大模型从0到1|第三讲:详解现代LLM基础架构
本文最后更新于:2025年11月24日 晚上
大模型从0到1|第三讲:详解现代LLM基础架构
课程信息:CS336 | 讲师:Tatsu H | 幻灯片总数:68
Part 1: 课程概览 (Introduction)

Page 1: 标题页
- 内容: 课程名称 “Lecture 3: Everything you didn’t want to know about LM architecture and training”。
- 解析: 这一讲主要关注那些我们在调用 API 时看不到,但自己训练模型时必须决定的“肮脏细节”。
Page 2: 课程目标 (Outline & Goals)
- 内容:
- 回顾标准 Transformer。
- 分析主流大模型(Big LMs)的架构共性。
- 探讨常见的架构变体(Variations)及其取舍。
- 核心: “Today’s theme: the best way to learn is hands-on experience… try to learn from others.”(从前人的实验中总结最佳实践)。

Page 3: 后勤通知 (Logistics)
- 内容: 加入 Slack,检查作业版本等行政事项。
Page 4: 技术大纲
- 内容:
- 架构变体: 激活函数、FFN 设计、Attention 变体、位置编码。
- 超参数: 哪些参数重要(Scale)?哪些不重要?
- 稳定性: 如何防止训练崩溃(Stability tricks)。
Part 2: 架构演进与共性 (The Landscape)
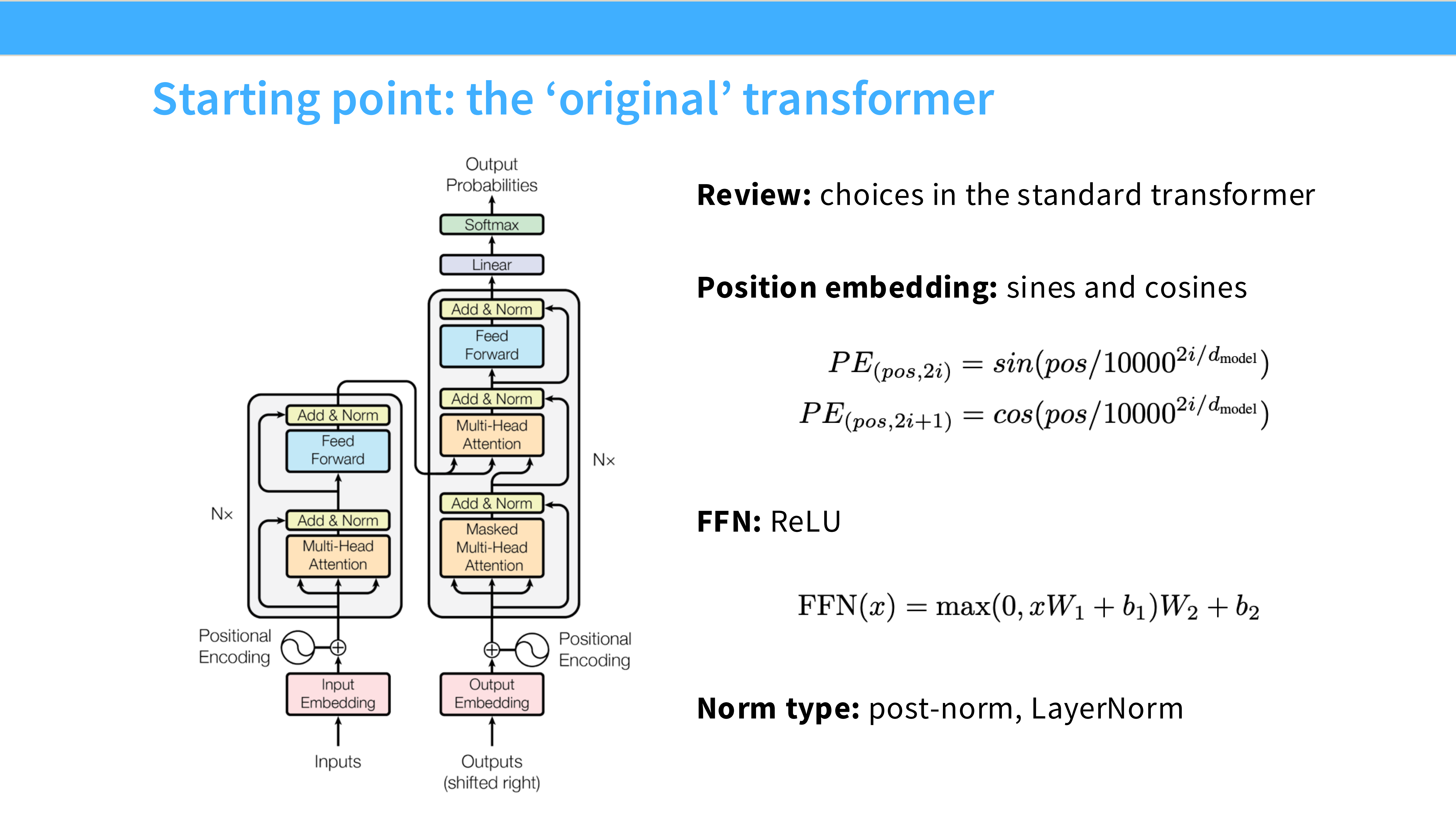
Page 5: 原始 Transformer (The Original)
- 内容: 经典的 Attention is All You Need 架构图。
- 关键特征:
- Post-Norm: Add & Norm 在子层之后。
- Sinusoidal: 正弦位置编码。
- ReLU: 激活函数。
- Bias: 全连接层带有偏置项。

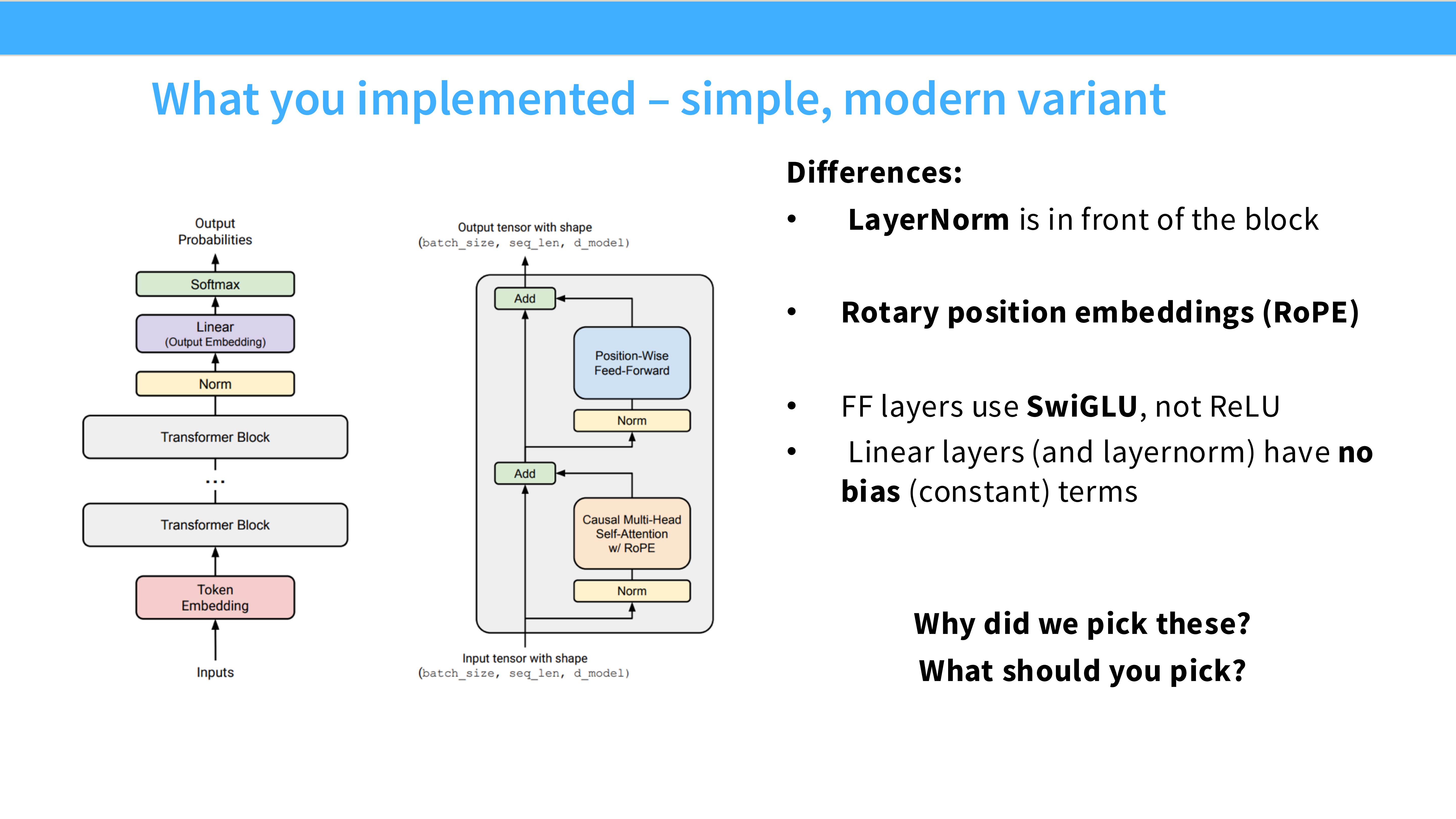
Page 6: 现代架构的“标准答案” (Modern Variant)
- 内容: 这就是你们在作业中要实现的架构(类似 Llama)。
- 改进点:
- Pre-Norm: Norm 放在子层之前。
- RMSNorm: 替代 LayerNorm。
- RoPE: 旋转位置编码。
- SwiGLU: 替代 ReLU。
- No Bias: 去掉 Bias。
Page 7: 模型大爆发
- 内容: 列举了近年来发布的各种模型(Llama 3, Nemotron, Qwen 1.5, Gemma 等)。
- 解析: 虽然名字不同,但它们在架构上惊人地相似,大多是对 Page 6 所述架构的微调。

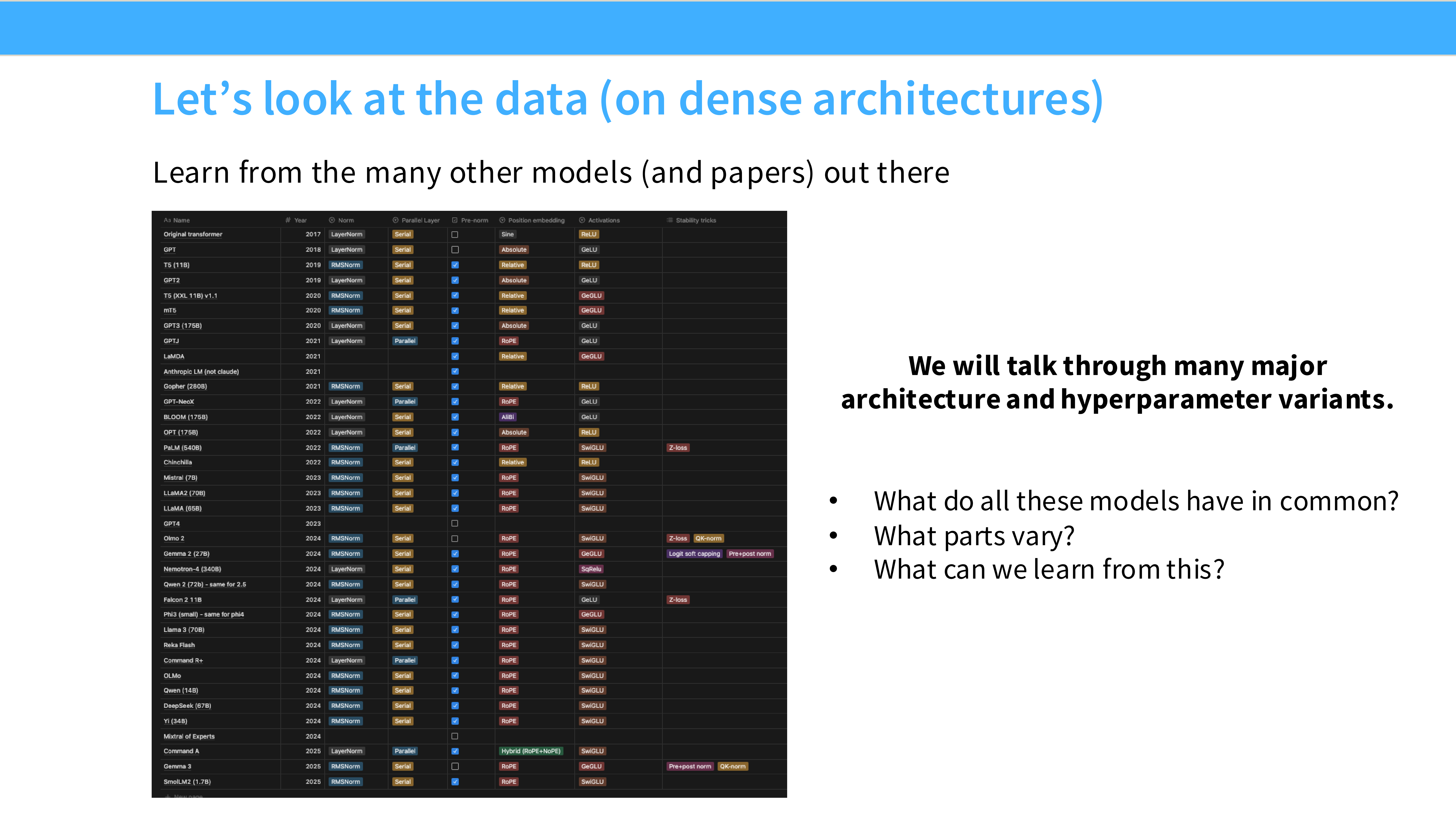
Page 8: 架构统计大表 (The Data)
- 内容: 一个详细的表格,横轴是模型(GPT-3, PaLM, Llama, Chinchilla 等),纵轴是配置(Norm 类型, Pos Emb, Activation)。
- 趋势: 可以明显看到从早期的混乱(各种尝试)到后期的统一(Pre-norm, RoPE, SwiGLU 占主导)。

Page 9: 架构共性总结
- 内容: High level view。
- Pre-norm: 现在的绝对主流。
- RMSNorm: Llama 系列, PaLM, Gopher 使用。
- SwiGLU: Llama 系列, PaLM, Mistral 使用。
- RoPE: 几乎所有现代模型(除了 ALiBi 的少数拥护者)都使用。
Part 3: 归一化层详解 (Normalization)
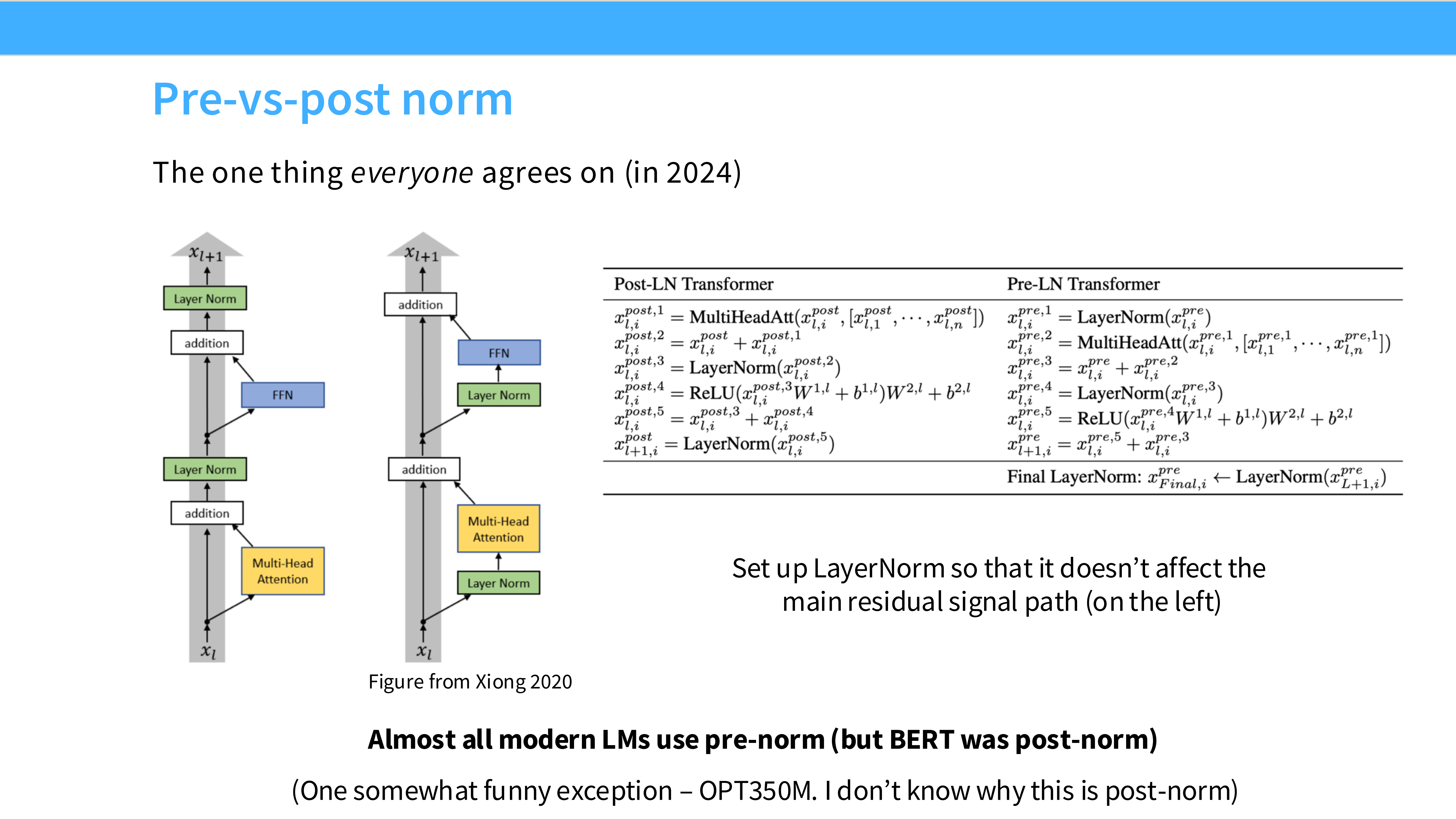
Page 10: Pre-Norm vs Post-Norm 结构图
- 左图 (Post-LN): $x = Norm(x + f(x))$。BERT 时代的主流。
- 右图 (Pre-LN): $x = x + f(Norm(x))$。GPT-2 之后的主流。
- 区别: Pre-LN 保证了残差主干(Identity path)的纯净,梯度可以直接流到底。
Page 11: 为什么选 Pre-Norm? (原理)
- 内容: 引用 Xiong 2020。
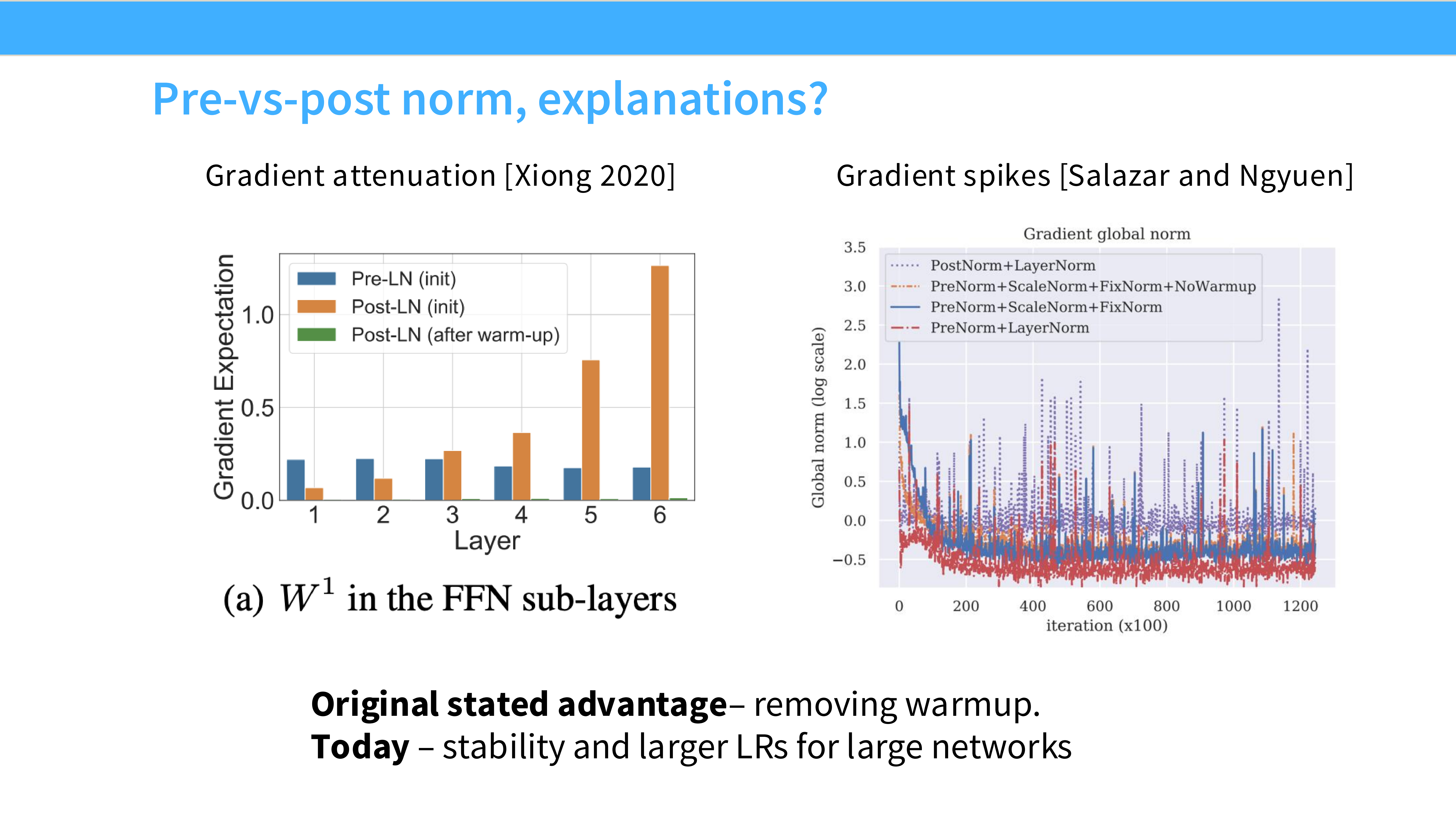
- 核心: Pre-LN 使得深层网络的梯度范数(Gradient Norm)更稳定。它消除了梯度爆炸/消失的风险,使得我们可以使用更大的学习率,并且不需要很长时间的 Warmup。
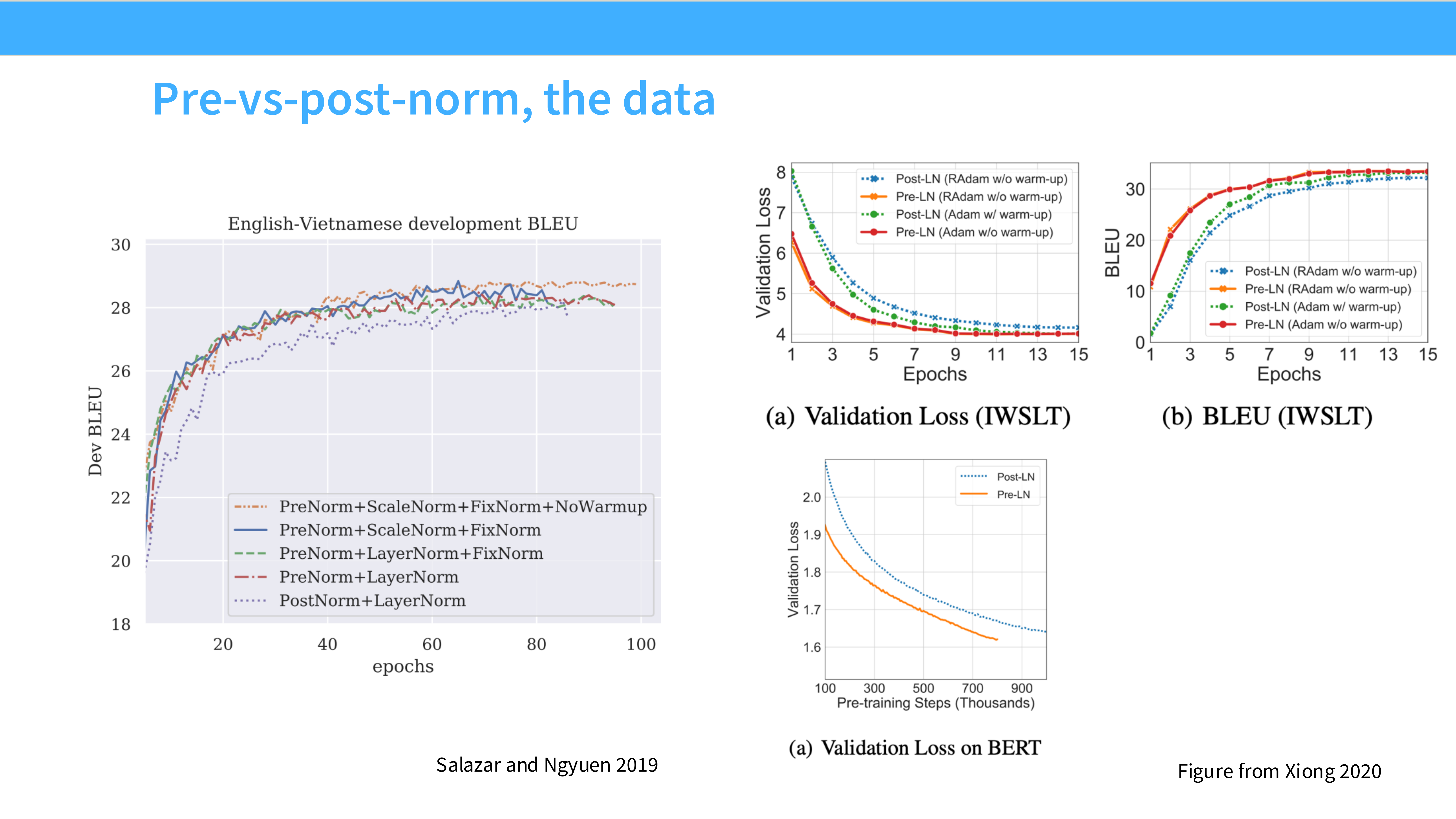
Page 12: Pre/Post Norm 的实验对比
- 内容: 训练曲线图 (IWSLT)。
- 结论: Post-LN(蓝线)如果没有精心设计的 Warmup 很容易炸或者是收敛慢;Pre-LN(红/绿线)则非常稳健,收敛更快。
Page 13: 梯度范数可视化
- 内容: 图表展示了不同层级的梯度大小。
- 解析: Post-LN 的梯度在反向传播时,到底层会变得非常小(梯度消失);Pre-LN 的梯度在所有层级保持一致。
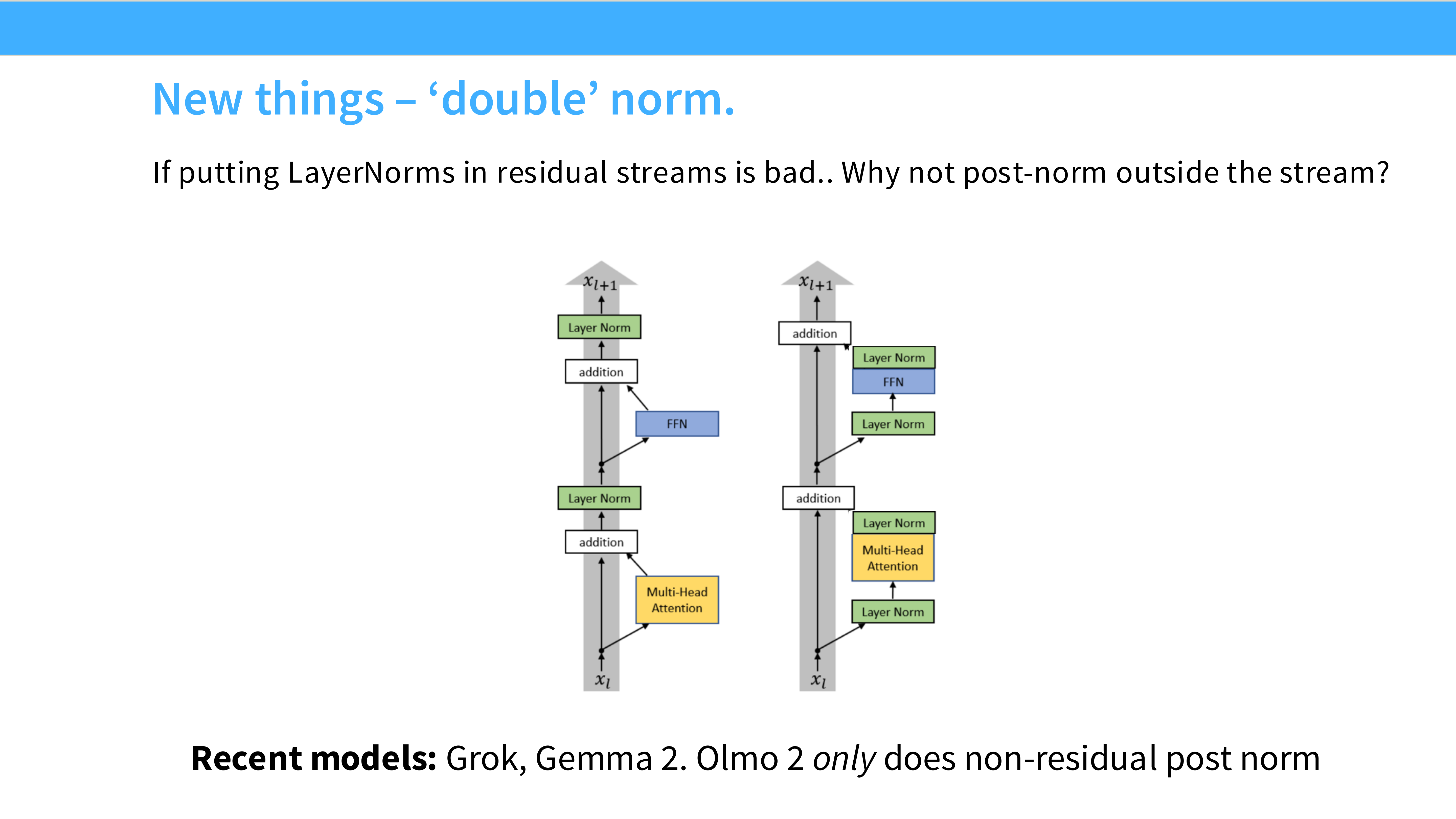
Page 14: 新趋势 - Double Norm?
- 内容: 提到了一些最新的模型(如 Grok, Gemma 2)。
- 做法: 它们在 Pre-Norm 的基础上,又在残差块的输出位置加了一个 Norm。这是一种“双保险”,为了在大规模训练时获得极致的稳定性。

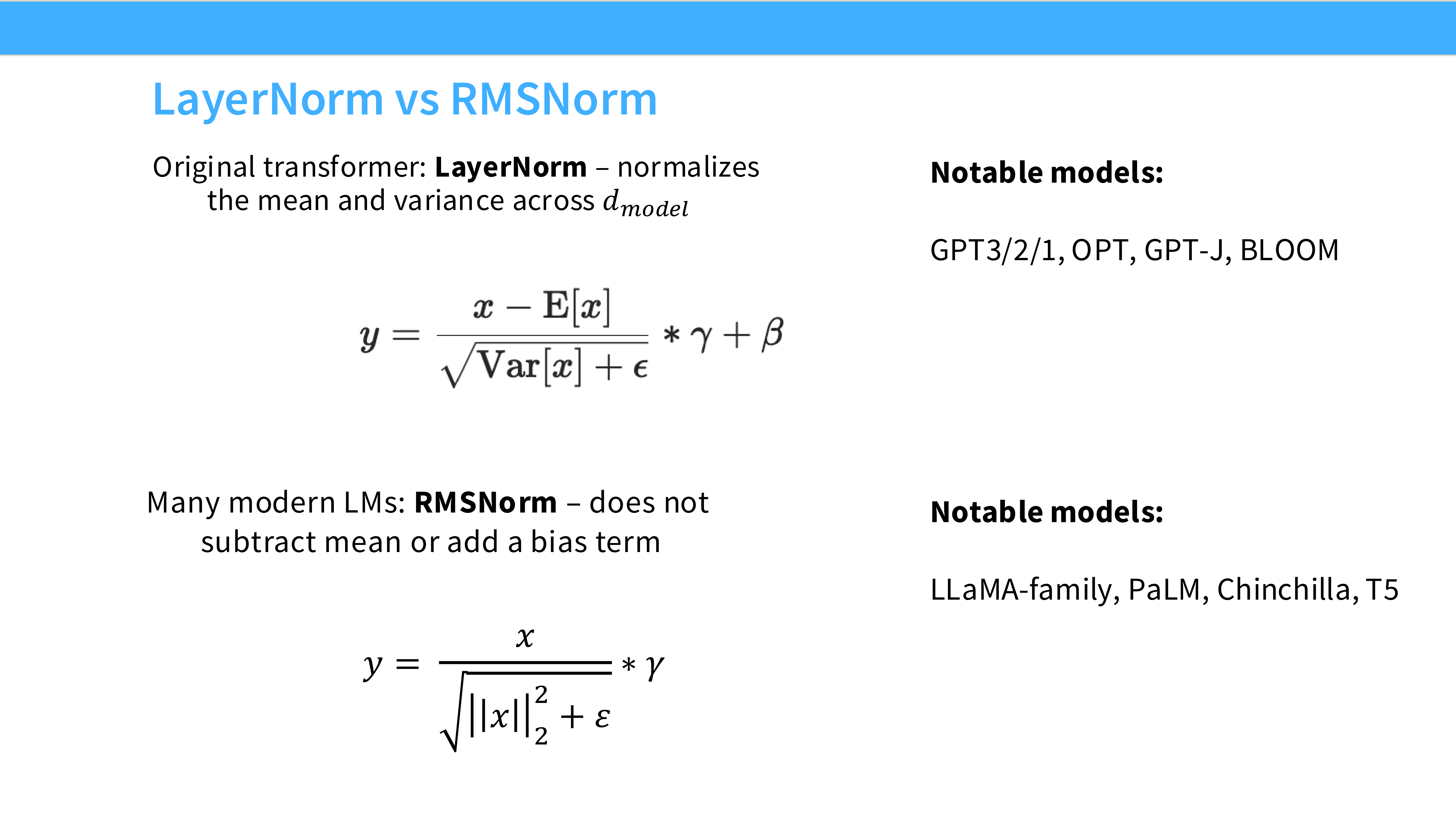
Page 15: LayerNorm 回顾
- 内容: 标准 LayerNorm 的公式。
- 需要计算 Mean $\mu$ 和 Variance $\sigma^2$。
- 操作:Centering (减均值) + Scaling (除标准差)。
Page 16: RMSNorm (Root Mean Square Norm)
- 内容: 公式:$y = \frac{x}{\text{RMS}(x)} * \gamma$。
- 核心: 去掉了减均值的操作。只做缩放(Rescaling),不做中心化(Re-centering)。
- 使用者: LLaMA, PaLM, T5。
Page 17: 为什么 RMSNorm 有效?
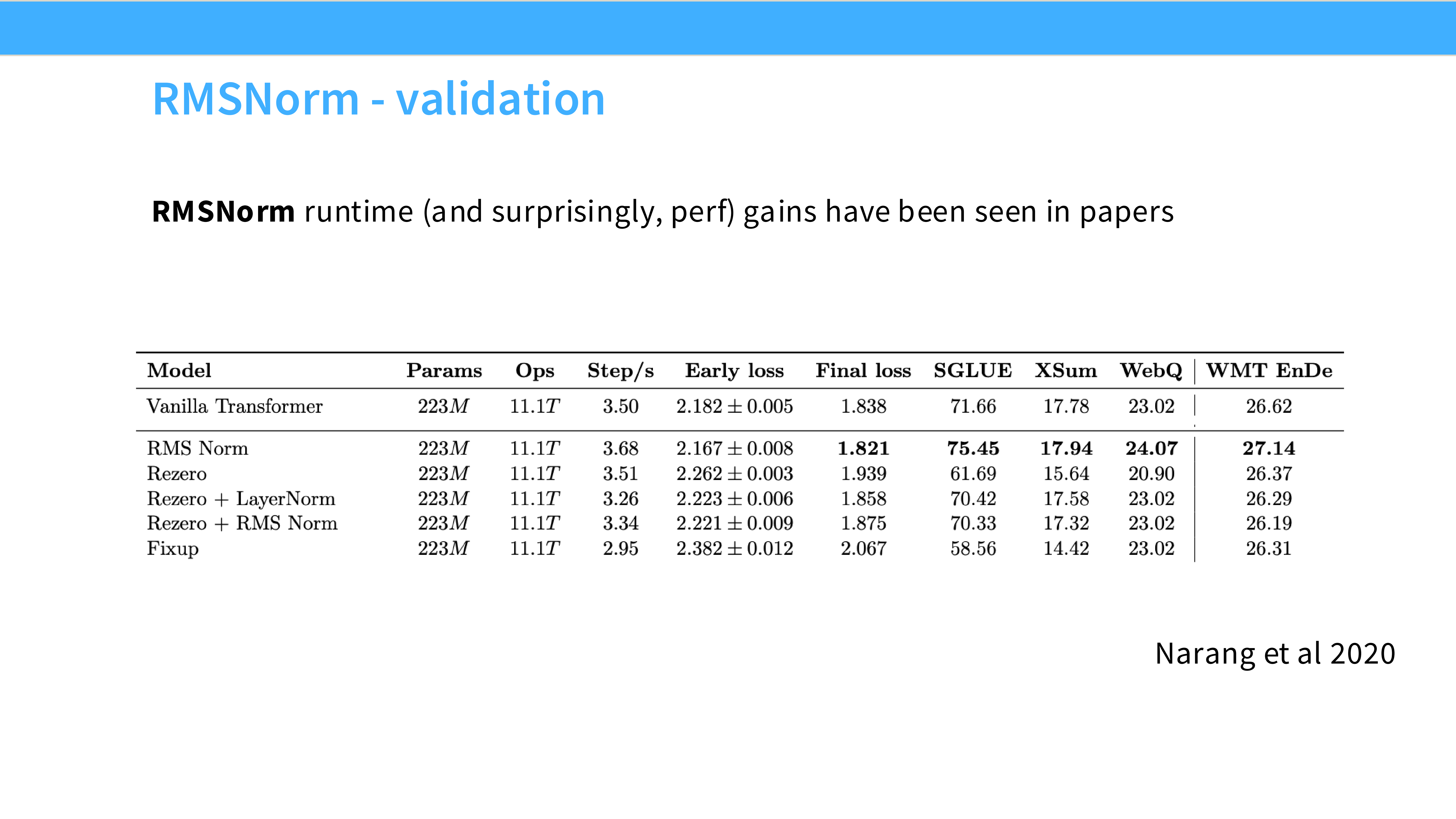
- 内容: 引用 Bjorck et al 2018。
- 解释: 实验发现 LayerNorm 的成功主要归功于 Scaling(缩放不变性),Mean(平移不变性)其实没啥用。既然没用,为了速度就干掉它。

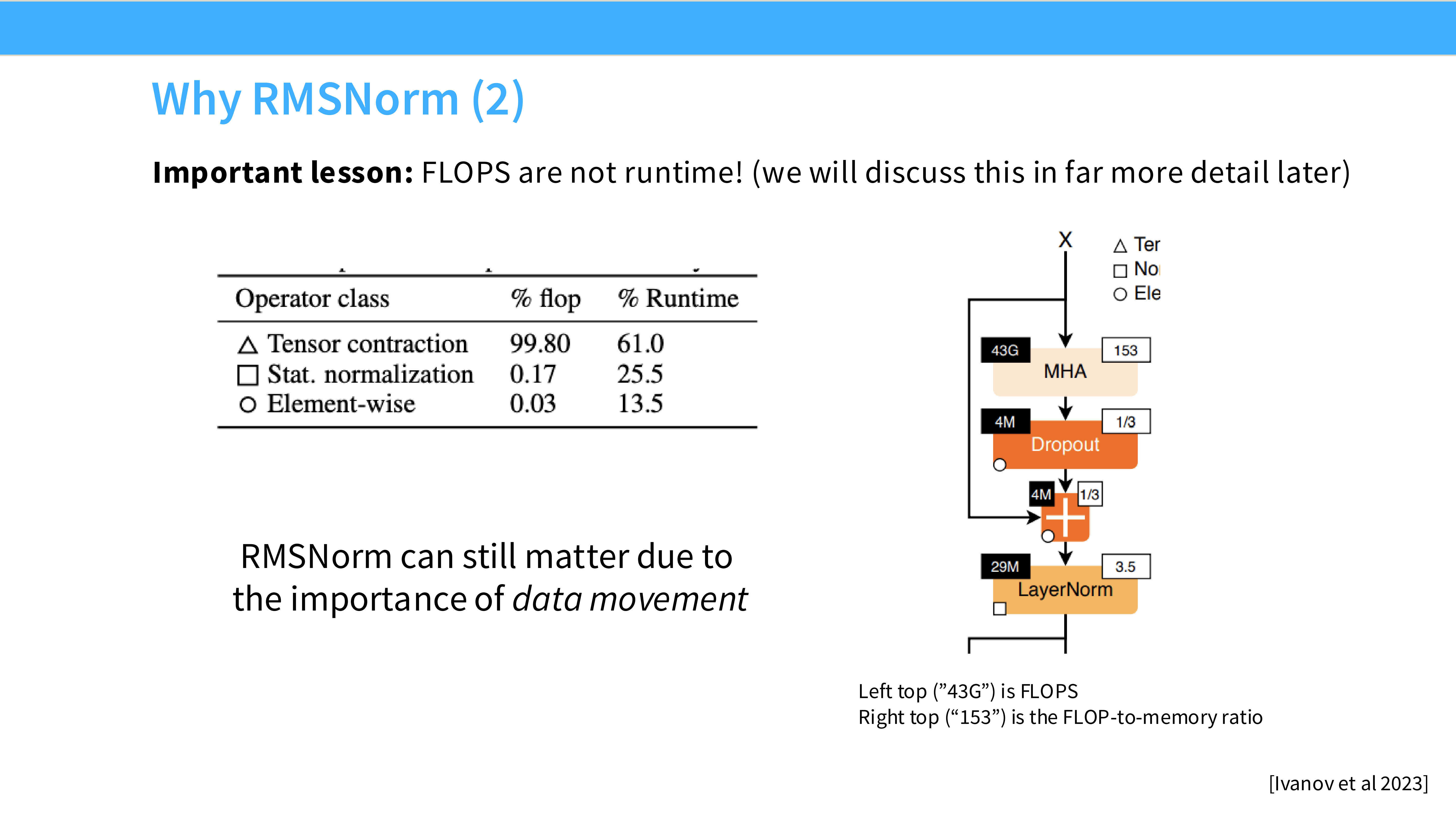
Page 18: RMSNorm 的速度优势
- 内容: 性能对比表。
- 结论: 少了均值计算,RMSNorm 在 GPU 上通常能带来 10% - 40% 的速度提升(取决于实现细节)。这是大家在这个时代选择它的主要原因——快。

Page 19: 移除偏置项 (No Bias)
- 内容: 许多现代模型(PaLM, Llama)移除了所有 Linear 层和 Norm 层的 Bias 参数。
- 原因:
- 对性能(PPL)几乎无影响。
- 提升训练稳定性(Stability)。
- 稍微减少一点显存和通信量。
Part 4: 激活函数 (Activations)

Page 20: 激活函数概览
- 内容: 标题页。我们将看到从 ReLU 到 SwiGLU 的演进。

Page 21: 经典激活函数
- ReLU: $max(0, x)$。简单,稀疏。
- GeLU: $x \Phi(x)$。BERT/GPT 使用。平滑,非线性更强。

Page 22: GLU (Gated Linear Units) 家族
- 内容: 介绍“门控”机制。
- 普通 FFN: $Act(xW_1)W_2$
- GLU FFN: $(Act(xW_1) \odot xV_1) W_2$
- 解析: 引入了额外的投影层 $V_1$ 作为“门”,通过逐元素乘法控制信息流。

Page 23: GeGLU
- 内容: 激活函数用 GeLU 的 GLU。
- 公式: $\text{GeLU}(xW) \odot (xV) W_2$
- 代表: PaLM, T5。
Page 24: SwiGLU (The Winner)
- 内容: 激活函数用 Swish 的 GLU。
- 公式: $\text{Swish}(xW) \odot (xV) W_2$
- 代表: LLaMA, Mistral。
- 注意: 因为多了 $V$ 矩阵,为了参数量公平对比,通常会把 FFN 的中间维度从 $4d$ 降到 $\frac{8}{3}d$ (约 2.67d)。
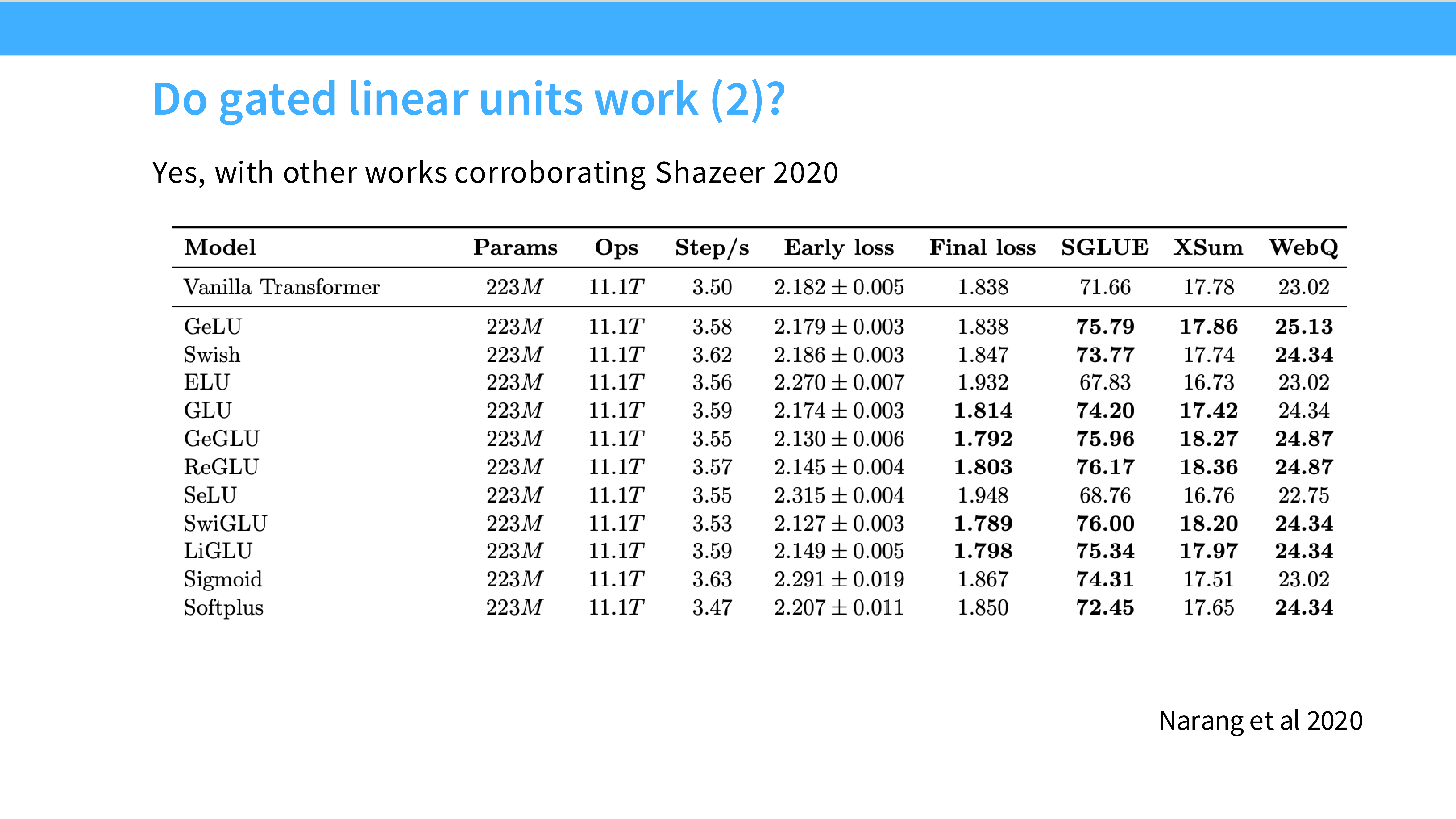
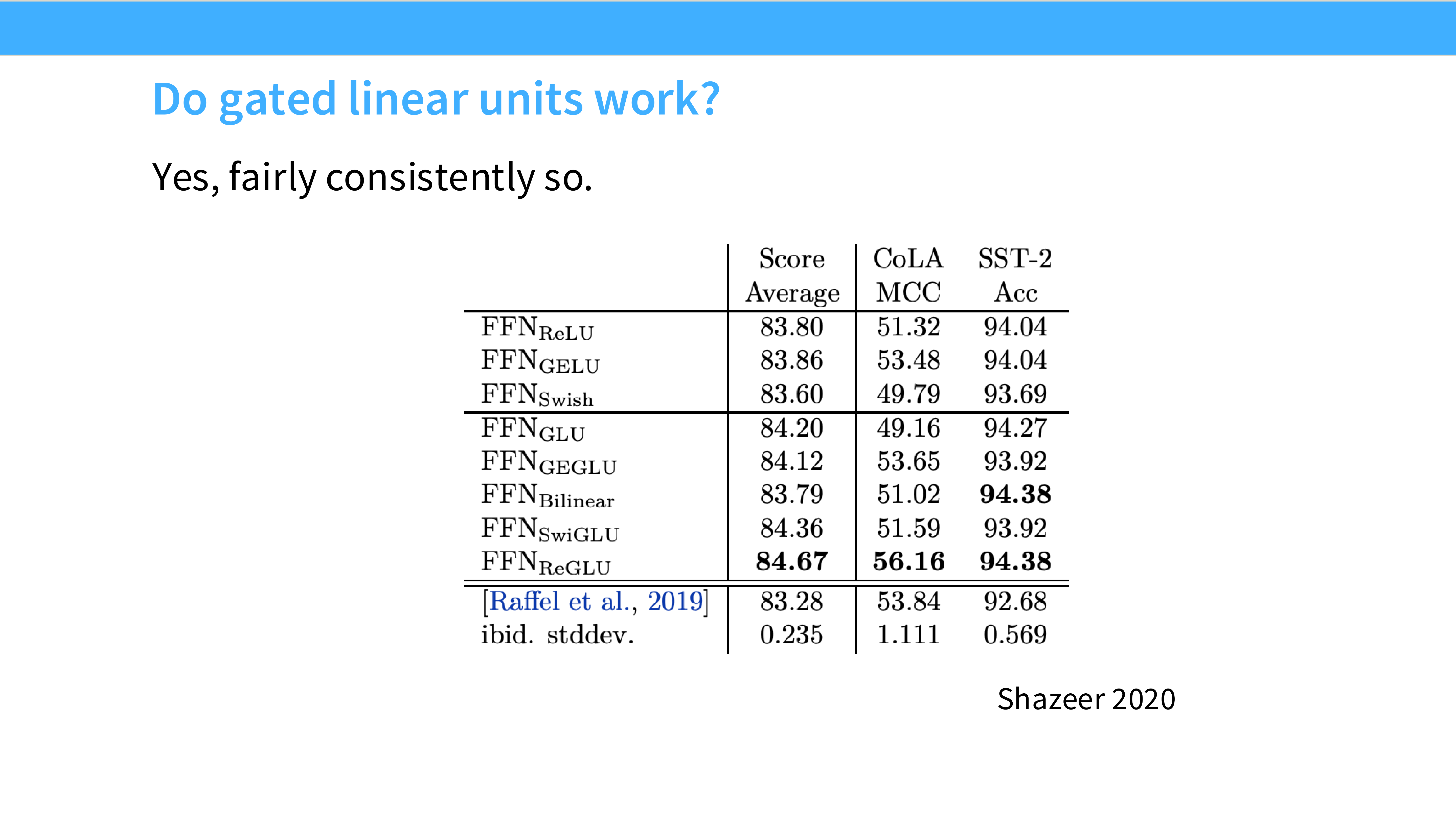
Page 25: GLU 真的更好吗?
- 内容: 引用 Shazeer 2020 论文图表。
- 结论: 在相同 FLOPs 下,GLU 变体(ReGLU, SwiGLU)始终优于非门控版本(ReLU, GeLU)。

Page 26: 更多实验证据
- 内容: 另一组 PPL 对比。SwiGLU 表现最佳。
Page 27: 激活函数总结
- 结论: SwiGLU 提供了最佳的性能/计算比。虽然计算稍微繁琐(多一次矩阵乘),但效果值得。目前是 Llama-like 架构的标配。
Part 5: 并行层与位置编码 (Parallel Layers & Pos Embs)

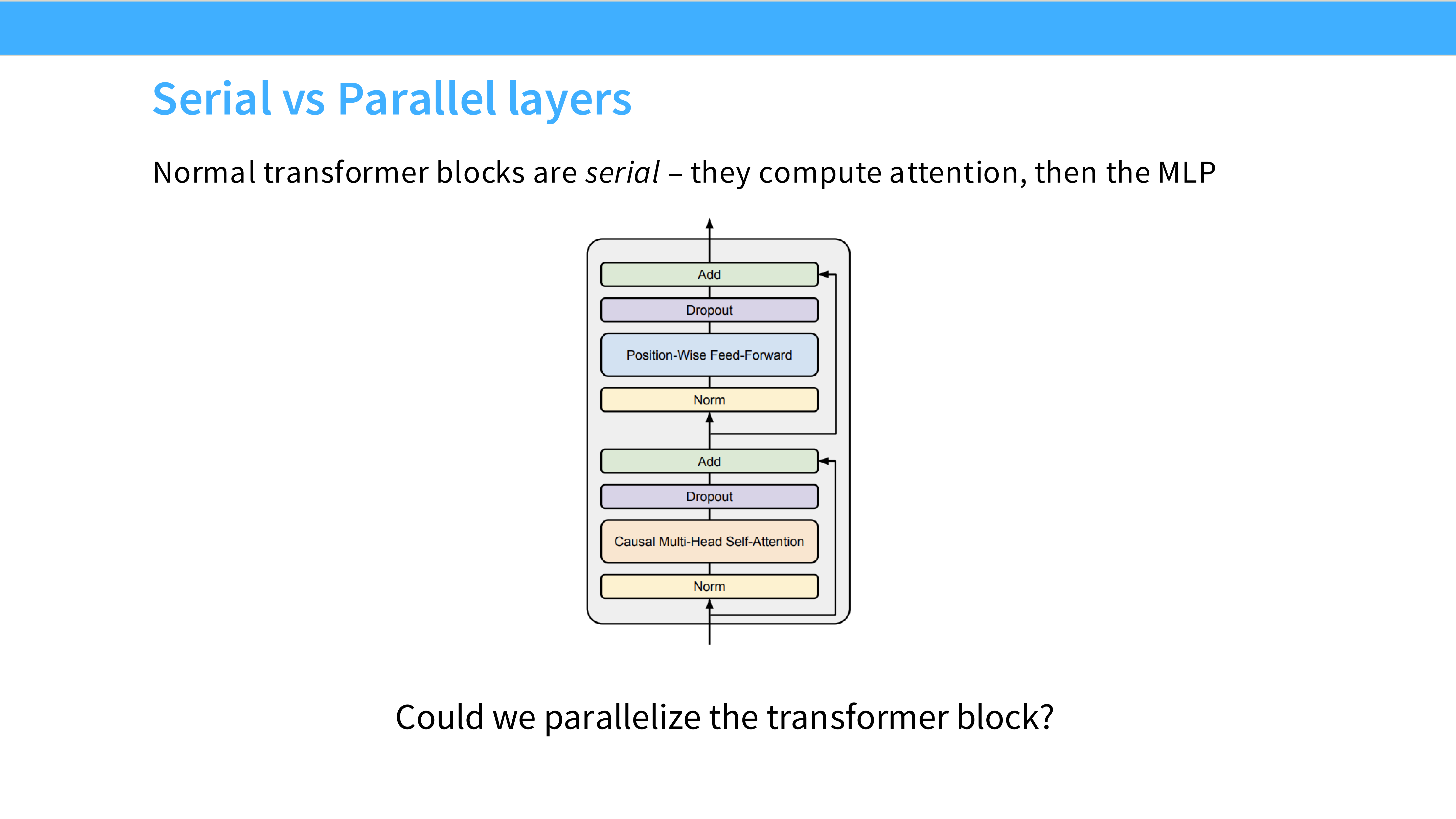
Page 28: 串行 (Serial) vs 并行 (Parallel) 块
- Serial (标准): 先算 Attention,加残差,Norm,再算 MLP,加残差。
- Parallel: Attention 和 MLP 同时计算(共享同一个 Norm 后的输入),然后把它们的结果一起加到残差上。
- $x_{out} = x + Attn(LN(x)) + MLP(LN(x))$

Page 29: 并行层的权衡
- 优点: 训练速度快约 **15%**。因为矩阵乘法可以融合,通信可以合并。PaLM 和 GPT-J 采用了这种设计。
- 缺点: 性能略微下降(Worse Quality)。
- 现状: 大多数追求极致性能的模型(Llama)依然使用串行架构。
Page 30: 架构小结 (Summary so far)
- 必选: Pre-norm (RMSNorm)。
- 首选: SwiGLU。
- 可选: Parallel Layers(为了速度),No Bias(为了稳定)。

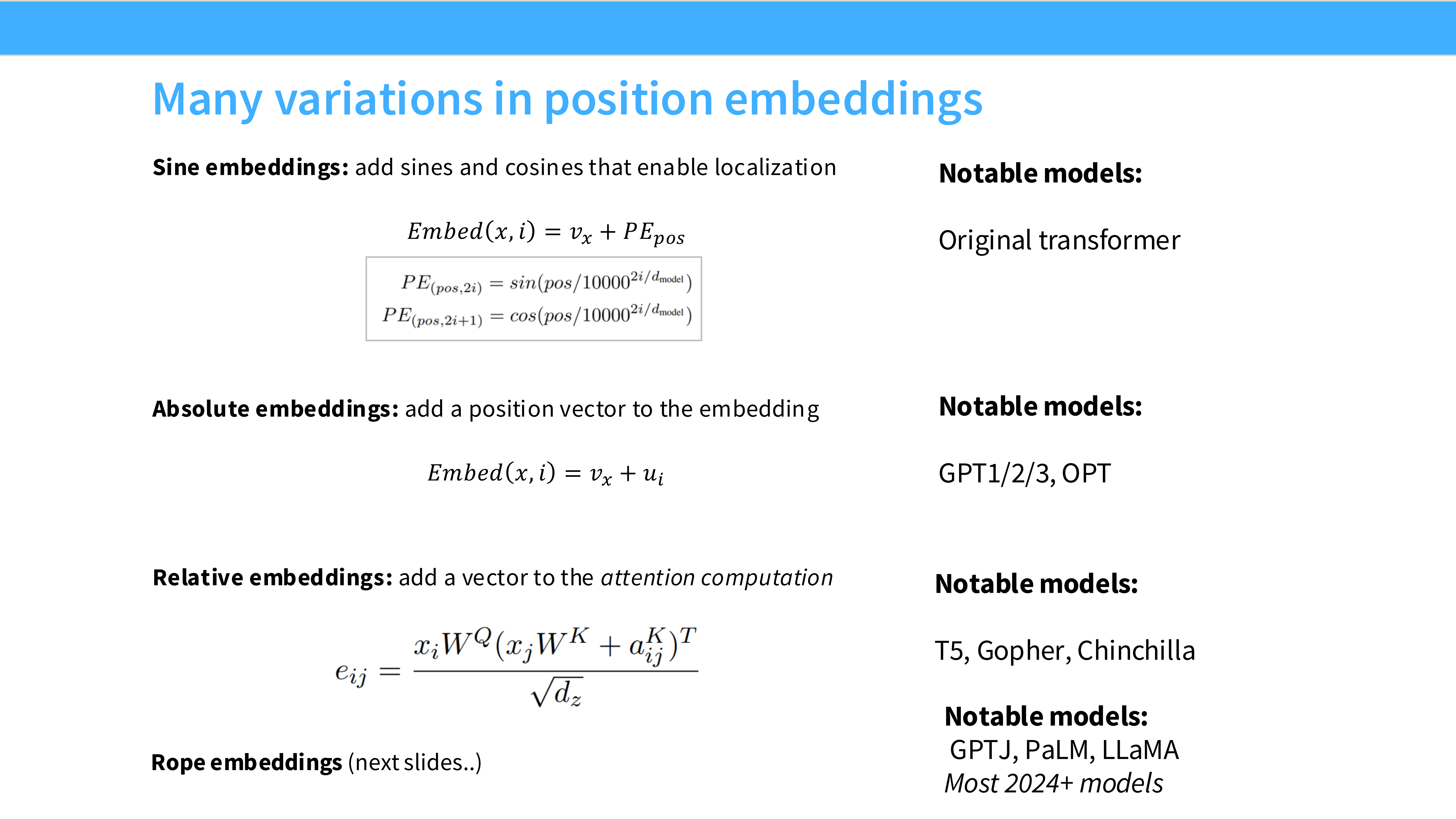
Page 31: 位置编码的演变
- 绝对位置: Sine/Cosine (Transformer), Learned (GPT-3)。
- 相对位置: T5, ALiBi。
- 旋转位置 (RoPE): LLaMA, PaLM。现在是 RoPE 的天下。
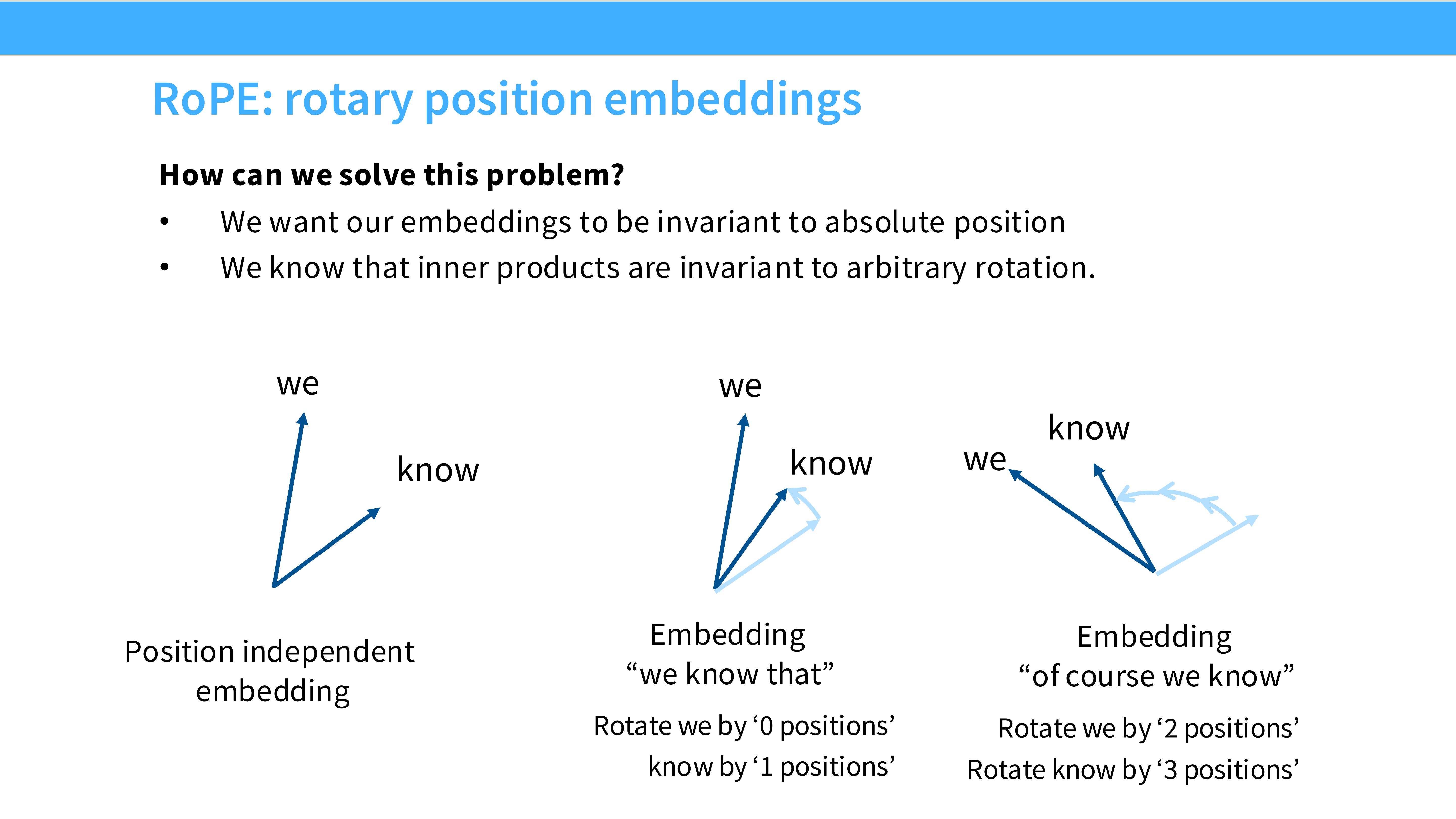
Page 32: RoPE 的核心理念
- 目标: 我们希望 Attention 机制能自然地捕捉 Token 之间的相对距离 $(m-n)$,而不是关心它们的绝对位置 $m, n$。
- 方法: 寻找一种变换,使得 $\langle f(q, m), f(k, n) \rangle = g(q, k, m-n)$。RoPE 通过复数旋转完美解决了这个问题。
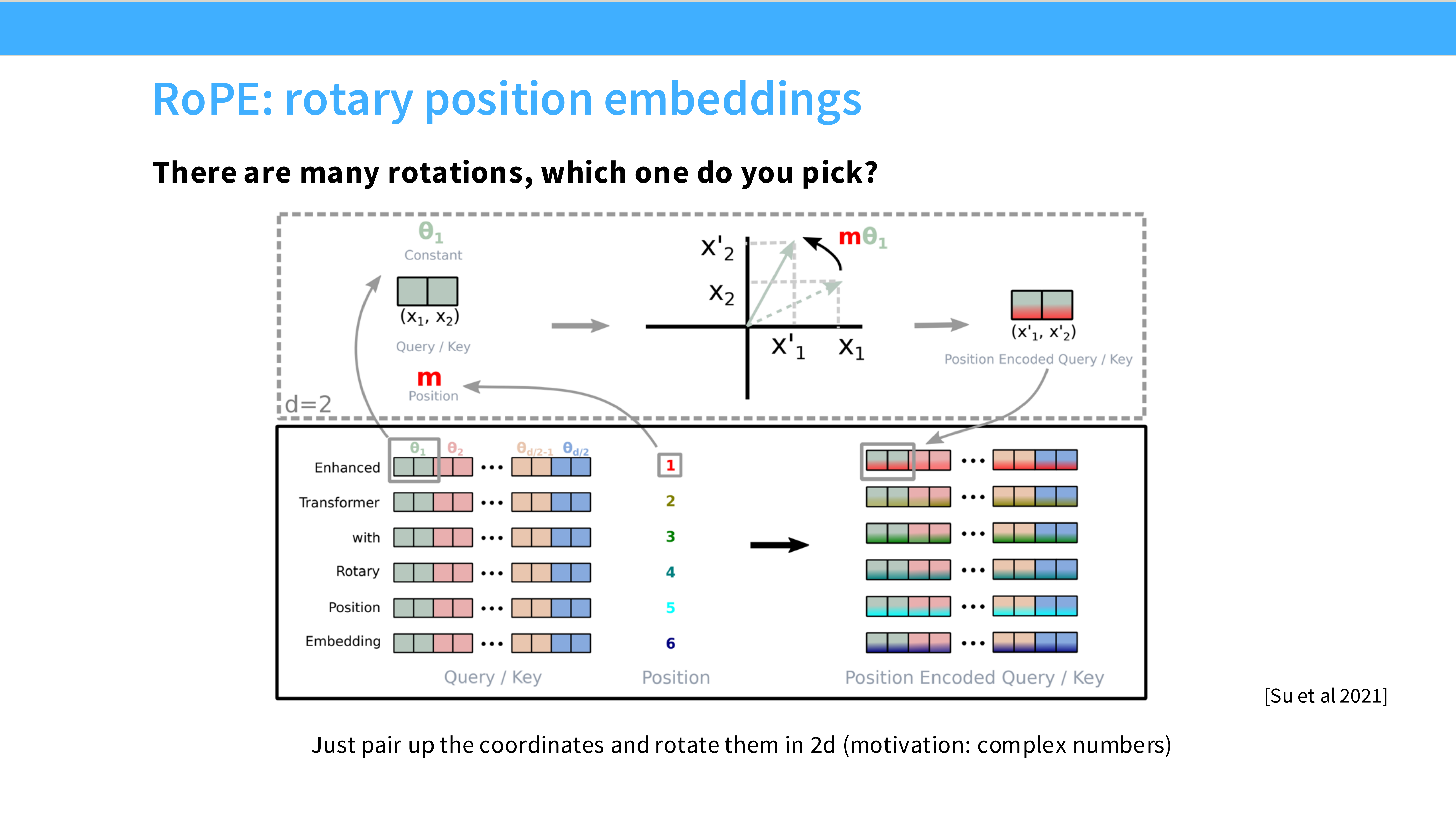
Page 33: RoPE 的直观图示
- 视觉: 二维平面上的向量旋转。
- 原理解析: 将 Embedding 向量两两分组,视为复数。根据该 Token 的位置 $m$,将复数向量旋转 $m\theta$ 角度。两个向量点积时,角度相减,自然得到相对位置信息 $(m-n)\theta$。
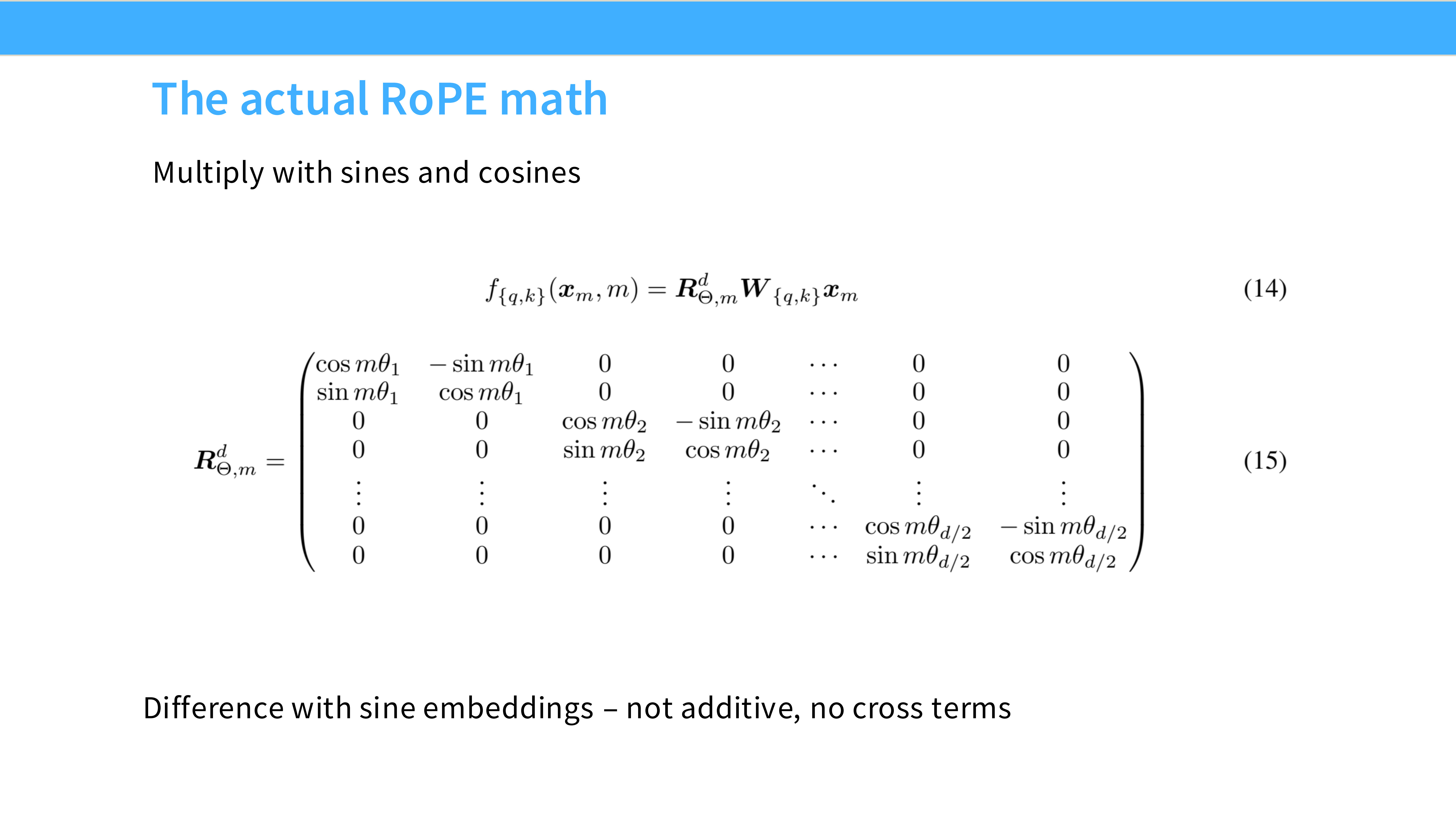
Page 34: RoPE 数学形式
- 内容: 旋转矩阵 $R_{\Theta}$ 是块对角的。
- 特点: 这种稀疏结构意味着我们可以快速计算旋转,不需要进行庞大的矩阵乘法。

Page 35: RoPE 代码与外推
- 实现: 在每一层计算 Attention Score 之前,即时对 Q 和 K 进行旋转。
- 外推性 (Extrapolation): RoPE 在处理比训练长度更长的序列时,表现优于绝对位置编码,但仍有衰减。
Part 6: 超参数调优 (Hyperparameters)

Page 36: 哪些参数重要?
- FFN 维度?Head 数量?Head 大小?词表大小?

Page 37: FFN 膨胀系数
- 标准: $d_{ff} = 4 d_{model}$。
- SwiGLU: 由于参数变多了,通常设为 $\frac{8}{3} d_{model} \approx 2.66 d_{model}$,以保持总参数量与标准版一致。
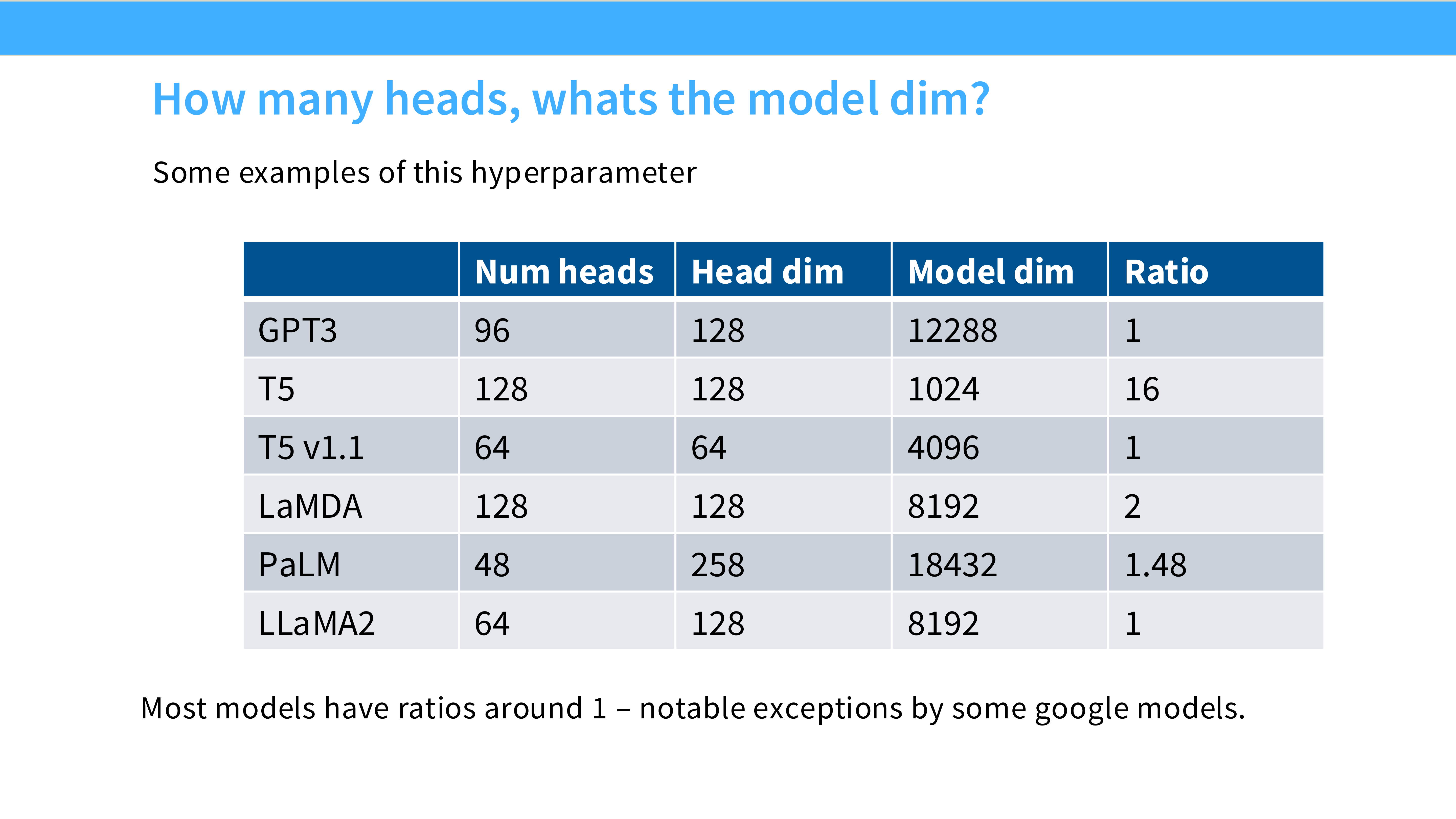
Page 38: Head Dimension (头维度)
- 黄金标准: 128。
- 观察: 无论是 7B 的 Llama 还是 175B 的 GPT-3,大家都在用
head_dim=128。 - 原因: 硬件亲和性。128 完美契合 GPU Tensor Core 的计算分块大小,效率最高。

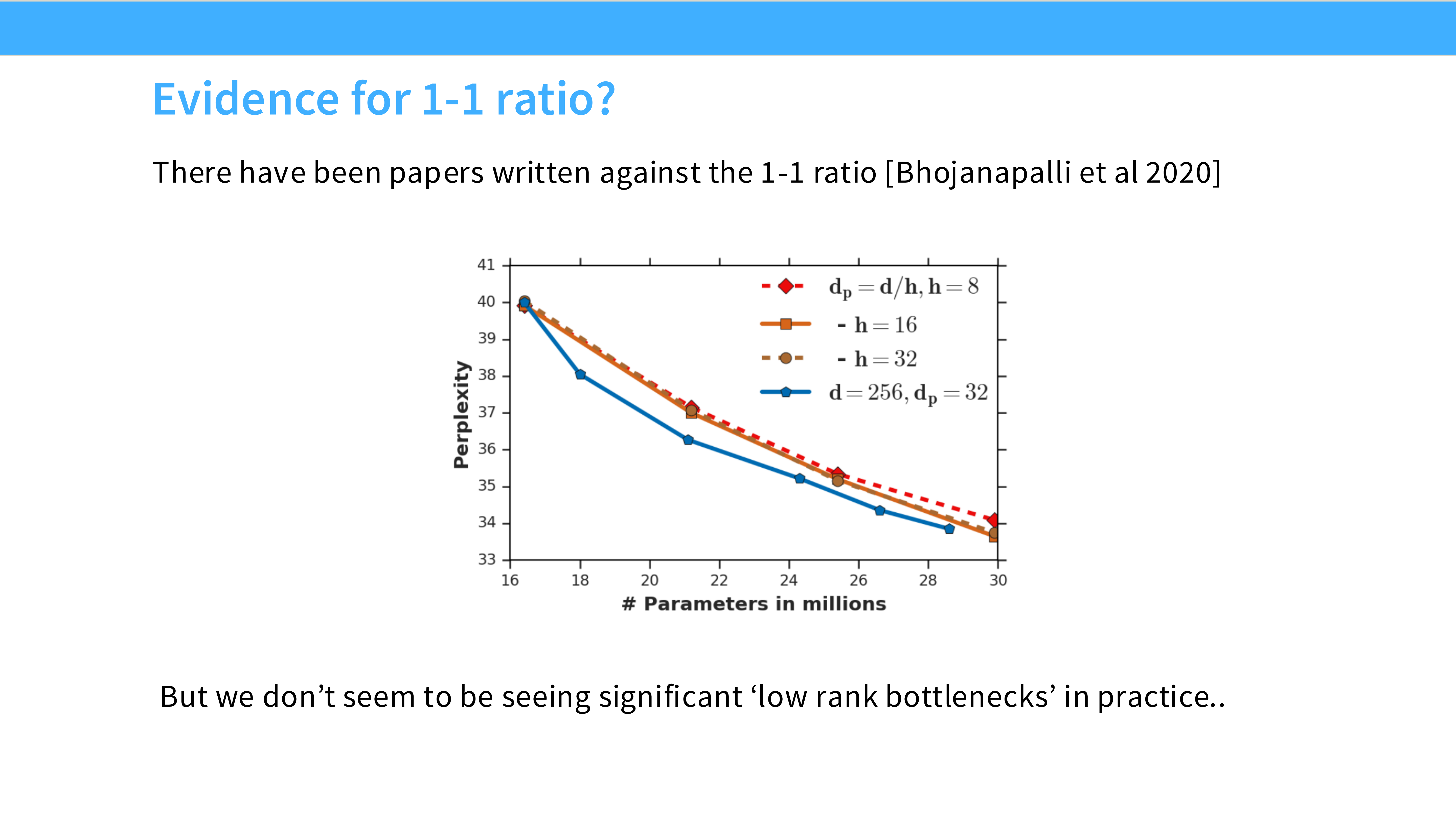
Page 39: 为什么是 1-1 Ratio?
- 内容: 引用 Bhojanapalli et al 2020。
- 结论: 保持
n_heads * head_dim = d_model是最佳实践。虽然理论上可以解耦,但没什么好处。
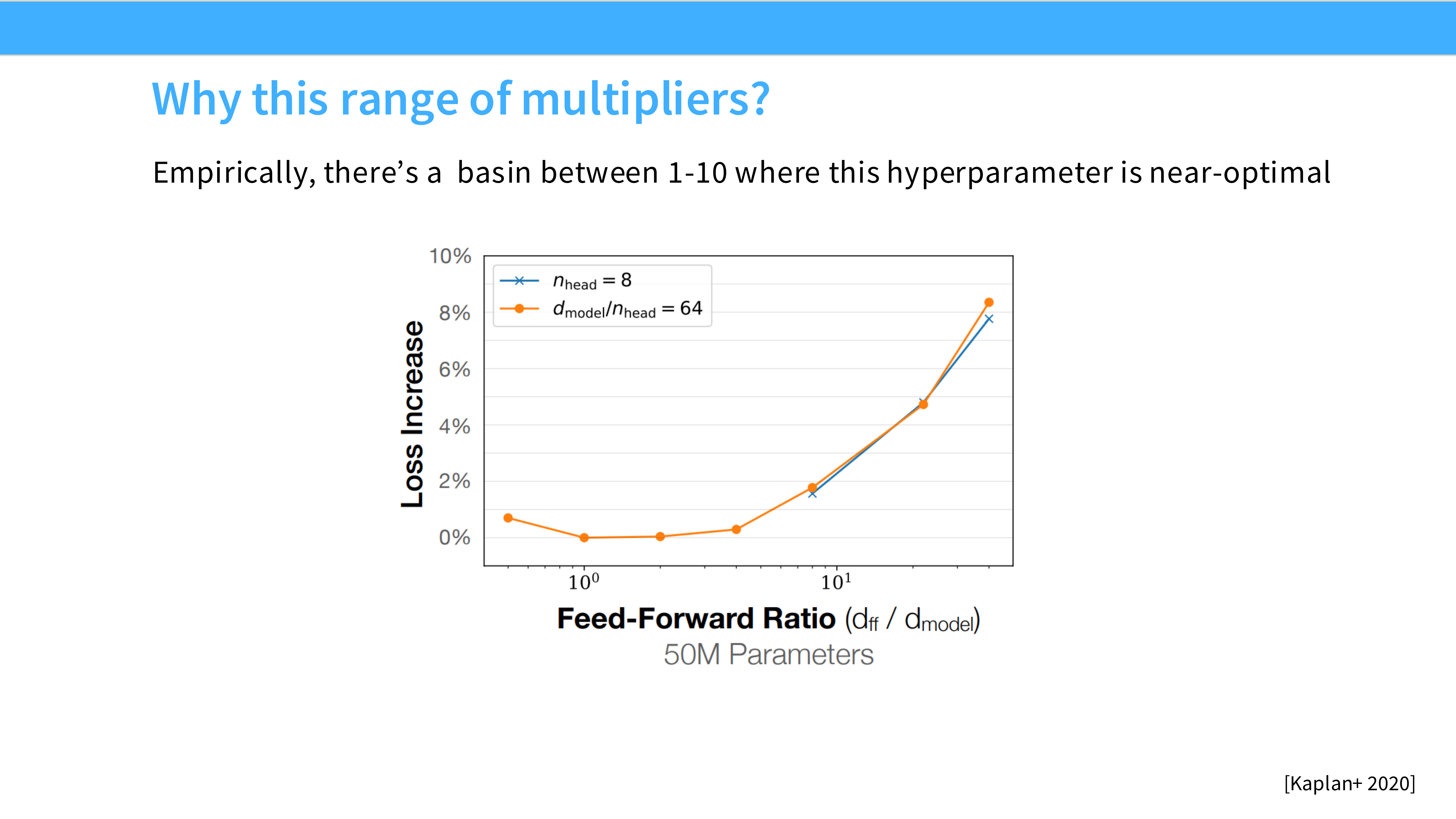
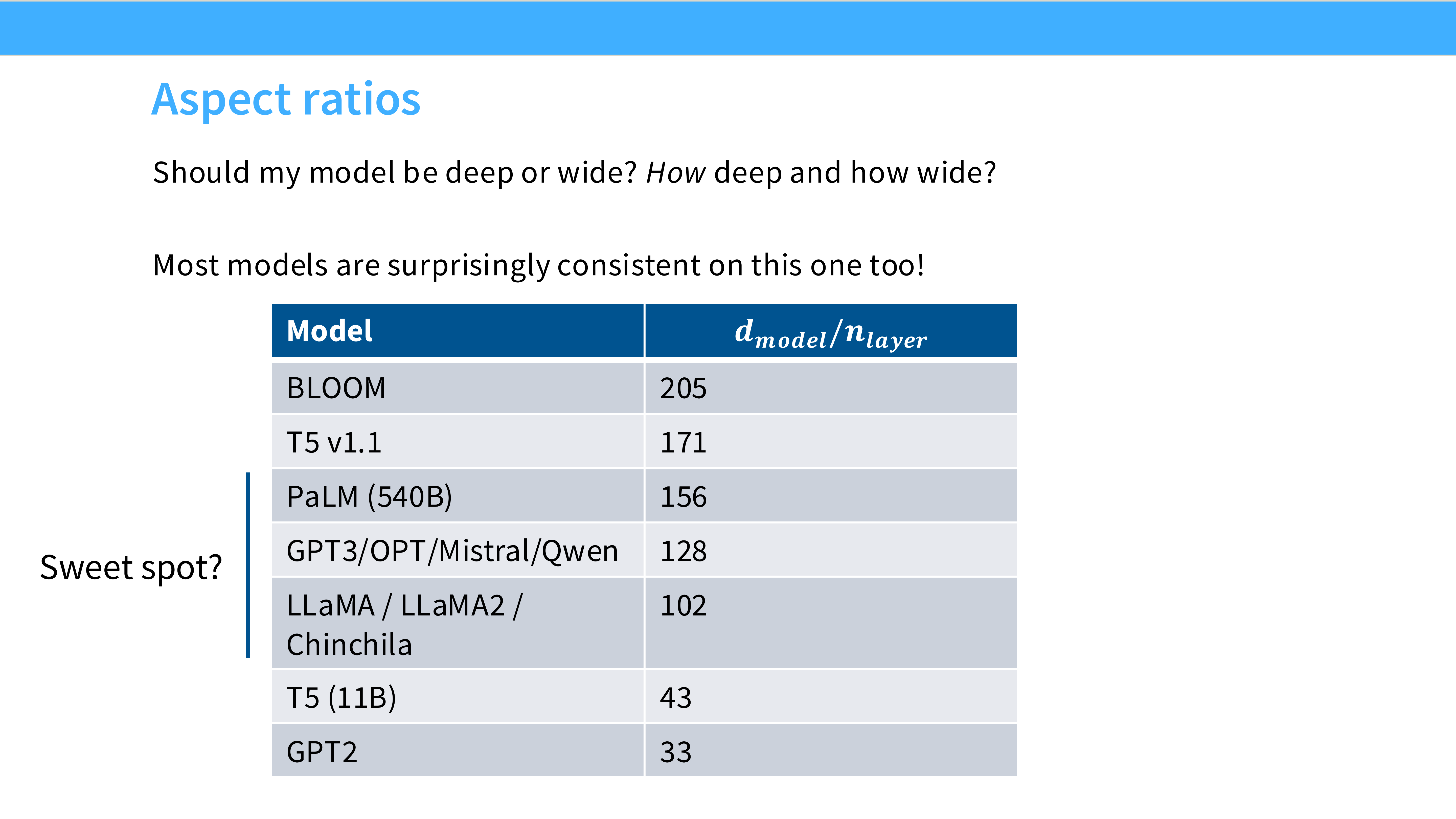
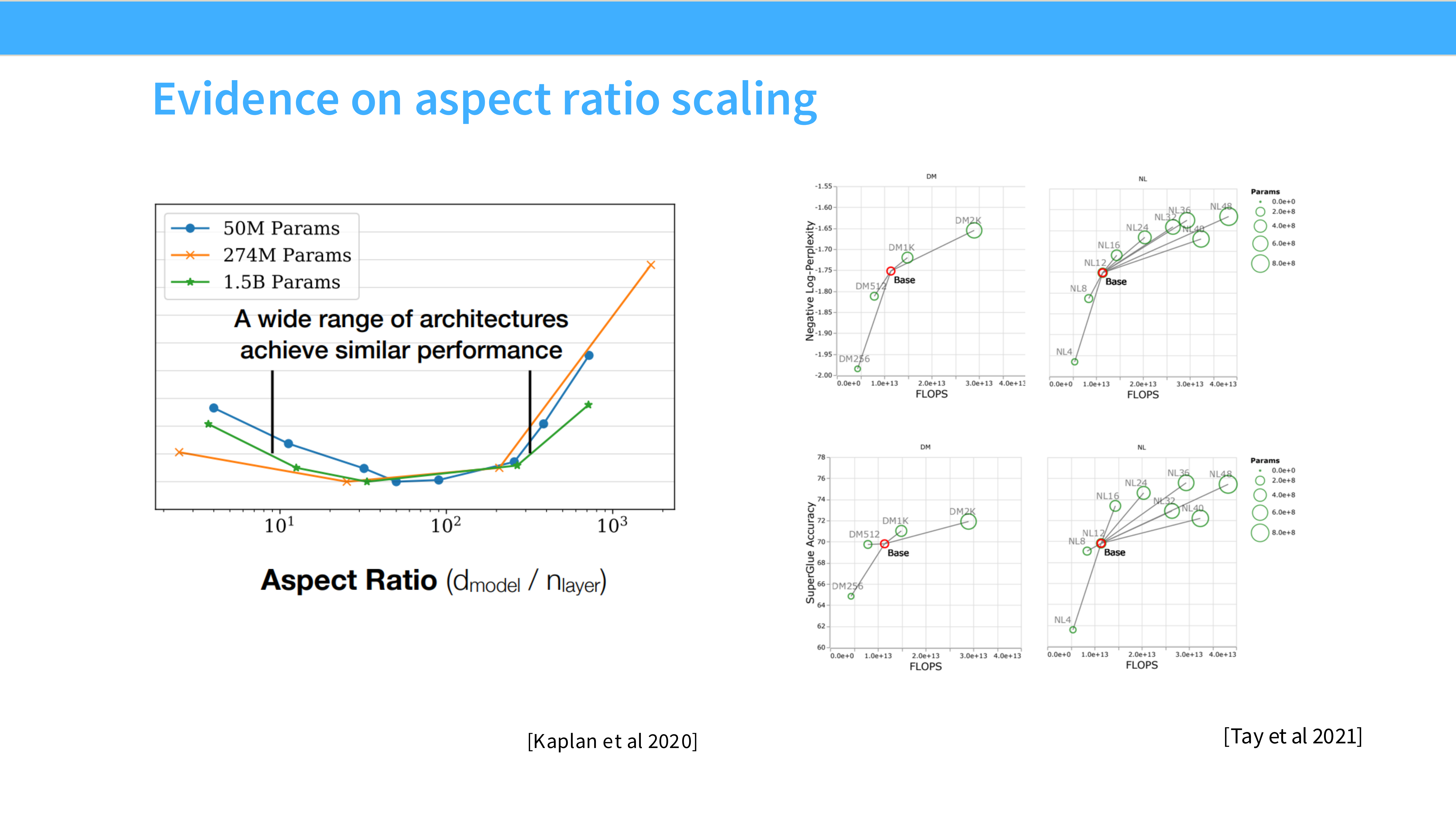
Page 40: 深宽比 (Aspect Ratio)
- 内容: 模型该深(Deep)还是该宽(Wide)?
- 结论: 在很大范围内,性能对形状不敏感。只要参数量够了就行。
- Sweet Spot: 通常 $d_{model} \approx 128 \times n_{layers}$。

Page 41: 深度限制
- 提示: 不要让模型太深(例如超过 100 层)。太深会导致推理延迟高,且流水线并行(Pipeline Parallelism)更难切分。稍微宽一点对系统更友好。

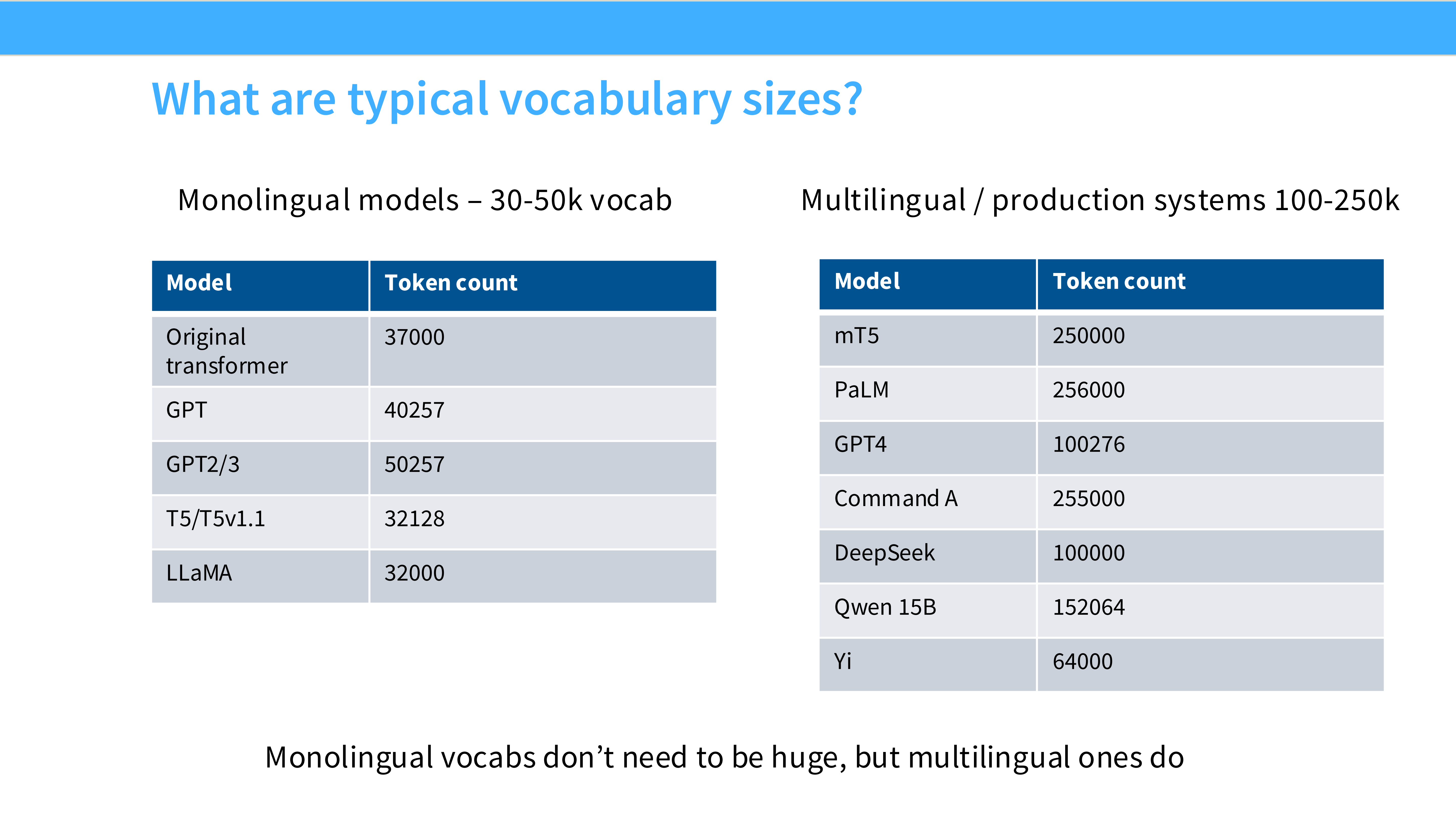
Page 42: 词表大小 (Vocab Size)
- 趋势: 变大。
- GPT-2: 50k
- Llama 2: 32k
- Llama 3: 128k
- Qwen: 150k
- 原因: 大词表 = 压缩率高 = 同样 2048 长度包含更多信息 = 推理更快。虽然 Embedding 层参数多了,但值得。
Page 43: 正则化 (Regularization)
- 问题: 这么多数据,还需要防过拟合吗?
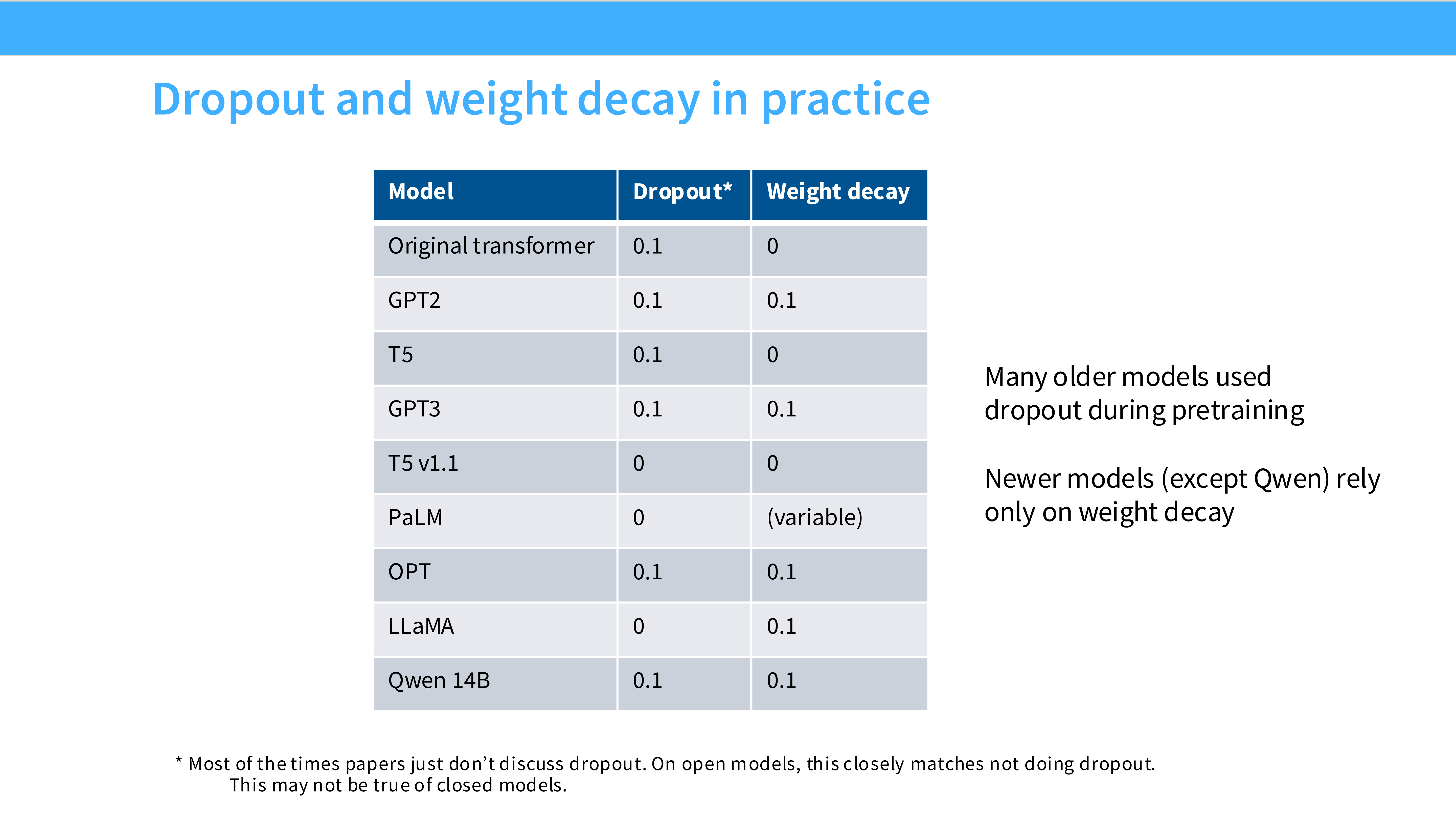
Page 44: Dropout 的消失
- 内容: 预训练期间 Dropout = 0。
- 原因: 我们的数据量太大了(Trillions tokens),模型根本记不住,不存在过拟合。Dropout 只会浪费计算资源并减慢收敛。Llama, PaLM 全都把 Dropout 关了。
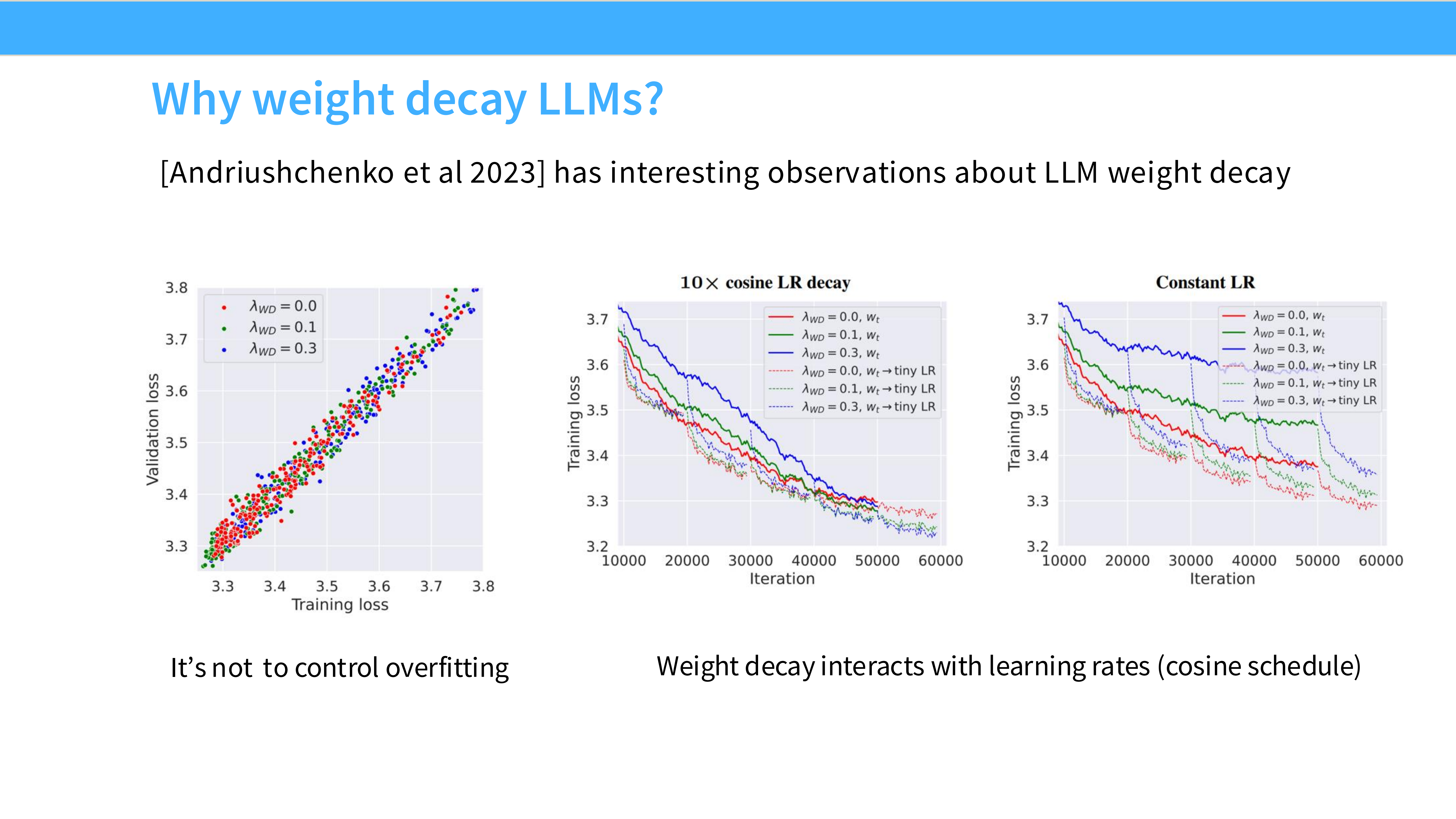
Page 45: Weight Decay 依然存在
- 内容: Weight Decay = 0.1。
- 原因: 它不仅是正则化,更重要的是它影响**优化动态 (Optimization Dynamics)**。有 Weight Decay,SGD/Adam 才能收敛到更平滑的极小值点。这个不能关。

Page 46: 超参数总结
- FFN Mult: 2.67 (SwiGLU)
- Head Dim: 128
- Dropout: 0
- Weight Decay: 0.1
Part 7: 训练稳定性与推理优化 (Stability & Inference)
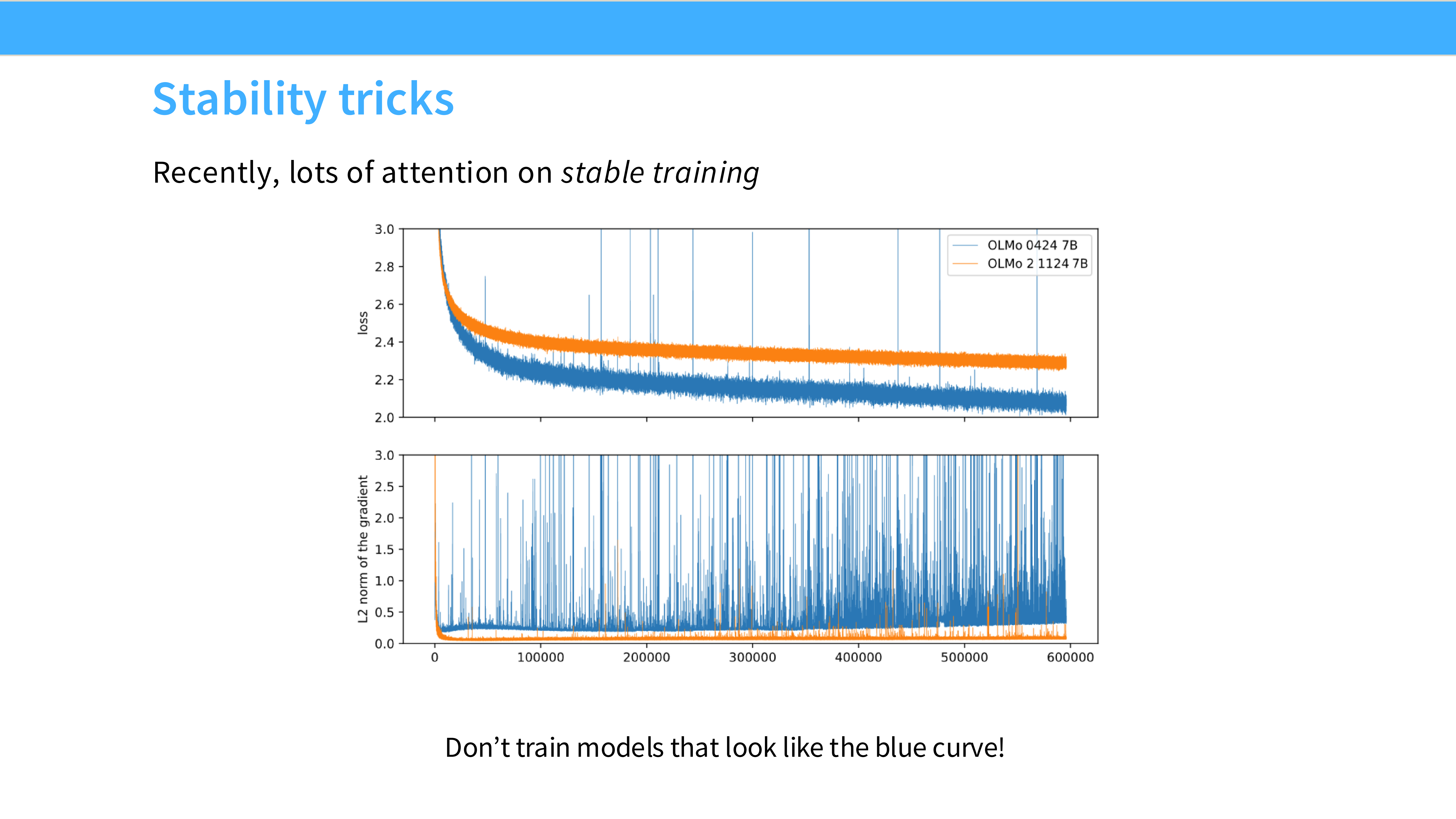
Page 47: 稳定性技巧 (Stability Tricks)
- 背景: 训练大模型最怕遇到 Loss Spike(Loss 突然暴涨),这通常意味着你要回滚几十个小时的 Checkpoint,甚至从头再来。
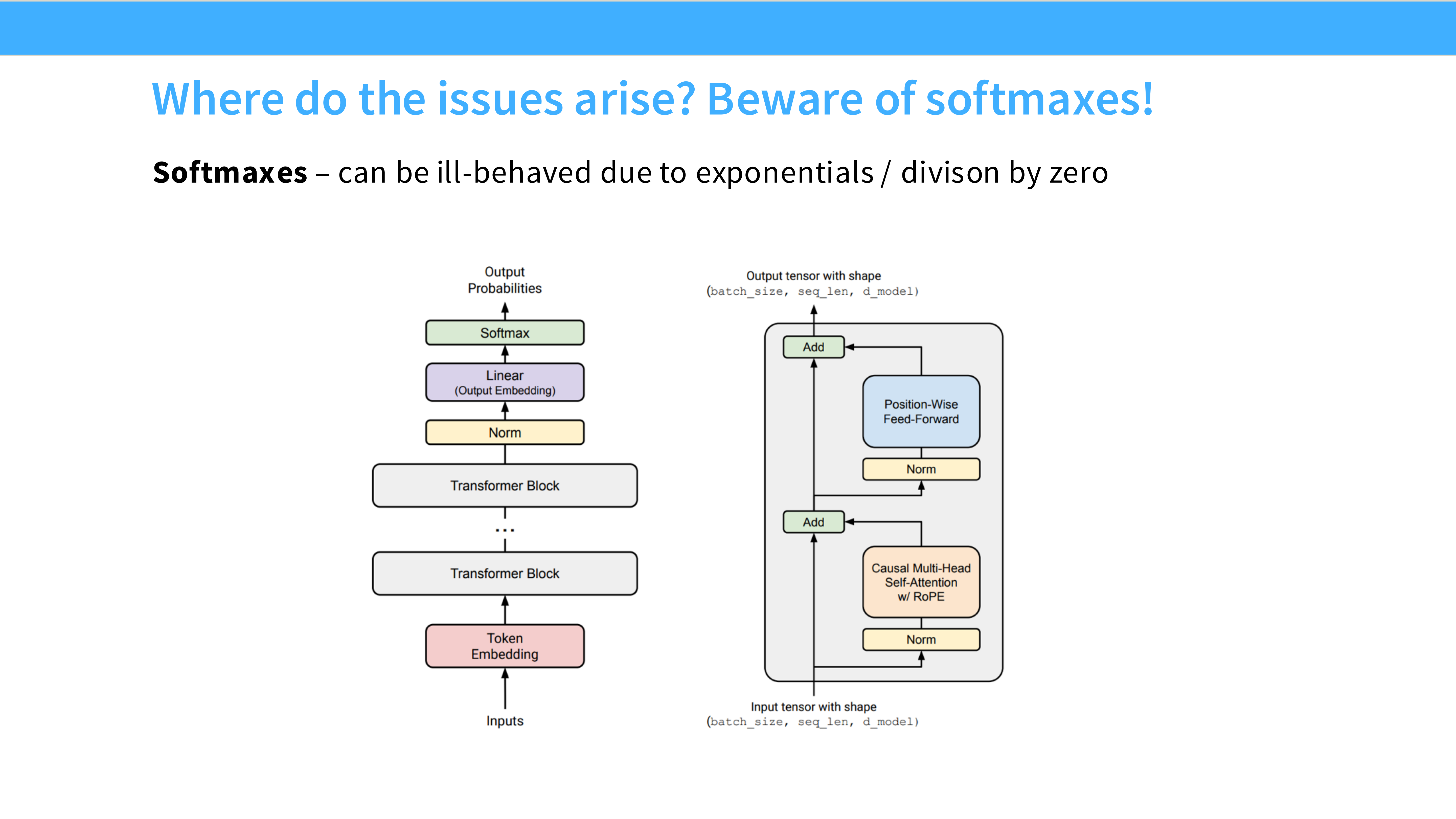
Page 48: 元凶 - Softmax 溢出
- 内容: Softmax 里的
exp(x)对大数值非常敏感。如果 Logits 稍微大一点,exp就会溢出 FP16 的范围(NaN),导致训练崩溃。

Page 49: Trick 1 - z-loss
- 来源: PaLM 论文。
- 方法: 加一个辅助 Loss:$L_{aux} = 10^{-4} \log^2 Z$ ($Z$是Softmax分母)。
- 作用: 惩罚过大的 Logits 总和,强制 Softmax 的 Logits 保持在 0 附近,防止爆炸。
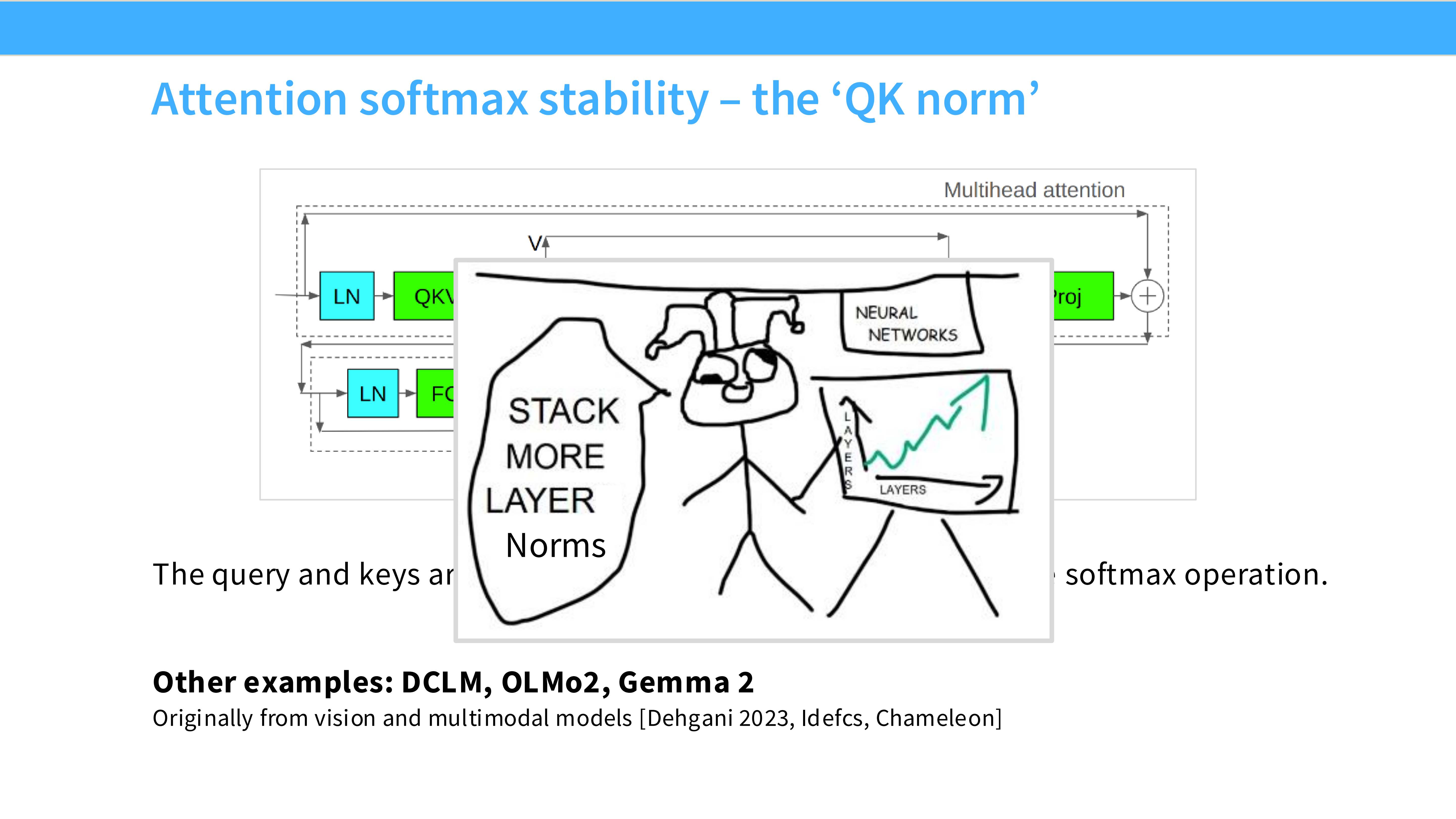
Page 50: Trick 2 - QK Norm
- 来源: ViT-22B, Gilmer et al.
- 方法: 在计算 $Q \cdot K^T$ 之前,先对 Query 和 Key 向量做 LayerNorm。
- 作用: 无论 Embedding 维度多大,强制 Q 和 K 的尺度保持不变,从而稳定 Attention Score。DCLM 和 Gemma 2 都在用。
Page 51: Trick 3 - Logit Soft-capping
- 来源: Gemma 2。
- 方法: $logits = C \cdot \tanh(logits / C)$。
- 作用: 用
tanh物理截断 Logits,使其永远不会超过 $C$(例如 50)。这是一种硬约束,彻底消除了溢出可能。

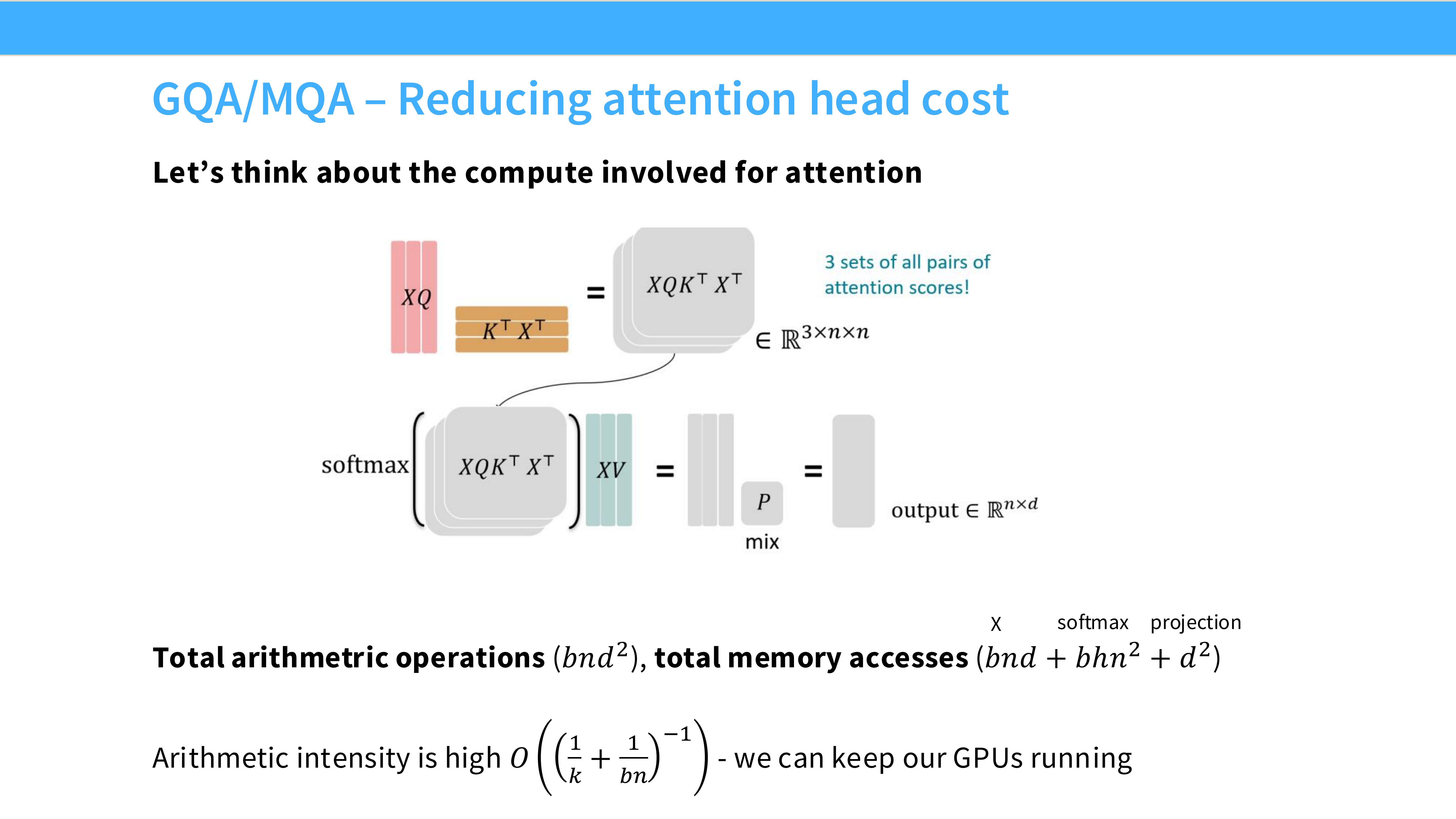
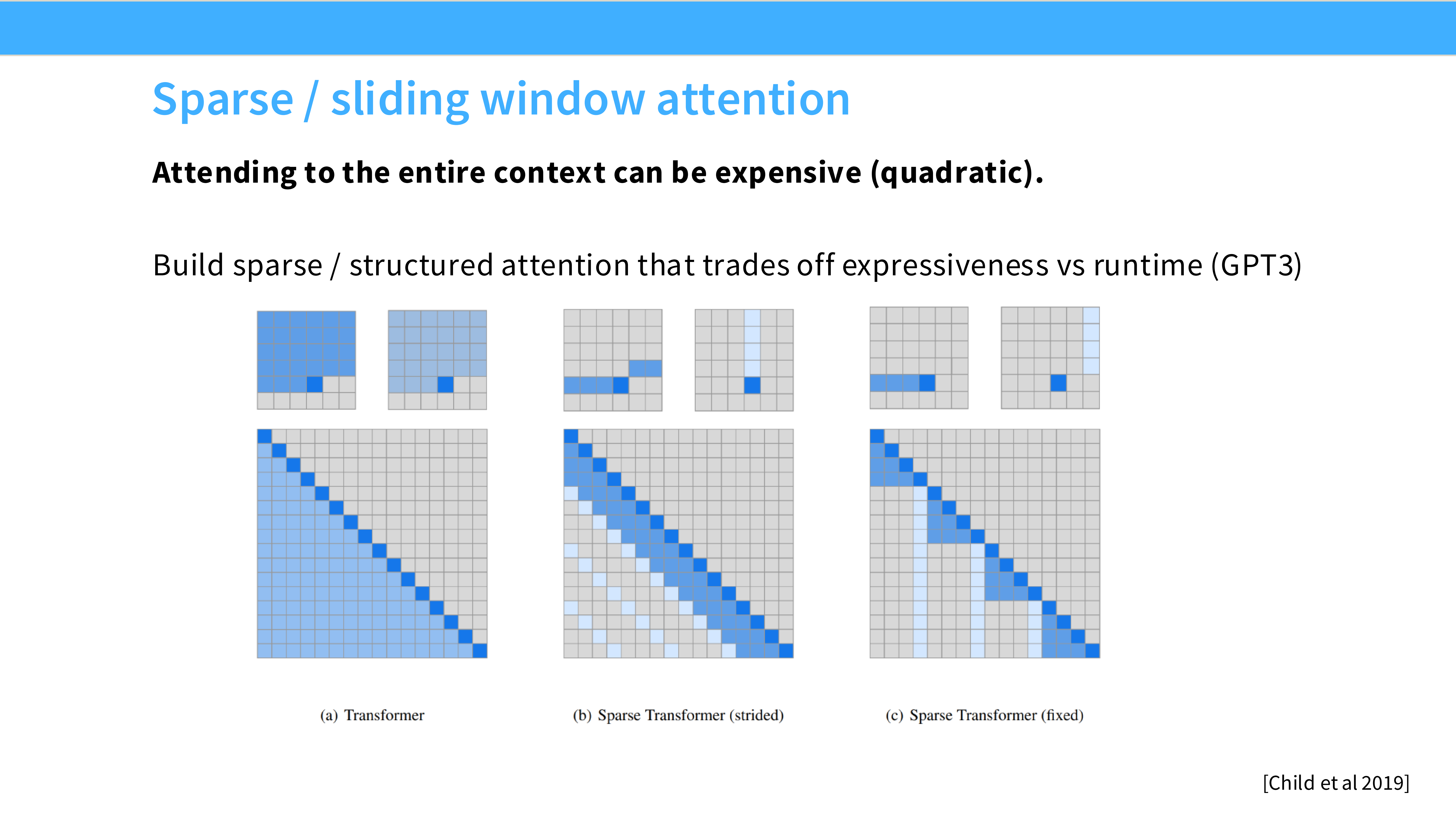
Page 52: 推理优化 - Attention 瓶颈
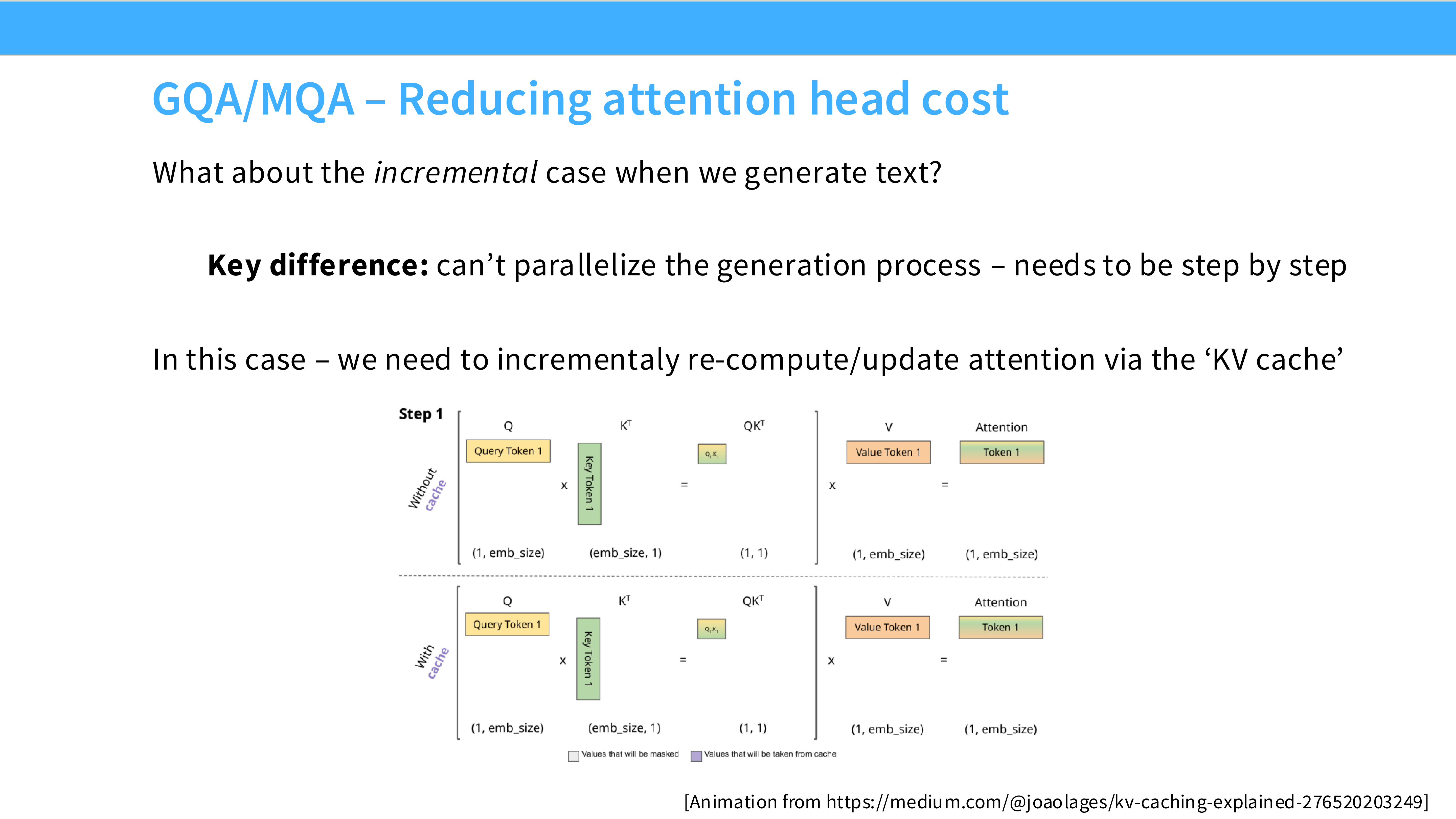
- 问题: 推理时,KV Cache 占用大量显存,且搬运 KV Cache 是 IO 瓶颈。MHA (Multi-Head Attention) 每一层都要加载巨大的 KV 矩阵。
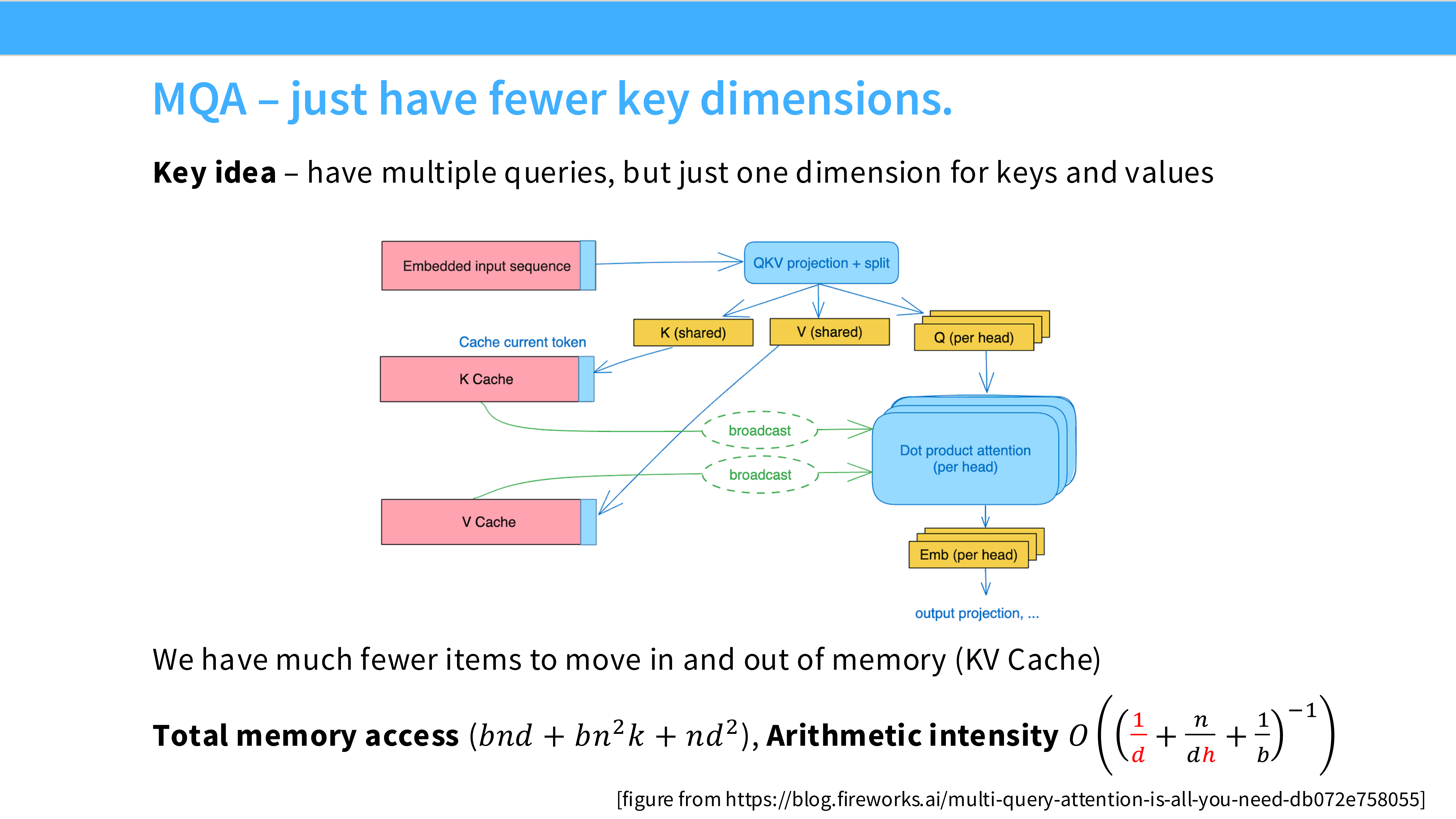
Page 53: MQA (Multi-Query Attention)
- 机制: 整个模型的所有 Query Heads 共享同一对 K 和 V Head。
- 优势: KV Cache 大小减少了 $N_{head}$ 倍。推理飞快。
- 劣势: 模型表达能力受损,质量下降。
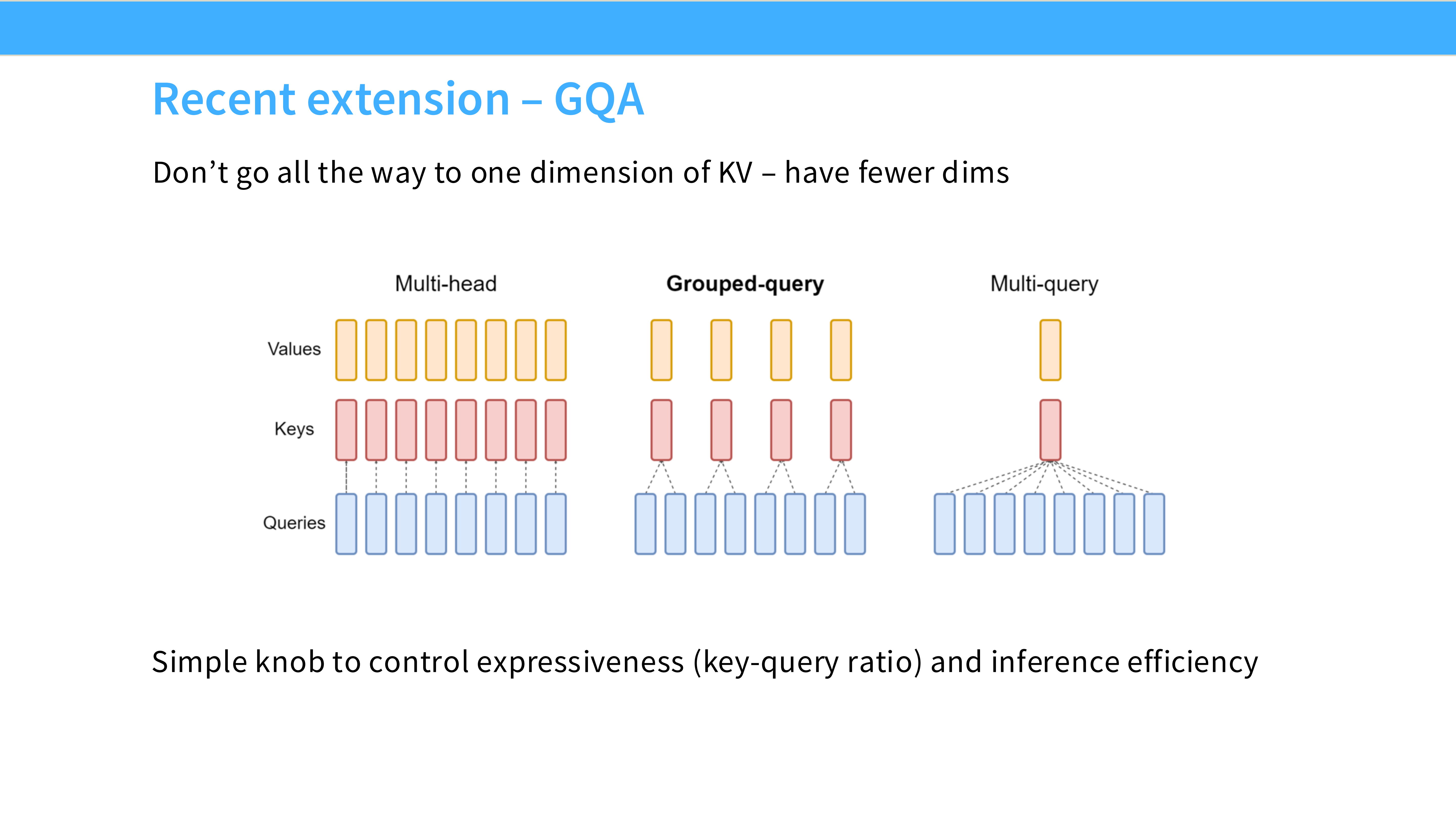
Page 54: GQA (Grouped-Query Attention)
- 机制: 折中方案。将 Query Heads 分组(例如 8 组),每组共享一对 K/V Head。
- 优势: 速度接近 MQA,质量接近 MHA。
- 地位: Llama 2/3, Mistral 的标配。现在基本上没人用标准 MHA 了。

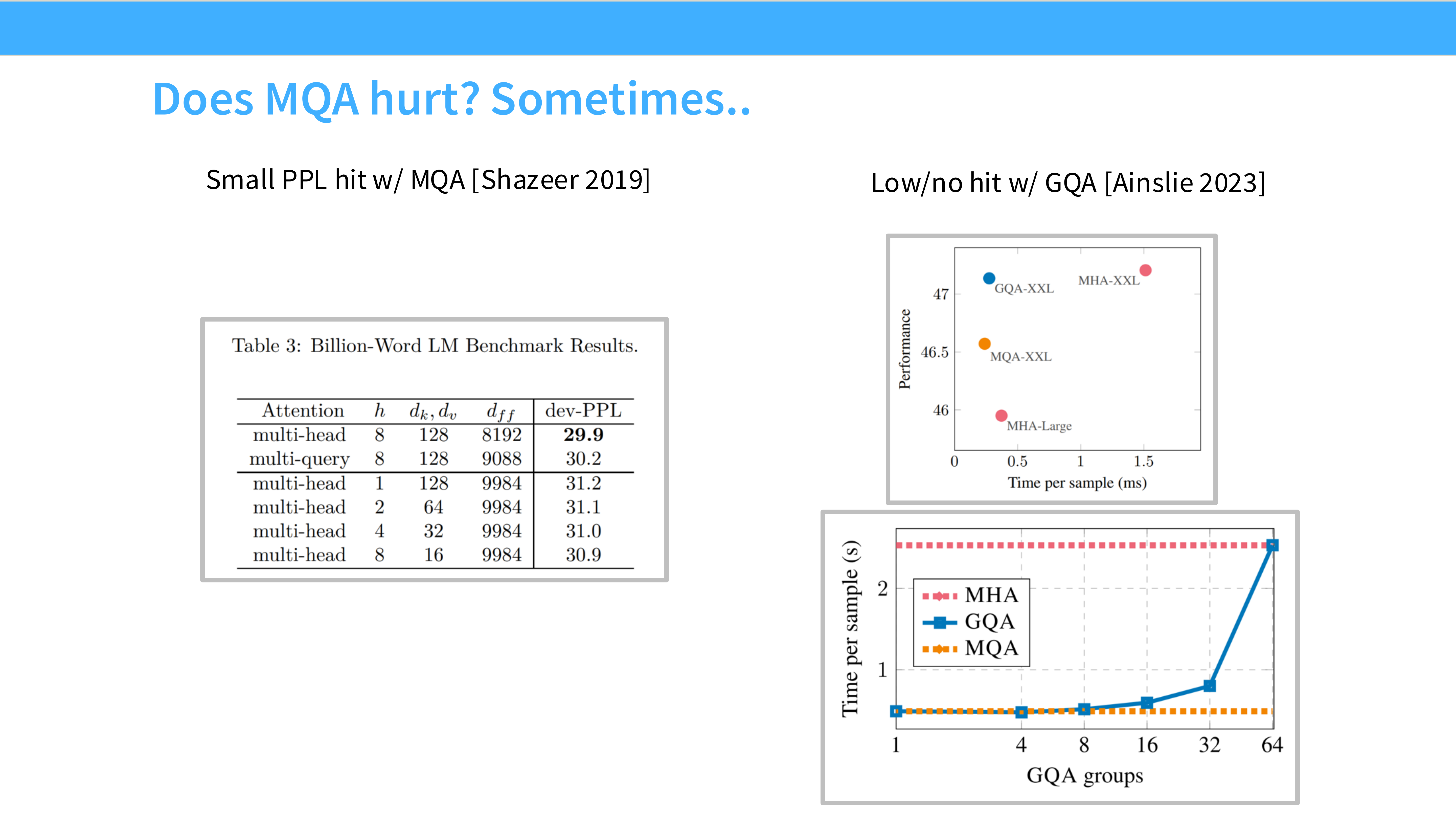
Page 55: MQA vs GQA 性能图
- 内容: 图表显示 GQA 在保持高吞吐量的同时,PPL 损失极小。
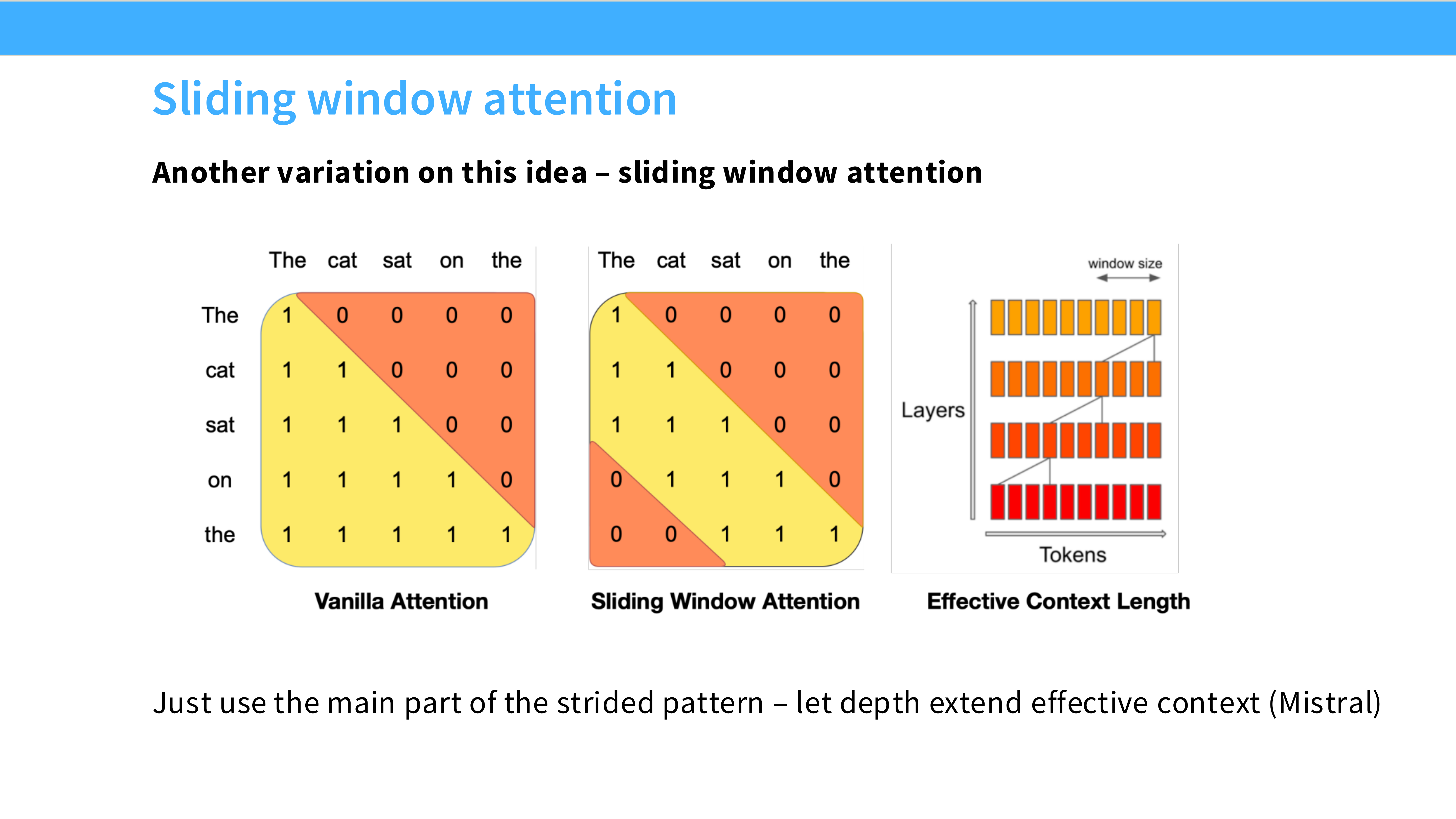
Page 56: SWA (Sliding Window Attention)
- 机制: 强行限制 Attention 只看最近的 $W$ 个 Token(如 4096)。
- 代表: Mistral 7B。
- 作用: 节省计算量,变成 $O(N)$ 复杂度。

Page 57: 混合 Attention (Interleaving)
- 机制: Gemma 2 的做法。例如:层 1 用 SWA(局部),层 2 用 Full Attention(全局),交替进行。
- 作用: 既节省了计算,又保留了长距离建模能力。
Part 8: 总结 (Conclusion)

Page 58: 架构收敛 (Convergence)
- 核心结论: 2024-2025 年的 LLM 架构已经高度趋同,被称为 “Llama-like” 架构:
- Pre-RMSNorm
- SwiGLU
- RoPE
- GQA
- No Bias
Page 59: 为什么收敛到这套配置?
- Pre-norm: 为了梯度流(训练深层模型)。
- RMSNorm/SwiGLU: 为了计算效率和微小的性能增益。
- RoPE: 为了位置外推性。
- GQA: 为了推理成本。
Page 60: 警惕盲从 (Cargo Culting)
- 警告: 虽然我们要学习最佳实践,但不要盲目复制。很多配置(如 128 head dim)可能是因为硬件原因,也可能只是习惯,未必是科学上的最优解。

Page 61: 没讲到的内容
- Encoder-Decoder (T5): 现在的 LLM 几乎全是 Decoder-only。
- MoE: 下节课重点讲。
- SSM/Linear Attn: 很有趣,但还未动摇 Transformer 的统治地位。
Page 62: 总结
- 架构设计是系统工程(考虑硬件效率)、优化理论(考虑梯度流)和经验主义(看谁跑分高)的结合。
Page 63: 推荐阅读
- Llama 1/2/3 论文、PaLM 论文、Gopher 论文。重点读 Appendix 中的实验细节。
Page 64: 作业预告
- 实现一个带有 RoPE 和 RMSNorm 的现代 Transformer。
Page 65: 下节课预告
- Lecture 4: **Mixture of Experts (MoE)**。
Page 66: Q&A
- 问答环节。

Page 67: 参考文献 1
- 论文列表。

Page 68: 参考文献 2 / 结束
- 论文列表。课程结束。