大模型从0到1|第十讲:详解模型推理
大模型从0到1|第十讲:详解模型推理
Inference: 给定一个固定的模型,根据提示词(prompts)生成响应。
1. 理解推理负载 (Understanding the inference workload)
概览 (Landscape)
推理出现在很多地方:
- 实际应用:聊天机器人、代码补全、批量数据处理。
- 模型评估:例如在指令遵循任务上。
- **测试时计算 (Test-time compute)**:思考(Thinking)需要更多的推理。
- 强化学习训练:生成样本,然后评分。
为什么效率很重要:训练是一次性的成本,而推理是重复多次的。
指标:
- **Time-to-first-token (TTFT)**:用户在看到任何生成内容前等待的时间(对交互式应用很重要)。
- **Latency (seconds/token)**:用户看到token生成的速度(对交互式应用很重要)。
- **Throughput (tokens/second)**:对批量处理应用很有用。
效率的关键考量:
- **训练 (Supervised)**:你可以看到所有 tokens,可以在序列维度上并行(Transformer 中的矩阵乘法)。
- 推理:必须按顺序生成,无法并行,因此更难充分利用计算资源。
从事推理的公司:
- 提供闭源模型的服务商 (OpenAI, Anthropic, Google 等)。
- 提供开源权重模型的服务商 (Together, Fireworks, DeepInfra 等)。
开源库:
回顾 Transformer (Review Transformer)
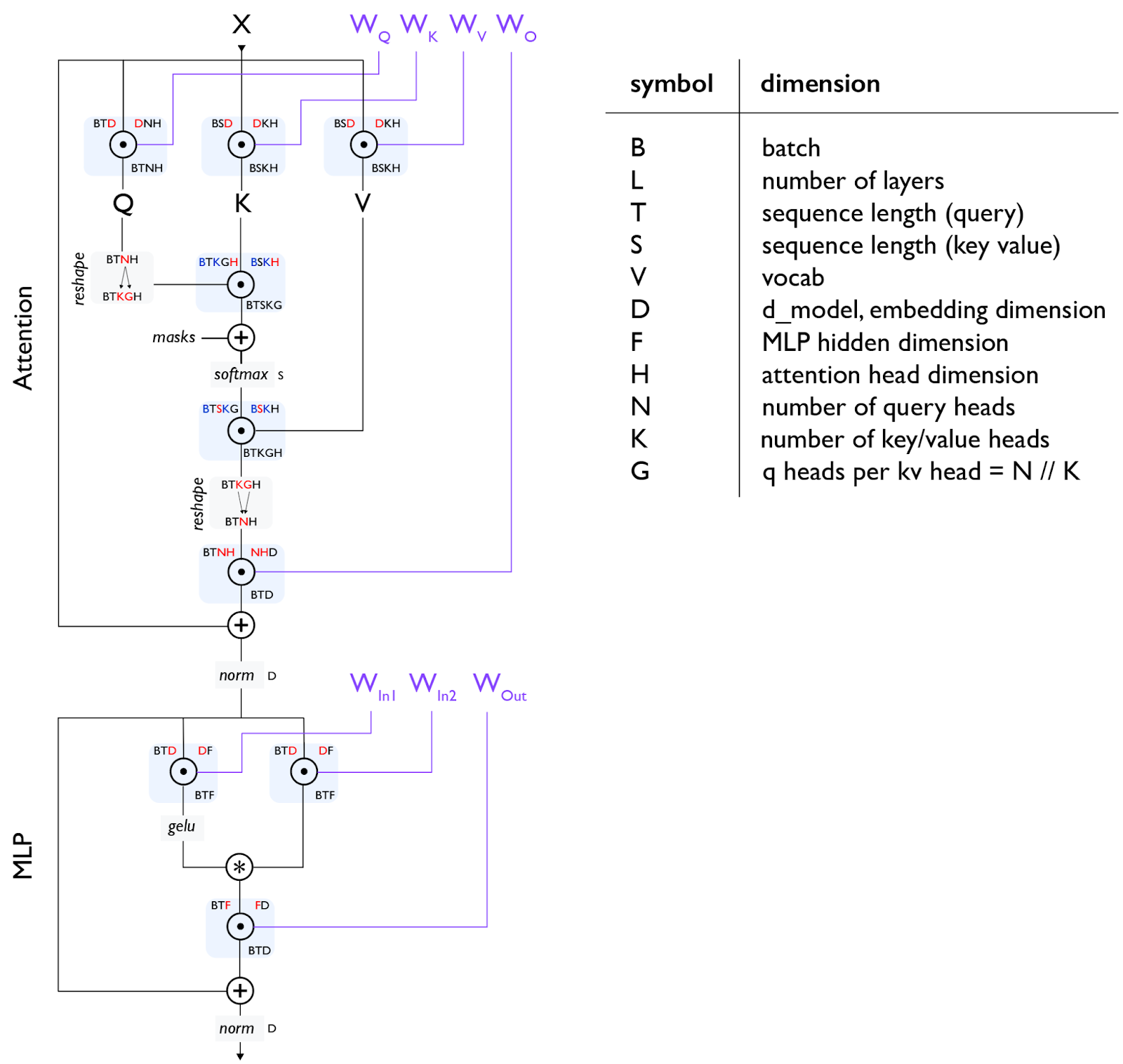
- 简化公式(遵循惯例):
F = 4*D, D = N*H, N = K*G, S = T - 前向传播的 FLOPs:
6 * (B*T) * (num_params + O(T))
回顾算术强度 (Review of Arithmetic Intensity)
设定:矩阵乘法 X (B x D) 和 W (D x F)。
- B: Batch size
- D: Hidden dimension
- F: MLP up-projection dimension
算术强度 (Arithmetic Intensity) = 计算量 (FLOPs) / 传输字节数 (Bytes Transferred)。我们希望这个值很高。
对于矩阵乘法,当 B 远小于 D 和 F 时,强度约为 B。
H100 的加速器强度:FLOPs (989e12) / Bandwidth (3.35e12) ≈ 295。
如果 计算强度 > 加速器强度:计算受限 (Compute-limited) (好)。
如果 计算强度 < 加速器强度:内存受限 (Memory-limited) (坏)。
结论:只有当 B > 295 时,才是计算受限的。
**极端情况 (B=1)**:对应矩阵-向量乘积。
- 算术强度:1。
- 内存受限:读取 D x F 矩阵,只执行 2DF FLOPs。
- 这基本上就是生成阶段发生的事情…
推理的算术强度 (Arithmetic Intensity of Inference)
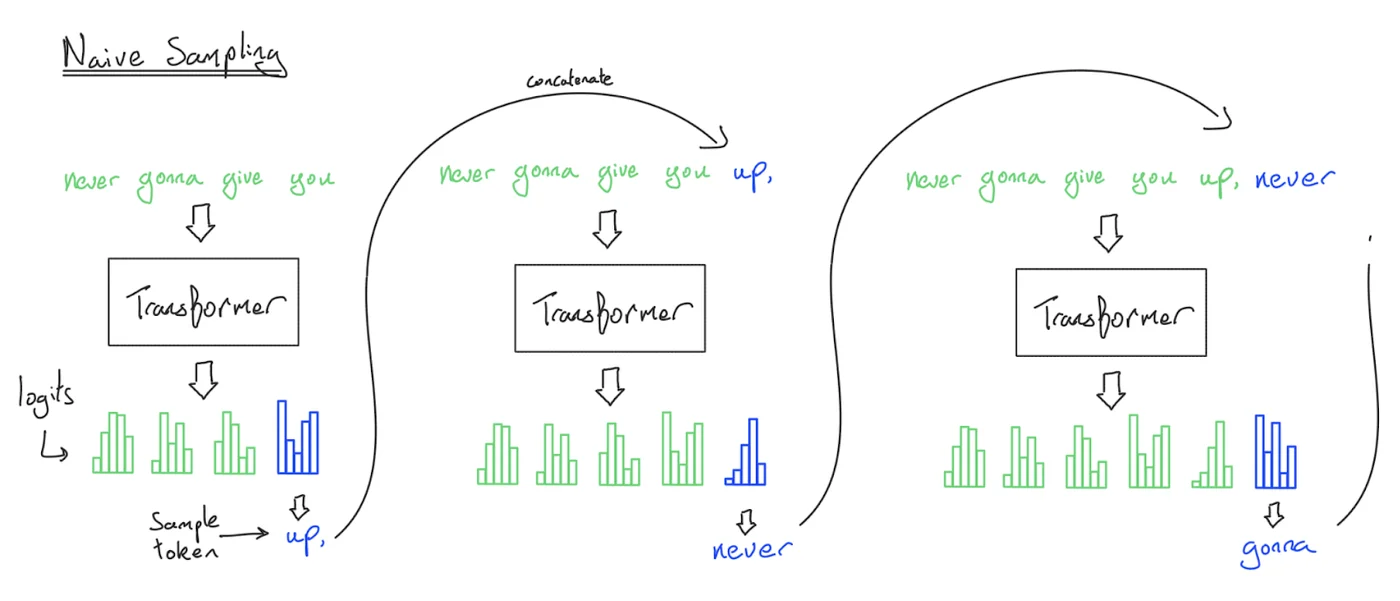
- 朴素推理:生成每个 token 时,将历史记录输入 Transformer。复杂度 O(T^3)。
- 解决方案:在 HBM 中存储 KV Cache。
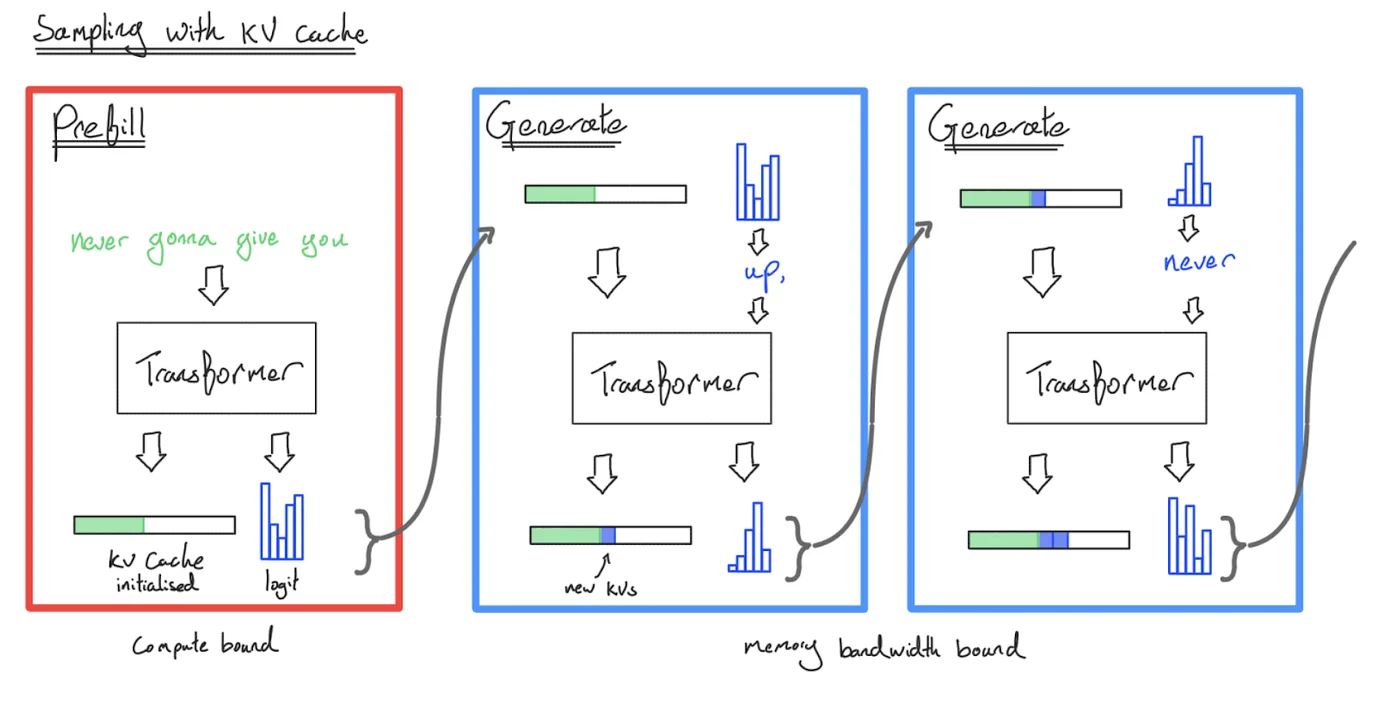
- KV Cache:为每个序列 (B)、token (S)、层 (L)、头 (K) 存储一个 H 维向量。
推理的两个阶段:
- **Prefill (预填充)**:给定提示词,编码成向量(像训练一样可并行)。
- **Generation (生成)**:生成新的响应 token(串行)。
MLP 层:
- 强度 ≈ B*T。
- Prefill:容易做到计算受限(通过增大 B*T)。
- Generation (T=1):B 是并发请求数,很难做得足够大!
Attention 层:
- 强度 ≈ S*T / (S + T)。
- Prefill (T=S):强度 ≈ S/2 (好!)。
- Generation (T=1):强度 < 1 (坏!)。
- 注意:Attention 层不依赖于 B,所以增大 Batch size 没用!因为每个序列都有自己的 KV Cache,必须分别读取。
总结:
- Prefill 是计算受限的。
- Generation 是内存受限的。
- MLP 强度取决于 B(需要并发请求),Attention 强度为 1(无法通过 Batching 提高)。
吞吐量与延迟 (Throughput and Latency)
推理是内存受限的。
- 内存使用:参数 + KV Cache。
- **延迟 (Latency)**:由内存 IO 决定(每步读取所有参数和 KV Cache)。
- **吞吐量 (Throughput)**:B / Latency。
**权衡 (Tradeoff)**:
- 较小的 Batch size:延迟更好,但吞吐量更差。
- 较大的 Batch size:吞吐量更好,但延迟更差。
并行化:
- 简单并行:启动 M 个模型副本,延迟不变,吞吐量增加 M 倍。
- 困难并行:对模型和 KV Cache 进行分片 (Sharding)。
注意:TTFT 本质上是 Prefill 的函数。
- Prefill 阶段使用较小 Batch size 以获得更快的 TTFT。
- Generation 阶段使用较大 Batch size 以提高吞吐量。
2. 走捷径 (有损) (Taking shortcuts - lossy)
既然内存是瓶颈,我们尝试减少 KV Cache 的大小,但要确保精度不下降太多。
Grouped-query attention (GQA)
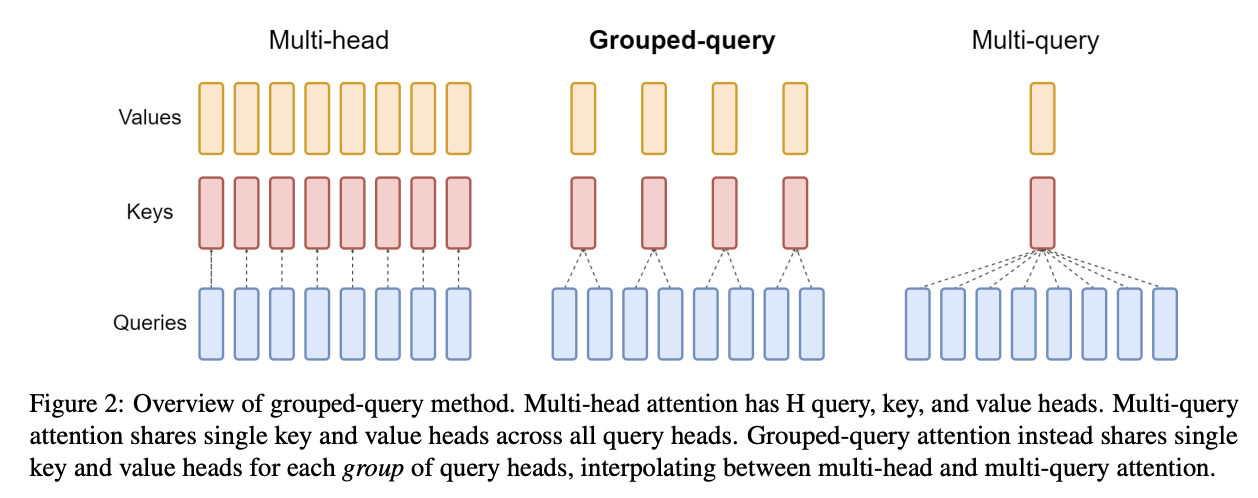
- Idea:N 个查询头 (Query heads),但只有 K 个键值头 (Key/Value heads)。
- MHA (Multi-headed attention): K=N
- MQA (Multi-query attention): K=1
- GQA: K 在中间。
- 效果:将 KV Cache 减少 N/K 倍。允许使用更大的 Batch size,从而提高吞吐量。
Multi-head latent attention (MLA)
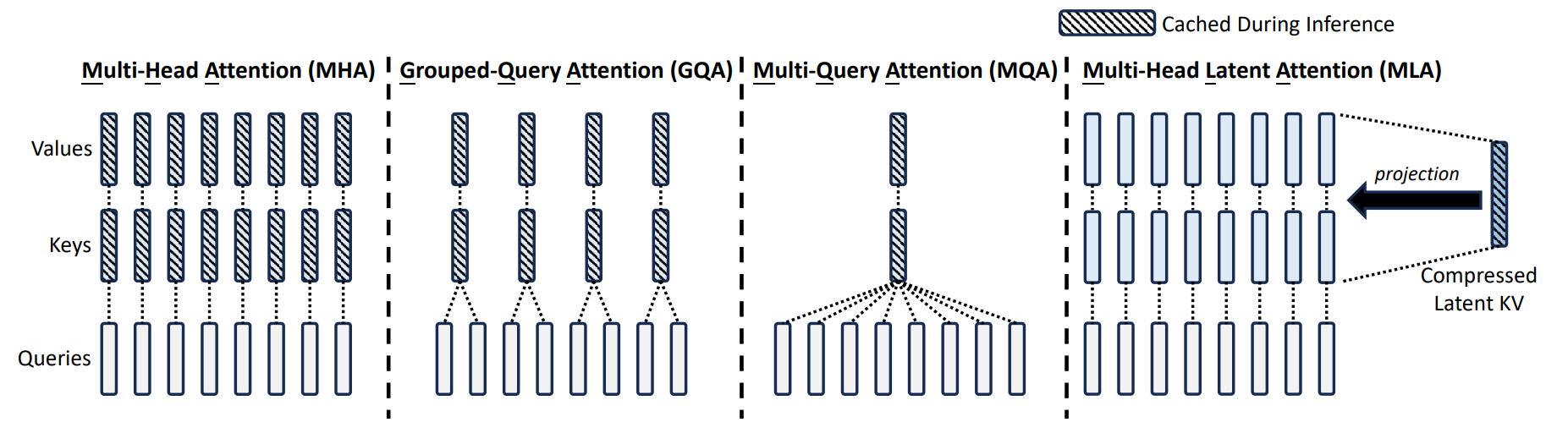
- Idea:将每个 Key 和 Value 向量从 N*H 维投影到 C 维。
- DeepSeek v2:将 16384 维减少到 512 维(+64 RoPE 维)。
- 效果:比 MHA 便宜得多,精度比 MHA 稍好(DeepSeek 论文结果)。
Cross-layer attention (CLA)
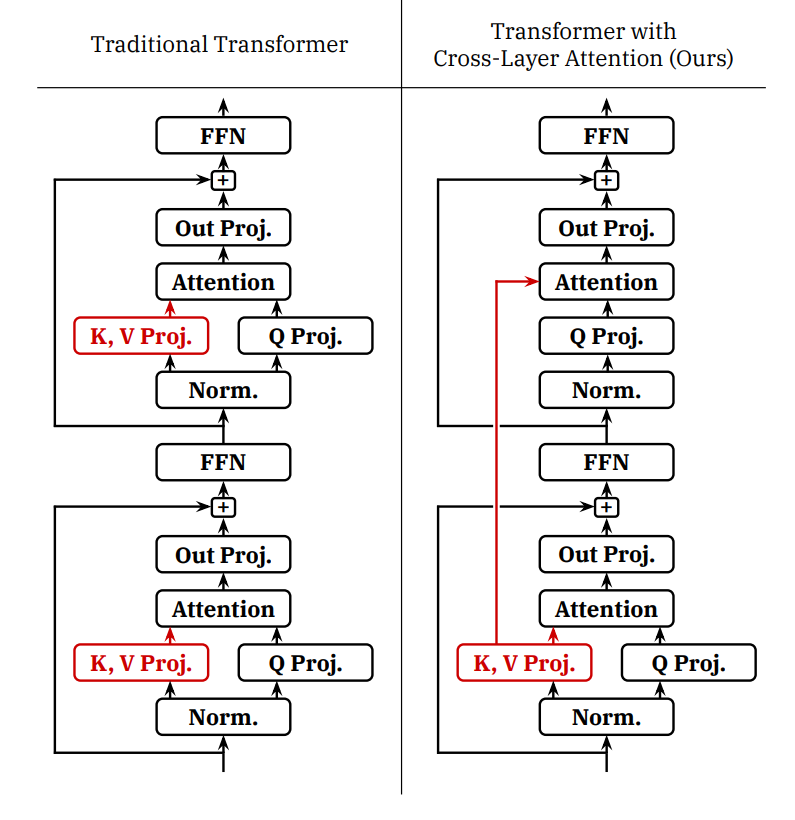
- Idea:跨层共享 KV(就像 GQA 跨头共享 KV 一样)。
- 实证结果表明它改善了精度和 KV Cache 大小的帕累托前沿。
Local attention (局部注意力)
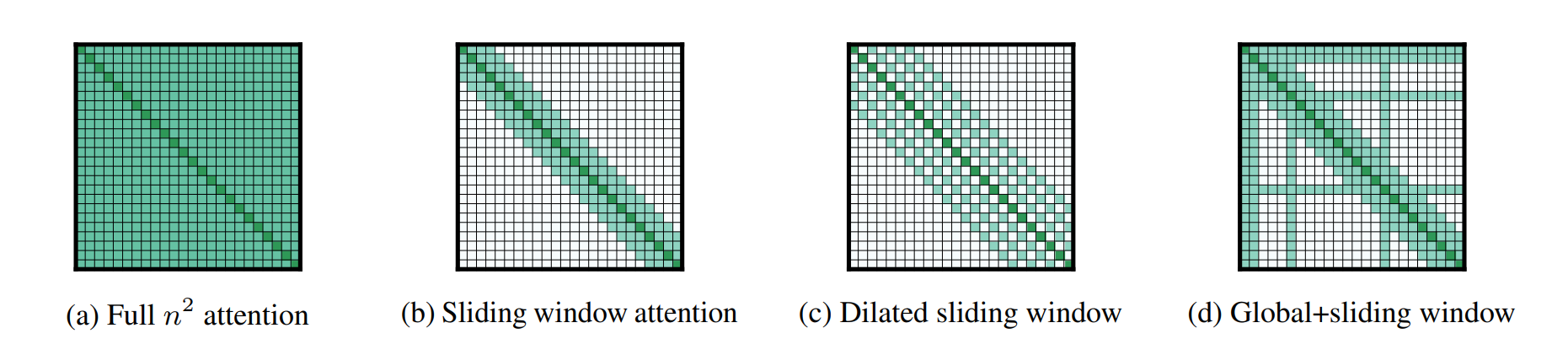
- Idea:只看局部上下文。
- KV Cache 大小独立于序列长度!
- 问题:可能损害精度。
- 解决方案:与全局注意力层交替使用(混合层)。例如 character.ai 每 6 层使用 1 个全局层。
Transformer 的替代品 (Alternatives to the Transformer)
Attention + Autoregression 本质上是内存受限的。
State-space models (状态空间模型)
- Idea:从信号处理出发,以次二次时间复杂度建模长序列。
- S4:擅长合成长上下文任务,但在此联想回忆任务上表现不佳。
- Mamba:允许 SSM 参数依赖于输入,在 1B 规模上匹配 Transformer。
- Jamba:交替使用 Transformer-Mamba 层。
- BASED / MiniMax-01:使用线性注意力 + 局部注意力。
- Takeaway:将 O(T) 的 KV Cache 替换为 O(1) 的状态 => 推理效率大大提高。
Diffusion models (扩散模型)
- Idea:并行生成每个 token(非自回归),多次迭代细化。
- 从随机噪声开始,迭代去噪。
- Inception Labs 的结果显示在编码基准测试中速度更快。
量化 (Quantization)
关键思想:降低数值精度。更少的内存意味着更低的延迟/更高的吞吐量。
- **fp32 (4 bytes)**:训练所需。
- **bf16 (2 bytes)**:推理默认值。
- **fp8 (1 byte)**:H100 支持。
- **int8 (1 byte)**:精度较低,推理专用。
- **int4 (0.5 bytes)**:更便宜,精度更低。
方法:
- **LLM.int8()**:解决离群值问题(混合精度,离群值用 fp16)。
- **Activation-aware quantization (AWQ)**:根据激活值选择保留哪些权重(0.1-1%)的高精度。
模型剪枝 (Model Pruning)
关键思想:直接去掉昂贵模型的一部分,然后修复它。
- NVIDIA 论文:识别重要的层/头/隐藏维,移除不重要的,然后蒸馏。
3. 走捷径 (无损) (Use shortcuts but double check - lossless)
投机采样 (Speculative Sampling)

- 回顾:Prefill(检查)比 Generation(生成)快。
- Idea:使用一个便宜的 Draft model (草稿模型) 猜测几个 token,然后用 Target model (目标模型) 并行验证。
- 关键属性:保证从目标模型进行精确采样(数学上等价)!
- 扩展:Medusa (并行生成多个 token), EAGLE (利用目标模型的特征)。
4. 处理动态负载 (Handling dynamic workloads)
连续批处理 (Continuous Batching)
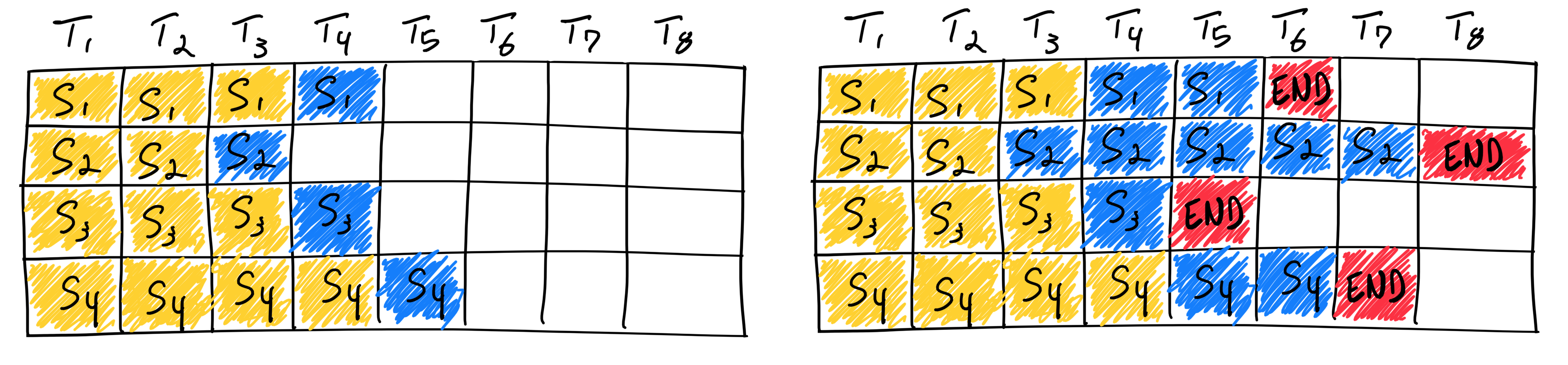
- 问题:推理请求到达和结束时间不同,形成参差不齐的数组 (Ragged array)。
- 解决方案:迭代级调度。一步一步解码,新请求到达时直接加入 Batch,不需要等待当前 Batch 完成。
分页注意力 (Paged Attention)
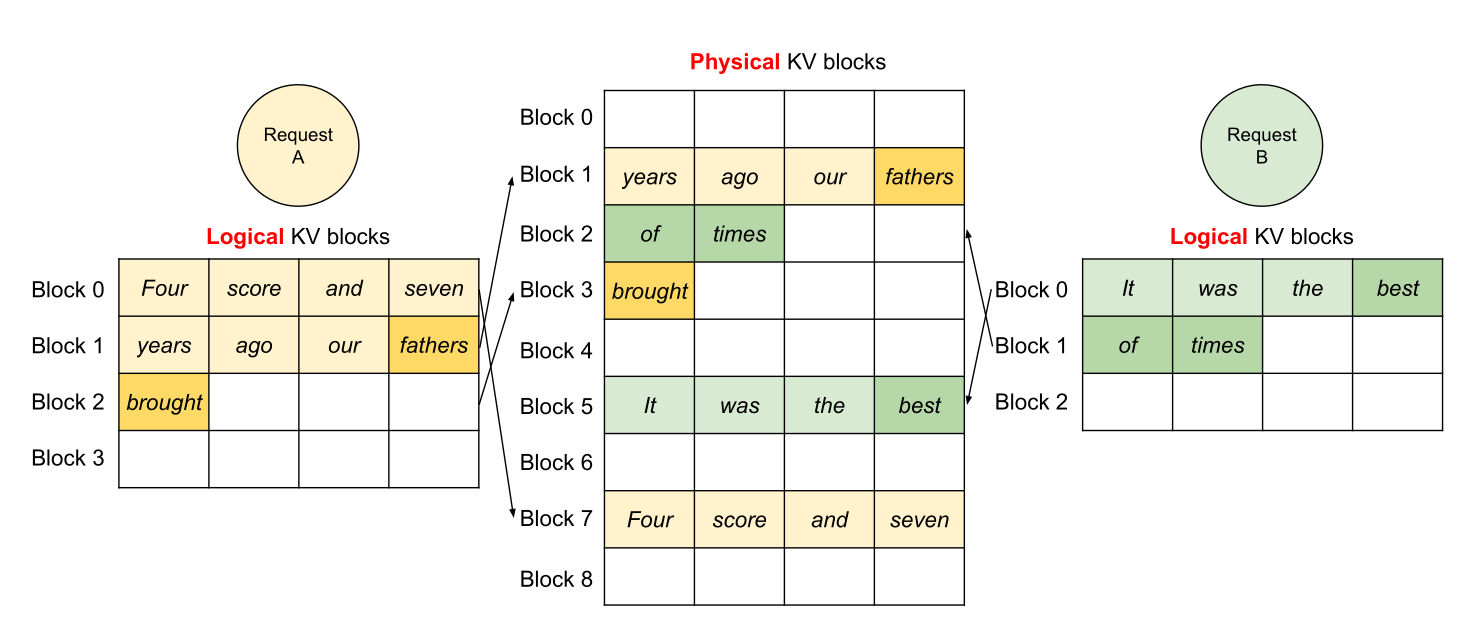
- 问题:KV Cache 导致内存碎片化(内部和外部碎片)。
- 解决方案:PagedAttention(借鉴操作系统)。将 KV Cache 分成不连续的**块 (Blocks)**。
- 优势:
- 消除碎片。
- 共享内存:多个请求可以共享系统提示词或共享前缀(Copy-on-write)。
总结
- 推理很重要:实际使用、评估、强化学习。
- 特点:与训练不同,推理通常是内存受限的,且负载是动态的。
- 技术:
- 新架构 (GQA, MLA, SSM)。
- 量化 (Quantization)。
- 剪枝/蒸馏 (Pruning/Distillation)。
- 投机解码 (Speculative decoding)。
- 系统思想:投机执行、分页 (Paging)。
- 潜力:新架构在推理效率上有巨大的提升空间。
大模型从0到1|第十讲:详解模型推理
https://realwujing.github.io/linux/drivers/gpu/stanford-cs336/大模型从0到1|第十讲:详解模型推理/