlock()设置超时时间,避免无限等待。
总结
- 该代码通过两个线程竞争两个锁,形成了死锁,符合死锁的四个必要条件。
- 解决死锁的方法:改变加锁顺序、使用
trylock()、引入超时机制。

图中每一种颜色代表一种竞态情况,主要归结为三类:
- 进程与进程之间:单核上的抢占,多核上的SMP;
- 进程与中断之间:中断又包含了上半部与下半部,中断总是能打断进程的执行流;
- 中断与中断之间:外设的中断可以路由到不同的CPU上,它们之间也可能带来竞态;
在内核中,可能出现多个进程(通过系统调用进入内核模式)访问同一个对象、进程 和硬中断访问同一个对象、进程和软中断访问同一个对象、多个处理器访问同一个对象等 现象,我们需要使用互斥技术,确保在给定的时刻只有一个主体可以进入临界区访问对象。
如果临界区的执行时间比较长或者可能睡眠,可以使用下面这些互斥技术。
- (1)信号量,大多数情况下我们使用互斥信号量。
- (2)读写信号量。
- (3)互斥锁。
- (4)实时互斥锁。
申请这些锁的时候,如果锁被其他进程占有,进程将会睡眠等待,代价很高。
如果临界区的执行时间很短,并且不会睡眠,那么使用上面的锁不太合适,因为进程 切换的代价很高,可以使用下面这些互斥技术。
- (1)原子变量。
- (2)自旋锁。
- (3)读写自旋锁,它是对自旋锁的改进,允许多个读者同时进入临界区。
- (4)顺序锁,它是对读写自旋锁的改进,读者不会阻塞写者。
申请这些锁的时候,如果锁被其他进程占有,进程自旋等待(也称为忙等待)。
进程还可以使用下面的互斥技术。
- (1)禁止内核抢占,防止被当前处理器上的其他进程抢占,实现和当前处理器上的其 他进程互斥。
- (2)禁止软中断,防止被当前处理器上的软中断抢占,实现和当前处理器上的软中断 互斥。
- (3)禁止硬中断,防止被当前处理器上的硬中断抢占,实现和当前处理器上的硬中断 互斥。
在多处理器系统中,为了提高程序的性能,需要尽量减少处理器之间的互斥,使处理 器可以最大限度地并行执行。从互斥信号量到读写信号量的改进,从自旋锁到读写自旋锁 的改进,允许读者并行访问临界区,提高了并行性能,但是我们还可以进一步提高并行性 能,使用下面这些避免使用锁的互斥技术。
- (1)每处理器变量。
- (2)每处理器计数器。
- (3)内存屏障。
- (4)读-复制更新(Read-Copy Update,RCU)。
- (5)可睡眠 RCU。
使用锁保护临界区,如果使用不当,可能出现死锁问题。内核里面的锁非常多,定位 很难,为了方便定位死锁问题,内核提供了死锁检测工具 lockdep。
可睡眠RCU与RCU的区别?
RCU(Read-Copy Update)和可睡眠 RCU 是两种用于实现并发读取和更新的无锁同步机制,但它们在一些方面存在区别。
RCU(Read-Copy Update):
特点:
- RCU 是一种无锁同步机制,主要用于在多处理器系统中实现高效的读取和更新。
- 在 RCU 中,读操作是非阻塞的,不会阻塞其他读者,且可以与写者并发进行。
- 写操作(更新)可能会有一定的延迟,因为它要等待正在执行的读者完成后,再应用更新。
应用场景:
- RCU 适用于读多写少的场景,其中读操作占主导地位。
可睡眠 RCU:
特点:
- 可睡眠 RCU 是对传统 RCU 的扩展,允许在临界区执行可能会导致进程睡眠的操作。
- 传统 RCU 不允许在临界区中执行可能导致进程睡眠的操作,因为这可能会破坏 RCU 的原理。可睡眠 RCU 通过使用睡眠锁和条件变量等技术来解决这个问题。
适用场景:
- 当需要在 RCU 临界区中执行可能导致睡眠的操作时,可睡眠 RCU 是一种更为灵活的选择。
区别总结:
- 睡眠操作支持: 主要区别在于可睡眠 RCU 允许在 RCU 临界区执行可能导致睡眠的操作,而传统 RCU 不支持这样的操作。
- 复杂性: 由于支持睡眠操作,可睡眠 RCU 的实现可能相对复杂一些。 选择使用哪种形式的 RCU 取决于具体的应用场景。如果在临界区执行的操作不涉及可能导致睡眠的情况,传统 RCU 可能更为简单且高效。但如果需要在临界区执行可能导致睡眠的操作,可睡眠 RCU 提供了相应的支持。
spin_lock原理
目前内核中提供了很多机制来处理并发问题,spinlock就是其中一种。
spinlock,就是大家熟知的自旋锁,它的特点是自旋锁保护的区域不允许睡眠,不可以用在中断上下文中。自旋锁获取不到时,CPU会忙等待,并循环测试等待条件。自旋锁一般用于保护很短的临界区。

spin_lock/spin_unlock
先看一下函数调用流程:

- spin_lock操作中,关闭了抢占,也就是其他进程无法再来抢占当前进程了;
- spin_lock函数中,关键逻辑需要依赖于体系结构的实现,也就是arch_spin_lock函数;
- spin_unlock函数中,关键逻辑需要依赖于体系结构的实现,也就是arch_spin_unlock函数;
spinlock的核心思想是基于tickets的机制:
- 每个锁的数据结构arch_spinlock_t中维护两个字段:next和owner,只有当next和owner相等时才能获取锁;
- 每个进程在获取锁的时候,next值会增加,当进程在释放锁的时候owner值会增加;
- 如果有多个进程在争抢锁的时候,看起来就像是一个排队系统,FIFO ticket spinlock;
上边的代码中,核心逻辑在于asm volatile()内联汇编中,有点迷糊吗?把核心逻辑翻译成C语言,类似于下边:
asm volatile内联汇编中,有很多独占的操作指令,只有基于指令的独占操作,才能保证软件上的互斥,简单介绍如下:
- ldaxr:Load-Acquire Exclusive Register derives an address from a base register value, loads a 32-bit word or 64-bit doubleword from memory, and writes it to a register,从内存地址中读取值到寄存器中,独占访问;
- stxr:Store Exclusive Register stores a 32-bit or a 64-bit doubleword from a register to memory if the PE has exclusive access to the memory address,将寄存器中的值写入到内存中,并需要返回是否独占访问成功;
- eor:Bitwise Exclusive OR,执行独占的按位或操作;
- ldadda:Atomic add on word or doubleword in memory atomically loads a 32-bit word or 64-bit doubleword from memory, adds the value held in a register to it, and stores the result back to memory,原子的将内存中的数据进行加值处理,并将结果写回到内存中;
此外,还需要提醒一点的是,在arch_spin_lock中,当自旋等待时,会执行WFE指令,这条指令会让CPU处于低功耗的状态,其他CPU可以通过SEV指令来唤醒当前CPU。
spin_lock_irq/spin_lock_bh
自旋锁还有另外两种形式,那就是在持有锁的时候,不仅仅关掉抢占,还会把本地的中断关掉,或者把下半部关掉(本质上是把软中断关掉)。 这种锁用来保护临界资源既会被进程访问,也会被中断访问的情况。
看一下调用流程图:

- 可以看到这两个函数中,实际锁的机制实现跟spin_lock是一样的;
- 额外提一句,spin_lock_irq还有一种变种形式spin_lock_irqsave,该函数会将当前处理器的硬件中断状态保存下来;
__local_bh_disable_ip是怎么实现的呢,貌似也没有看到关抢占?有必要前情回顾一下了,如果看过之前的文章的朋友,应该见过下边这张图片:

- thread_info->preempt_count值就维护了各种状态,针对该值的加减操作,就可以进行状态的控制;
rwlock读写锁
读写锁是自旋锁的一种变种,分为读锁和写锁,有以下特点:
- 可以多个读者同时进入临界区;
- 读者与写者互斥;
- 写者与写者互斥;
先看流程分析图:

- 读写锁数据结构arch_rwlock_t中只维护了一个字段:volatile unsigned int lock,其中bit[31]用于写锁的标记,bit[30:0]用于读锁的统计;
- 读者在获取读锁的时候,高位bit[31]如果为1,表明正有写者在访问临界区,这时候会进入自旋的状态,如果没有写者访问,那么直接去自加rw->lock的值,从逻辑中可以看出,是支持多个读者同时访问的;
- 读者在释放锁的时候,直接将rw->lock自减1即可;
- 写者在获取锁的时候,判断rw->lock的值是否为0,这个条件显得更为苛刻,也就是只要有其他读者或者写者访问,那么都将进入自旋,没错,它确实很霸道,只能自己一个人持有;
- 写者在释放锁的时候,很简单,直接将rw->lock值清零即可;
- 缺点:由于读者的判断条件很苛刻,假设出现了接二连三的读者来访问临界区,那么rw->lock的值将一直不为0,也就是会把写者活活的气死,噢,是活活的饿死。
读写锁当然也有类似于自旋锁的关中断、关底半部的形式:read_lock_irq/read_lock_bh/write_lock_irq/write_lock_bh,原理都类似,不再赘述了。
seqlock顺序锁
- 顺序锁也区分读者与写者,它的优点是不会把写者给饿死。
来看一下流程图:

顺序锁的读锁有三种形式:
- 无加锁访问,读者在读临界区之前,先读取序列号,退出临界区操作后再读取序列号进行比较,如果发现不相等,说明被写者更新内容了,需要重新再读取临界区,所以这种情况下可能给读者带来的开销会大一些;
- 加锁访问,实际是spin_lock/spin_unlock,仅仅是接口包装了一下而已,因此对读和写都是互斥的;
- 在形式1和形式2中动态选择,如果有写者在写临界区,读者化身为自旋锁,没有写者在写临界区,则化身为顺序无锁访问;
顺序锁的写锁,只有一种形式,本质上是用自旋锁来保护临界区,然后再把序号值自加处理;
顺序锁也有一些局限的地方,比如采用读者的形式1的话,临界区中存在地址(指针)操作,如果写者把地址进行了修改,那就可能造成访问错误了;
说明一下流程图中的smp_rmb/smp_wmb,这两个函数是内存屏障操作,作用是告诉编译器内存中的值已经改变,之前对内存的缓存(缓存到寄存器)都需要抛弃,屏障之后的内存操作需要重新从内存load,而不能使用之前寄存器缓存的值,内存屏障就像是代码中一道不可逾越的屏障,屏障之前的load/store指令不能跑到屏障的后边,同理,后边的也不能跑到前边;
顺序锁也同样存在关中断和关下半部的形式,原理基本都是一致的,不再啰嗦了。
RCU原理
RCU, Read-Copy-Update,是Linux内核中的一种同步机制。RCU常被描述为读写锁的替代品,它的特点是读者并不需要直接与写者进行同步,读者与写者也能并发的执行。RCU的目标就是最大程度来减少读者侧的开销,因此也常用于对读者性能要求高的场景。
优点:
- 读者侧开销很少、不需要获取任何锁,不需要执行原子指令或者内存屏障;
- 没有死锁问题;
- 没有优先级反转的问题;
- 没有内存泄露的危险问题;
- 很好的实时延迟;
缺点:
- 写者的同步开销比较大,写者之间需要互斥处理;
- 使用上比其他同步机制复杂;

- 多个读者可以并发访问临界资源,同时使用rcu_read_lock/rcu_read_unlock来标定临界区;
- 写者(updater)在更新临界资源的时候,拷贝一份副本作为基础进行修改,当所有读者离开临界区后,把指向旧临界资源的指针指向更新后的副本,并对旧资源进行回收处理;
- 图中只显示一个写者,当存在多个写者的时候,需要在写者之间进行互斥处理;
上述的描述比较简单,RCU的实现很复杂。本文先对RCU来一个初印象,并结合接口进行实例分析,后续文章再逐层深入到背后的实现原理。开始吧!
RCU基本要素
RCU的基本思想是将更新Update操作分为两个部分:1)Removal移除;2)Reclamation回收。直白点来理解就是,临界资源被多个读者读取,写者在拷贝副本修改后进行更新时,第一步需要先把旧的临界资源数据移除(修改指针指向),第二步需要把旧的数据进行回收(比如kfree)。
因此,从功能上分为以下三个基本的要素:Reader/Updater/Reclaimer,三者之间的交互如下图:
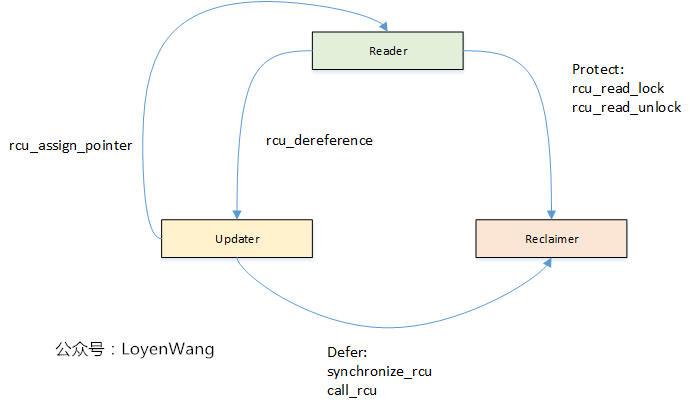
Reader
- 使用rcu_read_lock和rcu_read_unlock来界定读者的临界区,访问受RCU保护的数据时,需要始终在该临界区域内访问;
- 在访问受保护的数据之前,需要使用rcu_dereference来获取RCU-protected指针;
- 当使用不可抢占的RCU时,rcu_read_lock/rcu_read_unlock之间不能使用可以睡眠的代码;
Updater
- 多个Updater更新数据时,需要使用互斥机制进行保护;
- Updater使用rcu_assign_pointer来移除旧的指针指向,指向更新后的临界资源;
- Updater使用synchronize_rcu或call_rcu来启动Reclaimer,对旧的临界资源进行回收,其中synchronize_rcu表示同步等待回收,call_rcu表示异步回收;
Reclaimer
- Reclaimer回收的是旧的临界资源;
- 为了确保没有读者正在访问要回收的临界资源,Reclaimer需要等待所有的读者退出临界区,这个等待的时间叫做宽限期(Grace Period);
Grace Period
- 中间的黄色部分代表的就是Grace Period,中文叫做宽限期,从Removal到Reclamation,中间就隔了一个宽限期;
- 只有当宽限期结束后,才会触发回收的工作,宽限期的结束代表着Reader都已经退出了临界区,因此回收工作也就是安全的操作了;
- 宽限期是否结束,与处理器的执行状态检测有关,也就是检测静止状态Quiescent Status;
- RCU的性能与可扩展性依赖于它是否能有效的检测出静止状态(Quiescent Status),并且判断宽限期是否结束。
来一张图:

Quiescent Status
Quiescent Status,用于描述处理器的执行状态。当某个CPU正在访问RCU保护的临界区时,认为是活动的状态,而当它离开了临界区后,则认为它是静止的状态。当所有的CPU都至少经历过一次QS后,宽限期将结束并触发回收工作。

- 在时钟tick中检测CPU处于用户模式或者idle模式,则表明CPU离开了临界区;
- 在不支持抢占的RCU实现中,检测到CPU有context切换,就能表明CPU离开了临界区;
RCU三个基本机制
Publish-Subscribe Mechanism
订阅机制是个什么概念,来张图:
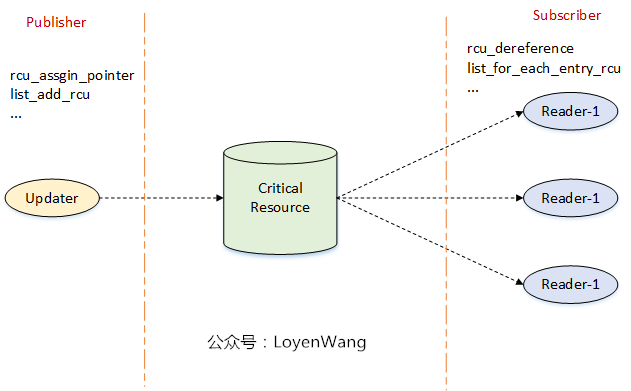
- Updater与Reader类似于Publisher和Subsriber的关系;
- Updater更新内容后调用接口进行发布,Reader调用接口读取发布内容;
乍一看似乎问题不大,Updater进行赋值更新,Reader进行读取和其他处理。然而,由于存在编译乱序和执行乱序的问题,上述代码的执行顺序不见得就是代码的顺序,比如在某些架构(DEC Alpha)中,读者的操作部分,可能在p赋值之前就操作了do_something_with()。
为了解决这个问题,Linux提供了rcu_assign_pointer/rcu_dereference宏来确保执行顺序,Linux内核也基于rcu_assign_pointer/rcu_dereference宏进行了更高层的封装,比如list, hlist,因此,在内核中有三种被RCU保护的场景:1)指针;2)list链表;3)hlist哈希链表。
针对这三种场景,Publish-Subscribe接口如下表:

Wait For Pre-Existing RCU Readers to Complete
Reclaimer需要对旧的临界资源进行回收,那么问题来了,什么时候进行呢?因此RCU需要提供一种机制来确保之前的RCU读者全部都已经完成,也就是退出了rcu_read_lock/rcu_read_unlock标定的临界区后,才能进行回收处理。

- 图中Readers和Updater并发执行;
- 当Updater执行Removal操作后,调用synchronize_rcu,标志着更新结束并开始进入回收阶段;
- 在synchronize_rcu调用后,此时可能还有新的读者来读取临界资源(更新后的内容),但是,Grace Period只等待Pre-Existing的读者,也就是在图中的Reader-4, Reader-5。只要这些之前就存在的RCU读者退出临界区后,意味着宽限期的结束,因此就进行回收处理工作了;
- synchronize_rcu并不是在最后一个Pre-ExistingRCU读者离开临界区后立马就返回,它可能存在一个调度延迟;
Maintain Multiple Versions of Recently Updated Objects
从2.2.2节可以看出,在Updater进行更新后,在Reclaimer进行回收之前,是会存在新旧两个版本的临界资源的,只有在synchronize_rcu返回后,Reclaimer对旧的临界资源进行回收,最后剩下一个版本。显然,在有多个Updater时,临界资源的版本会更多。
还是来张图吧,分别以指针和链表为例:

- 调用synchronize_rcu开始为临界点,分别维护不同版本的临界资源;
- 等到Reclaimer回收旧版本资源后,最终归一统;
RCU更新接口
从《Linux RCU原理剖析(一)-初窥门径》的示例中,我们看到了RCU的写端调用了synchronize_rcu/call_rcu两种类型的接口,事实上Linux内核提供了三种不同类型的RCU,因此也对应了相应形式的接口。
来张图:

- RCU写者,可以通过两种方式来等待宽限期的结束,一种是调用同步接口等待宽限期结束,一种是异步接口等待宽限期结束后再进行回调处理,分别如上图的左右两侧所示;
- 从图中的接口调用来看,同步接口中实际会去调用异步接口,只是同步接口中增加了一个wait_for_completion睡眠等待操作,并且会将wakeme_after_rcu回调- 函数传递给异步接口,当宽限期结束后,在异步接口中回调了wakeme_after_rcu进行唤醒处理;
- 目前内核中提供了三种RCU:
- 可抢占RCU:rcu_read_lock/rcu_read_unlock来界定区域,在读端临界区可以被其他进程抢占;
- 不可抢占RCU(RCU-sched):rcu_read_lock_sched/rcu_read_unlock_sched来界定区域,在读端临界区不允许其他进程抢占;
- 关下半部RCU(RCU-bh):rcu_read_lock_bh/rcu_read_unlock_bh来界定区域,在读端临界区禁止软中断;
- 从图中可以看出来,不管是同步还是异步接口,最终都是调到__call_rcu接口,它是接口实现的关键,所以接下来分析下这个函数了;
__call_rcu

- __call_rcu函数,第一个功能是注册回调函数,而回调的函数的维护是在rcu_data结构中的struct rcu_segcblist cblist字段中; rcu_accelerate_cbs/rcu_advance_cbs,实现中都是通过操作struct rcu_segcblist结构,来完成回调函数的移动处理等;
- __call_rcu函数第二个功能是判断是否需要开启新的宽限期GP;
链表的维护关系如下图所示:

- 实际的设计比较巧妙,通过一个链表来链接所有的回调函数节点,同时维护一个二级指针数组,用于将该链表进行分段,分别维护不同阶段的回调函数,回调函数的移动方向如图所示,关于回调函数节点的处理都围绕着这个图来展开;
那么通过__call_rcu注册的这些回调函数在哪里调用呢?答案是在RCU_SOFTIRQ软中断中:

- 当invoke_rcu_core时,在该函数中调用raise_softirq接口,从而触发软中断回调函数rcu_process_callbacks的执行;
- 涉及到与宽限期GP相关的操作,在rcu_process_callbacks中会调用rcu_gp_kthread_wake唤醒内核线程,最终会在rcu_gp_kthread线程中执行;
- 涉及到RCU注册的回调函数执行的操作,都在rcu_do_batch函数中执行,其中有两种执行方式:
- 1)如果不支持优先级继承的话,直接调用即可;
- 2)支持优先级继承,在把回调的工作放置在rcu_cpu_kthread内核线程中,其中内核为每个CPU都创建了一个rcu_cpu_kthread内核线程;
宽限期开始与结束
既然涉及到宽限期GP的操作,都放到了rcu_gp_kthread内核线程中了,那么来看看这个内核线程的逻辑操作吧:

- 内核分别为rcu_preempt_state, rcu_bh_state, rcu_sched_state创建了内核线程rcu_gp_kthread;
- rcu_gp_kthread内核线程主要完成三个工作:
- 1)创建新的宽限期GP;
- 2)等待强制静止状态,设置超时,提前唤醒说明所有处理器经过了静止状态;
- 3)宽限期结束处理。其中,前边两个操作都是通过睡眠等待在某个条件上。
静止状态检测及报告
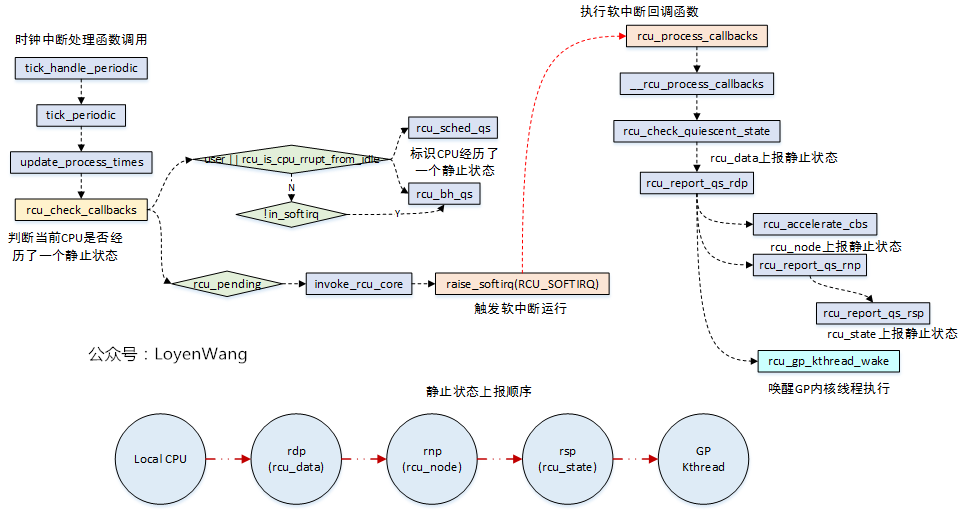
- rcu_sched/rcu_bh类型的RCU中,当检测CPU处于用户模式或处于idle线程中,说明当前CPU已经离开了临界区,经历了一个QS静止状态,对于rcu_bh的RCU,如果没有出去softirq上下文中,也表明CPU经历了QS静止状态;
- 在rcu_pending满足条件的情况下,触发软中断的执行,rcu_process_callbacks将会被调用;
- 在rcu_process_callbacks回调函数中,对宽限期进行判断,并对静止状态逐级上报,如果整个树状结构都经历了静止状态,那就表明了宽限期的结束,从而唤醒内核线程去处理;
- 顺便提一句,在rcu_pending函数中,rcu_pending->__rcu_pending->check_cpu_stall->print_cpu_stall的流程中,会去判断是否有CPU stall的问题,这个在内核中有文档专门来描述,不再分析了;
内存管理
内存管理子系统的架构如图 3.1 所示,分为用户空间、内核空间和硬件 3 个层面。

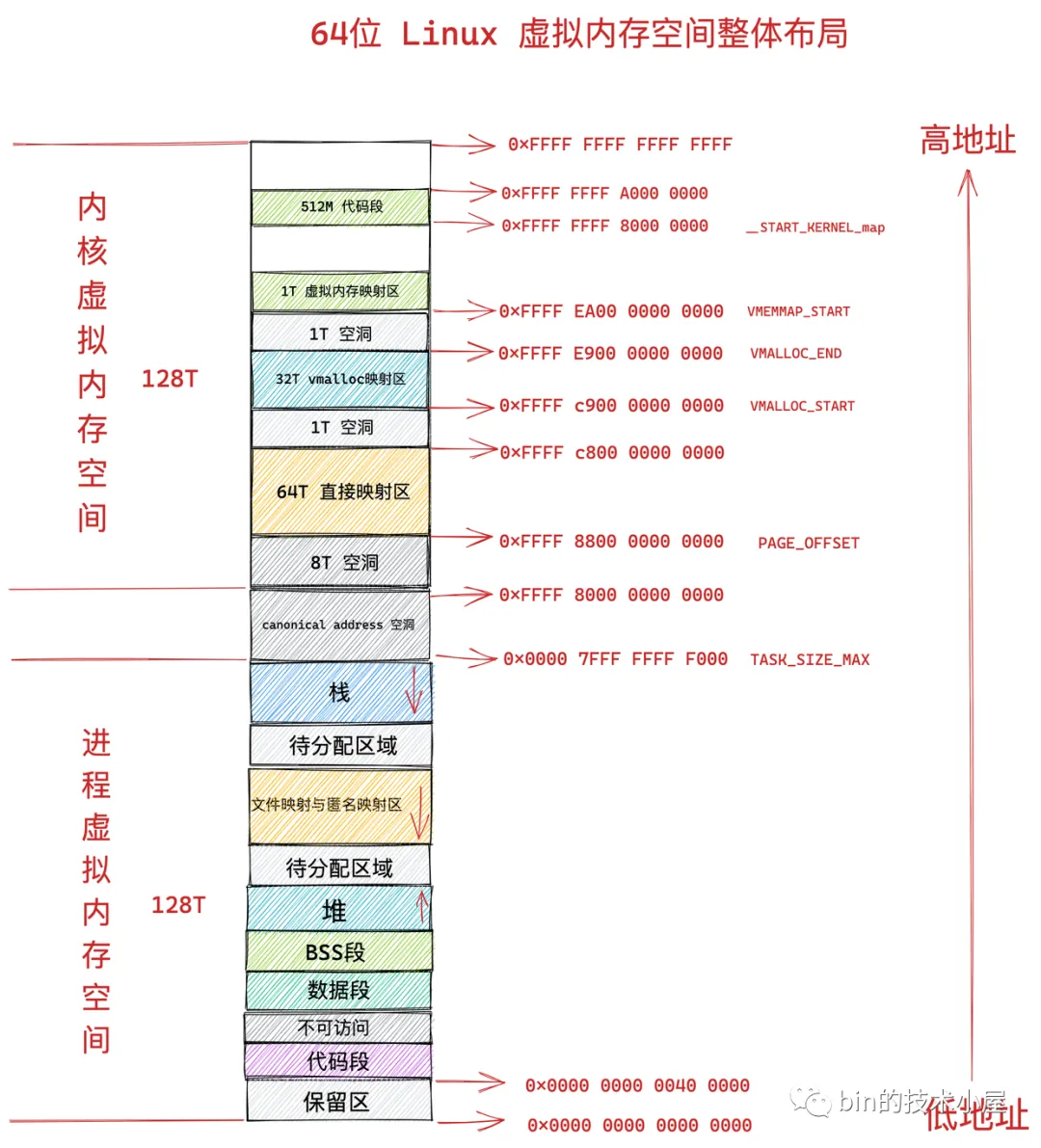
虚拟内存
64位虚拟内存空间

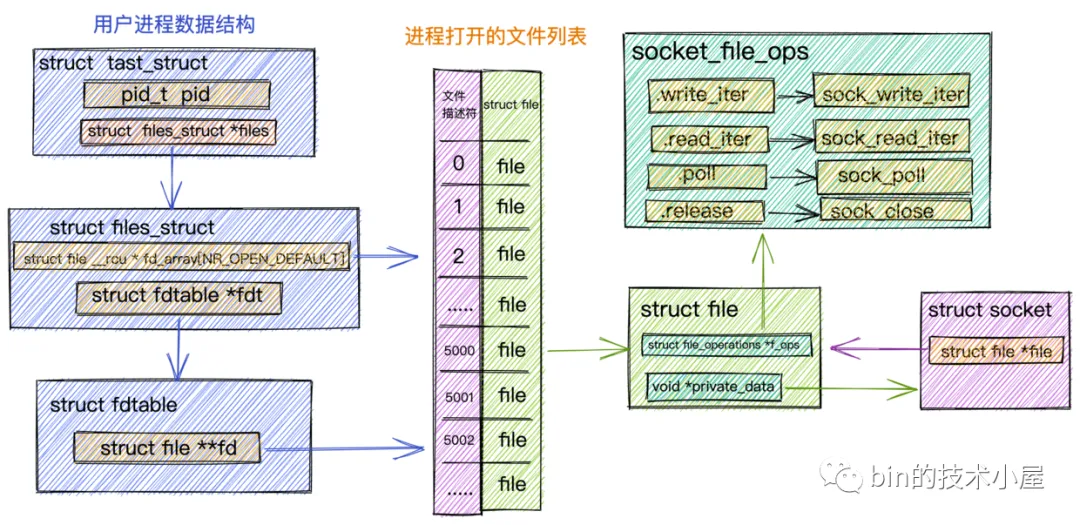
用户态虚拟内存空间




虚拟内存区域相关操作
1 | |
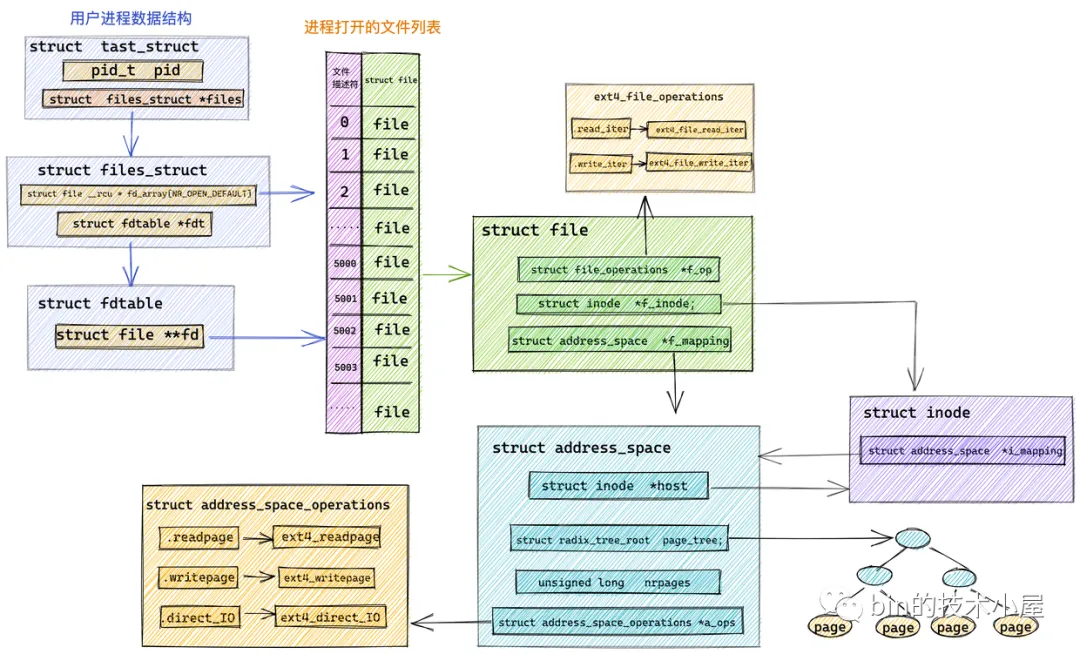

内核虚拟内存空间

物理内存
快速路径 fast path:该路径的下,内存分配的逻辑比较简单,主要是在 WMARK_LOW 水位线之上快速的扫描一下各个内存区域中是否有足够的空闲内存能够满足本次内存分配,如果有则立马从伙伴系统中申请,如果没有立即返回。
慢速路径 slow path:慢速路径下的内存分配逻辑就变的非常复杂了,其中包含了内存分配的各种异常情况的处理,并且会根据文中介绍的 GFP_,ALLOC_ 等各种内存分配策略掩码进行不同分支的处理,整个链路非常庞大且繁杂。
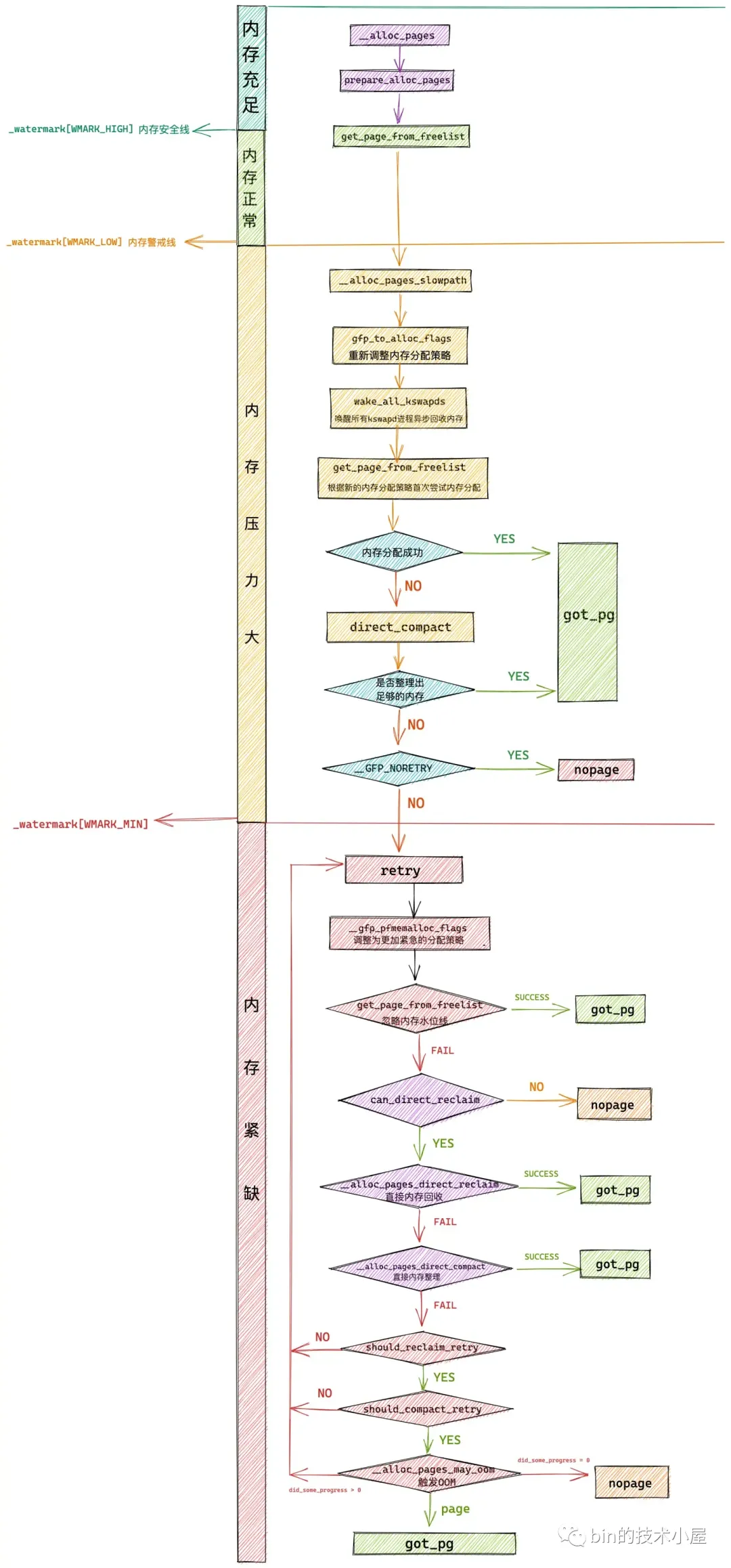
无论是快速路径还是慢速路径下的内存分配都需要最终调用 get_page_from_freelist 函数进行最终的内存分配。只不过,不同路径下 get_page_from_freelist 函数的内存分配策略以及需要考虑的内存水位线会有所不同,其中慢速路径下的内存分配策略会更加激进一些。

伙伴系统
6.1 从 CPU 高速缓存列表中获取内存页
内核对只分配一页物理内存的情况做了特殊处理,当只请求一页内存时,内核会借助 CPU 高速缓存冷热页列表 pcplist 加速内存分配的处理,此时分配的内存页将来自于 pcplist 而不是伙伴系统。
6.2 从伙伴系统中获取内存页
在本文 "3. 伙伴系统的内存分配原理" 小节中笔者详细为大家介绍了伙伴系统的整个内存分配原理,那么在本小节中,我们将正式进入伙伴系统中,来看下伙伴系统在内核中是如何实现的。
在前面介绍的 rmqueue 函数中,涉及到伙伴系统入口函数的有两个:
__rmqueue_smallest 函数主要是封装了整个伙伴系统关于内存分配的核心流程,该函数中的代码正是 “3. 伙伴系统的内存分配原理” 小节所讲的核心内容。
__rmqueue 函数封装的是伙伴系统的整个完整流程,底层调用了 __rmqueue_smallest 函数,它主要实现的是当伙伴系统 free_area 中对应的迁移列表 free_list[MIGRATE_TYPE] 无法满足内存分配需求时, 内存分配在伙伴系统中的 fallback 流程。这一点笔者也在 “3. 伙伴系统的内存分配原理” 小节中详细介绍过了。
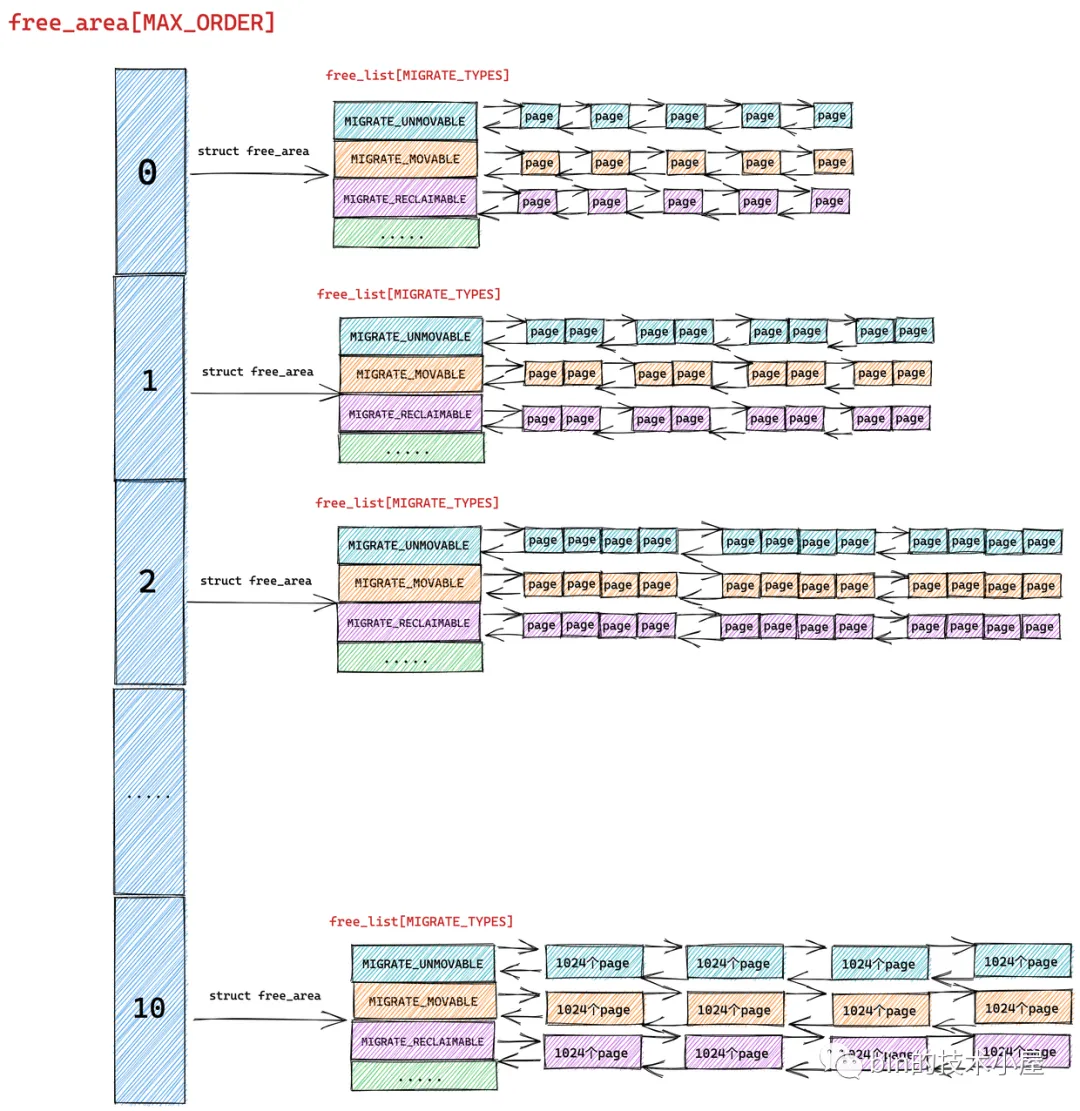
当我们向内核申请的内存页超过一页(order > 0)时,内核就会进入伙伴系统中为我们申请内存。
如果内存分配策略 alloc_flags 指定了 ALLOC_HARDER 时,就会调用 __rmqueue_smallest 直接进入伙伴系统,从 free_list[MIGRATE_HIGHATOMIC] 链表中分配 order 大小的物理内存块。

内存释放

slub内存池


slub 数据结构
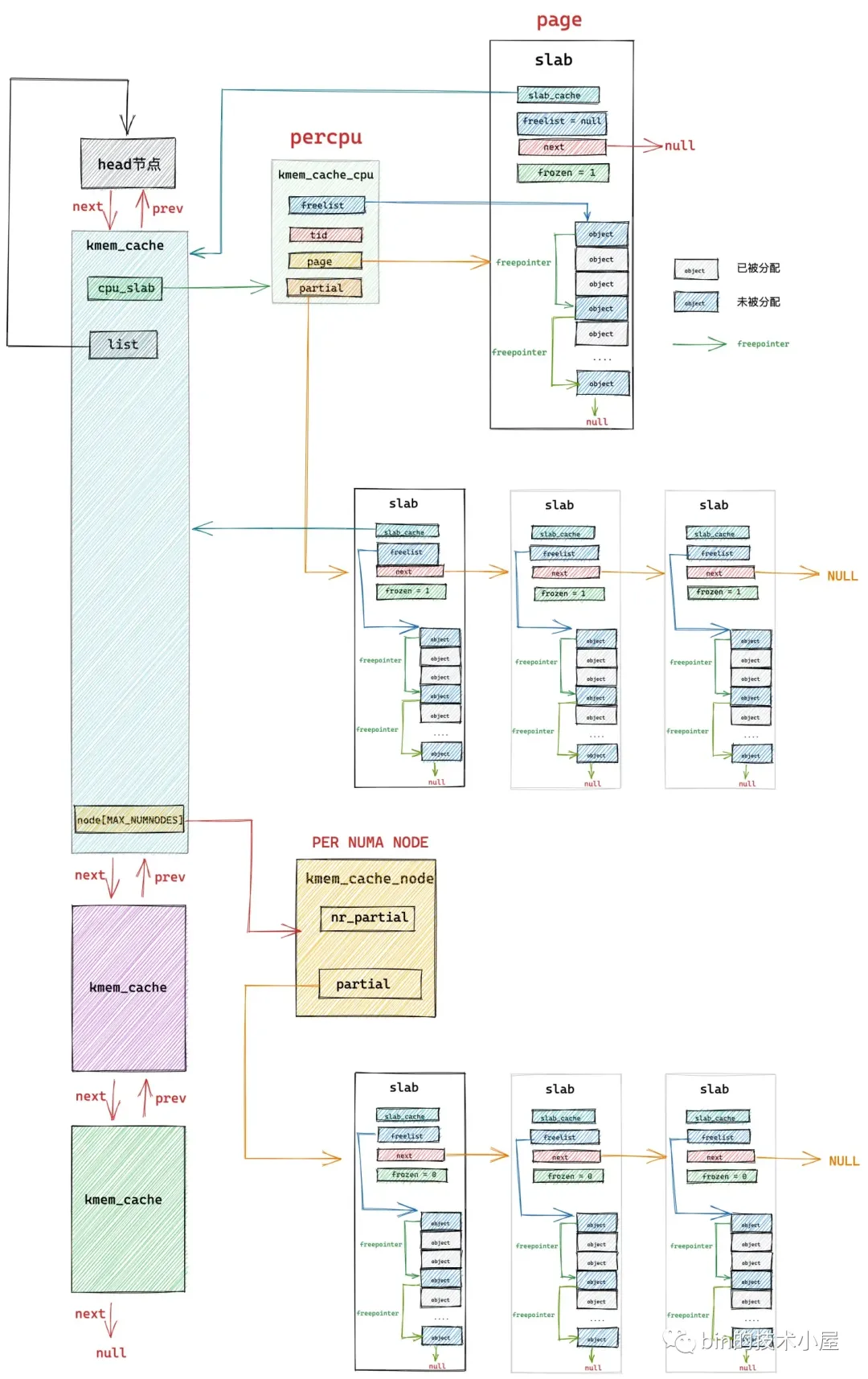
slab 的具体信息也是在 struct page 中存储,下面笔者提取了 struct page 结构中和 slab 相关的字段:
1 | |
在笔者当前所在的内核版本 5.4 中,内核是使用 struct page 来表示 slab 的,但是考虑到 struct page 结构已经非常庞大且复杂,为了减少 struct page 的内存占用以及提高可读性,内核在 5.17 版本中专门为 slab 引入了一个管理结构 struct slab,将原有 struct page 中 slab 相关的字段全部删除,转移到了 struct slab 结构中。这一点,大家只做了解即可。
内存对齐



freepointer

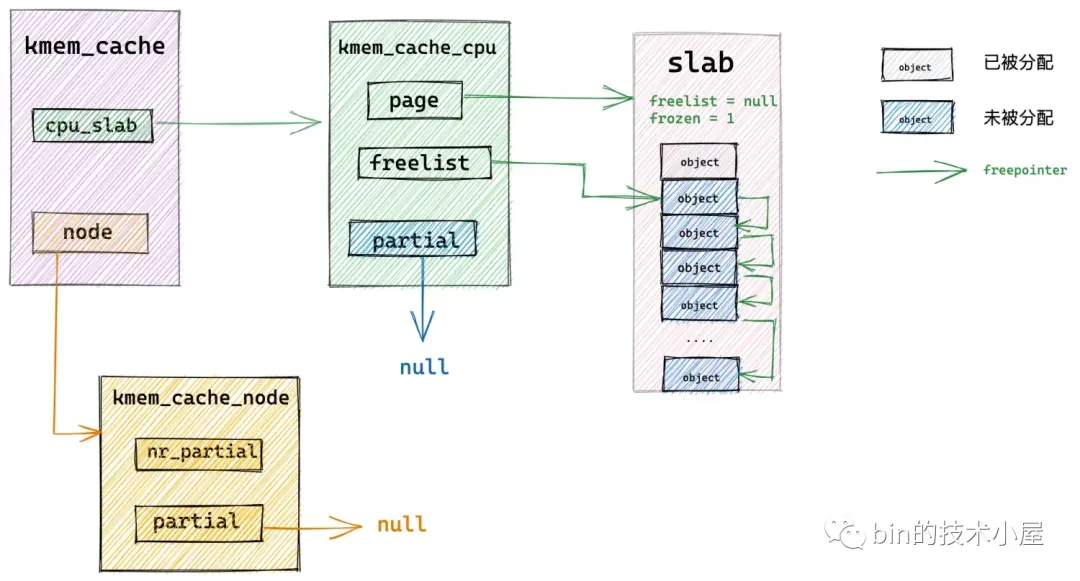
kmem_cache
在 cat /proc/slabinfo 命令显示的这些系统中所有的 slab cache,内核会将这些 slab cache 用一个双向链表统一串联起来。链表的头结点指针保存在 struct kmem_cache 结构的 list 中。
1 | |

slab cache 的架构全貌
7. slab 内存分配原理
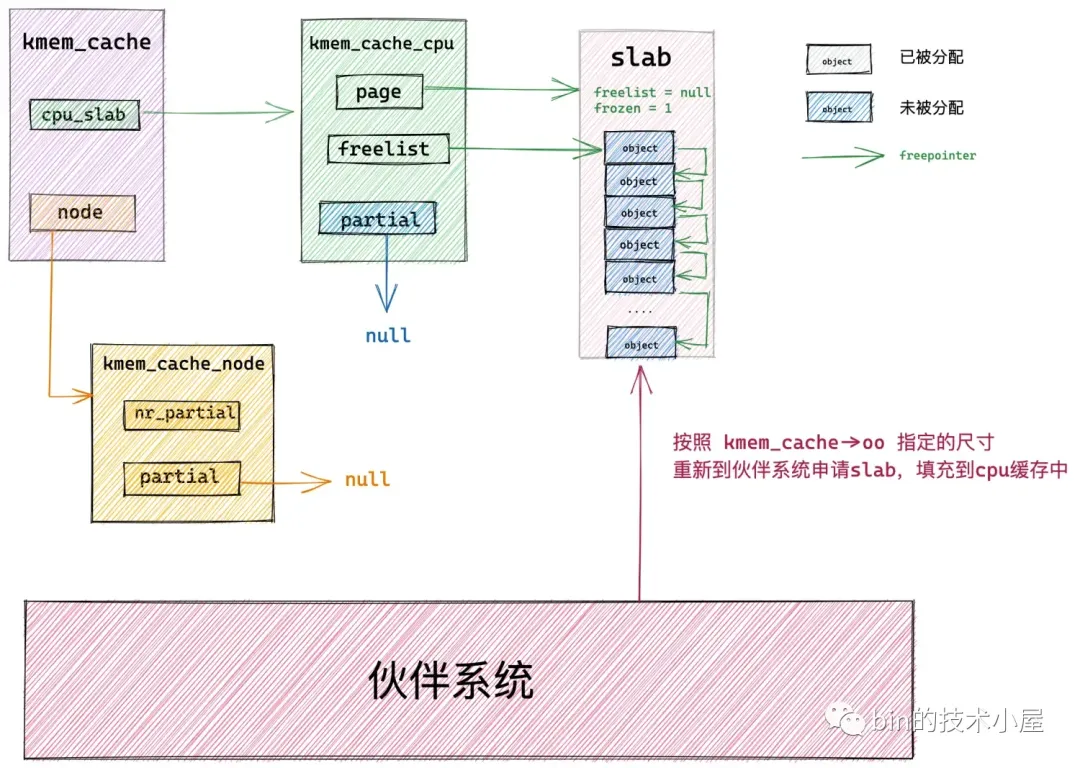
7.1 从本地 cpu 缓存中直接分配

7.2 从本地 cpu 缓存 partial 列表中分配

7.3 从 NUMA 节点缓存中分配


7.4 从伙伴系统中重新申请 slab
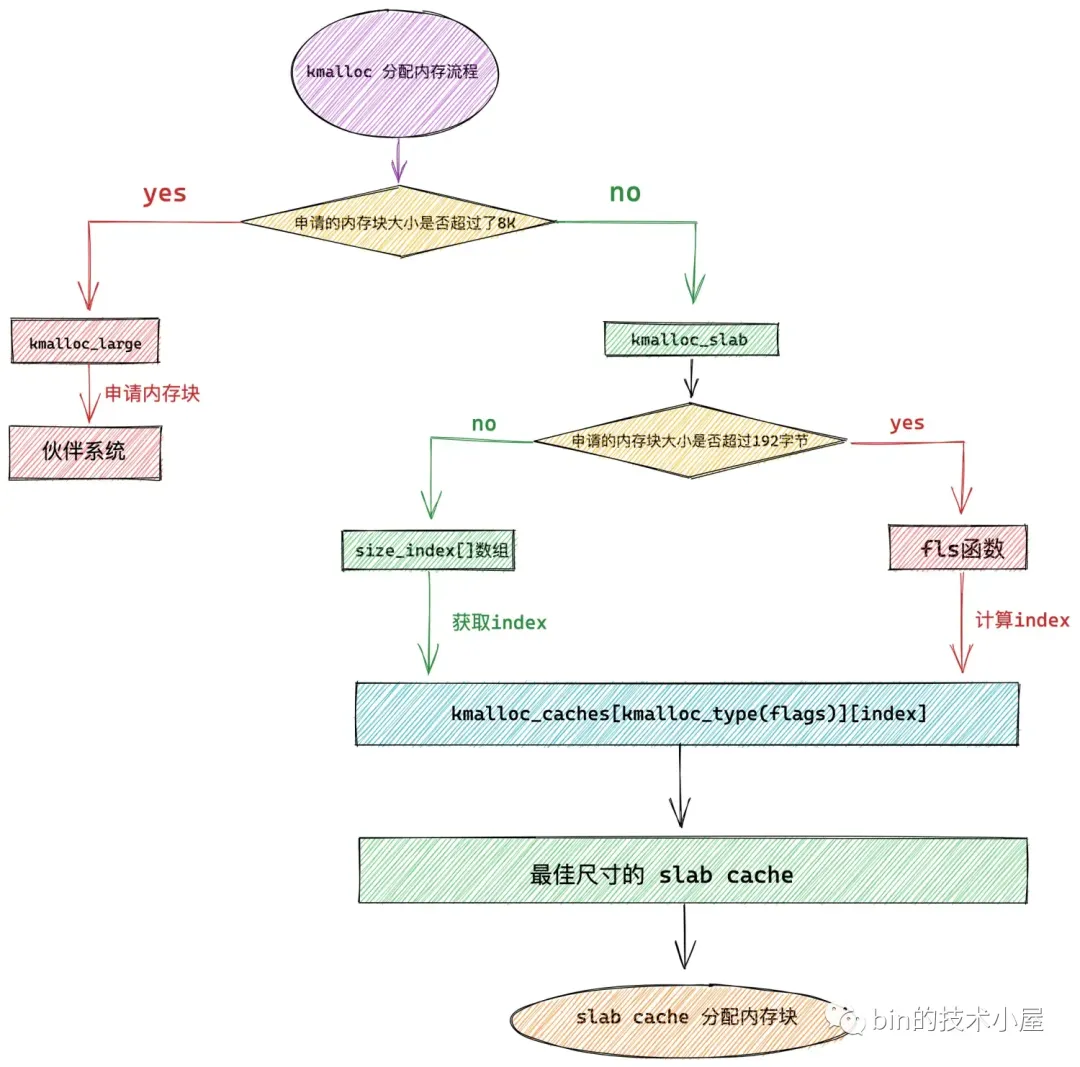
kmalloc
kmalloc 内存池体系的底层基石是基于 slab alloactor 体系构建的,其本质其实就是各种不同尺寸的通用 slab cache。
KMALLOC_NORMAL 表示 kmalloc 需要从 ZONE_NORMAL 物理内存区域中分配内存。
KMALLOC_DMA 表示 kmalloc 需要从 ZONE_DMA 物理内存区域中分配内存。
KMALLOC_RECLAIM 表示需要分配可以被回收的内存,RECLAIM 类型的内存页,不能移动,但是可以直接回收,比如文件缓存页,它们就可以直接被回收掉,当再次需要的时候可以从磁盘中读取生成。或者一些生命周期比较短的内存页,比如 DMA 缓存区中的内存页也是可以被直接回收掉。

kmalloc 内存池的整体架构
kmalloc 内存池的本质其实还是 slab 内存池,底层依赖于 slab alloactor 体系,在 kmalloc 体系的内部,管理了多个不同尺寸的 slab cache,kmalloc 只不过负责根据内核申请的内存块尺寸大小来选取一个最佳合适尺寸的 slab cache。
最终内存块的分配和释放还需要由底层的 slab cache 来负责,经过前两个小节的介绍,现在我们已经对 kmalloc 内存池架构有了一个初步的认识。

其中 kmalloc 支持的最小内存块尺寸为:2^KMALLOC_SHIFT_LOW,在 slub 实现中 KMALLOC_SHIFT_LOW = 3,kmalloc 支持的最小内存块尺寸为 8 字节大小。
kmalloc 支持的最大内存块尺寸为:2^KMALLOC_SHIFT_HIGH,在 slub 实现中 KMALLOC_SHIFT_HIGH = 13,kmalloc 支持的最大内存块尺寸为 8K ,也就是两个内存页大小。
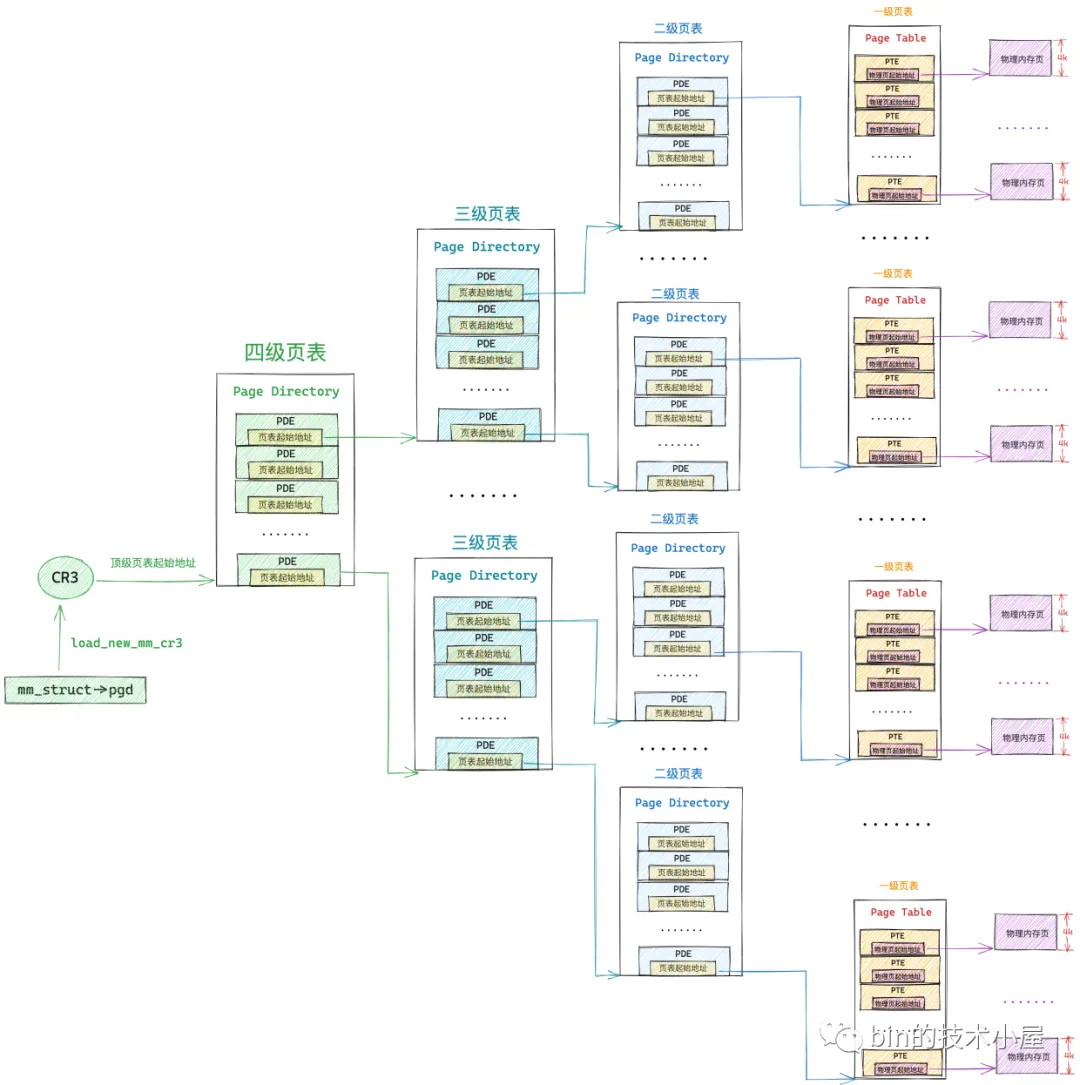
虚拟内存到物理内存的映射
cr3 寄存器中存放的是当前进程顶级页表 pgd 的物理内存地址,不能是虚拟内存地址。
进程的上下文在内核中完成切换之后,现在 cr3 寄存器中保存的就是当前进程顶级页表的起始物理内存地址了,当 CPU 通过下图所示的虚拟内存地址访问进程的虚拟内存时,CPU 首先会从 cr3 寄存器中获取到当前进程的顶级页表起始地址,然后从虚拟内存地址中提取出虚拟内存页对应 PTE 在页表内的偏移,通过 页表起始地址 + 页表内偏移 * sizeof(PTE) 这个公式定位到虚拟内存页在页表中所对应的 PTE。

四级页表
但是在内核中一般不这么叫,内核中称上图中的四级页表为全局页目录 PGD(Page Global Directory),PGD 中的页目录项叫做 pgd_t,PGD 是四级页表体系下的顶级页表,保存在进程 struct mm_struct 结构中的 pgd 属性中,在进程调度上下文切换的时候,由内核通过 load_new_mm_cr3 方法将 pgd 中保存的顶级页表虚拟内存地址转换物理内存地址,随后加载到 cr3 寄存器中,从而完成进程虚拟内存空间的切换。
上图中的三级页表在内核中称之为上层页目录 PUD(Page Upper Directory),PUD 中的页目录项叫做 pud_t 。
二级页表在这里也改了一个名字叫做中间页目录 PMD(Page Middle Directory),PMD 中的页目录项叫做 pmd_t,最底层的用来直接映射物理内存页面的一级页表,名字不变还叫做页表(Page Table)
由于在四级页表体系下,又多引入了两层页目录(PGD,PUD),所以导致其通过虚拟内存地址定位 PTE 的步骤又增加了两步,首先需要定位顶级页表 PGD 中的页目录项 pgd_t,pgd_t 指向的 PUD 的起始内存地址,然后在定位 PUD 中的页目录项 pud_t,后面的流程就和二级页表一样了。


PAGE_SHIFT 用来表示页表中的一个 PTE 可以映射的物理内存大小(4K)。
PMD_SHIFT 用来表示 PMD 中的一个页目录项 pmd_t 可以映射的物理内存大小(2M)。
PUD_SHIFT 用来表示 PUD 中的一个页目录项 pud_t 可以映射的物理内存大小(1G)。
PGD_SHIFT 用来表示 PGD 中的一个页目录项 pgd_t 可以映射的物理内存大小(512G)。
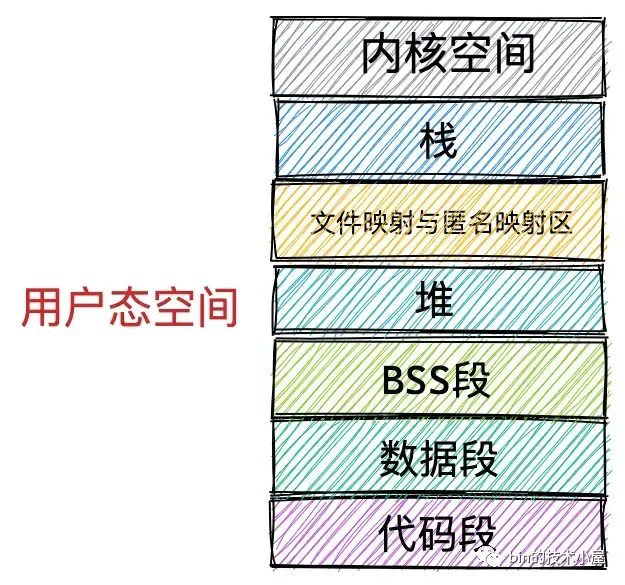
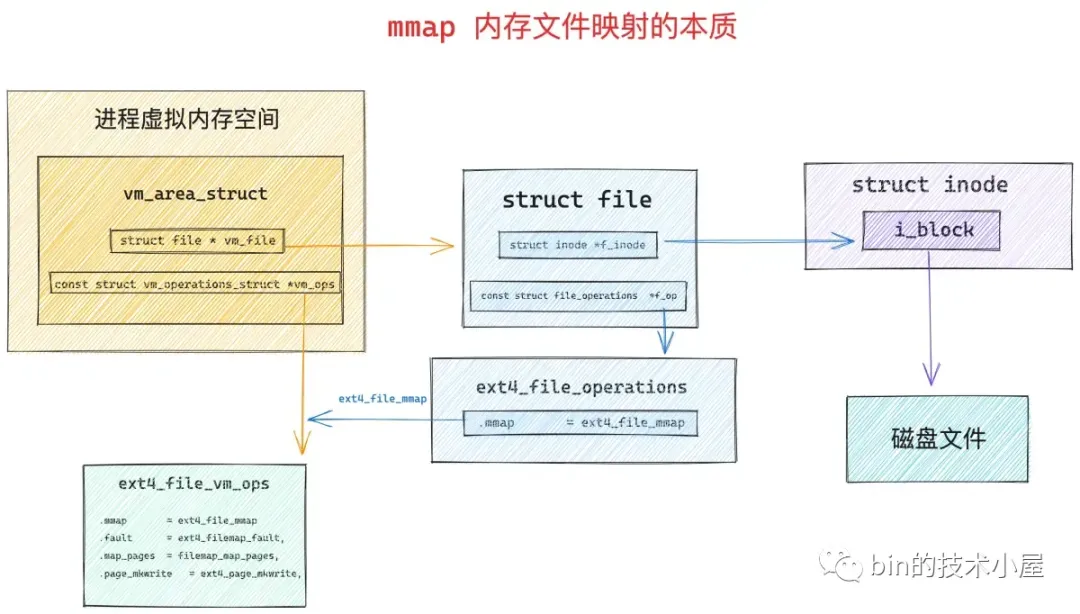
mmap原理
在进程虚拟内存空间的布局中,有一段叫做文件映射与匿名映射区的虚拟内存区域,当我们在用户态应用程序中调用 mmap 进行内存映射的时候,所需要的虚拟内存就是在这个区域中划分出来的。

如果我们通过 mmap 映射的是磁盘上的一个文件,那么就需要通过参数 fd 来指定要映射文件的描述符(file descriptor),通过参数 offset 来指定文件映射区域在文件中偏移。

struct vm_area_struct
1 | |


私有匿名映射

私有文件映射



多进程读取文件映射区域

多进程改写文件映射区域

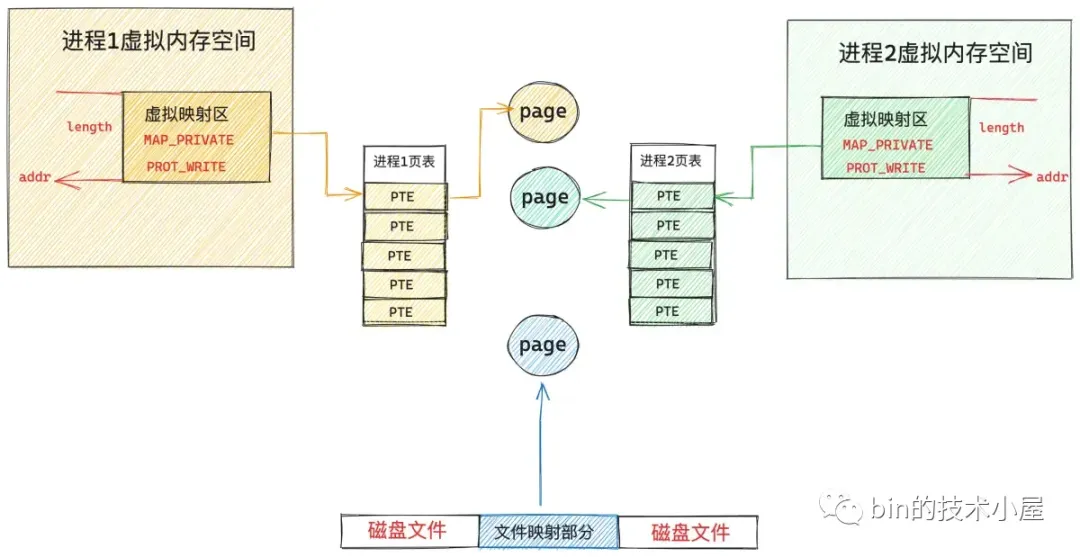
进程 1 和进程 2 对各自虚拟内存区的修改只能反应到各自对应的物理内存页上,而且各自的修改在进程之间是互不可见的,最重要的一点是这些修改均不会回写到磁盘文件中,这就是私有文件映射的核心特点。
代码段和数据段

共享文件映射

共享匿名映射

大页内存映射
标准大页
在 64 位 x86 CPU 架构 Linux 的四级页表体系下,系统支持的大页尺寸有 2M,1G。
大页内存也不允许被 swap。而且内核大页池中的这些大页内存使用完了就完了,大页池耗尽之后,应用程序将无法再使用大页。
hugetlbfs 内存文件系统
hugetlbfs 是一个基于内存的文件系统,类似前边介绍的 tmpfs 文件系统,位于 hugetlbfs 文件系统下的所有文件都是被大页支持的,也就说通过 mmap 对 hugetlbfs 文件系统下的文件进行文件映射,默认都是用 HugePage 进行映射。
hugetlbfs 下的文件支持大多数的文件系统操作,比如:open , close , chmod , read 等等,但是不支持 write 系统调用,如果想要对 hugetlbfs 下的文件进行写入操作,那么必须通过文件映射的方式将 hugetlbfs 中的文件通过大页映射进内存,然后在映射内存中进行写入操作。
所以在我们使用 mmap 系统调用对 hugetlbfs 下的文件进行大页映射之前,首先需要做的事情就是在系统中挂载 hugetlbfs 文件系统到指定的路径下。
1 | |
只有在 hugetlbfs 下的文件进行 mmap 文件映射的时候才能使用大页,其他普通文件系统下的文件依然只能映射普通 4K 内存页。
当 hugetlbfs 被我们挂载好之后,接下来我们就可以直接通过 mmap 系统调用对挂载目录 /mnt/huge 下的文件进行内存映射了,当缺页的时候,内核会直接分配大页,大页尺寸是 pagesize。
1 | |
这里需要注意是,通过 mmap 映射 hugetlbfs 中的文件的时候,并不需要指定 MAP_HUGETLB 。而我们通过 SYSV 标准的系统调用 shmget 和 shmat 以及前边介绍的 mmap ( flags 参数设置 MAP_HUGETLB)进行大页申请的时候,并不需要挂载 hugetlbfs。
透明大页
透明大页的使用对用户完全是透明的,内核会在背后为我们自动做大页的映射,透明大页不需要像标准大页那样需要提前预先分配好大页内存池,透明大页的分配是动态的,由内核线程 khugepaged 负责在背后默默地将普通 4K 内存页整理成内存大页给进程使用。但是如果由于内存碎片的因素,内核无法整理出内存大页,那么就会降级为使用普通 4K 内存页。但是透明大页这里会有一个问题,当碎片化严重的时候,内核会启动 kcompactd 线程去整理碎片,期望获得连续的内存用于大页分配,但是 compact 的过程可能会引起 sys cpu 飙高,应用程序卡顿。
透明大页是允许 swap 的,这一点和标准大页不同,在内存紧张需要 swap 的时候,透明大页会被内核默默拆分成普通 4K 内存页,然后 swap out 到磁盘。
透明大页只支持 2M 的大页,标准大页可以支持 1G 的大页,透明大页主要应用于匿名内存中,可以在 tmpfs 文件系统中使用。
Page Faults
无论是匿名映射还是文件映射,内核在处理 mmap 映射过程中貌似都是在进程的虚拟地址空间中和虚拟内存打交道,仅仅只是为 mmap 映射分配出一段虚拟内存而已,整个映射过程我们并没有看到物理内存的身影。
1. 缺页中断产生的原因

当 CPU 访问这段由 mmap 映射出来的虚拟内存区域 vma 中的任意虚拟地址时,MMU 在遍历进程页表的时候就会发现,该虚拟内存地址在进程顶级页目录 PGD(Page Global Directory)中对应的页目录项 pgd_t 是空的,该 pgd_t 并没有指向其下一级页目录 PUD(Page Upper Directory)。
也就是说,此时进程页表中只有一张顶级页目录表 PGD,而上层页目录 PUD(Page Upper Directory),中间页目录 PMD(Page Middle Directory),一级页表(Page Table)内核都还没有创建。
由于现在被访问到的虚拟内存地址对应的 pgd_t 是空的,进程的四级页表体系还未建立,所以 MMU 会产生一个缺页中断,进程从用户态转入内核态来处理这个缺页异常。
此时 CPU 会将发生缺页异常时,进程正在使用的相关寄存器中的值压入内核栈中。比如,引起进程缺页异常的虚拟内存地址会被存放在 CR2 寄存器中。同时 CPU 还会将缺页异常的错误码 error_code 压入内核栈中。
随后内核会在 do_page_fault 函数中来处理缺页异常,该函数的参数都是内核在处理缺页异常的时候需要用到的基本信息:
2. 内核处理缺页中断的入口 —— do_page_fault
缺页中断产生的根本原因是由于 CPU 访问的这段虚拟内存背后没有物理内存与之映射,表现的具体形式主要有三种:
虚拟内存对应在进程页表体系中的相关各级页目录或者页表是空的,也就是说这段虚拟内存完全没有被映射过。
虚拟内存之前被映射过,其在进程页表的各级页目录以及页表中均有对应的页目录项和页表项,但是其对应的物理内存被内核 swap out 到磁盘上了。
虚拟内存虽然背后映射着物理内存,但是由于对物理内存的访问权限不够而导致的保护类型的缺页中断。比如,尝试去写一个只读的物理内存页。
进程在使用 mmap 申请内存的时候,内核仅仅只是为进程在文件映射与匿名映射区分配一段虚拟内存,重要的物理内存资源不会马上分配,而是延迟到进程真正使用的时候,才会通过缺页中断 __do_page_fault 进入到 do_user_addr_fault 分支进行物理内存资源的分配。
内核空间中的缺页异常主要发生在进程内核虚拟地址空间中 32T 的 vmalloc 映射区,这段区域的虚拟内存地址范围为:0xFFFF C900 0000 0000 - 0xFFFF E900 0000 0000。内核中的 vmalloc 内存分配接口就工作在这个区域,它用于将那些不连续的物理内存映射到连续的虚拟内存上。
3. 内核态缺页异常处理 —— do_kern_addr_fault
do_kern_addr_fault 函数的工作主要就是处理内核虚拟内存空间中 vmalloc 映射区里的缺页异常,这一部分内容,笔者会在 vmalloc_fault 函数中进行介绍。
读到这里,大家可能会有一个疑惑,作者你刚刚不是才说了吗,工作在内核就相当于工作在公司的核心部门,要什么资源公司就会给什么资源,在内核空间申请虚拟内存的时候,都会马上分配物理内存资源,而且申请多少给多少。
既然物理内存会马上被分配,那为什么内核空间中的 vmalloc 映射区还会发生缺页中断呢 ?
事实上,内核空间里 vmalloc 映射区中发生的缺页中断与用户空间里文件映射与匿名映射区以及堆中发生的缺页中断是不一样的。
进程在用户空间中无论是通过 brk 系统调用在堆中申请内存还是通过 mmap 系统调用在文件与匿名映射区中申请内存,内核都只是在相应的虚拟内存空间中划分出一段虚拟内存来给进程使用。
当进程真正访问到这段虚拟内存地址的时候,才会产生缺页中断,近而才会分配物理内存,最后将引起本次缺页的虚拟地址在进程页表中对应的全局页目录项 pgd,上层页目录项 pud,中间页目录 pmd,页表项 pte 都创建好,然后在 pte 中将虚拟内存地址与物理内存地址映射起来。
而内核通过 vmalloc 内存分配接口在 vmalloc 映射区申请内存的时候,首先也会在 32T 大小的 vmalloc 映射区中划分出一段未被使用的虚拟内存区域出来,我们暂且叫这段虚拟内存区域为 vmalloc 区,这一点和前面文章介绍的 mmap 非常相似,只不过 mmap 工作在用户空间的文件与匿名映射区,vmalloc 工作在内核空间的 vmalloc 映射区。
内核空间中的 vmalloc 映射区就是由这样一段一段的 vmalloc 区组成的,每调用一次 vmalloc 内存分配接口,就会在 vmalloc 映射区中映射出一段 vmalloc 虚拟内存区域,而且每个 vmalloc 区之间隔着一个 4K 大小的 guard page(虚拟内存),用于防止内存越界,将这些非连续的物理内存区域隔离起来。

和 mmap 不同的是,vmalloc 在分配完虚拟内存之后,会马上为这段虚拟内存分配物理内存,内核会首先计算出由 vmalloc 内存分配接口映射出的这一段虚拟内存区域 vmalloc 区中包含的虚拟内存页数,然后调用伙伴系统依次为这些虚拟内存页分配物理内存页。
3.1 vmalloc
下面是 vmalloc 内存分配的核心逻辑,封装在 __vmalloc_node_range 函数中:
1 | |
3.2 struct vmap_area
1 | |
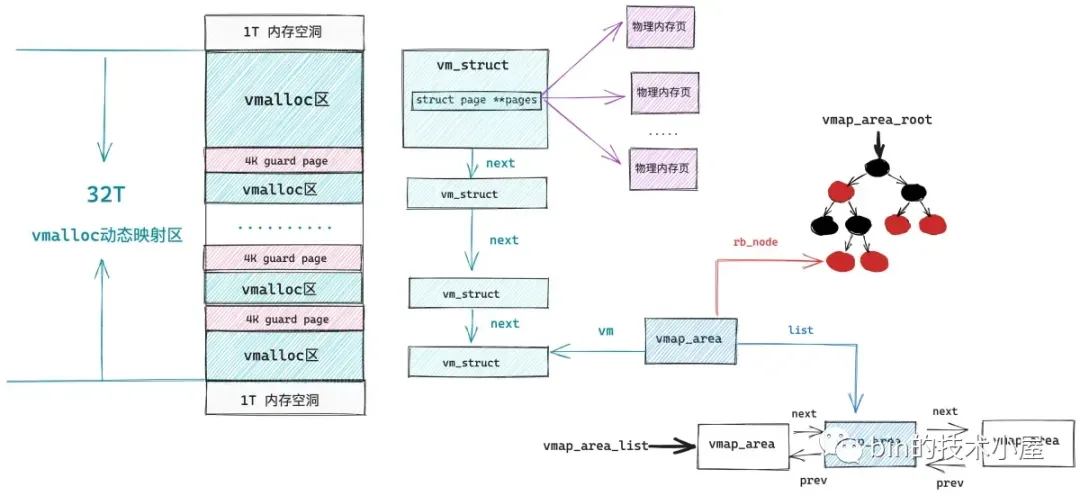
看起来和用户空间中虚拟内存区域的组织形式越来越像了,不同的是由于用户空间是进程间隔离的,所以组织用户空间虚拟内存区域的红黑树以及双向链表是进程独占的。
在我们了解了 vmalloc 动态映射区中的相关数据结构与组织形式之后,接下来我们看一看为 vmalloc 区分配物理内存的过程:
1 | |
在内核中,凡是有物理内存出现的地方,就一定伴随着页表的映射,vmalloc 也不例外,当分配完物理内存之后,就需要修改内核页表,然后将物理内存映射到 vmalloc 虚拟内存区域中,当然了,这个过程也伴随着 vmalloc 区域中的这些虚拟内存地址在内核页表中对应的 pgd,pud,pmd,pte 相关页目录项以及页表项的创建。
3.4 vmalloc_fault
当内核通过 vmalloc 内存分配接口修改完内核主页表之后,主页表中的相关页目录项以及页表项的内容就发生了改变,而这背后的一切,进程现在还被蒙在鼓里,一无所知,此时,进程页表中的内核部分相关的页目录项以及页表项还都是空的。

当进程陷入内核态访问这部分页表的的时候,会发现相关页目录或者页表项是空的,就会进入缺页中断的内核处理部分,也就是前面提到的 vmalloc_fault 函数中,如果发现缺页的虚拟地址在内核主页表顶级全局页目录表中对应的页目录项 pgd 存在,而缺页地址在进程页表内核部分对应的 pgd 不存在,那么内核就会把内核主页表中 pgd 页目录项里的内容复制给进程页表内核部分中对应的 pgd。

事实上,同步内核主页表的工作只需要将缺页地址对应在内核主页表中的顶级全局页目录项 pgd 同步到进程页表内核部分对应的 pgd 地址处就可以了,正如上图中所示,每一级的页目录项中存放的均是其下一级页目录表的物理内存地址。
4. 用户态缺页异常处理 —— do_user_addr_fault
进程用户态虚拟地址空间的布局我们现在已经非常熟悉了,在处理用户态缺页异常之前,内核需要在进程用户空间众多的虚拟内存区域 vma 之中找到引起缺页的内存地址 address 究竟是属于哪一个 vma 。如果没有一个 vma 能够包含 address , 那么就说明该 address 是一个还未被分配的虚拟内存地址,进程对该地址的访问是非法的,自然也就不用处理缺页了。

5. handle_mm_fault 完善进程页表体系
饶了一大圈,现在我们终于来到了缺页处理的核心逻辑,之前笔者提到,引起缺页中断的原因大概有三种:
第一种是 CPU 访问的虚拟内存地址 address 之前完全没有被映射过,其在页表中对应的各级页目录项以及页表项都还是空的。
第二种是 address 之前被映射过,但是映射的这块物理内存被内核 swap out 到磁盘上了。
第三种是 address 背后映射的物理内存还在,只是由于访问权限不够引起的缺页中断,比如,后面要为大家介绍的写时复制(COW)机制就属于这一种。
6. handle_pte_fault
handle_pte_fault 是 Linux 内核中处理页表项故障(Page Table Entry Fault)的关键函数之一。当用户空间程序试图访问一个虚拟地址,但该地址对应的页表项不存在、不可访问或者无效时,就会触发页表项故障。

1 | |
7. do_anonymous_page 处理匿名页缺页
do_anonymous_page 是 Linux 内核中处理匿名页缺页的关键函数之一。当用户空间程序访问的页面是匿名页,但该页面的数据尚未加载到内存中时,就会触发缺页异常。do_anonymous_page 函数负责处理这种情况,即为进程分配一个新的物理页框,并将匿名页的数据加载到该物理页框中。
1 | |
8. do_fault 处理文件页缺页
do_fault 是 Linux 内核中处理文件页缺页的关键函数之一。当进程访问的虚拟地址对应的页面不在内存中时,会触发缺页异常,do_fault 函数负责处理这种情况,从文件系统中将相应的页面加载到内存中。
1 | |
上述伪代码展示了 do_fault 函数的基本逻辑。具体步骤包括:
检查地址是否在虚拟内存区域范围内,确保地址有效。
根据虚拟地址从文件系统中加载页面,通常是通过调用 filemap_fault 函数来实现的,该函数会从文件中读取相应的数据并创建页面对象。
将加载的页面插入到进程的页表中,通常是通过调用 handle_pte_fault 函数来实现的,该函数会将页面映射到虚拟地址空间中的正确位置。
如果插入页面失败,则释放页面并返回错误码;如果成功,则返回0表示处理成功。
8.1 do_read_fault 处理读操作引起的缺页
以下是处理读操作引起的缺页(do_read_fault)的关键伪代码:
1 | |
在上述伪代码中:
- do_read_fault 函数负责处理读操作引起的缺页。
- 首先,它尝试从虚拟内存区域(VMA)中获取对应的文件页,如果文件页不存在,则需要从文件系统中读取内容并填充到页中。
- 然后,将页面映射到页表中,以使得用户空间进程可以继续访问该页面。
- 最后,返回到用户空间,用户空间进程可以继续执行。
8.2 do_cow_fault 处理私有文件映射的写时复制
以下是处理私有文件映射的写时复制(do_cow_fault)的关键伪代码:
1 | |
在上述伪代码中:
- do_cow_fault 函数负责处理私有文件映射的写时复制。
- 首先,它尝试从虚拟内存区域(VMA)中获取对应的文件页。
- 然后,检查页面是否被写保护,如果没有,则表示页面未被修改,直接返回。
- 如果页面是私有的,并且不是共享页面或者交换缓存页面,则需要进行写时复制。它分配一个新的页面,并将原始页面的内容复制到新页面中。然后,替换VMA中的页表项,将新页面映射到页表中。
- 最后,返回到用户空间,用户空间进程可以继续执行。
8.3 do_shared_fault 处理对共享文件映射区写入引起的缺页
以下是处理对共享文件映射区写入引起的缺页(do_shared_fault)的关键伪代码:
1 | |
在上述伪代码中:
- do_shared_fault 函数负责处理对共享文件映射区写入引起的缺页。
- 首先,它尝试从虚拟内存区域(VMA)中获取对应的文件页。
- 然后,检查页面是否被写保护,如果没有,则表示页面未被修改,直接返回。
- 如果页面是共享的,则需要进行写时复制。它创建一个写时复制页面,并将其映射到VMA中,以确保对共享页面的写入不会影响到其他进程。
- 最后,返回到用户空间,用户空间进程可以继续执行。
9. do_wp_page 进行写时复制
do_wp_page 函数用于进行写时复制(Copy-On-Write)操作,通常在处理写入操作时发生缺页时调用。以下是 do_wp_page 的关键伪代码:
1 | |
在上述伪代码中:
- do_wp_page 函数负责处理写入操作引起的缺页,并执行写时复制操作。
- 首先,它尝试从虚拟内存区域(VMA)中获取对应的文件页。
- 然后,检查页面是否是私有的,并且是否被写保护。
- 如果页面是私有的并且被写保护,则进行写时复制。它分配一个新的页面,并将原始页面的内容复制到新页面中。然后,替换VMA中的页表项,将新页面映射到页表中。
- 最后,返回新页面,表示写时复制操作成功。
10. do_swap_page 处理 swap 缺页异常
如果在遍历进程页表的时候发现,虚拟内存地址 address 对应的页表项 pte 不为空,但是 pte 中第 0 个比特位置为 0 ,则表示该 pte 之前是被物理内存映射过的,只不过后来被内核 swap out 出去了。
我们需要的物理内存页不在内存中反而在磁盘中,现在我们就需要将物理内存页从磁盘中 swap in 进来。但在 swap in 之前内核需要知道该物理内存页的内容被保存在磁盘的什么位置上。

64 位的 pte 主要用来表示物理内存页的地址以及相关的权限标识位,但是当物理内存页不在内存中的时候,这些比特位就没有了任何意义。我们何不将这些已经没有任何意义的比特位利用起来,在物理内存页被 swap out 到磁盘上的时候,将物理内存页在磁盘上的位置保存在这些比特位中。本质上还利用的是之前 pte 中的那 64 个比特,为了区别 swap 的场景,内核使用了一个新的结构体 swp_entry_t 来包装。
swap in 的首要任务就是先要从进程页表中将这个 swp_entry_t 读取出来,然后从 swp_entry_t 中解析出内存页在 swap 交换区中的位置,根据磁盘位置信息将内存页的内容读取到内存中。由于产生了新的物理内存页,所以就要创建新的 pte 来映射这个物理内存页,然后将新的 pte 设置到页表中,替换原来的 swp_entry_t。
这里笔者需要为大家解释的第一个问题就是 —— 这个 swp_entry_t 究竟是长什么样子 的,它是如何保存 swap 交换区相关位置信息的 ?
10.1 交换区的布局及其组织结构
swap_info_struct 结构用于描述单个交换区中的各种信息:
1 | |
而在每个交换区 swap area 内部又会分为很多连续的 slot (槽),每个 slot 的大小刚好和一个物理内存页的大小相同都是 4K,物理内存页在被 swap out 到交换区时,就会存放在 slot 中。
交换区中的这些 slot 会被组织在一个叫做 swap_map 的数组中,数组中的索引就是 slot 在交换区中的 offset (这个位置信息很重要),数组中的值表示该 slot 总共被多少个进程同时引用。
什么意思呢 ? 比如现在系统中一共有三个进程同时共享一个物理内存页(内存中的概念),当这个物理内存页被 swap out 到交换区上时,就变成了 slot (内存页在交换区中的概念),现在物理内存页没了,这三个共享进程就只能在各自的页表中指向这个 slot,因此该 slot 的引用计数就是 3,对应在数组 swap_map 中的值也是 3 。

SWAPFILE_CLUSTER

slot 与连续的磁盘块组的映射关系保存在 swap_extent 结构中:

10.2 一睹 swp_entry_t 真容
匿名内存页在被内核 swap out 到磁盘上之后,内存页中的内容保存在交换区的 slot 中,在 swap in 的场景中,内核需要根据 swp_entry_t 里的信息找到这个 slot,进而找到其对应的磁盘块,然后从磁盘块中读取出被 swap out 出去的内容。
这个就和交换区的布局有很大的关系,首先系统中存在多个交换区,这些交换区被内核组织在 swap_info 数组中。
10.3 swap cache
有了 swap cache 之后,情况就会变得大不相同,我们在回过头来看第一个问题 —— 多进程共享内存页。
进程1 在 swap in 的时候首先会到 swap cache 中去查找,看看是否有其他进程已经把内存页 swap in 进来了,如果 swap cache 中没有才会调用 swap_readpage 从磁盘中去读取。
当内核通过 swap_readpage 将内存页中的内容从磁盘中读取进内存之后,内核会把这个匿名页先放入 swap cache 中。进程 1 的页表将原来的 swp_entry_t 填充为 pte 并指向 swap cache 中的这个内存页。




10.4 swap 预读
现在我们已经清楚了当进程虚拟内存空间中的某一段 vma 发生 swap 缺页异常之后,内核的 swap in 核心处理流程。但是整个完整的 swap 流程还没有结束,内核还需要考虑内存访问的空间局部性原理。
当进程访问某一段内存的时候,在不久之后,其附近的内存地址也将被访问。对应于本小节的 swap 场景来说,当进程地址空间中的某一个虚拟内存地址 address 被访问之后,那么其周围的虚拟内存地址在不久之后,也会被进程访问。
而那些相邻的虚拟内存地址,在进程页表中对应的页表项也都是相邻的,当我们处理完了缺页地址 address 的 swap 缺页异常之后,如果其相邻的页表项均是 swp_entry_t,那么这些相邻的 swp_entry_t 所指向交换区的内容也需要被内核预读进内存中。
这样一来,当 address 附近的虚拟内存地址发生 swap 缺页的时候,内核就可以直接从 swap cache 中读到了,避免了磁盘 IO,使得 swap in 可以快速完成,这里和文件的预读机制有点类似。
swap 预读在 Linux 内核中由 swapin_readahead 函数负责,它有两种实现方式:
第一种是根据缺页地址 address 周围的虚拟内存地址进行预读,但前提是它们必须属于同一个 vma,这个逻辑在 swap_vma_readahead 函数中完成。
第二种是根据内存页在交换区中周围的磁盘地址进行预读,但前提是它们必须属于同一个交换区,这个逻辑在 swap_cluster_readahead 函数中完成。
10.5 还原 do_swap_page 完整面貌
当我们明白了前面介绍的这些背景知识之后,再回过头来看内核完整的 swap in 过程就很清晰了
首先内核会通过 pte_to_swp_entry 将进程页表中的 pte 转换为 swp_entry_t
通过 lookup_swap_cache 根据 swp_entry_t 到 swap cache 中查找是否已经有其他进程将内存页 swap 进来了。
如果 swap cache 没有对应的内存页,则调用 swapin_readahead 启动预读,在这个过程中,内核会重新分配物理内存页,并将这个物理内存页加入到 swap cache 中,随后通过 swap_readpage 将交换区的内容读取到这个内存页中。
现在我们需要的内存页已经 swap in 到内存中了,后面的流程就和普通的缺页处理一样了,根据 swap in 进来的内存页地址重新创建初始化一个新的 pte,然后用这个新的 pte,将进程页表中原来的 swp_entry_t 替换掉。
为新的内存页建立反向映射关系,加入 lru active list 中,最后 swap_free 释放交换区中的资源。

中断
这段文字概述了第10章《中断与时钟》的主要内容,主要涵盖了中断和定时器在Linux设备驱动编程中的重要性以及相应的处理流程和机制。以下是对每个小节的简要解释:
10.1 节 - 中断和定时器的概念及处理流程:
- 中断和定时器概念: 介绍中断和定时器的基本概念,以及它们在Linux设备驱动中的作用。
- 处理流程: 概述中断和定时器的处理流程,强调中断服务程序需要尽量短暂,因为它执行在非进程上下文中。
10.2 节 - Linux中断处理程序的架构和顶半部、底半部之间的关系:
- 中断处理程序架构: 解释Linux中断处理程序的整体架构,包括中断处理的两个主要部分:顶半部(Top Half)和底半部(Bottom Half)。
- 顶半部和底半部: 讨论顶半部和底半部之间的关系,强调它们的划分是为了确保中断服务程序的执行时间尽量短。
10.3 节 - Linux中断编程的方法:
- 中断编程方法: 探讨Linux中断编程的方法,包括中断的申请和释放、中断的使能和屏蔽,以及介绍中断底半部相关的概念,如tasklet、工作队列、软中断机制和threaded_irq。
10.4 节 - 多个设备共享同一个中断号时的中断处理过程:
- 中断处理过程: 解释当多个设备共享同一个中断号时,Linux中的中断处理过程,包括中断的共享机制和相应的处理策略。
10.5 节和 10.6 节 - 定时器的编程和内核延时的方法:
- 定时器编程: 介绍Linux设备驱动编程中定时器的编程方法。
- 内核延时: 探讨在Linux内核中实现延时的方法,强调内核软件定时器最终依赖于时钟中断。
这些主题涵盖了在Linux设备驱动编程中涉及中断和定时器的核心概念、架构和编程方法。理解这些内容对于设计和实现高效、稳定的设备驱动程序至关重要。

- 硬件层:最下层为硬件连接层,对应的是具体的外设与SoC的物理连接,中断信号是从外设到中断控制器,由中断控制器统一管理,再路由到处理器上;
- 硬件相关层:这个层包括两部分代码,一部分是架构相关的,比如ARM64处理器处理中断相关,另一部分是中断控制器的驱动代码;
- 通用层:这部分也可以认为是框架层,是硬件无关层,这部分代码在所有硬件平台上是通用的;
- 用户层:这部分也就是中断的使用者了,主要是各类设备驱动,通过中断相关接口来进行申请和注册,最终在外设触发中断时,进行相应的回调处理;
中断子系统系列文章,会包括硬件相关、中断框架层、上半部与下半部、Softirq、Workqueue等机制的介绍,本文会先介绍硬件相关的原理及驱动,前戏结束,直奔主题。
GIC硬件原理
ARM公司提供了一个通用的中断控制器GIC(Generic Interrupt Controller),GIC的版本包括V1 ~ V4,由于本人使用的SoC中的中断控制器是V2版本,本文将围绕GIC-V2来展开介绍;
来一张功能版的框图:

- GIC-V2从功能上说,除了常用的中断使能、中断屏蔽、优先级管理等功能外,还支持安全扩展、虚拟化等;
- GIC-V2从组成上说,主要分为Distributor和CPU Interface两个模块,Distributor主要负责中断源的管理,包括优先级的处理,屏蔽、抢占等,并将最高优- 先级的中断分发给CPU Interface,CPU Interface主要用于连接处理器,与处理器进行交互;
- Virtual Distributor和Virtual CPU Interface都与虚拟化相关,本文不深入分析;
再来一张细节图看看Distributor和CPU Interface的功能:

GIC-V2支持三种类型的中断:
SGI(software-generated interrupts):软件产生的中断,主要用于核间交互,内核中的IPI:inter-processor interrupts就是基于SGI,中断号ID0 - ID15用于SGI;
PPI(Private Peripheral Interrupt):私有外设中断,每个CPU都有自己的私有中断,典型的应用有local timer,中断号ID16 - ID31用于PPI;
SPI(Shared Peripheral Interrupt):共享外设中断,中断产生后,可以分发到某一个CPU上,中断号ID32 - ID1019用于SPI,ID1020 - ID1023保留用于特殊用途;
Distributor功能:
- 全局开关控制Distributor分发到CPU Interface;
- 打开或关闭每个中断;
- 设置每个中断的优先级;
- 设置每个中断将路由的CPU列表;
- 设置每个外设中断的触发方式:电平触发、边缘触发;
- 设置每个中断的Group:Group0或Group1,其中Group0用于安全中断,支持FIQ和IRQ,Group1用于非安全中断,只支持IRQ;
- 将SGI中断分发到目标CPU上;
- 每个中断的状态可见;
- 提供软件机制来设置和清除外设中断的pending状态;
CPU Interface功能:
- 使能中断请求信号到CPU上;
- 中断的确认;
- 标识中断处理的完成;
- 为处理器设置中断优先级掩码;
- 设置处理器的中断抢占策略;
- 确定处理器的最高优先级pending中断;
中断处理的状态机如下图:

- Inactive:无中断状态;
- Pending:硬件或软件触发了中断,但尚未传递到目标CPU,在电平触发模式下,产生中断的同时保持pending状态;
- Active:发生了中断并将其传递给目标CPU,并且目标CPU可以处理该中断;
- Active and pending:发生了中断并将其传递给目标CPU,同时发生了相同的中断并且该中断正在等待处理;
GIC检测中断流程如下:
- GIC捕获中断信号,中断信号assert,标记为pending状态;
- Distributor确定好目标CPU后,将中断信号发送到目标CPU上,同时,对于每个CPU,Distributor会从pending信号中选择最高优先级中断发送至CPU Interface;
- CPU Interface来决定是否将中断信号发送至目标CPU;
- CPU完成中断处理后,发送一个完成信号EOI(End of Interrupt)给GIC;
GIC驱动分析
设备信息添加
ARM平台的设备信息,都是通过Device Tree设备树来添加,设备树信息放置在arch/arm64/boot/dts/下
下图就是一个中断控制器的设备树信息:

- compatible字段:用于与具体的驱动来进行匹配,比如图片中arm, gic-400,可以根据这个名字去匹配对应的驱动程序;
- interrupt-cells字段:用于指定编码一个中断源所需要的单元个数,这个值为3。比如在外设在设备树中添加中断信号时,通常能看到类似interrupts = <0 23 4>;的信息,第一个单元0,表示的是中断类型(1:PPI,0:SPI),第二个单元23表示的是中断号,第三个单元4表示的是中断触发的类型;
- reg字段:描述中断控制器的地址信息以及地址范围,比如图片中分别制定了GIC Distributor(GICD)和GIC CPU Interface(GICC)的地址信息;
- interrupt-controller字段:表示该设备是一个中断控制器,外设可以连接在该中断控制器上;
- 关于设备数的各个字段含义,详细可以参考Documentation/devicetree/bindings下的对应信息;
设备树的信息,是怎么添加到系统中的呢?Device Tree最终会编译成dtb文件,并通过Uboot传递给内核,在内核启动后会将dtb文件解析成device_node结构。关于设备树的相关知识,本文先不展开,后续再找机会补充。来一张图,先简要介绍下关键路径:

- 设备树的节点信息,最终会变成device_node结构,在内存中维持一个树状结构;
- 设备与驱动,会根据compatible字段进行匹配;
驱动流程分析
GIC驱动的执行流程如下图所示:

- 首先需要了解一下链接脚本vmlinux.lds,脚本中定义了一个__irqchip_of_table段,该段用于存放中断控制器信息,用于最终来匹配设备;
- 在GIC驱动程序中,使用IRQCHIP_DECLARE宏来声明结构信息,包括compatible字段和回调函数,该宏会将这个结构放置到__irqchip_of_table字段中;
- 在内核启动初始化中断的函数中,of_irq_init函数会去查找设备节点信息,该函数的传入参数就是__irqchip_of_table段,由于IRQCHIP_DECLARE已经将信息填充好了,of_irq_init函数会根据arm,gic-400去查找对应的设备节点,并获取设备的信息。中断控制器也存在级联的情况,of_irq_init函数中也处理了这种情况;
- or_irq_init函数中,最终会回调IRQCHIP_DECLARE声明的回调函数,也就是gic_of_init,而这个函数就是GIC驱动的初始化入口函数了;
- GIC的工作,本质上是由中断信号来驱动,因此驱动本身的工作就是完成各类信息的初始化,注册好相应的回调函数,以便能在信号到来之时去执行;
- set_smp_process_call设置__smp_cross_call函数指向gic_raise_softirq,本质上就是通过软件来触发GIC的SGI中断,用于核间交互;
- cpuhp_setup_state_nocalls函数,设置好CPU进行热插拔时GIC的回调函数,以便在CPU热插拔时做相应处理;
- set_handle_irq函数的设置很关键,它将全局函数指针handle_arch_irq指向了gic_handle_irq,而处理器在进入中断异常时,会跳转到handle_arch_irq执行,所以,可以认为它就是中断处理的入口函数了;
- 驱动中完成了各类函数的注册,此外还完成了irq_chip, irq_domain等结构体的初始化,这些结构在下文会进一步分析;
- 最后,完成GIC硬件模块的初始化设置,以及电源管理相关的注册等工作;
数据结构分析
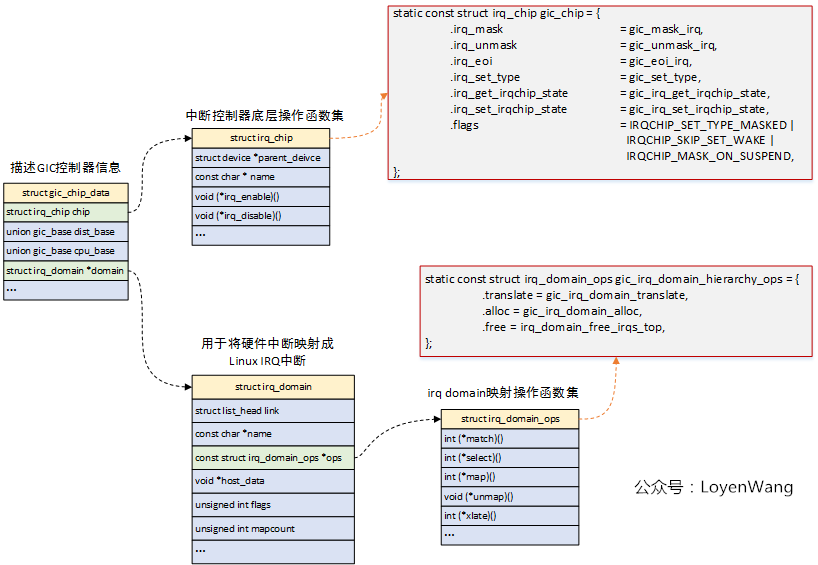
- GIC驱动中,使用struct gic_chip_data结构体来描述GIC控制器的信息,整个驱动都是围绕着该结构体的初始化,驱动中将函数指针都初始化好,实际的工作是由中断信号触发,也就是在中断来临的时候去进行回调;
- struct irq_chip结构,描述的是中断控制器的底层操作函数集,这些函数集最终完成对控制器硬件的操作;
- struct irq_domain结构,用于硬件中断号和Linux IRQ中断号(virq,虚拟中断号)之间的映射;
IRQ domain
IRQ domain用于将硬件的中断号,转换成Linux系统中的中断号(virtual irq, virq),来张图:
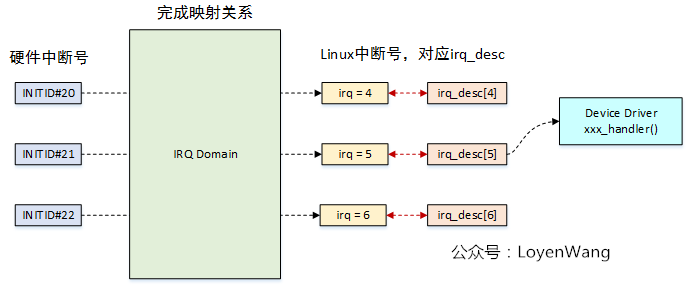
- 每个中断控制器都对应一个IRQ Domain;
- 中断控制器驱动通过irq_domain_add_*()接口来创建IRQ Domain;
- IRQ Domain支持三种映射方式:linear map(线性映射),tree
map(树映射),no map(不映射);
- linear map:维护固定大小的表,索引是硬件中断号,如果硬件中断最大数量固定,并且数值不大,可以选择线性映射;
- tree map:硬件中断号可能很大,可以选择树映射;
- no map:硬件中断号直接就是Linux的中断号;
三种映射的方式如下图:

- 图中描述了三个中断控制器,对应到三种不同的映射方式;
- 各个控制器的硬件中断号可以一样,最终在Linux内核中映射的中断号是唯一的;
Arch-speicific代码分析
中断也是异常模式的一种,当外设触发中断时,处理器会切换到特定的异常模式进行处理,而这部分代码都是架构相关的;ARM64的代码位于arch/arm64/kernel/entry.S。
ARM64处理器有四个异常级别Exception Level:0~3,EL0级对应用户态程序,EL1级对应操作系统内核态,EL2级对应Hypervisor,EL3级对应Secure Monitor;
异常触发时,处理器进行切换,并且跳转到异常向量表开始执行,针对中断异常,最终会跳转到irq_handler中;

中断触发,处理器去异常向量表找到对应的入口,比如EL0的中断跳转到el0_irq处,EL1则跳转到el1_irq处;
在GIC驱动中,会调用set_handle_irq接口来设置handle_arch_irq的函数指针,让它指向gic_handle_irq,因此中断触发的时候会跳转到gic_handle_irq处执行;
gic_handle_irq函数处理时,分为两种情况,一种是外设触发的中断,硬件中断号在16 ~ 1020之间,一种是软件触发的中断,用于处理器之间的交互,硬件中断号在16以内;
外设触发中断后,根据irq domain去查找对应的Linux IRQ中断号,进而得到中断描述符irq_desc,最终也就能调用到外设的中断处理函数了;
GIC和Arch相关的介绍就此打住,下一篇文章会接着介绍通用的中断处理框架,敬请期待。
通用框架处理
这篇文章会解答两个问题:
- 用户是怎么使用中断的(中断注册)?
- 外设触发中断信号时,最终是怎么调用到中断handler的(中断处理)?
struct irq_desc

Linux内核的中断处理,围绕着中断描述符结构struct irq_desc展开,内核提供了两种中断描述符组织形式:
- 打开CONFIG_SPARSE_IRQ宏(中断编号不连续),中断描述符以radix-tree来组织,用户在初始化时进行动态分配,然后再插入radix-tree中;
- 关闭CONFIG_SPARSE_IRQ宏(中断编号连续),中断描述符以数组的形式组织,并且已经分配好;
- 不管哪种形式,都可以通过linux irq号来找到对应的中断描述符;
图的左侧灰色部分,主要在中断控制器驱动中进行初始化设置,包括各个结构中函数指针的指向等,其中struct irq_chip用于对中断控制器的硬件操作,struct irq_domain与中断控制器对应,完成的工作是硬件中断号到Linux irq的映射;
图的上侧灰色部分,中断描述符的创建(这里指CONFIG_SPARSE_IRQ),主要在获取设备中断信息的过程中完成的,从而让设备树中的中断能与具体的中断描述符irq_desc匹配;
图中剩余部分,在设备申请注册中断的过程中进行设置,比如struct irqaction中handler的设置,这个用于指向我们设备驱动程序中的中断处理函数了;
中断的处理主要有以下几个功能模块:
- 硬件中断号到Linux irq中断号的映射,并创建好irq_desc中断描述符;
- 中断注册时,先获取设备的中断号,根据中断号找到对应的irq_desc,并将设备的中断处理函数添加到irq_desc中;
- 设备触发中断信号时,根据硬件中断号得到Linux irq中断号,找到对应的irq_desc,最终调用到设备的中断处理函数;
流程分析
这一次,让我们以问题的方式来展开:先来让我们回答第一个问题:用户是怎么使用中断的?
- 熟悉设备驱动的同学应该都清楚,经常会在驱动程序中调用request_irq()接口或者request_threaded_irq()接口来注册设备的中断处理函数;
- request_irq()/request_threaded_irq接口中,都需要用到irq,也就是中断号,那么这个中断号是从哪里来的呢?它是Linux irq,它又是如何映射到具体的硬件设备的中断号的呢?
先来看第二个问题:设备硬件中断号到Linux irq中断号的映射

- 硬件设备的中断信息都在设备树device tree中进行了描述,在系统启动过程中,这些信息都已经加载到内存中并得到了解析;
- 驱动中通常会使用platform_get_irq或irq_of_parse_and_map接口,去根据设备树的信息去创建映射关系(硬件中断号到linux irq中断号映射);
- 《Linux中断子系统(一)-中断控制器及驱动分析》提到过struct irq_domain用于完成映射工作,因此在irq_create_fwspec_mapping接口中,会先去找到- 匹配的irq domain,再去回调该irq domain中的函数集,通常irq domain都是在中断控制器驱动中初始化的,以ARM GICv2为例,最终回调到gic_irq_domain_hierarchy_ops中的函数;
- 如果已经创建好了映射,那么可以直接进行返回linux irq中断号了,否则的话需要irq_domain_alloc_irqs来创建映射关系;
- irq_domain_alloc_irqs完成两个工作:
- 针对linux irq中断号创建一个irq_desc中断描述符;
- 调用domain->ops->alloc函数来完成映射,在ARM GICv2驱动中对应gic_irq_domain_alloc函数,这个函数很关键,所以下文介绍一下;
gic_irq_domain_alloc函数如下:

- gic_irq_domain_translate:负责解析出设备树中描述的中断号和中断触发类型(边缘触发、电平触发等);
- gic_irq_domain_map:将硬件中断号和linux中断号绑定到一个结构中,也就完成了映射,此外还绑定了irq_desc结构中的其他字段,最重要的是设置了irq_desc->handle_irq的函数指针,这个最终是中断响应时往上执行的入口,这个是关键,下文讲述中断处理过程时还会提到;
- 根据硬件中断号的范围设置irq_desc->handle_irq的指针,共享中断入口为handle_fasteoi_irq,私有中断入口为handle_percpu_devid_irq;
上述函数执行完成后,完成了两大工作:
- 硬件中断号与Linux中断号完成映射,并为Linux中断号创建了irq_desc中断描述符;
- 数据结构的绑定及初始化,关键的地方是设置了中断处理往上执行的入口;
再看第一个问题:中断是怎么来注册的?
设备驱动中,获取到了irq中断号后,通常就会采用request_irq/request_threaded_irq来注册中断,其中request_irq用于注册普通处理的中断,request_threaded_irq用于注册线程化处理的中断;
在讲具体的注册流程前,先看一下主要的中断标志位:
1 | |

- request_irq也是调用request_threaded_irq,只是在传参的时候,线程处理函数thread_fn函数设置成NULL;
- 由于在硬件中断号和Linux中断号完成映射后,irq_desc已经创建好,可以通过irq_to_desc接口去获取对应的irq_desc;
- 创建irqaction,并初始化该结构体中的各个字段,其中包括传入的中断处理函数赋值给对应的字段;
- __setup_irq用于完成中断的相关设置,包括中断线程化的处理:
- 中断线程化用于减少系统关中断的时间,增强系统的实时性;
- ARM64默认开启了CONFIG_IRQ_FORCED_THREADING,引导参数传入threadirqs时,则除了IRQF_NO_THREAD外的中断,其他的都将强制线程化处理;
- 中断线程化会为每个中断都创建一个内核线程,如果中断进行共享,对应irqaction将连接成链表,每个irqaction都有thread_mask位图字段,当所有共享中断都处理完成后才能unmask中断,解除中断屏蔽;
中断处理
当完成中断的注册后,所有结构的组织关系都已经建立好,剩下的工作就是当信号来临时,进行中断的处理工作。
来回顾一下《Linux中断子系统(一)-中断控制器及驱动分析》中的Arch-specific处理流程:

- 中断收到之后,首先会跳转到异常向量表的入口处,进而逐级进行回调处理,最终调用到generic_handle_irq来进行中断处理。
generic_handle_irq处理如下图:

- generic_handle_irq函数最终会调用到desc->handle_irq(),这个也就是对应到上文中在建立映射关系的过程中,调用irq_domain_set_info函数,设置好了函数指针,也就是handle_fasteoi_irq和handle_percpu_devid_irq;
- handle_fasteoi_irq:处理共享中断,并且遍历irqaction链表,逐个调用action->handler()函数,这个函数正是设备驱动程序调用request_irq/request_threaded_irq接口注册的中断处理函数,此外如果中断线程化处理的话,还会调用__irq_wake_thread()唤醒内核线程;
- handle_percpu_devid_irq:处理per-CPU中断处理,在这个过程中会分别调用中断控制器的处理函数进行硬件操作,该函数调用action->handler()来进行中断处理;
来看看中断线程化处理后的唤醒流程吧__handle_irq_event_percpu->__irq_wake_thread:
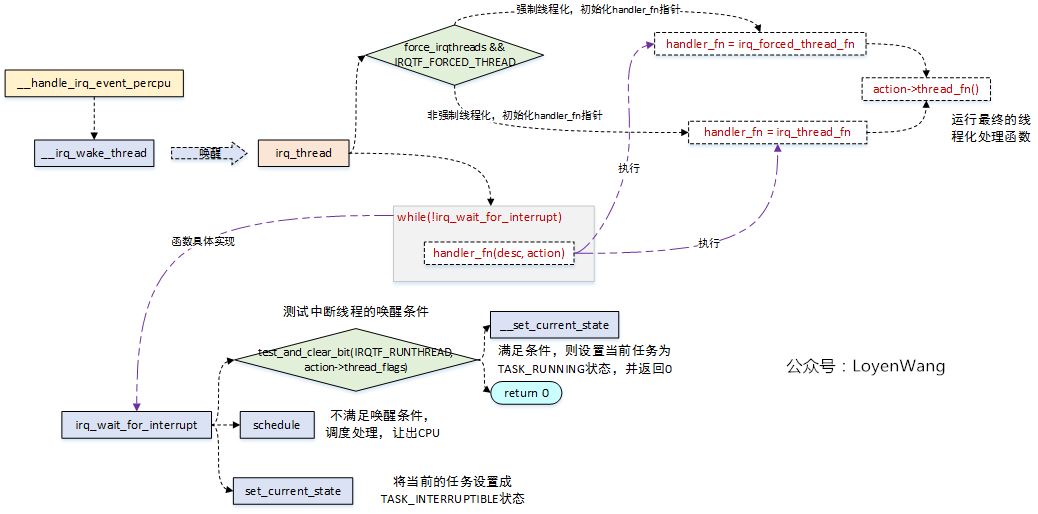
- __handle_irq_event_percpu->__irq_wake_thread将唤醒irq_thread中断内核线程;
- irq_thread内核线程,将根据是否为强制中断线程化对函数指针handler_fn进行初始化,以便后续进行调用;
- irq_thread内核线程将while(!irq_wait_for_interrupt)循环进行中断的处理,当满足条件时,执行handler_fn,在该函数中最终调用action->thread_fn,也就是完成了中断的处理;
- irq_wait_for_interrupt函数,将会判断中断线程的唤醒条件,如果满足了,则将当前任务设置成TASK_RUNNING状态,并返回0,这样就能执行中断的处理,否则就调用schedule()进行调度,让出CPU,并将任务设置成TASK_INTERRUPTIBLE可中断睡眠状态;
总结
中断的处理,总体来说可以分为两部分来看:
- 从上到下:围绕irq_desc中断描述符建立好连接关系,这个过程就包括:中断源信息的解析(设备树),硬件中断号到Linux中断号的映射关系、irq_desc结构的分配及初始化(内部各个结构的组织关系)、中断的注册(填充irq_desc结构,包括handler处理函数)等,总而言之,就是完成静态关系创建,为中断处理做好准备;
- 从下到上,当外设触发中断信号时,中断控制器接收到信号并发送到处理器,此时处理器进行异常模式切换,并逐步从处理器架构相关代码逐级回调。如果涉及到中断线程化,则还需要进行中断内核线程的唤醒操作,最终完成中断处理函数的执行。
软中断和tasklet运行于软中断上下文,仍然属于原子上下文的一种,而工作队列则运行于进程上下 文。因此,在软中断和tasklet处理函数中不允许睡眠,而在工作队列处理函数中允许睡眠。
软中断(Softirq):
- 运行于软中断上下文,也被认为是一种原子上下文。
- 在软中断中运行的代码应该是非阻塞的,不允许执行可能导致进程切换(调度)的操作,如休眠。
- 主要用于在内核中处理底半部工作。
Tasklet:
- 也运行于软中断上下文,因此同样属于原子上下文。
- 与软中断类似,tasklet 中的代码应该是非阻塞的。
- Tasklet 提供了比软中断更方便的 API,使得处理底半部工作更加简单。
工作队列(Work Queue):
- 运行于进程上下文。
- 工作队列允许执行可能导致进程切换的操作,如休眠。
- 由于在进程上下文中执行,工作队列更适合执行那些可能耗时较长的任务。
- 在Linux内核中,软中断和tasklet通常用于处理一些紧急的、轻量级的任务,以避免在顶半部中执行过多的工作。因为它们运行在软中断上下文,所以它们的执行应该是快速的、不可睡眠的。
工作队列则更适合那些不太紧急、允许较长执行时间的任务,因为它们可以在进程上下文中执行,允许进行较长时间的处理,甚至是休眠。
进程上下文、线程上下文、中断上下文的区别?
在操作系统中,"上下文"通常指的是执行环境和状态的集合,不同的上下文代表了不同的执行环境。在 Linux 内核中,常见的上下文包括进程上下文、线程上下文和中断上下文。以下是它们的主要区别:
进程上下文(Process Context):
- 概念: 进程上下文是指一个运行在内核态的进程的上下文环境。
- 特点: 在进程上下文中,内核代码执行的是进程的名义上下文,因此可以访问进程的地址空间和所有用户空间数据。
- 切换代价: 进程上下文切换的代价相对较高,因为需要保存和还原完整的进程状态,包括寄存器、页表等。
线程上下文(Thread Context):
- 概念: 线程上下文是指一个运行在内核态的线程的上下文环境。
- 特点: 与进程上下文相似,线程上下文也可以访问线程的地址空间和用户空间数据。
- 切换代价: 线程上下文切换的代价相对于进程上下文来说较小,因为在同一地址空间中运行的线程共享了相同的页表。
中断上下文(Interrupt Context):
- 概念: 中断上下文是指内核在响应硬件中断时执行的上下文环境。
- 特点: 中断上下文运行在中断服务例程(ISR)中,它必须迅速完成以便尽早恢复硬件中断。
- 限制: 中断上下文有一些限制,例如不允许休眠、不允许访问用户空间数据,因为这可能导致不可预测的延迟。
总体而言,这三种上下文反映了不同的执行环境和执行要求。在内核中,合理的使用这些上下文是确保系统稳定性和性能的关键。
网卡驱动net-device,suckbf这两个数据结构很关键,驱动中收包逻辑通过中断,这个稍微复杂些
您提到的 "net-device" 和 "skb"(假设 "suckbf" 是打字错误,应该是 "skb")是 Linux 网络驱动开发中的两个关键数据结构。
net_device:
- net_device 是 Linux 网络设备的抽象表示。每个网络设备(例如网卡)都由一个 net_device 结构体表示。
- 该结构体包含了网络设备的各种信息,如设备名称、MAC 地址、状态等。
- 驱动程序通过操作 net_device 结构体来控制和管理网络设备。
skb(Socket Buffer):
- skb 是 Linux 内核中用于表示网络数据包的结构体。它包含了传输层和网络层的数据,以及与数据包相关的元数据。
- skb 中包含了指向数据区域的指针,以及与数据包相关的一系列头部信息。
- skb 是网络驱动中非常关键的数据结构,用于传递和处理网络数据包。
如果您是在谈论网络驱动的中断处理,那么通常是使用中断机制来接收网络数据包。下面是简要的网络驱动中收包逻辑的概述:
中断处理:
- 网卡通常会生成中断,以通知系统有新的数据包到达。这可以是硬中断或者通过 Polling 机制。
- 中断服务程序(ISR)是一个与中断相关的函数,它会在中断发生时执行。在网络驱动中,ISR 的任务是通知内核有新的数据包到达。
数据包接收:
- ISR 负责从网卡接收数据包,将数据包存储到内存中。
- 接收到的数据包通常会以 skb 结构体的形式存在。
net_device 处理:
- 接着,网络驱动会将接收到的数据包封装成 skb,并将 skb 与对应的 net_device 关联起来。
- 驱动可能会更新 net_device 结构体中的统计信息(如接收的字节数、数据包数量等)。
上层处理:
- 最后,驱动会将 skb 传递给协议栈的上层,让网络协议栈(例如TCP/IP协议栈)进一步处理。
- 这是一个简单的概述,实际上,网络驱动的开发涉及到很多复杂的细节,包括对各种网络协议的处理、中断处理程序的高效性等。
10.7 总结
Linux的中断处理分为两个半部,顶半部处理紧急的硬件操作,底半部处理不紧急的耗时操作。tasklet 和工作队列都是调度中断底半部的良好机制,tasklet基于软中断实现。内核定时器也依靠软中断实现。
内核中的延时可以采用忙等待或睡眠等待,为了充分利用CPU资源,使系统有更好的吞吐性能,在对 延迟时间的要求并不是很精确的情况下,睡眠等待通常是值得推荐的,而ndelay()、udelay()忙等待 机制在驱动中通常是为了配合硬件上的短时延迟要求。
17.1 I2C、SPI、USB驱动架构
您提到的内容涉及Linux中I2C、SPI、USB等总线驱动的架构。下面是对这些内容的一些解释:
总线驱动架构:
- Linux的总线驱动架构采用了一种分层的设计,将主机端的驱动与外设端的驱动分离。
- 通过一个核心层对某种总线的协议进行抽象,外设端的驱动可以通过调用核心层的API间接访问主机端的驱动传输函数。
- 这种设计使得在不同总线上运行的外设可以共享相同的驱动接口,提高了驱动的可移植性。
板级描述信息:
- 对于像I2C、SPI这样不具备热插拔能力的总线,通常需要在arch/arm/mach-xxx或者arch/arm/boot/dts中提供板级描述信息。
- 这些描述信息包括外设与主机的连接情况,有助于内核正确地配置和初始化驱动。
USB、PCI等总线:
- USB、PCI等总线具备热插拔能力,因此在板级描述信息中通常不需要详细描述外设与主机的连接情况。
- Linux USB子系统和PCI子系统具有自动探测的功能,可以动态地发现和管理连接到系统的外设。
架构类比:
不仅限于I2C、SPI、USB,Linux的各个子系统都遵循相似的总线驱动架构。
表17.1中列举了I2C、SPI、USB的架构类比,说明了它们在整体架构上的相似性。
控制器的枚举:
- I2C、SPI、USB控制器实际上也是由它们自身依附的总线枚举出来的。
- 这些控制器通常直接集成在SoC内部,通过内存访问指令来访问。它们通过platform_driver、platform_device等模型被枚举进内核。
- 总体而言,这种总线驱动的设计和架构使得Linux内核能够更好地支持不同类型的总线和外设,并且具有良好的可移植性和可扩展性。
Linux 程序开发常用调试工具合集
01 总览
编译阶段
- nm 获取二进制文件包含的符号信息
- strings 获取二进制文件包含的字符串常量
- strip 去除二进制文件包含的符号
- readelf 显示目标文件详细信息
- objdump 尽可能反汇编出源代码
- addr2line 根据地址查找代码行
运行阶段
- gdb 强大的调试工具
- pstack
- ldd 显示程序需要使用的动态库和实际使用的动态库
- bpftrace
- trace-bpfcc
- execsnoop
- ftrace
- trace-cmd
- perf
- strace 跟踪程序当前的系统调用
- ltrace 跟踪程序当前的库函数
- time 查看程序执行时间、用户态时间、内核态时间
- gprof 显示用户态各函数执行时间
- valgrind 检查内存错误
- mtrace 检查内存错误
其他
- proc文件系统
- 系统日志
GPU
今天的GPU包含四大功能:显示、2D/3D加速、视频编 解码(一般称为媒体)和通用计算(称为GPGPU)。图8-4中把这四大 功能模块画在了一起。

VGA
VGA的全称为视频图形阵列(Video Graphics Array)。其核心功 能是把帧缓冲区(frame buffer)中的要显示内容转变成模拟信号并 通过一个15针的D形(D-sub)接口送给显示器。这个15针的显示接口 一直使用到现在,即通常说的VGA接口。VGA不仅支持彩色显示,还支 持多种图形模式。
一块VGA显卡的主要部件有以下几个部分。
- 视频内存(video memory),其主要作用是临时存放要显示的内 容,即上面提到的刷新缓冲区和帧缓冲区,也就是通常所说的显 存。
- 图形控制器,承载显卡的核心逻辑,负责与CPU和上层软件进行交 互,管理显卡的各种资源,通常实现在一块集成芯片内,是显卡 上最主要的芯片。这部分不断扩展和增强,逐步演化为后来的 GPU。
- 显示控制器,负责把要显示的内容转化为显示器可以接收的信 号,有时也称为DAC(数字模拟信号转换器)。
- 视频基本输入输出系统(Video BIOS,VBIOS),显卡上的固件单 元,从硬件角度来看,是一块可擦写的存储器(EPROM)芯片,里 面存放着用于配置和管理显卡的代码和数据。对于显卡的开发者 来说,可以通过修改VBIOS快速调整改变显卡的设置,或者修正瑕 疵。对于软件开发者来说,调用VBIOS提供的功能不但可以加快编 程速度,而且可以提高兼容性(VBIOS以统一的接口掩盖了硬件差 异性)。在DOS下,可以很方便地通过软中断机制(INT 10h)来 调用VBIOS提供的服务。
软件接口
批命令缓冲区
比如,在图8-5 所示的G965框图中,矩形框代表GPU,顶上从外到内的箭头代表GPU通 过内存接口(MI)从外部接收命令流。箭头下方的CS代表命令流处理 器(Command Streamer)。

图8-5中,中间的GEN4子系统中包含了通用执行单元(EU),两侧 分别是固定功能的3D流水线和媒体流水线。CS负责把命令分发给不同 的执行流水线。第11章将详细介绍英特尔GPU和GEN架构。
状态模型
上面介绍的批命令缓冲区解决了成批提交的问题,可以让GPU的多 个用户轮番提交自己的命令,但是还有一个问题没有解决。那就是如 果一个任务没有执行完,同时有更高优先级的任务需要执行,或者一 个任务执行中遇到问题,如何把当前的任务状态保存起来,然后切换 到另一个任务。用操作系统的术语来说,就是如何支持抢先式调度。
今天的GPU流水线都灵活多变,参数众多,如果在每次切换任务时 都要重复配置所有参数和寄存器,那么会浪费很多时间。
状态模型是解决上述问题的较好方案。简单来说,在状态模型中 使用一组状态数据作为软硬件之间的接口,相互传递信息。用程序员 的话来说,就是定义一套软件和硬件都认可的数据结构,然后通过这 个数据结构来保存任务状态。当需要执行某个任务时,只要把这个状 态的地址告诉GPU,GPU就会从这个地址加载状态。当GPU需要挂起这个 任务时,GPU可以把这个任务的状态保存到它的状态结构体中。

在图8-6中,上面是一个基本的数据结构,其起始地址有个专门的 名字,称为状态基地址(State Base Address),当向GPU下达任务 时,要把这个地址告诉GPU。从此,GPU便从这个状态空间来获取状态 信息。图中左侧是绑定表,考虑到准备任务时某些数据在GPU上的地址 还不确定,所以就先用句柄来索引它,在提交任务时,内核态驱动和 操作系统会在修补阶段(Patching)更新绑定表的内容,落实对象引 用。
总结一下,本节简要浏览了GPU与CPU之间的编程接口。从早期的 设备寄存器方式到后来的批命令方式,再到状态模型。变革的主要目 的是更好地支持多任务,并且可以快速提交和切换任务。
驱动模型
DRI和DRM
在UNIX和Linux系统中,X窗口系统(X Window System)历史悠 久,应用广泛。它起源于美国的麻省理工学院,最初版本发布于1984 年6月,其前身是名为W的窗口系统。从1987年开始,X的版本号一直为 11,因此,今天的很多文档中经常使用X11来称呼X。X是典型的“客户 端-服务器”架构,服务器部分一般称为X服务器,客户端称为X客户 端,比如xterm等。
进入20世纪90年代后,随着3D技术的走红,开源系统中也需要一 套与DirectX类似的GPU快速通道。1998年,DRI应运而生。DRI的全称 为直接渲染基础设施(Direct Renderring Infrastructure)。DRI的 目标是让DRI客户程序和X窗口系统都可以高效地使用GPU。
1999年,DRI项目的一部分核心实现开始发布,名叫直接渲染管理 器(Direct Rendering Manager,DRM)。严格来说,DRM是DRI的一部 分,但今天很多时候,这两个术语经常相互替代。
经过十多年的演进变化,今天的DRI架构已经和WDDM很类似,也可 以按前面介绍的四象限切分方法划分为四大角色,如图8-9所示。

在DRI架构中,内核模式的核心模块称为DRM核心,其角色相当于 WDDM中的DXG内核。DRM核心的目标是实现与GPU厂商无关的公共逻辑, 主要有以下几方面。
管理和调度GPU任务,这部分一般称为“图形执行管理器” (Graphics Execution Manager,GEM)。
检测和设置显示模式、分辨率等,这部分功能一般称为“内核模 式设置”(Kernel Mode Setting,KMS)。
管理GPU内存,这部分一般称为图形内存管理器(GMM)。
与具体GPU硬件密切关联的部分要分别实现,使用DRM的术语,这 部分称为DRM驱动,套用WDDM的术语就是KMD。
用户空间中的各种API和运行时通过libDRM与内核空间交互,厂商 相关的部分一般称其为libDRM驱动,相当于WDDM中的UMD。
举例来说,Nvidia GPU的KMD名为nvidia-drm,UMD名为libGL-nvidia-glx。
编程技术
Brook和CUDA
在2004年的SIGGRAPH大会上,Ian Buck发表了题为“Brook for GPUs:Stream Computing on Graphics Hardware”的演讲,公开介绍 了BrookGPU项目。
在Ian Buck的演讲稿的最后一页中有个征集合作的提示。我们不 知道有多少家公司当年曾经对Brook项目感兴趣,但可以确定的是ATI 和Nvidia都在其列。因为ATI曾经推出基于Brook的ATI Brook+技术, 而Nivida的做法更加彻底,2004年11月,直接把Ian Buck雇为自己的 员工。
Ian Buck加入Nvidia时,前一年加入的约翰·尼可尔斯应该正在 思考如何改变GPU的内部设计,使用新的通用核心来取代固定的硬件流 水线,让其更适合并行计算。作者认为两个人见面时一定有志同道 合、相见恨晚的感觉。2006年,使用通用核心思想重新设计的G80 GPU 问世。2007年,基于Brook的CUDA技术推出。高瞻远瞩的硬件,配上优 雅别致的软件,二者相辅相成,共同开创了GPGPU的康庄大道。
CUDA本来是Compute Unified Device Architecture的缩写,但后 来Nvidia取消了这个全称。CUDA就是CUDA,不需要解释。CUDA项目所 取得的成功众所周知,详细情况将在下一章介绍。
OpenCL
OpenCL也是基于C语言进行的扩展,但是与CUDA相比,相差悬殊。 CUDA和OpenCL的核心任务都是从CPU上给GPU编程。如何解决CPU代码和 GPU代码之间的过渡是关键之关键。CUDA比较巧妙地掩盖了很多烦琐的 细节,让代码自然过渡,看起来很优雅。而OpenCL则简单粗暴。以关 键的发起调用为例,在OpenCL中要像下面这样一个一个地设置参数。
在CUDA和OpenCL中,都把在GPU中执行的计算函数称为算核 (compute kernel),有时也简称核(kernel),本书统一将其称为 算核。
调试设施
输出调试信息
在CUDA和OpenCL中都定义了printf函数,让运行在GPU上的算核函 数可以很方便地输出各种调试信息。GPU版本的函数原型与标准C一 样,但是某些格式符号可能略有不同。
到目前为止,算核函数不能直接显示内容到屏幕,所以GPU上的 printf实现一般都先把信息写到一个内存缓冲区,然后再让CPU端的代 码从这个缓冲区读出信息并显示出来,如图8-10所示。

以CUDA为例,算核函数调用printf时会把要输出的信息写到一个 先进先出(FIFO)的内存缓冲区中,格式模板和动态信息是分别存放 的。
CPU端的代码启动算核函数后,一般会调用 cudaDeviceSynchronize()这样的同步函数等待GPU的计算结果。在同 步函数中,会监视FIFO内存区的变化,一旦发现新信息,便将模板信 息和动态信息合成在一起,然后输出到控制台窗口。
可以通过CUDA的如下两个函数分别获取和改变FIFO缓冲区的大 小。
- cudaDeviceGetLimit(size_t* size,cudaLimitPrintfFifoSize)
- cudaDeviceSetLimit(cudaLimitPrintfFifoSize, size_t size)
在OpenCL中,printf函数的实现是与编译器和运行时相关的,在 英特尔开源的Beignet编译器中,也使用与图8-10类似的内存缓冲区方 法。当一个算核完成或者CPU端调用clFinish等函数时,保存在内存区 中的调试信息会显示出来。
8.6.2 发布断点
在调试GPU程序时,用户可能希望在GPU真正开始执行自己的代码 前就中断下来,仿佛一开始执行算核函数就遇到断点一样,这样的中 断与CPU调试时的初始断点类似,本书将其称为发布断点(launch breakpoint)。
例如,在CUDA GDB(见第9章)中,可以通过set cuda break_on_launch命令来启用和禁止发布断点(参数all表示启用, none表示禁止)。
CUDA GDB的帮助手册把发布断点称为算核入口断点(kernel entry breakpoint)。
8.6.3 其他断点
当然,今天的大多数GPU都支持普通的软件断点。Nvidia GPU中有 专门的软件断点指令,英特尔GPU中每一条指令的操作码部分都有一个 调试控制位,一旦启用,这个指令便具有了断点指令的效果。
英特尔GPU还支持操作码匹配断点,可以针对某一种指令操作来设 置断点。这将在第11章详细介绍。
第9章 Nvidia GPU及其调试设施
9.2.1 G80(特斯拉1.0微架构)
G80内部一共有128个流式处理器(Streaming Processor,SP), 每8个一组,组成一个流式多处理器(Streaming Multiprocessor, SM),每两个SM组成一个集群,称为纹理处理器集群 (Texture/Processor Cluster,TPC)。换个角度来说,G80内部包含 了8个TPC、16个SM和128个SP,如图9-1所示[6] 。
图9-1最下方的方框代表显存(DRAM),其上的ROP代表光栅操作 处理器(Raster Operation Processor),可以直接对显存中的图形 数据做各种位运算。ROP旁边的L2代表二级缓存。ROP和L2上面的横条 代表互联网络,它把所有TPC和其他部件连接起来。
图9-1中央是8个TPC,其上方是三种任务分发器,分别用来分发顶 点任务(处理点、线和三角形),像素任务(处理光栅输出、填充图 元的内部区域),以及通用计算任务。
图9-1中最上方的三个矩形(位于GPU外面)代表通过总线桥接与 系统内存和主CPU的通信。
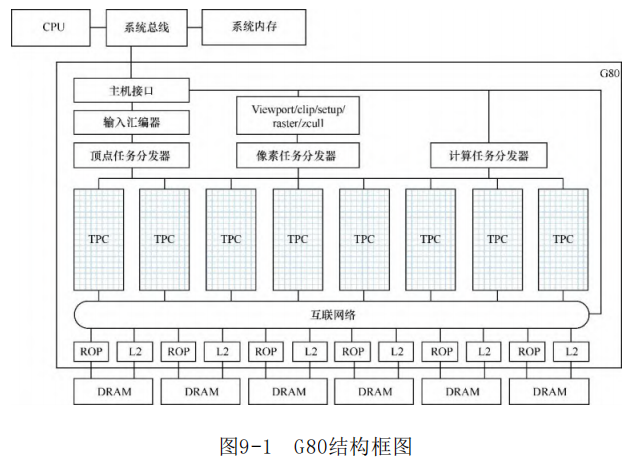
对G80的宏观架构有个大体了解之后,下面再深入TPC和SM的内 部。图9-2是TPC的内部结构框图,为了节约篇幅,这里将其画为横向 布局。
首先,在每个TPC中,包含两个SM,以及如下共享的设施。
一个SM控制器(SMC):除了管理SM外,它还负责管理和调度TPC 的其他资源,包括读写内存,访问I/O,以及处理顶点、像素和几 何图形等类型的工作负载。
几何控制器(geometry controller):负责把软件层使用DX10着 色器定义的顶点处理和几何处理逻辑翻译为SM上的操作,并负责 管理芯片上专门用于存储顶点属性的存储区,根据需要读写或者 转发其中的数据。
纹理单元(texture unit):负责执行纹理操作,通常以纹理坐 标为输入,输出R、G、B、A这4个分量。

在每个SM中,除了由8个流处理器组成的SP阵列外,还包含如下共 享的设施。
- 一级缓存(cache),分为两个部分。一个部分用于缓存代码,称 为指令缓存(I cache);另一部分用来缓存常量数据,称为常量 缓存(C cache)。
- 共享内存,后面将讲到的使用__shared__关键字描述的变量会分 配在这里。
- 两个特殊函数单元(Special Function Unit,SFU),用于支持 比较复杂的计算,比如对数函数、三角函数和平方根函数等,每 个SFU内部包含4个浮点乘法器。
- 一个多线程指令发射器(MT issuer),用于读取指令,并以并发 的方式发射到SP或者SFU中。
最后再介绍一下SM中最重要的执行单元——SP。在每个SP内,都 包含一个标量乘加(multiply-add)单元,它可以执行基本的浮点运 算,包括加法、乘法和乘加。SP还支持丰富的整数计算、比较和数据 转换操作。
值得说明的是,SP和SFU是独立的,可以各自执行不同的指令,同 时工作,以提高整个SM的处理能力。
9.2.3 GF100(费米微架构)
2010年3月,Nvidia发布GeForce 400系列GPU产品,其微架构名叫 费米(Fermi)。初期所发布产品的GPU代号名为GF100,代号中的F代 表费米微架构[7] 。
与前一代相比,GF100的第一个明显变化是进一步增加SP的数量, 由GT200中的240个增加到512个。SP的名字也改称CUDA核心(core)。 每个SM包含32个CUDA核心,每4个SM组成一个集群,集群的名字由TPC 改称GPC(Graphics Processing Cluster)。GF100中包含4个GPC,如 图9-3所示。

GF100的最重要技术之一是所谓的二级分布式线程调度器(two-level distributed thread scheduler)。第一级是指图9-3上方的吉 咖线程引擎,它是芯片级的,负责分发全局工作,把线程块(block) 分发给各个SM。第二级是指SM内部的WARP调度器,它负责把线程以 WARP为单位分发给SM中的执行单元。
在每个SM内部(见图9-4),除了有32个CUDA核心外,还有一些共 享的资源,包括128KB的寄存器文件、64KB大小的共享内存和L1缓存、 4个特殊函数单元(SFU)、16个用于访问内存的LD/ST单元、1个用于 3D应用的PolyMorph引擎、4个纹理处理单元,以及纹理数据缓存等。
在每个CUDA核心中(见图9-4左侧),包含了浮点单元和整数单 元,分别用于执行对应类型的数学运算。
把特斯拉1.0、2.0微架构和费米微架构相比较,一个明显的变化 趋势是每个集群的SM数量增加,从2到3再到4。每个SM中包含的核心数 量也在不断增加,从8到10再到32。

硬件指令集
9.3.1 SASS
Nvidia把GPU硬件指令对应的汇编语言称为SASS。关于SASS的全 称,官方文档不见其踪影。有人说它是Streaming ASSembler(流式汇 编器)的缩写[10] ,也有人说它是Shader Assembler的缩写,作者觉 得前者可能更接近。
可以使用CUDA开发包中的cuobjdump来查看SASS汇编,比如执行如 下命令可以把嵌在vectorAdd.exe中的GPU代码进行反汇编,然后以文 本的形式输出出来。
1 | |
在使用CUDA GDB调试时,可以直接使用GDB的反汇编命令来查看 SASS汇编,比如x /i、display /i命令,或者disassemble命令。
1 | |
9.4 PTX指令集
根据上一节对GPU硬件指令的介绍,我们知道不同微架构的指令是 有较大差异的。这意味着,如果把GPU程序直接按某一微架构的机器码 进行编译和链接,那么产生的二进制代码在其他微架构的GPU上执行时 很可能会有问题。为了解决这个问题,并避免顶层软件直接依赖底层 硬件,Nvidia定义了一个虚拟环境,取名为并行线程执行(Parallel Thread eXecution,PTX)环境。然后针对这个虚拟机定义了一套指令 集,称为PTX指令集(ISA)。
有了PTX后,顶层软件只要保证与PTX兼容即可(见图9-11)。在 编译程序时,可以只产生PTX指令,当实际执行时,再使用即时编译 (JIT)技术产生实际的机器码。这与Java和.NET等编程语言使用的中 间表示(IR)技术很类似。

与SASS没有公开文档不同,PTX指令集的应用指南(Parallel Thread eXecution ISA Application Guide)非常详细,有在线版 本,CUDA工具包中也有。CUDA 9.1版本的文件名为ptx_isa_6.1.pdf, 长达300余页。建议读者阅读本节内容时,同时参照这个文档。
9.5 CUDA
9.5.2 算核
在并行计算领域,常常把需要大量重复的操作提炼出来,编写成 一个短小精悍的函数,然后把这个函数放到GPU或者其他并行处理器上 去运行,重复执行很多次。为了便于与CPU上的普通代码区分开,人们 给这种要在并行处理器上运行的特别程序取了个新的名字,称为算核 (kernel)。
从代码的角度来看,算核函数用于把普通代码里的循环部分提取 出来。举例来说,如果要把两个大数组A和B相加,并把结果放入数组C 中,那么普通的C程序通常如下。
1 | |
如果用算核表达,那么算核函数中就只有C [i] = A[i] + B[i]。 对应的CUDA程序如清单9-3所示。
清单9-3 做向量加法的CUDA程序片段
1 | |
与普通的C语言程序相比,上面代码有三处不同。第一处是函数前 的__global__修饰。它是CUDA新引入的函数执行空间指示符 (Function Execution Space Specifier),一共有以下5个函数执行 空间指示符。
- global:一般用于定义GPU端代码的起始函数,表示该函数是 算核函数,将在GPU上执行,不能有返回值,在调用时总是异步调 用。另外,只有在计算能力不低于3.2的硬件上,才能从GPU端发 起调用(这一功能称为动态并行),否则,只能从CPU端发起调 用。
- device:用来定义GPU上的普通函数,表示该函数将在GPU上 执行,可以有返回值,不能从CPU端调用。
- host:用来定义CPU上的普通函数,可以省略。
- noinline:指示编译器不要对该函数做内嵌(inline)处 理。默认情况下,编译器倾向于对所有标有__device__指示符的 函数做内嵌处理。
- forceinline:指示编译器对该函数做内嵌处理。
简单来说,前两种指示符都代表该函数在GPU上执行,第三种指示 符代表该函数在CPU上执行。
9.5.3 执行配置
与普通C程序相比,上述CUDA程序的第二个明显不同是调用算核函 数的地方,即main中的如下语句。
1 | |
函数名之后,圆括号之前的部分是CUDA的扩展,用了三对 “<>”。这三对尖括号真是新颖,不知道是哪位同行的奇思妙想。 (简单搜索了一下Brook 0.4版本,没有搜索到,作者认为这应该是 CUDA的发明。)简单来说,尖括号中指定的是循环方式和循环次数。1 代表只要一个线程块(block),这个线程块里包含N 个线程。
不要小看上面这一行代码,它非常优雅地解决了一个大问题。这 个大问题就是到底该如何在CPU的代码里调用GPU的算核函数。根据前 面的介绍,在调用算核函数时,不仅要像调用普通函数那样传递参 数,还需要传递一个信息,那就是如何做循环,简单说就是循环方式 和循环次数。
在CUDA手册中,这三对括号被称为执行配置(Execution Configuration),用于描述 GPU 上执行 CUDA 核函数时的配置。完整形式如下:
1 | |
其中:
Dg(Grid Dimension)表示网格的维度,用于描述将核函数启动的网格的大小。Db(Block Dimension)表示线程块的维度,用于描述每个线程块中线程的数量。Ns(Shared Memory Size)表示共享内存的大小,用于描述每个线程块所使用的共享内存的大小。S(Stream)表示流,用于描述执行核函数的流。
这种执行配置允许开发者精确地控制 GPU 上的并行执行,包括启动多少个线程块、每个线程块中有多少个线程以及共享内存的使用情况等。通过调整执行配置,开发者可以优化 CUDA 程序的性能,充分发挥 GPU 的并行计算能力。
在 CUDA 中,网格的维度(Grid Dimension)是用来描述将核函数启动的网格的大小的参数。网格是线程块的集合,它们共同组成了 GPU 上的并行执行单元。网格的维度指定了在 GPU 上启动核函数时的线程块的排列方式。
网格的维度由三个参数组成,通常表示为 (x, y, z):
x表示网格在 x 轴方向上的大小。y表示网格在 y 轴方向上的大小。z表示网格在 z 轴方向上的大小。
网格的大小决定了在 GPU 上启动的线程块的数量。例如,一个大小为
(2, 3, 1) 的网格表示在 x 轴方向上有 2 个线程块,在 y
轴方向上有 3 个线程块,在 z 轴方向上有 1 个线程块。这样的网格总共包含 6
个线程块。
网格的维度是 CUDA 执行配置中的一个重要参数,通过调整网格的大小,开发者可以控制并行执行的程度,从而优化 CUDA 程序的性能。
9.5.4 内置变量
上述代码与普通C程序的第三处不同是算核函数中直接使用了一个 threadIdx变量。它是CUDA定义的内置变量(built-in variable), 在写CUDA程序时,不需要声明,可以直接使用。
截至CUDA 9.1版本,CUDA一共定义了5个内置变量,简述如下。
- 变量gridDim和blockDim分别代表线程网格和线程块的维度信息, 也就是启动核函数时通过三对尖括号指定的执行配置情况。
- 变量blockIdx和threadIdx分别表示当前线程块在线程网格里的坐 标位置和当前线程在线程块里的位置。
上面4个变量都是dim3类型,x 、y 、z 三个分量分别对应三个维 度。
变量warpSize是整型的,代表一个Warp的线程数。稍后会详细介 绍Warp。
CUDA还可定义了两个伪变量 @flatBlockIdx和@flatThreadIdx。二者都是长整型,分别代表平坦化 的线程组编号和线程编号。
9.5.5 Warp
GPU编程的一个基本特点是大规模并行,让GPU内数以千计的微处 理器同时转向要处理的数据,每个线程处理一个数据元素。
一方面是大量需要执行的任务,另一方面是很多等待任务的微处 理器。如何让这么多微处理器有条不紊地把所有任务都执行完毕呢? 这是个复杂的话题,详细讨论它超出了本书的范围。这里只能介绍其 中的一方面:调度粒度。
与军队里把士兵分成一个个小的战斗单位类似,在CUDA中,也把 微处理器分成一个个小组。每个组的大小是一样的。迄今为止,组的 规模总是32个。CUDA给这个组取了个特别的名字:Warp。
Warp是GPU调度的基本单位。这意味着,当GPU调度硬件资源时, 一次分派的执行单元至少是32个。如果每个线程块的大小不足32个, 那么也会分配32个,多余的硬件单元处于闲置状态。
9.6 异常和陷阱
与CPU的异常机制类似,Nvidia GPU也有异常机制,在官方文档中 大多称为陷阱(trap)。因为它与调试关系密切,所以本节专门介绍 Nvidia GPU中与陷阱机制密切相关的内容。
9.6.1 陷阱指令
从PTX指令集的1.0版本开始,就有一条专门用于执行陷阱操作的 指令,名字就叫trap。
PTX文档对这条指令的描述非常简略,惜字如金。只有简洁的一句 话:Abort execution and generate an interrupt to the host CPU (中止执行,并向主CPU产生一个中断)。
如果在CUDA程序中通过嵌入式汇编代码插入一条trap指令,那么 会发现它的效果居然与断点指令完全相同,查看反汇编代码,对应的 硬件指令竟然也完全一样。
9.7 系统调用
9.7.1 vprintf
在PTX手册中,列举了很多个系统调用。其中有一个名叫 vprintf,用于从GPU代码中输出信息,与CPU上的printf很类似,因为 它恰好与调试的关系比较密切,所以就先以它为例来理解GPU的系统调 用。
在使用系统调用时,必须有它的函数原型,vprintf的函数原型如 下。
1 | |
其中,status是返回值,format和valist分别是格式化模板和可 变数量的参数列表。对于32位地址,t1和t2都是.b32类型;对于64位 地址,它们都是.b64类型。
如果在CUDA程序中调用printf来输出信息,其内部就会调用 vprintf。打开一个CUDA程序,加入一行printf(或者打开CUDA开发包 中的simplePrintf示例),然后查看反汇编窗口,可以看到发起系统 调用的PTX指令和硬件指令。
9.7.2 malloc和free
与普通C中的malloc和free类似,CUDA中提供两个类似的函数 malloc和free,供GPU上的程序动态分配和释放GPU上的内存。这两个 函数都是以系统调用的方式实现的。
1 | |
它们的参数和与普通C中的完全相同。
9.7.3 __assertfail
断言是常用的调试机制。在CUDA中,可以像普通C程序那样使用 assert(包含assert.h),其内部基于以下名为__assertfail的系统 调用。
1 | |
9.8 断点指令
9.8.1 PTX的断点指令
在PTX 1.0版本中就包含了一条专门用于调试的断点指令,名叫 brkpt。
在CUDA程序中,可以非常方便地插入断点指令,只要使用前面介 绍过的嵌入式汇编语法就可以了,例如以下代码。
1 | |
这样嵌入的断点指令的效果与在普通C程序中嵌入CPU的断点指令 (x86下的INT 3或者调用DebugBreak)非常类似。
9.8.2 硬件的断点指令
从图9-19可以清楚地看出,手工嵌入的brkpt指令(属于PTX指令 集)对应的硬件指令为BPT.TRAP 0x1,特别摘录的对应关系如下。
1 | |
在前面介绍硬件指令集时,细心的读者就会看到在指令列表中有 一条断点指令,名叫BPT。现在看来,BPT只是主操作符,它至少还支 持后缀.TRAP和操作数1。或许它还支持其他操作数,但是官方的公开 资料里对此讳莫如深。
9.12 CUDA GDB
9.12.2 扩展
为了支持GPU调试的特定功能,CUDA GDB对一些命令做了扩展,主 要是set和info命令。
CUDA GDB增加了一系列以set cuda开头的命令,比如set cuda break_on_launch application和set cuda memcheck on等。前者执行 后,每次启动算核函数时都会中断到调试器;后者用于启用内存检查 功能,检测与内存有关的问题。
类似地,CUDA GDB还增加了很多个以info cuda开头的命令,用于 观察GPU有关的信息。比如,info cuda devices可以显示GPU的硬件信 息。此外,info cuda后面可以跟随的参数如下。
- sms:显示当前GPU的所有流式多处理器(SM)的信息。
- warps:显示当前SM的所有Warp的信息。
- lanes:显示当前Warp的所有管线的信息。
- kernels:显示所有活跃算核的信息。
- blocks:显示当前算核的所有活跃块(active block),支持合 并格式和展开格式,可以使用set cuda coalescing on/off来切 换。
- threads:显示当前算核的所有活跃线程,支持合并格式和展开格 式,可以使用set cuda coalescing on/off来切换。
- launch trace:当在算核函数中再次启动其他算核函数时,可以 用这个命令显示当前算核函数的启动者(父算核)。
- launch children:查看当前算核启动的所有子算核。
- contexts:查看所有GPU上的所有CUDA任务(上下文)。
9.13.3 工作原理
CUDA调试API的内部实现使用的是进程外模型,调用API的代码一 般运行在调试器进程(比如cuda-gdb)中,API的真正实现运行在名为 cudbgprocess的调试服务进程中,二者通过进程间通信(IPC)进行沟 通,其协作模型如图9-25所示。
当在cuda-gdb中开始调试时,cuda-gdb会创建一个临时目录,其
路径一般为:/tmp/cuda- dbg/

其中,pid为cuda-gdb进程的进程ID,n 代表在cuda-gdb中的调试 会话序号。第一次执行run命令来运行被调试进程时,n 为1,重新运 行被调试进程调试时n 便为2。例如,作者在进程ID为2132的cuda-gdb 中第3次执行run后,cuda-gdb使用的临时目录名为/tmp/cuda-dbg/2132/session3,其内容如清单9-4所示。
第 7 章 设备虚拟化
kvm
KVM模块的源代码主要包含在Linux内核的源代码树中。以下是KVM模块的主要源码文件和功能的简要分析:
arch/x86/kvm/:这个目录包含了x86架构下KVM模块的相关源码。其中,主要的文件包括:
- kvm_main.c:KVM模块的主要逻辑和初始化代码。
- vmx.c:用于处理Intel处理器的虚拟化相关逻辑。
- svm.c:用于处理AMD处理器的虚拟化相关逻辑。
include/linux/kvm.h:定义了KVM模块的公共接口和数据结构,供其他模块使用。
virt/kvm/:这个目录包含了KVM模块的虚拟机管理相关的源码。其中,主要的文件包括:
kvm_main.c:包含了创建、销毁、启动、暂停、恢复等虚拟机管理函数的实现。
irqchip.c:处理虚拟机中断控制器相关的逻辑。
mmu.c:处理虚拟机内存管理单元(MMU)相关的逻辑。
virt/kvm/ioapic.c:用于处理虚拟机中的I/O APIC(Advanced Programmable Interrupt Controller)的源码。
virt/kvm/eventfd.c:实现了KVM模块中的eventfd事件通知机制的相关逻辑。
arch/x86/include/asm/kvm_host.h:定义了KVM模块在x86架构下的一些相关宏和数据结构。
这些源码文件涵盖了KVM模块的主要功能,包括虚拟CPU的创建与管理、内存管理、中断处理、I/O设备模拟等。要深入理解KVM模块的工作原理,需要详细阅读这些源码文件,并结合相应的文档和注释进行分析。
qemu-kvm
QEMU与KVM交互涉及到许多关键函数,其中一些主要函数包括:
kvm_init():在QEMU启动时调用,用于初始化KVM环境。
kvm_create_vm():创建一个新的虚拟机实例。
kvm_set_memory_region():设置虚拟机的内存区域。
kvm_run():开始执行虚拟机,进入主循环以处理虚拟CPU的指令执行。
kvm_ioctl():进行与KVM相关的IO控制操作,如创建虚拟CPU、设置寄存器等。
kvm_get_irqchip() 和 kvm_set_irqchip():用于获取和设置虚拟机的中断控制器。
kvm_ioeventfd():处理eventfd事件,用于虚拟机与外部的事件通信。
kvm_get_supported_cpuid():获取KVM支持的CPUID信息。
kvm_device_ioctl():与虚拟机中的设备进行IO控制交互。
这些函数是QEMU与KVM进行交互的关键函数,通过这些函数可以完成虚拟机的创建、配置、运行以及与外部设备的交互等功能。
设备虚拟化概述
设备虚拟化是虚拟化技术的一个重要方面,它允许虚拟机(VM)访问模拟的外部设备,从而使得虚拟机能够与物理硬件交互,就像是在真实的计算机上运行一样。这在云计算等场景中至关重要,因为虚拟机通常需要访问各种设备,如磁盘、网络接口、图形显示等。
QEMU 的角色与发展历程

传统纯软件模拟
- 最初,QEMU采用传统的纯软件模拟方式,通过软件实现各种外部设备的模拟。这种方式的优势在于通用性强,可以模拟几乎任何类型的设备,但性能相对较低。


转向 virtio
随着虚拟化技术的发展,QEMU逐渐引入了 virtio 总线。virtio 是一种基于共享内存的设备虚拟化标准,它通过定义一组通用的设备接口和协议,实现了虚拟机与宿主机之间的高效通信。这种方式提高了性能,同时保持了一定的通用性。

virtio 是一种前后端架构,包括前端驱动(Front-End Driver)和后端设备(Back-End Device)以及自身定义的传输协议。通过传输协议,virtio 不仅可以用于 QEMU/KVM 方案,也 可以用于其他的虚拟化方案。如虚拟机可以不必是 QEMU,也可以是其他类型的虚拟机,后端 不一定要在 QEMU 中实现,也可以在内核中实现(这实际上就是 vhost 方案,后面会详细介 绍)。

转向 VFIO 设备直通
随着硬件对虚拟化的支持不断增强,QEMU 进一步发展,引入了 VFIO(Virtual Function I/O)设备直通技术。VFIO 允许虚拟机直接访问物理设备,绕过 QEMU 的模拟层,提高了性能和效率。
常见的总线系统模拟
QEMU对常见的总线系统进行了模拟,以支持各种设备的虚拟化:
- ISA 总线: 用于模拟传统的ISA总线,支持一些古老的设备。
- PCI 总线: 模拟了PCI总线,支持更现代的设备,是虚拟机中常见的总线之一。
- USB 总线: 用于模拟USB总线及其设备,支持虚拟机中的USB设备连接。
- virtio 总线: 为了提高性能,引入了 virtio 总线,用于虚拟机内部的高效通信。
这些总线系统模拟为 QEMU 提供了广泛的设备支持,使得虚拟机能够与各种外部设备进行交互,从而更好地满足不同应用场景的需求。
7.4 virtio 设备模拟
virtio 设备模拟概述
virtio 简介
在传统设备模拟中,虚拟机内部设备驱动并不知道自己处于虚拟化环境中,导致 I/O 操作需要经过虚拟机内核栈、QEMU 和宿主机内核栈,产生大量 VM Exit 和 VM Entry,性能较差。virtio 设备模拟方案旨在提高性能,使虚拟机感知到自身处于虚拟化环境中,加载相应的 virtio 总线驱动和 virtio 设备驱动。
半虚拟化的基本原理
半虚拟化的基本原理包括两个主要部分:VMM 创建出模拟设备和操作系统内部安装好该模拟设备的驱动。在半虚拟化环境下,设备和驱动是专门为虚拟化环境设计的,通过自定义接口进行通信,减少 VM Exit 次数,提高性能。
virtio 前后端结构
- virtio 采用前后端结构,包括前端驱动(Front-End Driver)、后端设备(Back-End Device)以及自定义传输协议。virtio 不仅适用于 QEMU/KVM,还可以用于其他虚拟化方案。前端驱动负责用户态请求的接收和封装,后端设备接收前端的 I/O 请求,解析数据并完成请求,通过中断机制通知前端。
virtio 数据传输
virtio 前后端驱动的数据传输通过 virtio 队列(virtqueue)实现,一个设备可以注册多个 virtqueue,每个队列处理不同的数据传输,包括控制层面和数据层面的队列。virtqueue 通过 vring 实现,是虚拟机和 QEMU 共享的环形缓冲区。虚拟机将数据描述放入 vring,QEMU 通过读取 vring 获取数据。vring 的基本原理如图 7-21 所示。
virtio vring
virtio 设备模拟通过这种前后端协作结构和数据传输机制,旨在提高虚拟机的 I/O 性能,减少不必要的虚拟化开销。
Virtio Balloon 设备
虚拟机发送数据:
- 虚拟机内的 Virtio Balloon 设备通过 Virtio 驱动程序生成要发送的数据。这些数据通常是关于虚拟机内存需求的请求,例如请求增加或减少内存大小。
- Virtio 驱动程序将数据写入 Virtio Balloon 设备的共享内存区域。
QEMU 接收数据:
- QEMU 作为虚拟化平台运行在宿主机上,并负责模拟虚拟设备并与虚拟机进行通信。
- QEMU 定期轮询虚拟机中的 Virtio Balloon 设备,检查共享内存区域是否有数据到达。
宿主机操作系统处理数据:
- 当 QEMU 探测到 Virtio Balloon 设备的共享内存区域有数据到达时,它将通知宿主机操作系统。
- 宿主机操作系统通过与 QEMU 通信的机制(例如通过 virtiofs、virtio-mmio 等)接收到数据。
宿主机操作系统管理物理设备:
- 宿主机操作系统接收到 Virtio Balloon 数据后,会根据具体的实现方式进行处理。
- 宿主机操作系统可能会根据请求来增加或减少虚拟机所占用的物理内存。
- 宿主机操作系统使用相应的内存管理机制(如页面分配、内存映射)来分配或释放物理内存。
物理设备管理:
- 宿主机操作系统负责管理物理设备,包括实际的物理内存。
- 当宿主机操作系统根据 Virtio Balloon 数据进行内存调整时,它会与物理设备管理机制进行交互。
- 物理设备管理机制可能涉及到页表更新、内存分配器的调整等操作,以确保虚拟机的内存资源得到正确的分配。
7.5 ioeventfd 和 irqfd
ioeventfd 和 irqfd
7.5.1 eventfd 原理
eventfd 概述
eventfd 是 Linux 内核提供的一种用于在用户空间和内核空间之间进行事件通知的机制。它提供了一种通过文件描述符传递事件信息的方式。
eventfd 工作原理
创建 eventfd: 用户空间通过 eventfd 系统调用创建一个 eventfd 对象,获得一个文件描述符。
读写操作: 用户空间可以通过读写文件描述符进行事件的等待和通知。读操作可以阻塞,等待事件发生;写操作用于通知事件发生。
内核实现: 内核为每个 eventfd 对象维护一个 64 位的计数器。写操作会增加计数器的值,读操作会减少计数器的值。当计数器的值不为 0 时,读操作可以成功完成,否则读操作可能阻塞。
触发事件: 用户空间通过写操作将计数器值增加,从而通知事件的发生。每次写操作都会唤醒等待中的读操作。
使用ioeventfd机制的I/O处理流程的简单示意图:
1 | |
在这个流程中:
- 虚拟机进程发出一个I/O请求。
- KVM截获了这个I/O请求,并通知QEMU处理这个I/O请求的相关信息。
- QEMU等待eventfd的事件通知,一旦收到通知,就开始处理对应的I/O请求。
- 处理完成后,QEMU返回到主循环中等待下一个事件的到来。
- 这种流程的关键在于QEMU能够异步地处理I/O事件,而不需要立即响应虚拟机的请求,从而减少了VM Exit的次数,提高了系统的整体性能和效率。
使用传统方式处理I/O请求的流程示意图:
1 | |
在这个流程中:
- 虚拟机进程发出一个I/O请求。
- KVM截获了这个I/O请求,并直接处理这个I/O请求。
- 处理完成后,KVM需要将虚拟机切换到Host Mode,进行VM Exit。
- 在Host Mode下,QEMU处理这个I/O请求,然后将虚拟机切换回Guest Mode。
这种传统方式的关键在于每次虚拟机发出I/O请求时都需要进行VM Exit,并且需要在Host Mode下处理这个I/O请求。这样会导致频繁的上下文切换和额外的开销,降低了系统的性能和效率。
7.5.2 ioeventfd 和 irqfd
ioeventfd 概述
ioeventfd 是一种机制,允许虚拟机通过向 QEMU 注册文件描述符,实现在虚拟机中向指定 I/O 地址写入数据时触发事件。
ioeventfd 工作原理
注册 ioeventfd: 在 QEMU 中,虚拟机可以通过向 KVM 注册 ioeventfd,将一段 I/O 地址范围与一个 eventfd 关联。
触发事件: 当虚拟机写入已注册的 I/O 地址范围时,KVM 收到写操作,触发与该 I/O 地址范围关联的 eventfd,从而通知 QEMU。
QEMU 处理事件: QEMU 主循环中检测到关联的 eventfd 变为可读,执行相应的函数处理事件,绕过了 QEMU 层的分发。
irqfd 概述
irqfd 是一种机制,允许虚拟机通过向 QEMU 注册文件描述符,实现在虚拟机中触发中断。
irqfd 工作原理
注册 irqfd: 虚拟机可以通过向 KVM 注册 irqfd,将一个 eventfd 与一个虚拟中断线索引关联。
触发中断: 当虚拟机写入注册的虚拟中断线索引对应的 I/O 地址时,KVM 收到写操作,触发关联的 eventfd,从而通知 QEMU。
QEMU 处理中断: QEMU 主循环中检测到关联的 eventfd 变为可读,执行相应的函数处理中断,实现了中断的注入。
通过 ioeventfd 和 irqfd 机制,虚拟机可以更高效地与 QEMU 进行通信,减少了 VM Exit 的开销,提高了虚拟机的性能。
7.6 vhost net 简介
vhost 概述
vhost 是一种虚拟化技术,用于将虚拟机内部的 I/O 请求直接传递给宿主机内核处理,而不经过用户态的 QEMU,以提高性能。
vhost net 工作原理
前端和后端通信: 虚拟机内部的 virtio 驱动充当前端,负责封装虚拟机内的 I/O 请求到 vring 描述符中。vhost 模块在宿主机内核中作为 virtio 的后端,接收来自虚拟机的通知。
vring 描述符: 虚拟机内的 virtio 驱动通过 vring 描述符传递 I/O 请求信息。这包括需要进行的数据传输的位置、长度等信息。
vhost 处理: vhost 模块在宿主机内核中接收到来自虚拟机的通知后,直接与 tap 设备通信。这绕过了用户态的 QEMU,提高了收发包的性能。
tap 设备: 宿主机的 tap 设备负责与宿主机网络协议栈交互,将数据包发送到真实的网络设备上。
通过使用 vhost net 技术,虚拟机的网络数据包在宿主机内核中的处理路径缩短,避免了用户态和宿主机网络协议栈的多次转换,从而提高了网络性能。vhost net 主要用于优化 virtio 网卡的性能,使其更适用于高性能网络应用场景。
7.7 设备直通与 VFIO
VFIO 基本思想与原理
设备直通概述: 设备直通是一种虚拟化技术,将物理设备直接分配给虚拟机,实现虚拟机对设备的直接访问,从而提高性能。
传统设备直通问题: 传统的设备直通方法(如PCI passthrough)要求KVM完成大量工作,包括与IOMMU交互、注册中断处理函数等。这使得KVM过多地涉及与设备的交互,不够通用和灵活。
VFIO 的出现: VFIO(Virtual Function I/O)是一种用户态驱动框架,利用硬件层面的I/O虚拟化技术(如Intel的VT-d和AMD的AMD-Vi),将设备直通给虚拟机。
VFIO 的基本思想:
资源分解: 将物理设备的各种资源进行分解。
导出接口: 将获取这些资源的接口向上导出到用户空间,使QEMU等应用层软件能够获取硬件的所有资源,包括设备的配置空间、BAR(Base Address Register)空间和中断。
VFIO 工作原理: VFIO通过将设备资源导出到用户空间,使QEMU等应用能够直接与这些资源进行交互,包括对设备的配置和中断的处理,而无需KVM过多介入。这提高了设备直通的通用性和灵活性。
VFIO的引入使得虚拟化环境中设备直通更加高效,通过硬件的支持,它提供了一种通用的框架,使得用户态软件能够更灵活地进行设备直通。
聚合与 IOMMU
在VFIO思想的第二部分中,聚合是关键的一环。聚合的目的是将从硬件设备得到的各种资源整合在一起,为虚拟化展示一个完整的设备接口。这个过程在用户空间完成,以QEMU为例,它将硬件设备分解得到的资源重新整合成虚拟机设备,并将其挂载到虚拟机上。QEMU通过调用KVM的接口将这些资源与虚拟机关联,使虚拟机内部能够无感知VFIO的存在,正常与直通设备进行交互。
在虚拟化环境中,将设备直通给虚拟机带来两个挑战:设备DMA使用的地址和中断的重定向。虚拟机内部可以随意指定设备DMA地址,因此需要一种机制来隔离对设备DMA地址的访问。此外,在Intel架构上,MSI(Message Signaled Interrupt)中断通过写入地址完成,任何DMA发起者都能够写入任意数据,可能导致虚拟机内部攻击者产生不属于其的中断。
解决这些问题的关键是IOMMU(Input-Output Memory Management Unit)。IOMMU的主要功能是DMA重映射,确保设备的DMA访问仅限于由宿主机分配的内存。类似于MMU将CPU访问的虚拟机地址转换为物理地址,IOMMU对设备的DMA地址进行重映射。
IOMMU的工作原理包括DMA Remapping和Interrupt Remapping。DMA Remapping通过建立类似页表的结构来完成DMA地址的转换,确保访问仅限于被分配的物理地址。Interrupt Remapping通过IOMMU对中断请求进行重定向,将直通设备的内部中断正确分派到虚拟机。这一流程确保了设备直通的安全性和正确性。
VFIO 框架设计
VFIO框架设计简洁清晰,主要包含以下组件:
VFIO Interface: 作为接口层,向应用层导出一系列接口。用户程序如QEMU通过相应的ioctl与VFIO进行交互。
iommu driver: 物理硬件IOMMU的驱动实现,例如Intel和AMD的IOMMU。
pci_bus driver: 物理PCI设备的驱动程序。
vfio_iommu: 对底层iommu driver的封装,向上提供IOMMU功能,包括DMA Remapping和Interrupt Remapping。
vfio_pci: 对设备驱动的封装,向用户进程提供访问设备驱动的功能,包括配置空间和模拟BAR。
重要的VFIO功能之一是对各个设备进行分区。在VFIO中,有三个关键的概念:container、group和device。它们的关系如图7-55所示。
VFIO 关键概念解析
Group: Group是IOMMU能进行DMA隔离的最小单元。在一个Group内可能包含一个或多个设备,这取决于硬件IOMMU的拓扑结构。在设备直通时,一个Group内的设备必须一起直通给一个虚拟机。这是为了确保物理上的DMA隔离,防止虚拟机中的设备攻击其他虚拟机或宿主机。
Device: Device指的是要操作的硬件设备。在IOMMU拓扑中,如果设备是独立的,它自身就构成一个IOMMU Group。对于多功能设备(multi-function device),所有的function一起构成一个IOMMU Group,因为它们在物理硬件上是互联的,需要进行隔离。
Container: Container是由多个Group组成的集合。虽然Group是VFIO的最小隔离单元,但有时候并不是最佳的分割粒度。多个Group可以共享一组页表,将它们组织到一个Container中,可以提高系统性能,也更方便用户管理。通常,每个进程或虚拟机可以作为一个Container。
2.VFIO 使用方法
1 | |
2)找到这个设备的 VFIO group,这是由内核生成的。
1 | |
3)查看 group 里面的设备,这个 group 只有一个设备。
1 | |
4)将设备与驱动程序解绑。
1 | |
5)找到设备的生产商&设备 ID。
1 | |
6)将设备绑定到 vfio-pci 驱动,这会导致一个新的设备节点“/dev/vfio/15”被创建,这个 节点表示直通设备所属的 group 文件,用户态程序可以通过该节点操作直通设备的 group。
1 | |
7)修改这个设备节点的属性。
1 | |
8)设置能够锁定的内存为虚拟机内存+一些 IO 空间。
1 | |
9)向 QEMU 传递相关参数。
1 | |
VFIO中断处理

通过 VFIO 将 PCI 设备直通给虚拟机之后,vfio-pci 驱动会接管该 PCI 设备的中断,所以 vfio-pci 会为设备注册中断处理函数,该中断处理函数需要把中断注入到虚拟机中。物理机接收 到直通设备中断的时候,既可以在内核直接处理注入虚拟机中,也可以交给 QEMU 处理。本节 先讨论中断完全在内核处理的情况,这种情况下 QEMU、vfio-pci 驱动、KVM 驱动以及虚拟机 的相互关系如图 7-61 所示。

初始化过程中,QEMU 在 VFIO 虚拟设备的 fd 上调用 ioctl(VFIO_DEVICE_SET_IRQS)设置 一个 eventfd,当 vfio-pci 驱动接收到直通设备的中断时就会向这个 eventfd 发送信号。初始化过 程中,QEMU 还会在虚拟机的 fd 上调用 ioctl(KVM_IRQFD)将前述 eventfd 与 VFIO 虚拟设备的 中断号联系起来,当 eventfd 上有信号时则向虚拟机注入中断。这样即完成了物理设备触发中 断、虚拟机接收中断的流程。
QEMU 虚拟机热迁移
虚拟化环境下的热迁移指的是在虚拟机运行的过程中透明地从源宿主机迁移到目的宿主 机,热迁移的好处是很明显的,QEMU/KVM 很早就支持热迁移了。早期的 QEMU 热迁移仅支 持内存热迁移,也就是迁移前后的虚拟机使用一个共享存储,现在的 QEMU 热迁移已经支持存 储的热迁移了。本章只介绍内存热迁移。
首先来看热迁移是怎么使用的。一般来说需要迁移的虚拟机所在的源宿主机(src)和目的 宿主机(dst)需要能够同时访问虚拟机镜像,为了简单起见,这里只在两台宿主机上使用同一 个虚拟机镜像。
- 在 src 启动一个虚拟机 vm1。
1 | |
- 在 dst 启动另一个虚拟机 vm2。
1 | |
- 在 vm1 的 monitor 里面输入。
1 | |
隔了十几秒可以看到,vm2 已经成为了 vm1 的状态,vm1 则处于 stop 状态。
热迁移要满足的条件
- 1)使用共享存储,如 NFS。
- 2)源端和目的端宿主机的时间要一致。
- 3)网络配置要一致,不能只允许源端虚拟机访问某个网络,而不允许目的端虚拟机访问。
- 4)源端和目的端 CPU 类型要一致,毕竟有的时候需要宿主机导出指令集给虚拟机。
- 5)虚拟机的机器类型、QEMU 版本、ROM 版本等应一致。
内存热迁移

1)源端将虚拟机所有 RAM 设置成脏页(dirty),主要函数为 ram_save_setup。
2)持续迭代将虚拟机的脏页从源端发送到目的端,直到达到一定条件,如 QEMU 判断在 当前带宽以及虚拟机停止时间符合设定要求的情况下能够将剩余的脏页发送到目的端,这个迭 代过程调用的主要函数是 ram_save_iterate。
3)停止源端上的虚拟机,把虚拟机剩下的脏页发送到目的端,之后发送源端上虚拟机的设 备状态到目的端,这个过程涉及的主要函数为 qemu_savevm_state_complete_precopy。
其中步骤 1)和步骤 2)是图 8-6 中的灰色区域,步骤 3)是中间部分灰色区域和左边的区 域。迁移完成之后虚拟机就可以在目的端上面继续运行了。
高并发和高性能的联系?
高并发和高性能在计算机科学中密切相关,但它们指向不同的概念。
高并发(High Concurrency):指系统能够同时处理大量的并发请求或操作。这意味着系统能够有效地管理多个用户或任务同时进行的情况,而不会因此导致性能下降或系统崩溃。高并发通常与网络服务器、数据库系统和分布式系统等领域相关。一个处理高并发的系统需要有效地管理资源,避免瓶颈和资源竞争,并确保请求的快速响应。
高性能(High Performance):指系统在给定的时间内能够完成大量的工作或任务。高性能系统通常具有快速的响应时间、高吞吐量和低延迟。为了实现高性能,系统通常需要优化算法、数据结构、代码和硬件等方面,以提高系统的效率和吞吐能力。
联系:
- 高并发和高性能经常一起出现,因为处理大量并发请求是实现高性能的一个关键因素。一个能够高效处理并发请求的系统往往也是一个高性能的系统。
- 通过优化系统架构、并发处理机制、资源管理和性能调优等手段,可以同时实现高并发和高性能。例如,使用异步处理、线程池、缓存和负载均衡等技术可以提高系统的并发处理能力和性能表现。
因此,高并发和高性能是在不同层面上对系统性能的考量,但它们通常是相辅相成的。
云计算对os的特性要求?
云计算对操作系统(OS)的特性提出了一些特定要求,以满足在云环境下运行的需求。这些要求通常包括以下方面:
可伸缩性(Scalability):云计算环境需要能够根据需求动态扩展或缩减资源。因此,操作系统应该支持水平扩展和垂直扩展,以便在需要时有效地分配和管理计算、存储和网络资源。
虚拟化支持(Virtualization Support):云计算中广泛使用虚拟化技术来实现资源的隔离和共享。因此,操作系统应该具备良好的虚拟化支持,包括对虚拟机监视器(VMM)或容器运行时的良好集成,以提供高效的虚拟化性能和管理功能。
多租户支持(Multi-Tenancy Support):云计算环境中可能同时运行多个租户的应用程序和服务,因此操作系统需要提供有效的隔离机制,以确保不同租户之间的资源和数据安全性。这包括隔离内存、存储、网络和计算资源等方面。
弹性和可靠性(Resilience and Reliability):云计算环境需要具备高可用性和容错性,以保证服务的连续性。操作系统应该具备自动恢复能力,能够在硬件或软件故障发生时快速进行故障转移或恢复,以确保服务的可靠性。
安全性(Security):云计算环境中存在着各种安全威胁和攻击,因此操作系统需要提供强大的安全功能,包括身份验证、访问控制、数据加密和安全审计等功能,以保护用户数据和系统资源的安全。
灵活性(Flexibility):操作系统应该具备灵活性,能够适应不同类型的工作负载和应用场景。它应该支持多种编程模型和开发框架,并提供丰富的管理和配置选项,以满足不同用户的需求。
总的来说,云计算对操作系统提出了更高的要求,需要操作系统能够提供更多的功能和特性,以支持动态、弹性和安全的云计算环境。